一、总体内容
1、内置函数、递归函数、闭包
2、数组和切片
3、map数据结构
4、package介绍
一、内置函数
注意:值类型用new来分配内存,引用类型用make来分配内存
1、close:主要用来关闭channel
2、len:用来求长度,比如string、array、slice、map、channel
3、new:用来分配内存,主要用来分配值类型,比如int、struct、浮点型。返回的是指针
代码案例
package main
import(
"fmt"
)
func main(){
var i int
fmt.Println(i) //0
j:=new(int) //返回的是地址,也就是指针
*j=100 //因为是指针,所以要这样赋值
fmt.Println(*j) //100
}
4、make:用来分配内存,主要用来分配引用类型。比如chan、map、slice
5、append:用来追加元素到数组、slice中
package main
import(
"fmt"
)
func main(){
var a [] int
a=append(a,10,20,30)
fmt.Println(a) //[10 20 30]
}
合并两个slice
package main
import(
"fmt"
)
func main(){
var a [] int
a=append(a,10,20,30)
a=append(a, a...) //后面的三个点,是展开,这个append是合并
fmt.Println(a)
}
注意这里的三个点的作用是展开
6、panic和recover:用来做错误处理
panic可以快速定位到哪里出错了
捕获异常的原因是因为上线项目之后不能够随便的停止,所以要捕获
package main
import(
"fmt"
"time"
)
func test(){
defer func(){
if err:=recover();err !=nil{ //这里捕获下面的系统的异常
fmt.Println(err) //这里的错误没有指定哪一行出错了。这里可以把堆栈打印出来
//捕获了异常之后下面可以继续写上报警的接口或者写到日志里面
}
}()
b:=0
a:=100/b //这里系统抛了一个异常,上面来捕获
fmt.Println(a)
return
}
func main(){
for {
test()
time.Sleep(time.Second) //这里是休息1秒,参数是一个常量
}
var a [] int
a=append(a,10,20,30)
a=append(a, a...)
fmt.Println(a) //[10 20 30]
}
D:\project>go build go_dev/day4/example/example2
D:\project>example2.exe
runtime error: integer divide by zero
runtime error: integer divide by zero。
还可以自己手动的通过pinic来捕获异常
package main
import(
"fmt"
"errors"
)
func initConfig()(err error){ //这里是命名返回值
return errors.New("init config failed") //初始化error这个实例
}
func test(){
err :=initConfig()
if err !=nil{
panic(err) //panic手动的捕获这个异常,这样就能知道程序的哪里出错了
}
return
}
func main(){
test()
var a [] int
a=append(a,10,20,30)
a=append(a, a...)
fmt.Println(a) //[10 20 30]
}
D:\project>go build go_dev/day4/example/example2
D:\project>example2.exe
panic: init config failed
goroutine 1 [running]:
main.test()
D:/project/src/go_dev/day4/example/example2/main.go:17 +0xb2
main.main()
D:/project/src/go_dev/day4/example/example2/main.go:24 +0x3b
数组:
var a [1]int :这个是确定的长度,为1
var a [] int :这个是切片
new和make的区别
new之后如果是slice等引用类型必须要用make初始化一下才可以用如下:
package main
import(
"fmt"
)
func test(){
s1:=new([] int) //new了这个指针,必须要用make来初始化一下
fmt.Println(s1) //这个返回来一个指针&[]
s2:=make([] int, 2) //这个后面的2是指定容量
fmt.Println(s2) //这个返回来这个数据类型 [0 0 ]
*s1=make([] int,5) //因为s1是一个指针(地址),要想用这个指针必须初始化一下
(*s1)[0]=100 //初始化之后给这个值赋值
fmt.Println(s1) //&[100 0 0 0 0]
s2[0]=100
fmt.Println(s2) //[100 0]
}
func main(){
test()
}
递归函数
一个函数调用自己,就叫做递归
package main
package main
import (
"fmt"
"time"
)
func recusive(n int){
fmt.Println("hello")
