Keith Randall (GitHub) is a principal software engineer at Google and works on the Go compiler. Last year he gave a talk on high-frequency trading with Go. Previously, he was a research scientist at Compaq’s System Research Center (SRC) and a student of the MIT Supercomputing Technologies Group.

Today, he’s talking about generating better machine code with Single Static Assignment (SSA). SSA is a technique used by most modern compilers to optimize generated machine code.
Go 1.5
The Go compiler was originally based on the Plan9 C compiler, which is old. This was modified to compile Go instead of C. Later it was autotranslated from C to Go.
In the era of Go 1.5, Keith began looking through Go-generated assembly code with the aim of making things faster. He noticed a number of instances where he thought the generated assembly was more verbose than it needed to be.
Consider the following assembly code generated from Go 1.5:
MOVQ AX, BX
SHLQ $0x3, BX
MOVQ BX, 0x10(SP)
CALL runtime.memmove(SB)
Why is that first MOVQ there? Why not just:
SHLQ $0x3, AX
MOVQ AX, 0x10(SP)
CALL runtime.memmove(SB)
Another example: Why do an expensive multiply operation:
IMULQ $0x10, R8, R8
instead of a shift operation, which is cheap:
SHLQ $0x4, R8
Yet another example: Writing value to register only to move the value straight to another register:
MOVQ R8, 0x20(CX)
MOVQ 0x20(CX), R9
Why not just:
MOVQ R8, 0x20(CX)MOVQ R8, R9
After finding all these examples of inefficiencies, Keith felt bold enough to proclaim, “I think it would be fairly easy to make the generated programs 20% smaller and 10% faster”. He admits those numbers were largely made up.
This was in in February 2015. Keith wanted to move the Go compiler from a syntax-tree-based intermediate representation (IR) to a more modern SSA-based IR. With an SSA IR, he believed they could implement a lot of optimizations that are difficult to do in the current compiler.
