循环是几乎所有编程语言都具有的控制结构,也是编程语言中常用的控制结构,Go 语言除了使用经典的『三段式』循环之外,还引入了另一个关键字 range 帮助我们快速遍历数组、哈希表以及 Channel 等元素。
在这一节中,我们将介绍 Go 语言中的两种不同循环,也就是经典的 for 循环和 for…range 循环,我们会分析这两种循环在运行时的结构以及它们的实现原理,
概述
for 循环能够将代码中的数据和逻辑分离,让同一份代码能够多次复用处理同样的逻辑,我们先来看一下 Go 语言两种不同的 for 循环在汇编代码这一层是如何实现的,首先我们先来看一下经典 for 循环编译之后的底层汇编代码,当我们将一段包含 for 循环的代码编译成汇编语言时会得到如下的结果:
$ cat main.go
package main
func main() {
for i := 0; i < 10; i++ {
println(i)
}
}
$ go build -gcflags -S main.go
"".main STEXT size=98 args=0x0 locals=0x18
0x0000 00000 (main.go:3) TEXT "".main(SB), $24-0
# ...
0x001d 00029 (main.go:3) XORL AX, AX
0x001f 00031 (main.go:4) JMP 75
0x0021 00033 (main.go:4) MOVQ AX, "".i+8(SP)
0x0026 00038 (main.go:5) CALL runtime.printlock(SB)
0x002b 00043 (main.go:5) MOVQ "".i+8(SP), AX
0x0030 00048 (main.go:5) MOVQ AX, (SP)
0x0034 00052 (main.go:5) CALL runtime.printint(SB)
0x0039 00057 (main.go:5) CALL runtime.printnl(SB)
0x003e 00062 (main.go:5) CALL runtime.printunlock(SB)
0x0043 00067 (main.go:4) MOVQ "".i+8(SP), AX
0x0048 00072 (main.go:4) INCQ AX
0x004b 00075 (main.go:4) CMPQ AX, $10
0x004f 00079 (main.go:4) JLT 33
# ...
- 这段汇编代码其实就是 for 循环被编译之后的结果,存储变量
i的寄存器就是AX,第 0029 行代码对寄存器中的数据进行初始化; - 通过
JMP 75,跳转到 0075 行,这里会将寄存器中存储的数据与 10 比较并通过JLT 33命令,在变量的值小于 10 时跳转到 0033 行; - 从 0033 行到 0067 行其实都是 for 循环中内部的语句,也就是执行
println(i)打印变量; - 每次执行完循环之后都会通过 0072 行中的
INCQ AX指定将变量加一,然后再与 10 进行比较,决定是跳转回循环内部继续执行其中的逻辑,还是顺序执行下面的指令;
如果我们在 Go 语言中使用 for…range 循环,经过优化的汇编代码其实有着完全相同的结构,无论是变量的初始化、循环体的执行还是最后的条件判断逻辑都是一样的,我们仍然会使用 JLT 指令在满足条件时跳回循环体的开始位置重新运行。
$ cat main.go
package main
func main() {
arr := []int{1, 2, 3}
for i, _ := range arr {
println(i)
}
}
$ GOOS=linux GOARCH=amd64 go tool compile -S main.go
"".main STEXT size=98 args=0x0 locals=0x18
0x0000 00000 (main.go:3) TEXT "".main(SB), $24-0
# ...
0x001d 00029 (main.go:3) XORL AX, AX
0x001f 00031 (main.go:5) JMP 75
0x0021 00033 (main.go:5) MOVQ AX, "".i+8(SP)
0x0026 00038 (main.go:6) CALL runtime.printlock(SB)
0x002b 00043 (main.go:6) MOVQ "".i+8(SP), AX
0x0030 00048 (main.go:6) MOVQ AX, (SP)
0x0034 00052 (main.go:6) CALL runtime.printint(SB)
0x0039 00057 (main.go:6) CALL runtime.printnl(SB)
0x003e 00062 (main.go:6) CALL runtime.printunlock(SB)
