结构体:
1、用来自定义复杂数据结构
2、struct里面可以包含多个字段(属性)
3、struct类型可以定义方法,注意和函数的区分
4、strucr类型是值类型
5、struct类型可以嵌套
6、go语言中没有class类型,只有struct类型
struct声明:
type 标识符 struct{
field1 type
field2 type
}
例子:
type Student struct{
Name string
Age int
Score int
}
struct中字段访问,和其他语言一样,使用点
例子:
var stu Student //拿结构题定义一个变量
stu.Name=”tony”
stu.Age=18
stu.Score=20
fmt.Printf(“name=%s,age=%d,score=%d”,stu.Name,stu.Age,stu.Sore)
struct定义的三种形式 初始化的三种方式
a、var stu Student
b、var stu *Student=new(Student)
c、var stu *Student=&Student{}
其中b和c返回的都是指向结构体的指针,访问形式如下:
a、stu.Name、stu.Age 和stu.Score 或者(*stu).Name、 (*stu).Age等
如果是指针形式可以用上面的普通的方式访问,其实就自动转化为指针访问的形式
package main
import (
"fmt"
)
type Student struct{
Name string
Age int
score float32
}
func main(){
//声明方式一
var stu Student
stu.Name="hua"
stu.Age=18
stu.score=80
//声明方式二
var stu1 *Student =&Student{
Age:20,
Name:"hua",
}
//声明方式三
var stu3 =Student{
Age:20,
Name:"hua",
}
fmt.Printf(stu1.Name)
fmt.Printf(stu3.Name)
}
struct内存布局

例子:
package main
import(
"fmt"
)
type Student struct{
Name string
Age int
score float32
}
func main(){
var stu Student
stu.Name="hua"
stu.Age=18
stu.score=80
fmt.Print(stu)
fmt.Printf("Name:%p\n",&stu.Name)
fmt.Printf("Age:%p\n",&stu.Age)
fmt.Printf("score:%p\n",&stu.score)
}
{hua 18 80}Name:0xc04204a3a0
Age:0xc04204a3b0
score:0xc04204a3b8
这里int32是4字节,64是8字节
链表的定义:
type Student struct{
name string
next* Student
}
每个节点包含下一个节点的地址,这样把所有的节点串起来,通常把链表中的每一个节点叫做链表头
遍历到最后一个元素的时候有个特点,就是next这个指针指向的是nil,可以从这个特点来判断是否是链表结束
单链表的特点:只有一个字段指向后面的结构体
单链表只能从前往后遍历
双链表的特点:有两个字段,分别指向前面和后面的结构体
双链表可以双向遍历
链表操作:
1、生成链表及遍历链表操作
package main
import (
"fmt"
)
type Student struct{
Name string
Age int
Score float32
next *Student
}
func main(){
var head Student
head.Name="hua"
head.Age=18
head.Score=80
var stu1 Student
stu1.Name="stu1"
stu1.Age=20
stu1.Score=100
head.next=&stu1
//遍历
var p *Student=&head //生成p指针,指向head
for p!=nil{ //这里p就是head结构体,所以要从第一个遍历
fmt.Println(*p)
p=p.next
}
}
D:\project>go build go_dev / example/example3
D:\project>example3.exe
{hua 18 80 0xc042078060} 这里第三个值指向的是下一个结构体
{stu1 20 100 <nil>}
上面的程序不规范,修改如下:
package main
import (
"fmt"
)
type Student struct{
Name string
Age int
Score float32
next *Student
}
func trans(p *Student){
for p!=nil { //这里p就是head结构体,所以要从第一个遍历
fmt.Println(*p)
p = p.next
}
}
func main(){
var head Student
head.Name="hua"
head.Age=18
head.Score=80
var stu1 Student
stu1.Name="stu1"
stu1.Age=20
stu1.Score=100 //这里默认第二个链表为nil
head.next=&stu1
//var p *Student=&head
trans(&head) //生成p指针,指向head
}
插入链表的方法:
1、尾部插入法,就在链表的尾部插入结构体