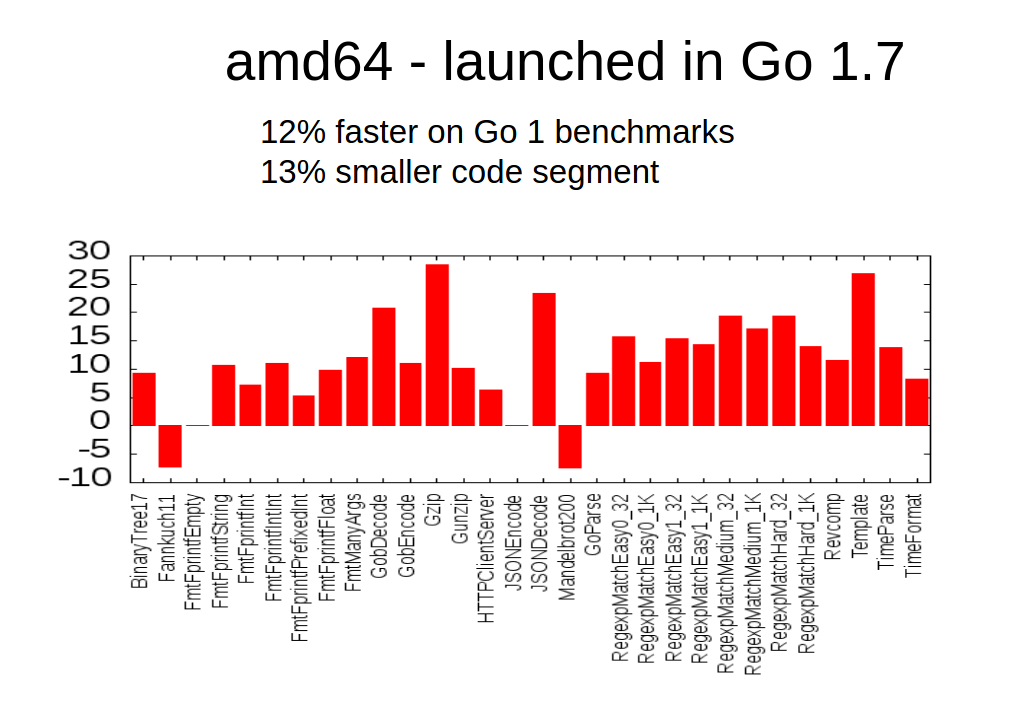
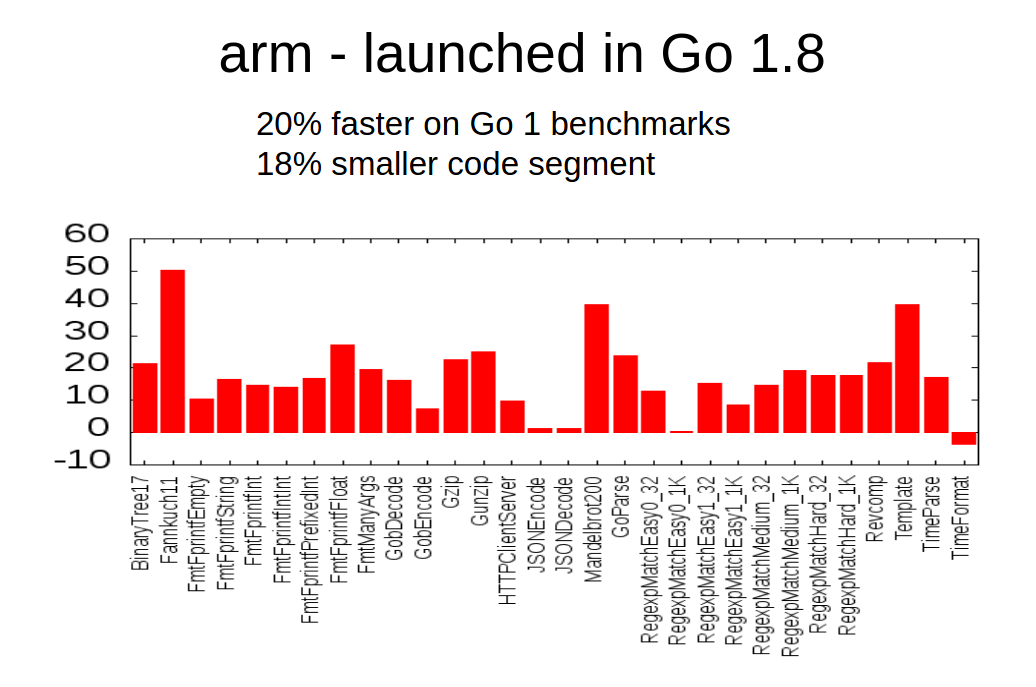
In, Feb 2015, the SSA proposal mailed to golang-dev. Work subsequently began, and in Go 1.7 and Go 1.8, the work was shipped for compiling to amd64 and arm respectively. Here are the performance improvements:
Go 1.7: amd64
Go 1.8: arm
There was better performance not only on the synthetic Go benchmarks (above), but also in the real world. Some benchmarks from the community:
- Big data workload - 15% improvement
- Convex hull - 14-24% improvement (from 1.5)
- Hash functions - 39% improvement
- Audio Processing (arm) - 48% improvement
Does the compiler itself get slower or faster with SSA?
So obviously, we’d expect a speedup in programs that were compiled via the SSA IR. But generating the SSA IR is also more computationally expensive. The one program where both these things will affect the speed of the program is the compiler itself. Compiler speed is very important. So with SSA IR, does the compiler get faster or slower?
He asks the audience, “How many people think it gets faster? How many people think it gets slower?” A few more people think it gets faster.
Turns out, the arm compiler is 10% faster. The compiler has more work to do to output SSA IR, but the compiler is now compiled with the new compiler and so itself is more optimized. For arm, the speedup from the compiler binary being generated from SSA IR is larger than the slowdown from the additional computation that needs to be done to output the SSA IR.
The amd64 compiler, on the other hand, is 10% slower. The extra work required by the SSA passes isn’t fully eliminated by the speedup we get from the compiling the compiler using SSA.
So what is SSA?