0x0043 00067 (main.go:5) MOVQ "".i+8(SP), AX
0x0048 00072 (main.go:5) INCQ AX
0x004b 00075 (main.go:5) CMPQ AX, $3
0x004f 00079 (main.go:5) JLT 33
# ...
在汇编语言这种线性的执行顺序下,无论是经典的 for 循环还是 for…range 循环都会使用 JMP 以及相关的命令跳回循环体的开始位置来复用代码的逻辑。
从这里的汇编代码我们就可以猜到,使用 for…range 语法的控制结构最终应该也会被 Go 语言的编译器转换成普通的 for 循环,所以我们在这里将先介绍 Go 语言的 for 循环是如何被编译成汇编代码,再介绍 for…range 循环如何被转换成 for 循环。
不过在深入语言的源代码中了解它们的实现之前,可以先来看一下使用 for 和 range 时遇到的一些现象和问题,我们可以带着这些现象和问题去源代码中寻找答案。
永不停止的循环
如果我们在 Go 语言中使用如下的方式在遍历数组的同时修改数组的元素,我们能否得到一个永远都不会停止的循环呢?你可以自己尝试运行下面的代码来得到结果:
func main() {
arr := []int{1, 2, 3}
for _, v := range arr {
arr = append(arr, v)
}
fmt.Println(arr)
}
$ go run main.go
1 2 3 1 2 3
这段代码的最终会打印出 1 2 3 1 2 3,也就意味着循环只遍历了切片中的三个元素,我们在遍历切片时追加的所有元素都不会导致循环次数的增加,所以循环最终还是停了下来。
神奇的指针
第二个例子是很多 Go 语言开发者都曾经遇到的问题,也就是如果在遍历一个数组时,如果我们获取 range 返回变量的地址并保存到另一个数组或者哈希中,当我们去打印这个数组中的内容时,就会发现新数组中指针指向的元素是 3 3 3:
func main() {
arr := []int{1, 2, 3}
newArr := []*int{}
for _, v := range arr {
newArr = append(newArr, &v)
}
for _, v := range newArr {
fmt.Println(*v)
}
}
$ go run main.go
3 3 3
这个问题其实比较常见,一些有经验的开发者不经意也会犯这种错误,正确的做法应该是使用 &arr[i] 替代 &v,我们会在下面分析这一现象出现的原因。
遍历清空数组
当我们想要在 Go 语言中清空一个切片或者哈希表时,我们一般都会使用一下的方法将切片中的元素置零,但是依次去遍历数组和哈希表其实是非常耗费性能的事情:
func main() {
arr := []int{1, 2, 3}
for i, _ := range arr {
arr[i] = 0
}
}
在前面的章节中我们也曾经介绍过 数组 和 哈希表 的内存占用都是连续的,所以是可以直接清空这片内存地址的内容,我们可以将上述的代码进行编译得到下面的汇编指令:
$ GOOS=linux GOARCH=amd64 go tool compile -S main.go
"".main STEXT size=93 args=0x0 locals=0x30
0x0000 00000 (main.go:3) TEXT "".main(SB), $48-0
# ...
0x001d 00029 (main.go:4) MOVQ "".statictmp_0(SB), AX
0x0024 00036 (main.go:4) MOVQ AX, ""..autotmp_3+16(SP)
0x0029 00041 (main.go:4) MOVUPS "".statictmp_0+8(SB), X0
0x0030 00048 (main.go:4) MOVUPS X0, ""..autotmp_3+24(SP)
0x0035 00053 (main.go:5) PCDATA $2, $1
0x0035 00053 (main.go:5) LEAQ ""..autotmp_3+16(SP), AX
0x003a 00058 (main.go:5) PCDATA $2, $0
0x003a 00058 (main.go:5) MOVQ AX, (SP)
0x003e 00062 (main.go:5) MOVQ $24, 8(SP)
0x0047 00071 (main.go:5) CALL runtime.memclrNoHeapPointers(SB)