代码如下:
package main
import(
"fmt"
)
type Student struct{
Name string
Age int
Score float32
next *Student
}
func trans(p *Student){
for p!=nil { //这里p就是head结构体,所以要从第一个遍历
fmt.Println(*p)
p = p.next
}
}
func main() {
var head Student
head.Name = "hua"
head.Age = 18
head.Score = 80
var stu1 Student
stu1.Name = "stu1"
stu1.Age = 20
stu1.Score = 100
var stu2 Student
stu2.Name="stu2"
stu2.Age=22
stu2.Score=90
head.next=&stu1
stu1.next=&stu2
trans(&head)
}
2、尾部循环插入
package main
import (
"fmt"
"math/rand"
)
type Student struct{
Name string
Age int
Score float32
next *Student
}
func trans(p *Student){
for p!=nil { //这里p就是head结构体,所以要从第一个遍历
fmt.Println(*p)
p = p.next
}
}
//尾部循环插入数据
func trans2(tail *Student){
for i:=0;i<10;i++{
stu:=&Student{
Name:fmt.Sprintf("stu%d",i),
Age:rand.Intn(100),
Score:rand.Float32()*100,
}
//注意下面的是指针
tail.next=stu //链表是指向下一个
tail=stu //更新最后一个链表
}
}
func main(){
var head Student
head.Name="hua"
head.Age=18
head.Score=100
//下面这两个都是根据head这个链表结构体产生
trans2(&head)
trans(&head)
}
3、头部插入
1、注意给指针分配内存空间
2、用指针的方式才可以分配内存,如果用变量就不行(牵扯到地址就用指针)
package main
import(
"fmt"
"math/rand"
)
type Student struct{
Name string
Age int
Score float32
next *Student
}
func trans(p *Student){
for p!=nil{
fmt.Println(*p)
p=p.next
}
}
func main(){
//因为这是指针,所以要给指针分配空间,下面是给指针分配内存空间的两种方法
//var head *Student=&Student{}
var head *Student=new(Student)
head.Name="hua"
head.Age=18
head.Score=100
//从头插入
for i:=0;i<10;i++{
stu:=Student{
Name:fmt.Sprintf("stu%d",i),
Age:rand.Intn(100),
Score:rand.Float32()*100,
}
//头部插入必须要传递指针才可以,首先头部插入一个,链表指向第一个,但是插入的链表地址被覆盖
stu.next=head
head=&stu //指针赋值
}
trans(head)
}
头部插入和尾部插入的区别是
头部插入:需要用指针的方式来插入
尾部插入:直接插入就可以了(变量形式插入)
优化代码
package main
import(
"fmt"
"math/rand"
)
type Student struct{
Name string
Age int
Score float32
next *Student
}
//打印函数
func trans(p *Student){
for p!=nil{
fmt.Println(*p)
p=p.next
}
}
//这里的head是指针变量副本,这里要接受指针的指针,head1 * Student是指针变量的副本
func insertHead(head1 **Student){
//从头插入
for i:=0;i<10;i++ {
stu := Student{
Name: fmt.Sprintf("stu%d", i),
Age: rand.Intn(100),
Score: rand.Float32() * 100,
}
//因为参数是指针的指针,所以这里要传递指针的指针,
stu.next = *head1
*head1 = &stu
}
}
func main(){
var head *Student=new(Student)
head.Name="hua"
head.Age=18
head.Score=100
//因为这个函数要改变指针变量的值,所以要传递指针的地址进去
insertHead(&head)
trans(head)
}
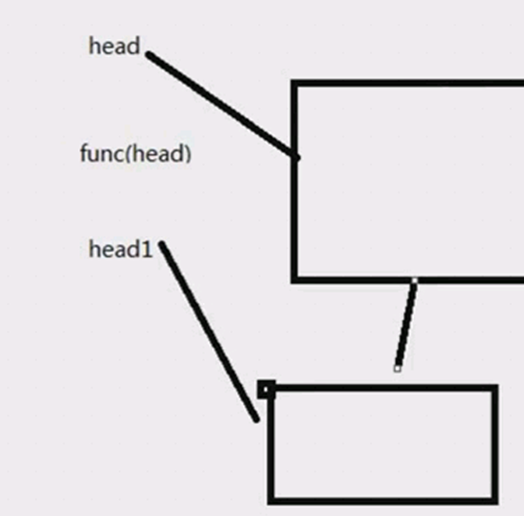
理解:
如下:这里的insertHead中的head1是head的副本,开始head1和head是指向同一个内存地址,当head1=&stu的时候head1的地址,也就是head的副本的地址就变化了,但是head还是没有变化的。所以要改变指针的地址,也就是head的地址,这里函数必须要传递指针的指针才可以,在指针的基础之上多加一个*,