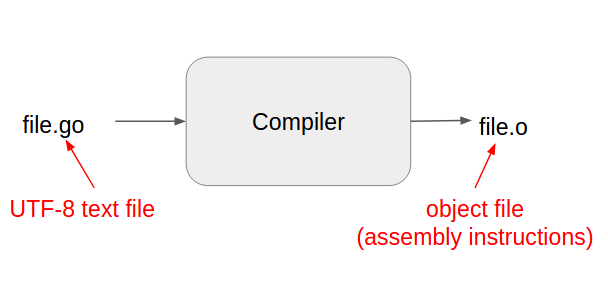
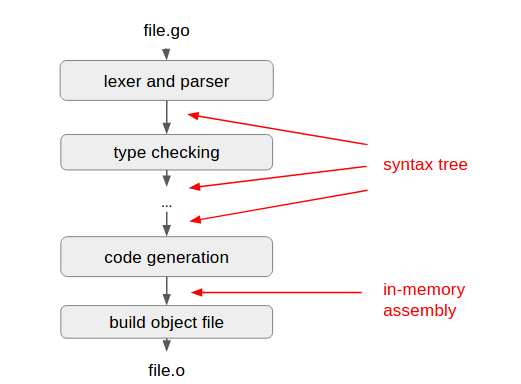
A compiler translates a plaintext source file into an object file that contains assembly instructions:
Internally, the compiler has multiple components that translate the source into successive intermediate representations before finally outputting assembly:
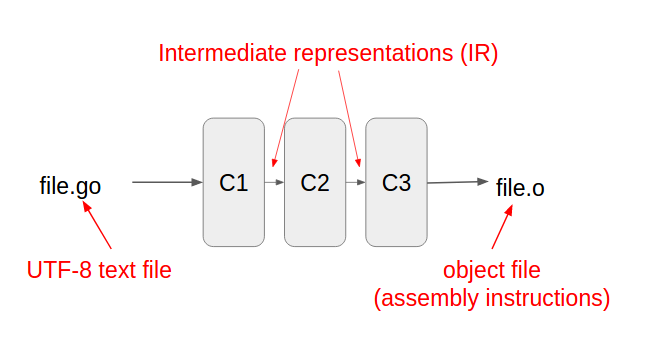
All phases of the Go 1.5 compiler dealt in syntax trees as its internal representation, with the exception of the very last step, which emits assembly:
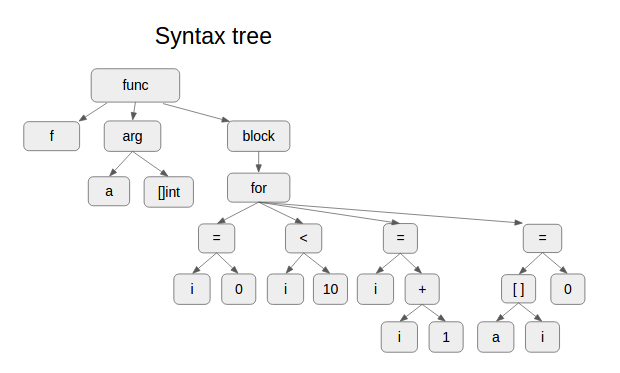
For this code snippet,
func f(a []int) {
for i := 0; i < 10; i++ {
a[i] = 0;
}
}
here’s what the syntax tree looks like:
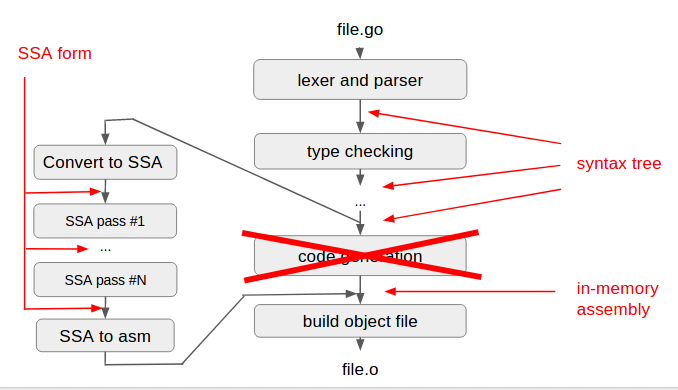
Here are the phases of the Go 1.5 compiler, all of which deal in syntax trees:
- type checking
- closure analysis
- inlining
- escape analysis
- adding temporaries where needed
- introducing runtime calls
- code generation
In the Go 1.7 compiler, SSA replaces the old code generation phase of the compiler with successive SSA passes:
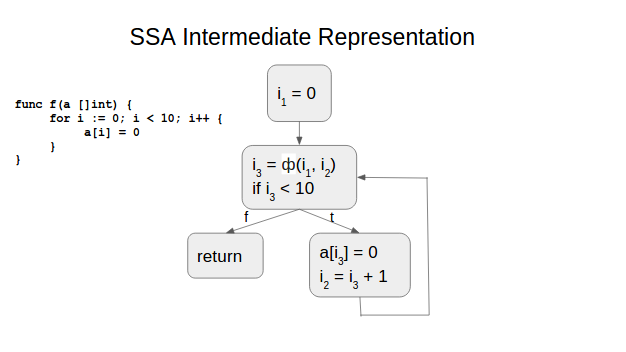
So, what does “SSA” actually mean? SSA stands for “Single Static Assignment” and it means each variable in the program only has one assignment in the text of the program. Dynamically, you can have multiple assignments (e.g., an increment variable in a loop), but statically, there is only one assignment. Here’s a simple conversion from original source to SSA form:
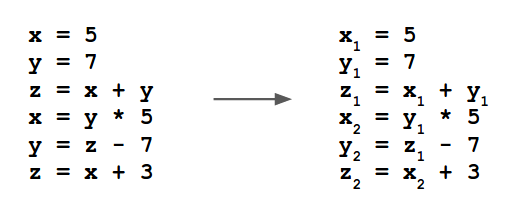
Sometimes, it’s not as simple as the example above. Consider the case of an assignment within a conditional block. It’s not clear how to translate this to SSA form. To solve this problem, we introduce a special notation, Φ:

Here’s the SSA representation embedded in a control flow graph:
Here’s just the control flow graph.
