今天简单记录一下弹幕服务器的设计思路,希望对大家有所帮助。
业务特点
弹幕典型的进少出多场景,一个房间如果有10W观众,每秒提交的弹幕也许只有1000次,但是广播弹幕给所有观众需要1000 * 10W次。
单机模型
为了推送消息,长连接几乎是必然的选择。
每个房间有若干观众,所有房间的观众都连接在1个服务进程上。
当弹幕提交上来,根据房间找出所有房间内的在线用户,循环将弹幕推送给他们。
假设1个服务进程的消息网络吞吐能力是50万次/秒,那么一个10万观众的房间,每秒提交5次弹幕就会达到服务端极限性能。
多机模型
假设一个直播间仍旧有10万人在线,希望解决每秒5次弹幕就达到性能瓶颈的问题,很容易想到能否横向扩展解决。
假设现在有2台服务器,10万人均匀连接在2台服务器上,也就是一台有5万人在线。
现在任意用户发送1条弹幕到A服务器,那么A服务器推送5万次,并且将弹幕转发给B服务器,B服务器也只需要推送5万次。
假设要达到A,B服务器的极限,只需要每秒有10条弹幕即可。。。那么横向扩展的收益就这么小吗?
显然有更不为人知的秘密存在。
批量模型
实际上,如果每个弹幕推送都作为一个独立的tcp包发送,那么网卡将很快达到瓶颈,因为几乎每个包都要经过一次内核中断交付给网卡,从而送出到网络中,这对网卡是不友好的。
根据实测经验,万兆网卡的每秒发包量大约在100-200万之间,之前我举例说50万次/秒实际说的比实际情况少一些。
如果可以减少网络发包的次数,那么就可以解决网卡的瓶颈,从而突破每秒广播50万人次弹幕的瓶颈。
思路就是批量,可以将原本要立即发送给观众的弹幕缓存起来,每间隔1秒将这些缓存的弹幕作为一个整体,发送给各个观众的tcp连接。
在这样的实现下,无论每秒是50条弹幕还是10000条弹幕提交到服务端,每秒的推送网络调用次数都是10万人次,也就是按秒为单位聚合弹幕,这样网络调用次数只与在线观众数相关了。
依旧是之前的服务器性能(极限每秒50万次网络调用),那么可以支撑50万观众同时在线,每秒将1秒内缓存的弹幕作为整体发送给50万观众,也就是这一秒只有50万次的网络调用,在网卡的承受范围之内。
在网络这一块来说,通过增加单次发送包的大小可以减少发包数量,提升带宽利用率,每秒送达的弹幕数量并没有受到影响(虽然每秒能够发出的包个数少了,但是单个包内有很多弹幕,总体保持不变),即延迟换吞吐。
接下来呢
从bilibili的弹幕服务压测数据来看,单个服务器单机每秒下发3500万+弹幕,承载大约100万的在线观众,单次发送打包的弹幕数量大约是3500万/100万=35条的样子,也就是每秒35条弹幕提交到服务端,然后打包广播给所有观众,带宽成为了瓶颈。
在观众数量不变的情况下,即便每秒提交10000条弹幕,那么瓶颈也只在带宽(推送的打包变大了)和CPU(聚合消息),只要观众数量变成80万,那么带宽又将有更多的冗余,CPU也会相应降低。
整个弹幕系统的瓶颈再也并不是每秒的弹幕数量了,而是观众数量决定:
每秒网络发送的次数=观众数量!=弹幕数量
这是很重要的结论!通过增加服务器均分观众,那么每台服务器每秒的推送次数就可以减少,只要集群有足够大的出口带宽,那么一切都不是问题!
架构
设计系统都讲究无状态,这样做复杂度最低。
其实弹幕本质算是IM系统,IM系统一般支持1对1,1:N的聊天方式。
IM系统在扩展性方面有一些惯例,下面基于bilibili的弹幕架构简单说说原理。
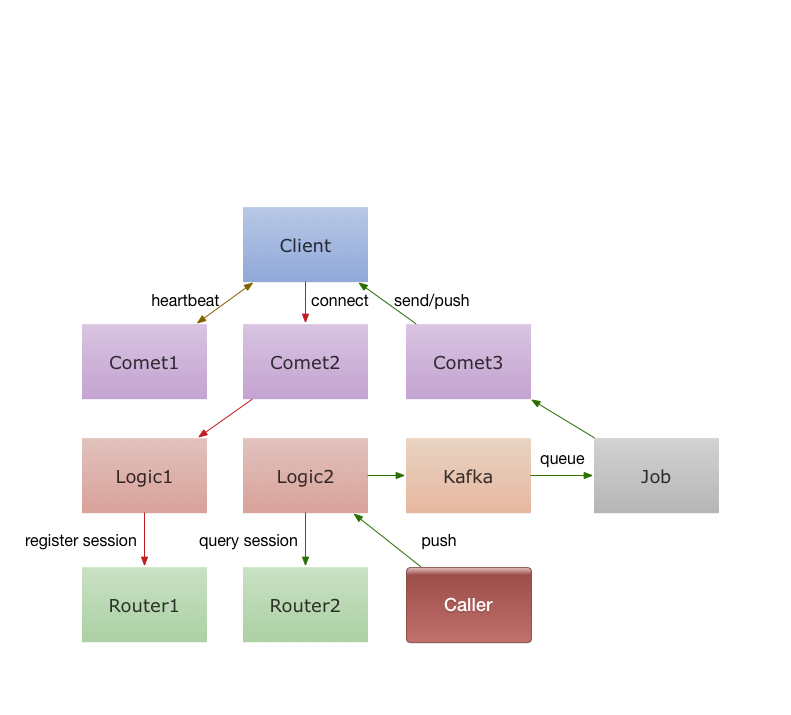
comet是网关,无状态,负责客户端长连接和消息收发。
logic是逻辑服务器,无状态,做业务逻辑用,保持comet逻辑单一高性能。
router有状态(内存状态),logic通过用户uid一致性哈希保存用户的会话信息在某个router。
一个uid可以进入多个房间,建立多条连接到不同comet,而每个直播间在不同服务器上都可能有用户在线。
用户向房间发弹幕直接通过HTTP协议调用logic服务,而logic直接发给kafka,由job服务消费广播给所有Comet。
用户也可以定向发送消息,可能直接发给个人,发给某个房间,发给全部房间。
发消息给个人的话logic查询router,获取uid在哪些server上的哪些room。然后向kafka上推送一条记录,由job服务将消息广播给这些server上的room,这样无论该用户在N个直播间里任意一个都可以看到推送。
发送全部房间和发送一个房间类似,就是由job广播给所有comet,然后每个Comet给所有用户发消息。
性能
其实推送有个程序设计问题,就是要推送的用户量很大,而用户频繁的在上线与下线,因此在线用户集合是上锁的。
推送就要遍历集合,所以很矛盾。
这个问题只能通过拆分集合实现,每个集合只维护部分用户,通过UID哈希分片。
推送消息时,逐个遍历每个小集合上锁处理。推送某个房间也是类似的,只需要遍历每个小集合,在小集合里找出对应房间的用户即可。
扩展阅读
bilibili的弹幕系统是开源的,感兴趣可以详细分析他的代码,用的是golang标准库的rpc,额外依赖了kafka,整体设计还是不算复杂的。
github:https://github.com/Terry-Mao/goim/
博客:http://geek.csdn.net/news/detail/96232
有疑问加站长微信联系(非本文作者)