func insertHead(head1 **Student){}
然后传递的时候要传递指针的地址,如 insertHead(* head)
小结: 要改变指针变量的值,就要传递指针的指针进去
指针还有二级指针,三级指针等
删除链表
删除指定节点:
思路:
1、遍历,
2、遍历当前节点的上个节点的next等于当前节点的下一个节点,这个节点就删除了
3、如果第一次没有找到,那么就往后移动位置,即当前节点的上级节点等于当前节点,当前节点的下一个节点赋值给当前节点,
4、下面这个代码是有问题的,主要是这是一个副本。头部插入会有问题
代码:
package main
import (
"fmt"
"math/rand"
)
type Student struct{
Name string
Age int
Score float32
next *Student //指向下一个节点
}
func trans(p *Student) {
for p!=nil{
fmt.Println(*p)
p=p.next
}
}
//头部插入
func insertHead(head **Student){
//从头插入
for i:=0;i<10;i++ {
stu := Student{
Name: fmt.Sprintf("stu%d", i),
Age: rand.Intn(100),
Score: rand.Float32() * 100,
}
//因为参数是指针的指针,所以这里要传递指针的指针,
stu.next = *head
*head = &stu
}
}
func delNode(p * Student){
//临时变量保存上一个节点
var prev *Student=p
/*
遍历链表
1、首先判断当前链表节点是否等于要删除的链表,如果是那么把当前链表节点上一个节点等于
当前链表节点的下一个节点
2、如果没有找到,那么当前链表节点就等于上个节点,当前链表节点就指向下个节点,也就是往后移动位置
*/
for p!=nil{
if p.Name=="stu6"{
prev.next=p.next
break
}
//如果没有找到,那么p就等于上个节点,p就指向下个节点
prev=p
p=p.next
}
}
func main(){
var head *Student=new(Student)
head.Name="hua"
head.Age=18
head.Score=100
insertHead(&head)
delNode(head)
trans(head)
}
怎么在上面stu6后面插入一个节点?
思路:
1、首先生成一个节点,让这个节点的下一个节点等于stu6的下一个节点
2、再让stu6的下一个节点指向插入的这个节点
package main
import (
"fmt"
"math/rand"
)
type Student struct{
Name string
Age int
Score float32
next *Student //指向下一个节点
}
func trans(p *Student) {
for p!=nil{
fmt.Println(*p)
p=p.next
}
}
//头部插入
func insertHead(head **Student){
//从头插入
for i:=0;i<10;i++ {
stu := Student{
Name: fmt.Sprintf("stu%d", i),
Age: rand.Intn(100),
Score: rand.Float32() * 100,
}
//因为参数是指针的指针,所以这里要传递指针的指针,
stu.next = *head
*head = &stu
}
}
func delNode(p * Student){
//临时变量保存上一个节点
var prev *Student=p
/*
遍历链表
1、首先判断当前链表节点是否等于要删除的链表,如果是那么把当前链表节点上一个节点等于
当前链表节点的下一个节点
2、如果没有找到,那么当前链表节点就等于上个节点,当前链表节点就指向下个节点,也就是往后移动位置
*/
for p!=nil{
if p.Name=="stu6"{
prev.next=p.next
break
}
//如果没有找到,那么p就等于上个节点,p就指向下个节点
prev=p
p=p.next
}
}
//在stu5后面插入一个链表
func addNode(p *Student,newNode * Student){
for p!=nil{
if p.Name=="stu5"{
newNode.next=p.next
p.next=newNode
break
}
p=p.next
}
}
func main(){
var head *Student=new(Student)
head.Name="hua"
head.Age=18
head.Score=100
insertHead(&head)
delNode(head)
trans(head)
var newNode *Student=new(Student)
newNode.Name="stu1000"
newNode.Age=18
newNode.Score=100
addNode(head,newNode)
trans(head)
}
双向链表
定义 type Student struct{
Name sring
next * Student
prevn * Student
}
如果有两个指针分别指向前一个节点和后一个节点,我们叫做双链表
二叉树
定义:
type Student struct{
Name string
left * Student
right *Student
}
如果每个节点有两个指针分别用来指向左子树和右子树,我们把这样的结构叫做二叉树