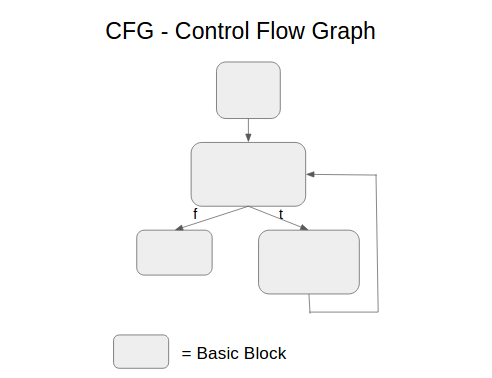
The control flow graph represents flow of logic in your code much better than a syntax tree (which just represents syntax containment). The SSA control flow graph enables a bunch of optimization algorithms, including:
- Common Subexpression Elimination
- Dead Code Elimination
- Dead Store Elimination: get rid of
storeoperations that are immediately overwritten - Nil Check Elimination: can often statically prove some nil checks are unnecessary
- Bounds Check Elimination
- Register allocation
- Loop rotation
- Instruction scheduling
- and more!
Consider the case of common subexpression elimination. If you’re dealing with a syntax tree, it’s not clear whether we can eliminate a subexpression in this example:

With SSA, however, it is clear. In fact, many optimizations can be reduced to simple (and not-so-simple) rewrite rules on the SSA form. Rules like:
(Mul64 x (Const64 [2])) -> (Add64 x x)
Here’s a rewrite rule that lowers machine-independent operations to machine-dependent operations:
(Add64 x y) -> (ADDQ x y)
Rules can also be more complicated:
(ORQ
s1:(SHLQconst [j1] x1:(MOVBload [i1] {s} p mem))
or:(ORQ
s0:(SHLQconst [j0] x0:(MOVBload [i0] {s} p mem))
y))
&& i1 == i0+1
&& j1 == j0+8
&& j0 % 16 == 0
&& x0.Uses == 1
&& x1.Uses == 1
&& s0.Uses == 1
&& s1.Uses == 1
&& or.Uses == 1
&& mergePoint(b,x0,x1) != nil
&& clobber(x0)
&& clobber(x1)
&& clobber(s0)
&& clobber(s1)
&& clobber(or)
-> @mergePoint(b,x0,x1) (ORQ (SHLQconst [j0] (MOVWload [i0] {s} p mem)) y)
This rule takes two 8-bit loads and replaces it with one 16-bit load if it can. The bulk of it describes different cases where such a translation can occur.
Rewrite rules make incorporating optimizations into new ports easy. Rules for most optimizations (e.g., common subexpression elimination, nil check elimination, etc.) are the same across architectures. The only rules that need to change are really the opcode lowering rules. It took a year to write the first SSA backend for amd64. Subsequent backends for arm, arm64, mips, mips64, ppc64, s390x, x86 only took 3 months.
The future
There’s still potentially lots to do to improve the SSA implementation in the Go compiler:
- Alias analysis
- Store-load forwarding
- Better dead store removal
- Devirtualization
- Better register allocation
- Better code layout
- Better instruction scheduling
- Lifting loop invariant code out of loops
They would like help creating better benchmarks against which to test. They are committed to only releasing optimizations that observably benefit real-world use cases.
有疑问加站长微信联系(非本文作者)



