
在两天前第一次遇到自己的程序出现死锁, 我一直非常的小心使用锁,了解死锁导致的各种可能性, 这次的经历让我未来会更加小心,下面来回顾一下死锁发生的过程与代码演进的过程吧。
简述业务背景及代码演进过程
我的程序中有一块缓存,数据会组织好放到内存中,会根据数据源(MySQL)更新而刷新缓存,是读多写少的应用场景。 内存中有一个很大数据列表,缓存模块会按数据维度进行分组,每次访问根据维度查找到这个列表里面的所有数据。 业务模块拿到数据后会根据业务需要再做一次筛选,选出N个符合条件的数据(具体多少个由业务模块的规则决定)。
以下是简化的代码:
package cache
import "sync"
type Cache struct {
lock sync.RWMutex
data []int // 实际数据比这个复杂很多有很多维度
}
func (c *Cache) Get() []int {
c.lock.RLock()
defer c.lock.RUnlock()
var res []int
// 筛选数据, 简单写一个筛选过程
for i := range c.data {
if c.data[i] > 10 {
res = append(res, c.data[i])
}
}
return res
}
这个方法返回的数据会很多,可实际业务需要的数据只有几个而已,那做一个优化吧,利用 go 的 chan 实现一个迭代生成器,每次只返回一个数据,业务端找到需要的数据后立即终止。
调整后的方法大致像下面这样:
package cache
import "sync"
type Cache struct {
lock sync.RWMutex
data []int // 实际数据比这个复杂很多有很多维度
}
func (c *Cache) Get(next chan struct{}) chan int {
ch := make(chan int, 1)
go func() {
c.lock.RLock()
defer c.lock.RUnlock()
defer close(ch)
// 筛选数据, 简单写一个筛选过程
for i := range c.data {
if c.data[i] > 10 {
ch <- i
if _, ok := <-next; !ok {
return
}
}
}
}()
return ch
}
调用端的代码类似下面这样:
data := make([]int, 0, 10)
c := Cache{}
next := make(chan struct{})
for i := range c.Get(next) {
data = append(data, i)
if len(data) >= 10 {
close(next)
break
}
next <- struct{}{}
}