对于二叉树,要用到广度优先或者深度优先的递归算法
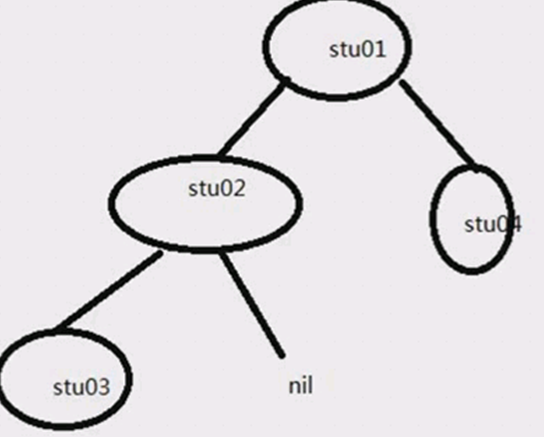
下面是二叉树的类型图,下面的stu2的右边的孩子也可以是为nil,然后stu3如果没有孩子就叫做叶子节点,stu02是stu01的子树
代码:
下面采用递归的形式进行遍历二叉树,下面是深度优先的原理
如果要采取广度优先,那么每次遍历的时候就要把结果放到队列里面
前序遍历:是从根节点开始遍历的


package main import( "fmt" ) //声明二叉树 type Student struct{ Name string Age int Score float32 left *Student right *Student } func trans(root *Student){ if root==nil{ return } fmt.Println(root) //递归遍历左子树 trans(root.left) //递归然后遍历右子树 trans(root.right) } func main(){ //初始化root定点 var root *Student=new(Student) root.Name="stu01" root.Age=18 root.Score=100 root.left=nil //初始化 root.right=nil var left1 *Student=new(Student) left1.Name="stu02" left1.Age=19 left1.Score=100 //把这个节点插入到root的左边 root.left=left1 var right1 *Student=new(Student) right1.Name="stu04" right1.Age=19 right1.Score=100 //把这个节点插入到root的右边 root.right=right1 var left02 *Student=new(Student) left02.Name="stu03" left02.Age=18 left02.Score=100 //把这个节点插入到left1的左边 left1.left=left02 trans(root) } /* 下面结果分别是,Name Age Score 然后左边和右边的地址 &{stu01 18 100 0xc042082090 0xc0420820c0} &{stu02 19 100 0xc0420820f0 <nil>} &{stu03 18 100 <nil> <nil>} &{stu04 19 100 <nil> <nil>} */ 中序遍历:先遍历左子树,然后遍历根节点,然后遍历右节点 package main import( "fmt" ) //声明二叉树 type Student struct{ Name string Age int Score float32 left *Student right *Student } func trans(root *Student){ if root==nil{ return } //中序遍历 trans(root.left) fmt.Println(root) trans(root.right) /* 结果 &{stu03 18 100 <nil> <nil>} &{stu02 19 100 0xc0420820f0 <nil>} &{stu01 18 100 0xc042082090 0xc0420820c0} &{stu04 19 100 <nil> <nil>} */ } func main(){ //初始化root定点 var root *Student=new(Student) root.Name="stu01" root.Age=18 root.Score=100 root.left=nil //初始化 root.right=nil var left1 *Student=new(Student) left1.Name="stu02" left1.Age=19 left1.Score=100 //把这个节点插入到root的左边 root.left=left1 var right1 *Student=new(Student) right1.Name="stu04" right1.Age=19 right1.Score=100 //把这个节点插入到root的右边 root.right=right1 var left02 *Student=new(Student) left02.Name="stu03" left02.Age=18 left02.Score=100 //把这个节点插入到left1的左边 left1.left=left02 trans(root) } 后序遍历:首先遍历左子树,然后遍历右子树,最后遍历根节点 package main import( "fmt" ) //声明二叉树 type Student struct{ Name string Age int Score float32 left *Student right *Student } func trans(root *Student){ if root==nil{ return } //后序遍历 trans(root.left) trans(root.right) fmt.Println(root) /* 结果 &{stu03 18 100 <nil> <nil>} &{stu02 19 100 0xc04206e0f0 <nil>} &{stu04 19 100 <nil> <nil>} &{stu01 18 100 0xc04206e090 0xc04206e0c0} */ } func main(){ //初始化root定点 var root *Student=new(Student) root.Name="stu01" root.Age=18 root.Score=100 root.left=nil //初始化 root.right=nil var left1 *Student=new(Student) left1.Name="stu02" left1.Age=19 left1.Score=100 //把这个节点插入到root的左边 root.left=left1 var right1 *Student=new(Student) right1.Name="stu04" right1.Age=19 right1.Score=100 //把这个节点插入到root的右边 root.right=right1 var left02 *Student=new(Student) left02.Name="stu03" left02.Age=18 left02.Score=100 //把这个节点插入到left1的左边 left1.left=left02 trans(root) }
结构体与方法
结构体是用户单独定义的类型,不能和其他类型进行强制转换
type Student struct{
Number int
}
type Stu Student //alias 别名 type 变量 类型 这个是定义类型的别名
var a Student
a=Student{30}
var b Stu
a=b //这样赋值错误
a=Student(b) //这样才可以
上面这两个Stu和Student是别名关系,但是这两个字段一样,并不是同一个类型,因为是type定义的
如:
package main
import (
"fmt"
)
type integer int
func main(){
//赋值给谁呢么类型,就要强制转换成什么类型
var i integer=1000
fmt.Println(i)
var j int=100
//这里i是自定义的类型, j是int类型,所以赋值的时候要强制转换,如下
j=int(i) //i如果赋值给j应该强制转换为int类型
i=integer(j) //j如果想复制给i必须转换为integer类型
fmt.Println(i)
fmt.Println(j)
}
工厂模式
golang中的struct没有构造函数,一般可以使用工厂模式来解决这个问题
Package model
type student Struct{
Name string
Age int
}
func NewStudent(name string,age int)*Student{
return &Student{ //创建实例
Name:name
Age:age
}
}
Package main
S:new(student)
S:model.NewStudent(“tony”,20)
再次强调
make用来创建map,slice ,channel
new 用来创建值类型
struct中的tag
我们可以为strct中的每一个字段,协商一个tag,这个tag可以通过反射机制获取到,最常用的场景就是json序列化和反序列化
type student struct{
Name string “this is name field” //每个字段写一个说明,作为这个字段的描述
Age int “this is age field”
}
json打包
json.Marshal()
注意:
json打包的时候,
1、必须要把结构体中的字段大写,才可以
下面是程序声明打包初始化的两种方式
package main
import(
"encoding/json"
"fmt"
)
type Student struct{
Name string `json:"Student_name"`
age int `json:"student_age"`
score int `json:score`
}
func main(){
//声明
var stu Student=Student{
Name:"stu01",
age:10,
score:100,
}
data,err:=json.Marshal(stu) //打包,返回值为byte
if err!=nil{
fmt.Println("json encode stu faild,err",err)
return
}
fmt.Println(string(data)) //把byte转化成string
}
//{"Student_name":"stu01"}
也可以下面的方式书写
package main
import(
"encoding/json"
"fmt"
)
type Student struct{
Name string `json:"Student_name"`
age int `json:"student_age"`
score int `json:score`
}
func main(){
//初始化
var stu *Student=new(Student)
stu.Name="stu01"
data,err:=json.Marshal(stu) //打包,返回值为byte
if err!=nil{
fmt.Println("json encode stu faild,err",err)
return
}
fmt.Println(string(data)) //把byte转化成string
}
//{"Student_name":"stu01"}
匿名字段
结构体 中字段可以没有名字,叫做匿名字段
type Car struct{
Name string
Age int
}
type Train struct{
Car //匿名字段
Start time.Time //有名字段
int //匿名字段
}
匿名字段要怎么访问呢?