time.Sleep(time.Second)
if n>10{ //这个是递归退出的条件
return
}
recusive(n+1) //这个就是递归的自己调用自己
}
func main(){
recusive(0)
}
例子一:计算阶乘


package main import ( "fmt" ) func factor(n int) int { if n==1{ return 1 } return factor(n-1)*n } func main(){ a:=factor(5) fmt.Println(a) } D:\project>go build go_dev/day4/example/example5 D:\project>example5.exe 120
斐波那契数列
package main import( "fmt" ) func fabnaqi(n int) int{ if n<=1 { return 1 } return fabnaqi(n-1)+fabnaqi(n-2) } func main(){ for i:=1;i<10;i++{ fmt.Println(fabnaqi(i)) } } D:\project>go build go_dev/day4/example/example6 D:\project>example6.exe 1 2 3 5 8 13 21 34 55
闭包:
闭包:是一个函数和与其相关作用域的结合体
下面的匿名函数中的变量和x绑定了
package main import ( "fmt" ) //闭包 func Adder() func(int)int{ //这里定义的返回值要和下面的匿名函数一样 //下面的整体才是闭包 var x int //默认为0 return func(d int) int{ //这里匿名函数要和上面返回值类型是一样 x+=d return x } } func main(){ f:=Adder() fmt.Println(f(1)) //这里的f就是执行Adder(),然后f(1),这个就是执行匿名函数,并且传入参数 fmt.Println(f(100)) //101 fmt.Println(f(1000)) //1101 }
例2
package main import ( "fmt" "strings" ) func makeSuffixFunc(suffix string) func (string )string{ return func (name string) string{ //这里的闭包的环境变量是和suffix绑定的 if strings.HasPrefix(name,suffix)==false{ return name+suffix } return name } } func main(){ func1:=makeSuffixFunc(".bmp") func2:=makeSuffixFunc(".jpg") fmt.Println(func1("test")) fmt.Println(func2("test")) }
数组
1、数组:是同一种数据类型的固定长度的序列
2、数组定义:var a [len]int 比如:var a [5] int 一旦定义长度就不会变了
3、长度是数组类型的一部分,因此var a[5]int和var a[10]int 是不同的类型
4、数组可以通过下标进行访问,下标是从零开始的,最后一个元素下标是len-1
遍历的方法如下:
下面是遍历数组的两种方法
package main import ( "fmt" ) func main(){ var a[10] int a[0]=100 for i:=0;i<len(a);i++{ fmt.Println(a[i]) } for _,value:=range a{ fmt.Println(value) } }
5、访问越界,如果下标在数组合法范围之外,则触发越界,会panic
如下,就会在编译的时候报错,也就是pinic了
package main import ( "fmt" ) func main(){ var a[10] int j:=10 a[0]=100 a[j]=200 fmt.Println(a) }
6、数组是值类型,因此改变副本的值,不会改变本身的值
在函数里面改变不会改变外部的值,在函数中改变的知识数组的副本
如果要改变函数中的值,需要通过指针的方式来修改
package main import( "fmt" ) func test(arr *[5] int){ (*arr)[0]=1000 } func main(){ var a [5] int test(&a) fmt.Println(a) // [1000 0 0 0 0] }
数组和切片:
1、练习,使用非递归的方式实现斐波那契数列,打印前100个数
package main
import (
"fmt"
)
func fab(n int){
var a[]uint64
a=make([]uint64 ,n)
a[0]=1
a[1]=1
for i:=2;i<n;i++{
a[i]=a[i-1]+a[i-2]
}
for _,v:=range a{
fmt.Println(v)
}
}
func main(){
fab(10)
}
2、数组初始化
a、var age0 [5]int =[5]int {1,2,3,4,5]
b、var age1=[5] int {1,2,3,4,5]
c、var age2=[…]int {1,2,3,4,5}
d、var str=[5]string{3:”hello word”,4:”tom”}
3、多维数组
a、var age[5][3] int //5行 3 列,第一个行,第二个列
b、var f[2][3] int=[…][3]int {{1,2,3},{7,8,9}}