这样调整后查看程序的内存分配显著降低,而且平安无事在生产环境运行了半个月^_^,当然截止当前还不会出现死锁的情况。
有一天业务调整了,在 cache 模块有另外一个方法,公用这个锁(实际我缓存模块为了统一,都使用一个锁,方便管理),下面的代码也写到这个 cache 组件里面。
以下代码只增加了改变的部分,.... 保持原来的代码不变。
package cache
import "sync"
type Cache struct {
....
x int
}
func (c *Cache) XX(i int) int{
c.lock.RLock()
defer c.lock.RUnlock()
if i >c.x {
return i
}
return 0
}
....
添加一个方法怎么就导致死锁了呢,主要是调用端的业务代码也发生变化了,更改如下:
data := make([]int, 0, 10)
c := Cache{}
next := make(chan struct{})
for i := range c.Get(next) {
data = append(data, i)
if c.XX(i) != i { // 在这里调用了缓存模块的另一个方法
close(next)
break
}
next <- struct{}{}
}
修改后的代码上线存活了5天就挂了,实际是当时业务订单需求很少,只是有很多流量请求,并没有频繁访问这个方法,否者会在极短的时间导致死锁, 通过这块简化的代码,也很难分析出会导致死锁,真实的业务代码很多,而且调用关系比较复杂,我们通过代码审核并没有发现任何问题。
事故现场分析排查问题
上线5天后突然接到服务无法响应的报警,事故发生立即查看了 grafana 的监控数据,发现在极段时间内服务器资源消耗极速增长,然后就立即没有响应了
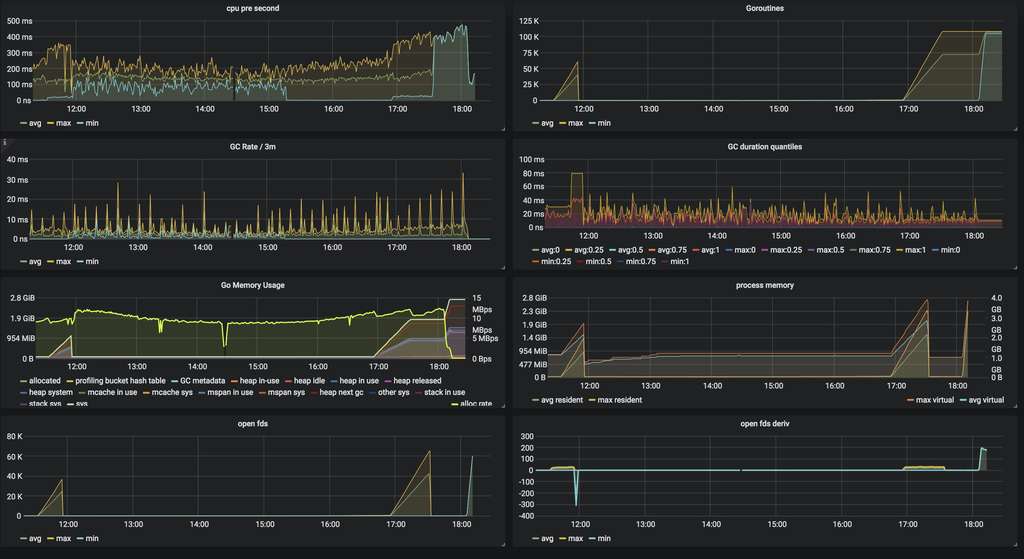
通过业务监控发现服务在极端的时间打开近10万个 goroutine 之后持续了很长一段时间,
cpu 占用和 gc 都很正常, 内存方面可以看出短时间内分配了很多内存,但是没有被释放,gc 没法回收说明一直被占用,
看到这里我心里在想可能是有个 goroutine 因为什么原因导致无法结束造成的事故吧,
然后我再往下看(实际页面是在需要滚动屏幕,第一屏只显示了上面6个模块),发现 open files 和 goroutine 的情况一致,并且之后的数据突然中断,
中断是因为服务无法影响,也就无法采集服务的信息了。
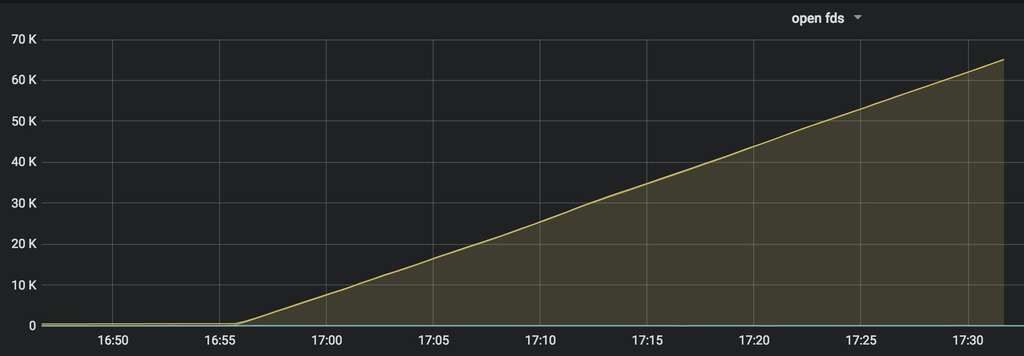
goroutine 并不会占用 open files,一个http服务导致这种情况大概只能是网络连接过多,我们遭受攻击了吗……
显然是没有的不然cpu不能很正常,那就是有可能请求无法响应,什么原因导致呢?