package main
import (
"fmt"
"time"
)
type Cart struct{
name string
age int
}
type Train struct{
Cart
int
strt time.Time
}
func main(){
var t Train
//正规写法
t.Cart.name="001"
t.Cart.age=11
//上面的正规写法可以缩写成下面的写法
t.name="001"
t.age=11
t.int=200
fmt.Println(t)
}
匿名字段冲突处理

对于上面的1这里有优先原则:
缩写形式,如果有两个结构体中有相同的字段,会优先找本身的字段
对于上面的2,必须要手动的指定某个字段才可以,不然会报错
方法:
golang中的方法是作用在特定类型的变量上,因此自定义类型,都可以有方法,而不仅仅是struct
定义: func (recevier type ) methodName(参数列表)(返回值列表){}
package main
import(
"fmt"
)
type Student struct{
Name string
Age int
Score int
sex int
}
func (p *Student) init(name string,age int,){
p.Name=name
p.Age=age
fmt.Println(p)
}
func (p Student) get() Student{
return p
}
func main(){
var stu Student
//由于这里传递指针才可以,正规写法应该是下面
(&stu).init("stu",10)
//但是由于go做了优化,只有在结构体方法中才可以用下面的方法
stu.init("stu",10)
stu1:=stu.get()
fmt.Println(stu1)
}
/*
&{stu 10 0 0}
&{stu 10 0 0}
{stu 10 0 0}
*/
方法的调用这里需要注意两点
1、任何自定义类型都有方法
2、在注意调用的时候的方法,注意指针才改变值
package main
import (
"fmt"
)
type integer int
func (p integer)print(){
fmt.Println(p)
}
//这里由于传递的是副本,所以无法改变值
func (p integer)set(b integer){
p=b
}
//这里直接传递的指针,所以可以改变
func (p *integer)get(b integer){
*p=b
}
func main(){
var a integer
a=100
a.print()
a.set(1000)
a.print()
//下面是(&a).get的缩写形式
a.get(1000)
a.print()
}
方法的调用
type A struct{
a int
}
func (this A)test(){
fmt.Println(this.a)
}
var t A
t.test()
上面的this就是下面的t,通过上面方法中的参数this.A就能获取当前结构体中的实例
方法和函数的区别:
1)函数调用 :function(variable,参数列表)
2)‘方法 variable.function(参数列表)
指针receiver vs值receiver
本质上和函数的值传递和地址传递是一样的
方法的访问控制,通过大小写控制
继承
如果一个struct潜逃了另一个匿名结构体,那么这个结构可以直接访问匿名结构体的方法,从而实现了继承
如:
package main
import (
"fmt"
"time"
)
type Cart struct{
name string
age int
}
type Train struct{
Cart
int
strt time.Time
age int
}
func main(){
var t Train
//正规写法
t.Cart.name="001"
t.Cart.age=11
//上面的正规写法可以缩写成下面的写法
t.name="001"
t.age=11
t.int=200
fmt.Println(t)
}
这里的Train继承了Cart,Cart为父类,然后Train里面有Cart的所有的方法
下面是方法的继承
package main
import (
"fmt"
)
type Car struct{
weight int
name string
}
func (p *Car) Run(){
fmt.Println("running")
}
type Bike struct{
Car
lunzi int
}
type Train struct{
Car
}
func main(){
var a Bike
a.weight=100
a.name="bike"
a.lunzi=2
fmt.Println(a) //{{100 bike} 2}
a.Run() //running
var b Train
b.weight=1000
b.name="train"
b.Run() //running
}
这里a和b都继承了Car父类中的Run方法
总结,匿名函数可以继承字段也可以继承方法
组合和匿名函数
如果一个struct嵌套了另一个匿名结构体,那么这个结构体可以直接访问匿名结构体的方法,从而实现了继承
如果一个struct嵌套了另一个有名结构体,那么这个模式就叫做组合(一个结构体嵌套另一个结构体)
也可以说匿名字段是特殊的组合
package main
import (
"fmt"
)
type Car struct{
weight int
name string
}
func (p *Car) Run(){
fmt.Println("running")
}
type Train struct{
c Car
}
func main(){
var b Train
b.c.weight=1000
b.c.name="train"
b.c.Run() //running
}
如上就是组合
多重继承
如果一个struct嵌套了多个匿名结构体,那么这个结构可以直接访问多个匿名结构体的方法,从而实现了多重继承
如果冲突的话,就需要带上结构体的名字来访问
实现String() 这是一个接口
如果一个变量实现了String()这个方法,那么fmt.Println默认会调用变量String()进行输出
go里面只要实现了接口这个方法,那么就实现了这个接口,相当于鸭子类型
package main
import (
"fmt"
)
type Cart struct{
weight int
name string
}
type Train struct{
Cart
}
func (p *Cart) Run(){
fmt.Println("running")
}
func (p *Train)String() string{
str:=fmt.Sprintf("name=[%s] weight=[%d]",p.name,p.weight)
return str
}
func main(){
var b Train
b.weight=100
b.name="train"
b.Run()
//这个是字符串的接口所以需要格式化才会调用这个接口,这个是指针型的
fmt.Printf("%s",&b)
}
有疑问加站长微信联系(非本文作者)