遍历多维数组
package main import ( "fmt" ) func testArry(){ var a[2][5]int=[...][5]int{{1,2,3,4,5},{6,7,8,9,10}} //前面是行,后面是列 for row,v:=range a{ //首先便利梅行 for col,v1:=range v{ //然后遍历每列 fmt.Printf("(%d,%d)=%d ",row,col,v1) //这里的v1是多维数组的遍历对象 } fmt.Println() } } func main(){ testArry() }
注意这里的切片和数组的区别:
a、声明的时候切片没有长度,数组有长度在中括号中,因为切片是变长的,数组的是长度固定的,切片是引用类型,数组是值类型
1、切片:切片是数组的一个引用,因此切片是引用类型
2、切片的长度可以改变,因此切片是一个可变的数组
3、切片遍历方式和数组一样,可以用len()求长度
4、cap可以求出slice最大的容量,0<= len (slice)<=cap (array),其中array是slice引用的数组
5、切片的定义:var变量名[]切片类型,比如var str []string var arr[] int
package main
import "fmt"
func testSlice(){
var slice [] int
var arr[5]int=[...]int{1,2,3,4,5}
slice=arr[2:5] //数组的切片
fmt.Println(slice)
fmt.Println(len(slice)) //求切片的长度
fmt.Println(cap(slice)) //求切片的容量
slice =slice[0:1] //这个切片引用了另一个切片
fmt.Println(len(slice)) //求新切片的长度
fmt.Println(cap(slice)) //这个还是原来切片的长度
}
func main(){
testSlice()
}
D:\project>go build go_dev/day4/example/slicea
D:\project>slicea.exe
[3 4 5]
3
3
1
3
方法: 切片初始化只能通过切片的方式
1、切片初始化:var slice [] int=arr[start”end].包含start到end之间的元素名不包含end
2、var slice []int=arr[0:end]可以简写为var slice []int=arr[:end]
3、var slice []int=arr[start:len(arr)] 可以简写为var slice[]int = arr[start:]
4、var slice []int=arr[0,len(arr)] 可以简写为var slice[]int=arr[:]
5、如果要切片最后一个元素去掉,可以这样写
slice=slice[:len(slice)-1]
数组和切片定义之后必须要初始化
下面是切片的内存布局 第一个是x的切片布局指针方式指针数组,

上面的第三个切片的地址指向的是数组的第一个元素的地址,如下:
func testslice1(){ var a=[10]int{1,2,3,4,5} b:=a[1:5] //这是一个切片 fmt.Printf("%p\n",b) //打印地址0xc042084008 fmt.Println(&a[2]) //打印地址0xc042084008 } func main(){ testslice1() } 从上面地址可以看到切片地址和第一个元素的地址相同
3、通过make来创建切片

4、用append内置函数操作切片
slice=append(slice,10)
var a=[]int{1,2,3}
var b=[]int{4,5,6}
a=append(a,b…) //这里注意,如果是一个切片的话,append需要后面是…
切片是引用,如果切片的append的大小超过了原来的数组的大小,这个时候就会扩容,可以通过切片和数组的第一个值的地址是否相同来比较
package main import ( "fmt" ) func test(){ var a [2]int=[...]int{1,2} s:=a[1:] fmt.Println(s,&a[1]) s=append(s,10) s=append(s,11) fmt.Printf("%p\n",s) //0xc04200e2a0 fmt.Println(s,&a[1]) //0xc0420080d8 } func main(){ test() }
上面切片的地址和数组的第一个元素的地址不同可以看到,这个切片进行了扩容的方式,新开了一块内存和原来的内存不一样了,这个是内部的算法决定的
5、切片遍历
for index,val :range slice{
}
6、切片resize,切片之后可以再进行切片
var a=[] int{1,2,3}
b:=a[1:2]
b=b[0:3]
7、切片的拷贝
s1:=[]int{1,2,3,4}
s2:=make([]int ,10)
copy(s2,s1)
s3:=[]int{1,2,3}
s3=append(s3,s2…)
s3=append(s3,4,5,6)
8、stringhe slice
string底层就是一个byte的数组,因此,也可以进行切片操作
package main import ( "fmt" ) func test(){ s:="hello world" s1:=s[0:5] fmt.Println(s1) //hello } func main(){ test() }
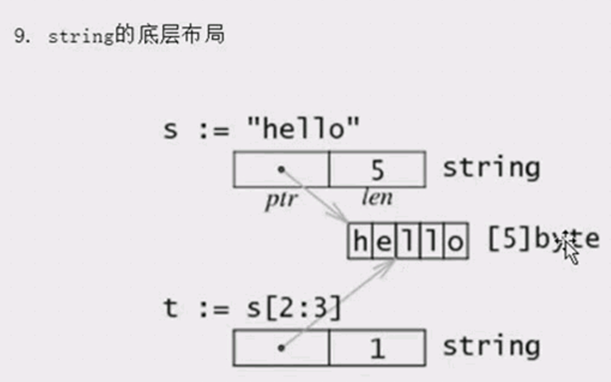
10、如何改变string中的字符串?