使用 lsof -n | grep dsp | wc -l 命令去服务器查找服务打开文件数,确实在六万五千多,
通过 cat /proc/30717/limits 发现 Max open files 65535 65535 files,
配置的最大打开文件数只有 65535,使用 lsof -n | grep dsp |grep TCP | wc -l 发现数据和之前接近,只小了几个,那是日志文件占用的。
查看日志发现大量 http: Accept error: accept tcp 172.17.191.231:8090: accept4: too many open files; retrying in 1s 错误。
这些数据帮助我快速定位确实是有请求发送到服务器,服务器无法响应导致短时间内占用很多文件打开数,导致系统限制无法建立新的连接。
这里要说一下,即使客户端断开连接了,服务器连接还是没有办法关闭,因为 goroutine 没有办法关闭, 除非自己退出。
找到原因了,服务没法响应,没法通过现场查找问题了,先重新启动一下服务,恢复业务在查找代码问题。
接下来就是查找代码问题了,期间又出现了一次故障,立即重启服务,恢复业务。
分析解决问题
通过几个小时分析代码逻辑,终于有了进展,发现上面的示例代码逻辑块导致读锁重入,存在死锁风险,这种死锁的碰撞概率非常低, 之前说过我们的缓存是读多写少的场景,如果只是读取数据,上面的代码不会有任何问题,我们一天刷新缓存的次数也不过百余次而已。
看一下究竟发生了什么导致的死锁吧:
- 程序执行
cache.Get获取一个chan, 在cache.Get里面有一个goroutine读取数据只有加了读写锁,只有goroutine关闭才会释放 for i := range c.Get(next) {遍历chan时goroutine不会结束,也就说读锁没有被释放- 遍历时执行了
c.XX(i)方法,在该方面里面也加了读锁, 形成了读锁重入的场景,但是该放执行周期很短,执行完就会马上释放
好吧,这样的流程并没有形成死锁,什么情况下导致的死锁呢,接着看一下一个场景:
- 程序执行
cache.Get获取一个chan, 在cache.Get里面有一个goroutine读取数据只有加了读写锁,只有goroutine关闭才会释放 for i := range c.Get(next) {遍历chan时goroutine不会结束,也就说读锁没有被释放- 数据发生了改变,触发了缓存刷新,申请独占锁(写锁),等待所有读锁释放
- 遍历时执行
c.XX(i)方法,该方法申请读锁,因为写锁在等待,所以任何读锁都将等待写锁释放后才能添加成功 - for 循环被阻塞,
cache.Get里面的goroutine无法退出,无法释放读锁 - 写锁等待所有读锁释放
c.XX(i)等待写锁释放- ....
重点看第三步,这里是关键,因为在两个嵌套的读锁中间申请写锁,导致死锁发生,找到原因修复起来很简单的,
调整 cache.Get 加锁的方法,把 c.data 赋值给一个临时变量 data, 在这段代码前后加锁和释放锁,锁的代码块更小,时间更短
c.data 单独拷贝是安全的,那怕是指针数据,因为每次刷新缓存都会给 c.data 重新赋值,分配新的内存空间。
package cache
import "sync"
type Cache struct {
lock sync.RWMutex
data []int // 实际数据比这个复杂很多有很多维度
x int
}
func (c *Cache) XX(i int) int{
c.lock.RLock()
defer c.lock.RUnlock()
if i >c.x {
return i
}
return 0
}
func (c *Cache) Get(next chan struct{}) chan int {
ch := make(chan int, 1)
go func() {
defer close(ch)
c.lock.RLock()
data := c.data
c.lock.RUnlock()
// 筛选数据, 简单写一个筛选过程
for i := range data {
if data[i] > 10 {
ch <- i
if _, ok := <-next; !ok {
return
}
}
}
}()
return ch
}
修复之后的业务状态:
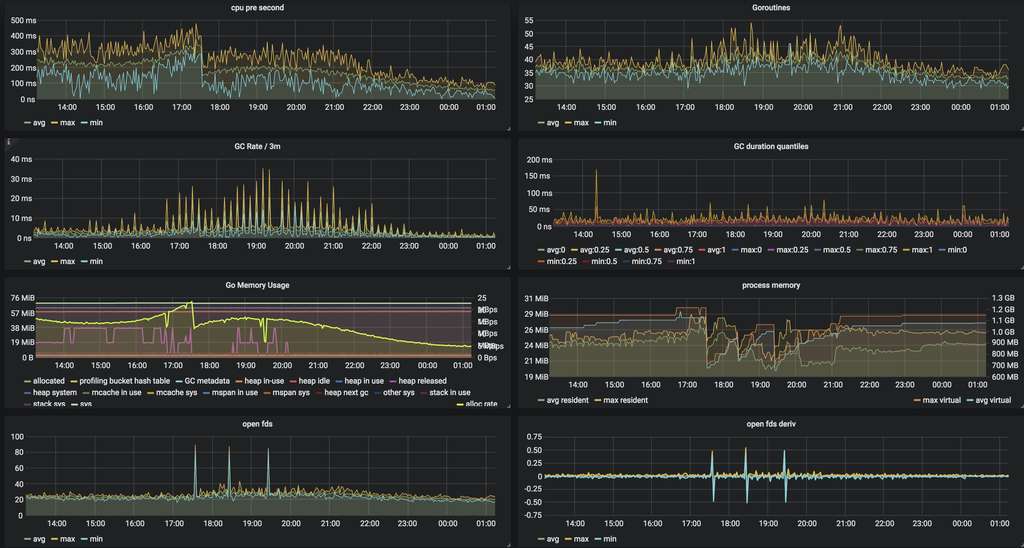
复现问题
用程序复现一下上面的场景可以吗,好像有点难,我写了一个简单的复现代码,如下:
package main
import (
"fmt"
"runtime"
"sync"
)
var l = sync.RWMutex{}
func main() {
var wg sync.WaitGroup
wg.Add(2)
c := make(chan int)
go func() {
l.RLock() // 读锁1
defer l.RUnlock()
fmt.Println(1)
c <- 1
fmt.Println(2)
runtime.Gosched()
fmt.Println(3)
b()
fmt.Println(4)
wg.Done()
}()
go func() {
fmt.Println(5)
<-c
fmt.Println(6)
l.Lock()
fmt.Println(7)
fmt.Println(8)
defer l.Unlock()
fmt.Println(9)
wg.Done()
}()
go func() {
i := 1
for {
i++
}
}()
wg.Wait()
}
func b() {
fmt.Println(10)
l.RLock() // 读锁2
fmt.Println(11)
defer l.RUnlock()
fmt.Println(12)
}
这段程序的输出(受 goroutine 运行时影响在输出数字3之前会有些许差异):
1
5
6
2
3
10
分析一下这个运行流程吧:
- 首先加上读锁1,就是
fmt.Println(1)之前, 状态加读锁1 - 另外一个
goroutine启动,fmt.Println(5), 状态加读锁1 - 发送数据
c <- 1, 状态加读锁1 - 接受到数据
<-cfmt.Println(6), 状态加读锁1 - 输出 2
fmt.Println(2), 状态加读锁1 - 暂停当前
goroutineruntime.Gosched(), 状态加读锁1 - 申请写锁
l.Lock(), 等待读锁1释放, 状态加读锁1、写锁等待 - 切换
goroutine执行fmt.Println(3)与b(), 状态加读锁1、写锁等待 - 输出10
fmt.Println(10), 申请读锁2,等待写锁释放, 状态加读锁1、写锁等待、读锁2等待 - 支持程序永久阻塞……
分析读写锁实现
func (rw *RWMutex) RLock() {
if race.Enabled {
_ = rw.w.state
race.Disable()
}
if atomic.AddInt32(&rw.readerCount, 1) < 0 {
// A writer is pending, wait for it.
runtime_SemacquireMutex(&rw.readerSem, false)
}
if race.Enabled {
race.Enable()
race.Acquire(unsafe.Pointer(&rw.readerSem))
}
}
申请写锁时会在 rw.readerCount 读数量变量上自增加 1,如果结果小于 0,当前读锁进入修改等待读锁唤醒信号,
单独看着一个方法会比较懵,为啥读的数量会小于0呢,接着看写锁。
func (rw *RWMutex) Lock() {
if race.Enabled {
_ = rw.w.state
race.Disable()
}
// First, resolve competition with other writers.
rw.w.Lock()
// Announce to readers there is a pending writer.