string本身是不可变的,因此要改变string中字符,需要如下操作
下面是针对没有中文的情况下:
func test2(){ str:="hello world" s:=[]byte(str) s[0]='o' str=string(s) fmt.Println(str) // oello world } func main(){ test2() } 下面是可以针对中文的情况 func testModify(){ str:="oello world" s:=[]rune(str) s[0]='h' str=string(s) fmt.Println(str) //hello world } func main(){ testModify() }
11、排序和查找操作
排序操作主要在sort包中,导入就可以使用了
import(“sort”)
sort.Ints对整数进行排序,sort.String对字符串进行排序,sort.Float64s对浮点数进行排序
sort.SearchInts(a []int,b int)从数组a中查找b,前提是a必须有序
sort.SearchFloats(a []float64 ,b float64)从数组a中查找b,前提是a必须有序
sort.SearchStrings(a []string,bstring)从数组a中查找b,请安提是a必须有序
下面是对数组进行排序
package main import( "fmt" "sort" ) func test(){ var a=[...]int{1,3,2,21,11,14} //因为这个是数组,所以不能直接排序 sort.Ints(a[:]) //所以这里要针对切片进行排序,因为切片实际引用类型 fmt.Println(a) } func main(){ test() } /* D:\project>go build go_dev/day4/example/example15 D:\project>example15 [1 2 3 11 14 21] */ 下面是对字符串进行排序 func testString(){ var a=[...]string{"abc","efg","b","A","eee"} sort.Strings(a[:]) fmt.Println(a) //[A abc b eee efg] } func main(){ testString() } 下面是对浮点型进行排序 func testFloat(){ var a=[...]float64{1.1,9.7,2.1} sort.Float64s(a[:]) fmt.Println(a) //[1.1 2.1 9.7] } func main(){ testFloat() } 下面是排序的方法 func testIntsearch(){ var a=[...]int{1,8,38,2,348,4} sort.Ints(a[:]) index:=sort.SearchInts(a[:],2) fmt.Println(index) //得到下标为1 } func main(){ testIntsearch() }
map数据结构
一、简介
key-value的数据结构
a、声明,声明是不会分配内存的,初始化需要make
var map1 map[key type]value type
var a map[string]string
var a map[string]int
var a map[int]string
var a map[string]map[string]string
package main import ( "fmt" ) func test(){ var a map[string]string //声明map,但是这里没有申请内存空间,所以必须初始化 a=make(map[string]string,10) //这里初始化,申请内存空间 a["abc"]="efg" fmt.Println(a) //map[abc:efg] } func main(){ test() } 方式二 package main import ( "fmt" ) func test(){ a:=make(map[string]string,10) //这里声明加上初始化,声明然后分配内存空间 a["abc"]="efg" fmt.Println(a) //map[abc:efg] } func main(){ test() } 方法三:不推荐 package main import ( "fmt" ) func test(){ var a map[string]string=map[string]string{ "key":"value", } //var a map[string]string //声明map,但是这里没有申请内存空间,所以必须初始化 //a:=make(map[string]string,10) //这里初始化,申请内存空间 a["abc"]="efg" fmt.Println(a) //map[abc:efg] } func main(){ test() } 多层map嵌套 func testMap2(){ a:=make(map[string]map[string]string,100) //声明 a["key1"]=make(map[string]string) //初始化 a["key1"]["key2"]="abc" a["key1"]["key3"]="abc" fmt.Println(a) } func main(){ testMap2() test() }
map相关的操作
a[“hello”]=”world” 插入和更新