r := atomic.AddInt32(&rw.readerCount, -rwmutexMaxReaders) + rwmutexMaxReaders
// Wait for active readers.
if r != 0 && atomic.AddInt32(&rw.readerWait, r) != 0 {
runtime_SemacquireMutex(&rw.writerSem, false)
}
if race.Enabled {
race.Enable()
race.Acquire(unsafe.Pointer(&rw.readerSem))
race.Acquire(unsafe.Pointer(&rw.writerSem))
}
}
申请写锁时会先加上互斥锁,也就是有其它写的客户端的话会等待写锁释放才能加上,具体实现看互斥锁的代码,
然后在 rw.readerCount 上自增一个极大的负数 1 << 30 , 读写锁这里也就限制了我们的同时读的进程不能超过这个值。
然后在结果上加上 rwmutexMaxReaders 也就是 atomic.AddInt32(&rw.readerCount, -rwmutexMaxReaders) + rwmutexMaxReaders 得到实际读客户端的数量
如果读的客户端不等于0,就在 rw.readerWait 自增读客户端的数量,之后陷入睡眠,等待 rw.writerSem 唤醒。
分析了这两段代码我们就能明白,写锁等待或者添加时,读锁没法添加上
func (rw *RWMutex) RUnlock() {
if race.Enabled {
_ = rw.w.state
race.ReleaseMerge(unsafe.Pointer(&rw.writerSem))
race.Disable()
}
if r := atomic.AddInt32(&rw.readerCount, -1); r < 0 {
if r+1 == 0 || r+1 == -rwmutexMaxReaders {
race.Enable()
throw("sync: RUnlock of unlocked RWMutex")
}
// A writer is pending.
if atomic.AddInt32(&rw.readerWait, -1) == 0 {
// The last reader unblocks the writer.
runtime_Semrelease(&rw.writerSem, false)
}
}
if race.Enabled {
race.Enable()
}
}
释放读锁,先在 rw.readerCount 减 1,然后检查读客户端是否小于0,如果小于0说明有写锁在等待,
在 rw.readerWait 上减1,这个变量记录的是写等待读客户端的数量,如果没有需要等待的读客户端了,就通知 rw.writerSem 唤醒写锁
func (rw *RWMutex) Unlock() {
if race.Enabled {
_ = rw.w.state
race.Release(unsafe.Pointer(&rw.readerSem))
race.Disable()
}
// Announce to readers there is no active writer.
r := atomic.AddInt32(&rw.readerCount, rwmutexMaxReaders)
if r >= rwmutexMaxReaders {
race.Enable()
throw("sync: Unlock of unlocked RWMutex")
}
// Unblock blocked readers, if any.
for i := 0; i < int(r); i++ {
runtime_Semrelease(&rw.readerSem, false)
}
// Allow other writers to proceed.
rw.w.Unlock()
if race.Enabled {
race.Enable()
}
}
写锁在释放时会给 rw.readerCount 自增 rwmutexMaxReaders 还原真实读客户端数量。
for i := 0; i < int(r); i++ { 用来唤醒所有的读客户端,因为在写锁的时候,申请读锁的客户端会被计数,但是都会陷入睡眠状态。
总结
以前特别强调过读锁重入导致死锁的问题,而且这个问题非常难在业务代码里面复现,触发几率很低, 编译和运行时都无法检测这种情况,所以千万不能陷入读锁重入的嵌套使用的情况,否者问题非常难以排查。
关于加锁的几个小经验:
- 运行时离开当前逻辑就释放锁。
- 锁的粒度越小越好,加锁后尽快释放锁。
- 尽量不用
defer释放锁。 - 读锁不要嵌套。
转载
- 本文作者: 戚银(thinkeridea)
- 本文链接: https://blog.thinkeridea.com/201812/go/yi_ci_du_suo_chong_ru_dao_zhi_de_si_suo_gu_zhang.html
- 版权声明: 本博客所有文章除特别声明外,均采用 CC BY 4.0 CN协议 许可协议。转载请注明出处!
有疑问加站长微信联系(非本文作者))