val,ok:=a[“hello”] 查找
for k,v:=range a { 遍历
}
delete (a,”hello”) 删除
len(a) 长度
func test3() { var a map[string]string = map[string]string{"hello": "world"} a = make(map[string]string, 10) a["hello"] = "world" //插入和更新 val,ok:=a["hello"] //查找 if ok{ fmt.Println(val) } for k,v :=range a { //遍历 fmt.Println(k,v) } } func main(){ test3() }
排序:
map排序,map的排序是无序的:
a、先获取所有key,把key进行排序
b、按照排好的key,进行遍历
package main import( "fmt" "sort" ) func test(){ var a map[int]int //声明 a=make(map[int]int,5) //初始化,加入内存 a[8]=10 a[3]=11 a[2]=10 a[1]=10 a[18]=10 var keys []int //创建一个切片 for k,_:=range a{ keys=append(keys,k) } sort.Ints(keys) for _,v:=range keys{ fmt.Println(v,a[v]) } } func main(){ test() } //D:\project>go build go_dev/day4/example/example17 // //D:\project>example17.exe //1 10 //2 10 //3 11 //8 10 //18 10 上面思路,由于map是无序的,这里创建一个切片,然后根据切片的方法进行排序
map反转
初始化另外一个map把key、value呼唤即可
package main
import (
"fmt"
)
func test(){
var a map[string] int
var b map[int] string
a=make(map[string]int,5)
b=make(map[int]string,5)
a["abc"]=1
a["efg"]=2
for k,v:=range a{
b[v]=k
}
fmt.Println(a) //map[abc:1 efg:2]
fmt.Println(b) //map[1:abc 2:efg]
}
func main(){
test()
}
原理:这里首先声明两个map,并且初始化,然后进行遍历第一个map,然后第二个map直接添加第一个map的v和k即可
包
1、golang中的包
a、golang目前有150个标准的包,覆盖了几乎所有的基础库
b、golang.org有所有包的文档,没事就翻翻
2、线程同步
a、import(“sync”)
b、互斥锁 var mu sync.Mutex,同一时间只能有一个goroute能进去
c、读写锁,var mu sync.RWMutex
线程和协程,只有读操作的时候不用加锁
1、如果有写操作,需要加锁
2、如果有读写的操作,需要加锁
3、如果只有读的操作,不需要加锁
编译的时候—race可以查看是否有竞争
下面是互斥锁的程序
import ( "fmt" "sync" "math/rand" "time" ) //因为这是一个读写的操作,所以读的时候也要加锁 var lock sync.Mutex func test(){ var a map[int] int a=make(map[int]int,5) a[8]=10 for i :=0;i<2;i++{ go func(b map [int]int){ //下面是写的操作,所以要加锁 lock.Lock() //加锁 b[8]=rand.Intn(100) lock.Unlock() //解锁 }(a) } lock.Lock() //这是读操作,因为程序中有读写,所以加锁 fmt.Println(a) time.Sleep(time.Second) lock.Unlock() //解锁 } func main(){ test() } D:\project>go build --race go_dev/day4/example/packagea 这里—race是检测是否有竞争 D:\project>packagea.exe //因为有race所以下面检测没有竞争 map[8:81] 上面是互斥锁 应用场景: 写比较多,有少量的读。(写多读少) 加锁后,任何其他试图再次加锁的线程会被阻塞,直到当前进程解锁 如果解锁时有一个以上的线程阻塞,那么所有该锁上的线程都被编程就绪状态, 第一个变为就绪状态的线程又执行加锁操作,那么其他的线程又会进入等待。 在这种方式下,只有一个线程能够访问被互斥锁保护的资源。 互斥锁无论读还是写同一时间只有一个协程在执行
读写锁:
实际就是一种特殊的自旋锁,它把共享资源的访问者划分为读者和写者,读者只对共享资源进行读访问,写者则需要对共享资源进行写操作
使用场景:
写比较少,有大量的读 (读多写少)
写的时候只有一个goroute去写,但是读的时候所有的goroute去读
读写锁有三种状态:读加锁状态、写加锁状态和不加锁状态
一次只有一个线程可以占有写模式的读写锁,但是多个线程可以同时占有读模式的读写锁。(这也是它能够实现高并发的一种手段)
当读写锁在写加锁模式下,任何试图对这个锁进行加锁的线程都会被阻塞,直到写进程对其解锁。
当读写锁在读加锁模式先,任何线程都可以对其进行读加锁操作,但是所有试图进行写加锁操作的线程都会被阻塞,直到所有的读线程都解锁。
所以读写锁非常适合对数据结构读的次数远远大于写的情况
package main import ( "fmt" "sync" "math/rand" "time" ) var rwlock sync.RWMutex //读写锁的定义 func test(){ var a map[int] int a=make(map[int]int,5) //var count int32 a[8]=10 for i:=0;i<2;i++{ go func(b map[int]int){ rwlock.Lock() b[8]=rand.Intn(100) rwlock.Unlock() }(a) } for i:=0;i<100;i++{ go func(b map[int]int){ rwlock.RLock() //加读写锁 fmt.Println(a) rwlock.RUnlock() //解锁 }(a) } time.Sleep(time.Second*3) } func main(){ test() }
原子操作:atomic 包 在sync下面
https://studygolang.com/pkgdoc
这是串行的操作
package main import ( "fmt" "sync" "math/rand" "time" "sync/atomic" ) var rwlock sync.RWMutex //读写锁的定义 func test(){ var a map[int] int a=make(map[int]int,5) var count int32 a[8]=10 for i:=0;i<2;i++{ go func(b map[int]int){ rwlock.Lock() b[8]=rand.Intn(100) rwlock.Unlock() }(a) } for i:=0;i<100;i++{ go func(b map[int]int){ for { rwlock.RLock() //加读写锁 fmt.Println(a) rwlock.RUnlock() //解锁 atomic.AddInt32(&count, 1) //原子操作进行计数 } }(a) } time.Sleep(time.Second*3) fmt.Println(atomic.LoadInt32(&count)) //原子操作进行读出来529500 次 } func main(){ test() }
比较读写锁和互斥锁的性能
下面是读写锁 package main import ( "fmt" "sync" "math/rand" "time" "sync/atomic" ) var rwlock sync.RWMutex //读写锁的定义 func test(){ var a map[int] int a=make(map[int]int,5) var count int32 a[8]=10 for i:=0;i<2;i++{ go func(b map[int]int){ rwlock.Lock() b[8]=rand.Intn(100) time.Sleep(time.Microsecond*10) rwlock.Unlock() }(a) } for i:=0;i<100;i++{ go func(b map[int]int){ for { rwlock.RLock() //加读写锁 time.Sleep(time.Microsecond) rwlock.RUnlock() //解锁 atomic.AddInt32(&count, 1) //原子操作进行计数 } }(a) } time.Sleep(time.Second*3) fmt.Println(atomic.LoadInt32(&count)) //251196 } func main(){ test() } 下面是互斥锁 package main import ( "fmt" "sync" "math/rand" "time" "sync/atomic" ) var lock sync.Mutex //读写锁的定义 func test(){ var a map[int] int a=make(map[int]int,5) var count int32 a[8]=10 for i:=0;i<2;i++{ go func(b map[int]int){ lock.Lock() b[8]=rand.Intn(100) time.Sleep(time.Microsecond*10) lock.Unlock() }(a) } for i:=0;i<100;i++{ go func(b map[int]int){ for { lock.Lock() //rwlock.RLock() //加读写锁 time.Sleep(time.Microsecond) //rwlock.RUnlock() //解锁 lock.Unlock() atomic.AddInt32(&count, 1) //原子操作进行计数 } }(a) } time.Sleep(time.Second*3) fmt.Println(atomic.LoadInt32(&count)) //2460次 } func main(){ test() } 可以看到读写锁的性能是互斥锁的性能的100倍! 读写锁:读的时候可以有多个协程在操作 互斥锁:无论读还是写,只有一个协程在执行
go get安装第三方包
go get后面跟上github地址
有疑问加站长微信联系(非本文作者)