# ...
从生成的汇编代码我们其实可以看出,编译器会直接使用 memclrNoHeapPointers 清除切片中的数据,这也是我们在下面的小节中会介绍的内容。
随机的遍历顺序
当我们在 Go 语言中使用 range 去遍历哈希表,往往都会使用如下的代码结构,但是当我们执行这里的代码时却会发现这段代码在每次执行时都会打印出不同的结果:
func main() {
hash := map[string]int{
"1": 1,
"2": 2,
"3": 3,
}
for k, v := range hash {
println(k, v)
}
}
假设我们运行了两次上述的代码,第一次会按照 2 3 1 的顺序打印键值对,但是第二次会按照 1 2 3 的顺序进行打印,如果我们多次运行这段代码就会发现每次执行的结果其实都不大相同。
$ go run main.go
2 2
3 3
1 1
$ go run main.go
1 1
2 2
3 3
这其实是 Go 语言故意的设计,它在运行时为哈希的遍历引入这种不确定性,也是告诉我们所有使用 Go 语言的开发者不要依赖于哈希遍历的稳定,我们在下面的小节中会介绍不稳定性是如何主动引入的。
经典循环
Go 语言中的经典循环在便一起看来就是一个 OFOR 类型的节点,这个节点具有以下的结构,其中包括由于初始化循环的 Ninit、循环的中止条件 Left、循环体结束时执行的 Right 表达式以及循环体 NBody:
for Ninit; Left; Right {
NBody
}
在生成 SSA 中间代码的阶段,stmt 方法发现传入的节点类型是 OFOR 时就会执行以下的代码,这段代码的主要作用就是将循环中的代码分成不同的块:
func (s *state) stmt(n *Node) {
switch n.Op {
case OFOR, OFORUNTIL:
bCond := s.f.NewBlock(ssa.BlockPlain)
bBody := s.f.NewBlock(ssa.BlockPlain)
bIncr := s.f.NewBlock(ssa.BlockPlain)
bEnd := s.f.NewBlock(ssa.BlockPlain)
b := s.endBlock()
b.AddEdgeTo(bCond)
s.startBlock(bCond)
if n.Left != nil {
s.condBranch(n.Left, bBody, bEnd, 1)
} else {
b := s.endBlock()
b.Kind = ssa.BlockPlain
b.AddEdgeTo(bBody)
}
s.startBlock(bBody)
s.stmtList(n.Nbody)
b.AddEdgeTo(bIncr)
s.startBlock(bIncr)
if n.Right != nil {
s.stmt(n.Right)
}
b.AddEdgeTo(bCond)
s.startBlock(bEnd)
}
}
一个常见的 for 循环代码会被 stmt 方法转换成以下的控制结构,其中包含了 4 个不同的块,这些不同的代码块之间会通过边去连接,与我们理解的 for 循环控制结构其实没有太多的差别。
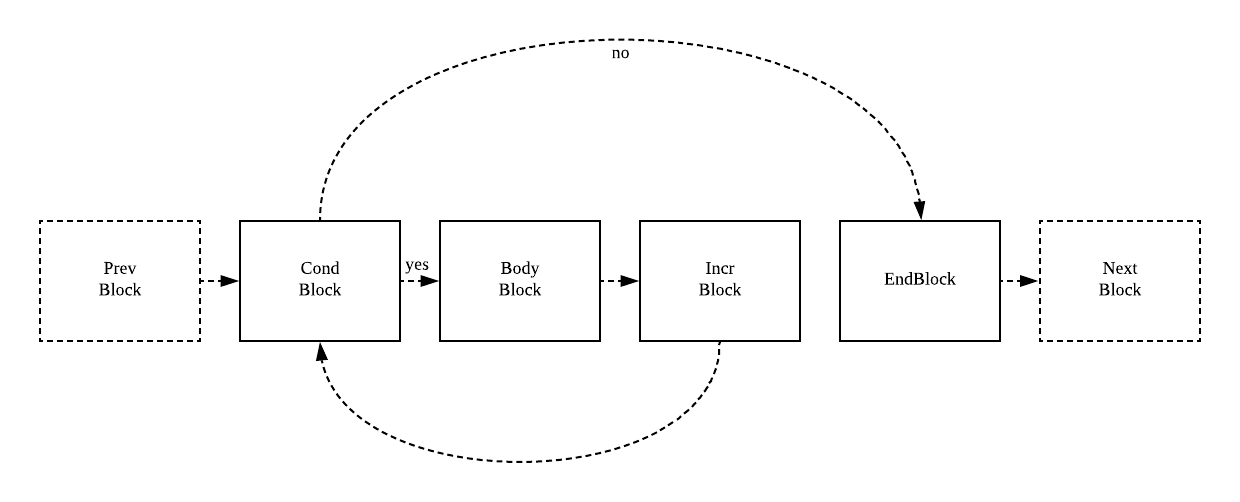
这些代码块在随后的 机器码生成 阶段会被转换成机器码并在最后转换成指定 CPU 架构上运行的机器语言,也就是我们上一节中看到的线性控制结构。
范围循环
与简单的经典循环相比,范围循环在 Go 语言中更常见,实现相对来说也更加复杂,这种循环同时会使用 for 和 range 两个关键字,编译器会在编译期间将带有 range 的循环变成普通的经典循环,也就是将 ORANGE 类型的节点转换成 OFOR 类型:
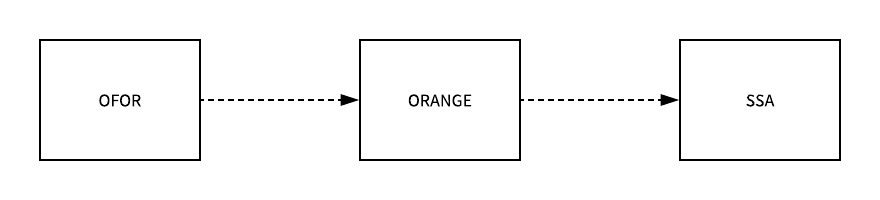
这一过程都发生在 SSA 中间代码的过程,所有的 range 都会被 walkrange 函数转换成只包含基本表达式的语句,不包含任何复杂的结构,这些简单的 for 循环最终会被转换成上一节中提到的 SSA 中间代码,我们接下来按照 range 操作的不同元素类型分别介绍范围循环遍历不同元素时的实现。
数组和切片
对于 数组或者切片 来说,Go 语言中其实有三种不同的 range 遍历方式,这三种不同的遍历方式会在 walkrange 函数中被转换成不同的控制逻辑,这三种不同的逻辑分别对应着代码中的不同条件,我们先看一下这段代码最开始的逻辑:
func walkrange(n *Node) *Node {
switch t.Etype {
case TARRAY, TSLICE:
if arrayClear(n, v1, v2, a) {
return n
}
arrayClear 是一个非常有趣的优化,当我们在 Go 语言中遍历去删除所有的元素时,其实会在这个函数中被优化成如下的代码:
// original
for i := range a {
a[i] = zero
}
// optimized
if len(a) != 0 {
hp = &a[0]
hn = len(a)*sizeof(elem(a))
memclrNoHeapPointers(hp, hn)
i = len(a) - 1
}
相比于依次清除数组或者切片中的数据,Go 语言会直接使用 memclrNoHeapPointers 或者 memclrHashPointers 函数直接清除目标数组对应内存空间中的数据并在执行完成后更新用于遍历数组的索引,保证上下文不会出现问题,这也印证了我们在概述一节中观察到的现象。
处理了这种特殊的情况之后,我们就可以继续回到 ORANGE 节点的处理过程了,在这里首先会设置 for 循环的 Left 和 Right 字段,也就是终止的条件和循环体每次执行结束后运行的代码:
ha := a
hv1 := temp(types.Types[TINT])
hn := temp(types.Types[TINT])
init = append(init, nod(OAS, hv1, nil))
init = append(init, nod(OAS, hn, nod(OLEN, ha, nil)))
n.Left = nod(OLT, hv1, hn)
n.Right = nod(OAS, hv1, nod(OADD, hv1, nodintconst(1)))
if v1 == nil {
break
}
如下所示的代码会进入 v1 == nil 条件,直接退出当前的 switch 语句,如果转换前的代码是 for range a {},那么它会被转换成如下所示的代码:
ha := a
hv1 := 0
hn := len(ha)
v1 := hv1
for ; hv1 < hn; hv1++ {
// ...
}
这其实是最简单的 range 结构在编译期间被转换后的形式,由于原代码其实并不需要数组中任何元素的信息,只需要使用数组或者切片的数量执行对应次数的循环,如果我们只需要使用遍历数组时的索引就会执行如下的代码:
if v2 == nil {
body = []*Node{nod(OAS, v1, hv1)}
break
}
它会将类似 for i := range a {} 的结构转换成如下所示的逻辑,与第一种循环相比,这种循环额外地在循环体中添加了 v1 := hv1 用于传递遍历数组时的索引:
ha := a
hv1 := 0
hn := len(ha)
v1 := hv1
for ; hv1 < hn; hv1++ {
v1 := hv1
// ...
}
上面的两种情况虽然也是使用 range 时经常遇到的情况,但是同时去遍历索引和元素才是最常见的场景,处理最后一种情况就使用了如下所示的代码:
tmp := nod(OINDEX, ha, hv1)
tmp.SetBounded(true)
a := nod(OAS2, nil, nil)
a.List.Set2(v1, v2)
a.Rlist.Set2(hv1, tmp)
body = []*Node{a}
}
n.Ninit.Append(init...)
n.Nbody.Prepend(body...)
return n
}
这段代码处理的就是类似 for i, elem := range a {} 的逻辑,它不止会在循环体中插入更新索引的表达式,还会插入赋值的操作让循环体内部的代码能够访问数组中的元素:
ha := a
hv1 := 0
hn := len(ha)
v1 := hv1
for ; hv1 < hn; hv1++ {
tmp := ha[hv1]
v1, v2 := hv1, tmp
// ...
}
对于所有的 range 循环,Go 语言都会在编译期间将原切片或者数组赋值给一个新的变量 ha,在赋值的过程中其实就发生了拷贝,所以我们遍历的切片其实已经不是原有的切片变量了。
而遇到这种同时遍历索引和元素的 range 循环时,Go 语言会额外创建一个新的 v2 变量存储切片中的元素,循环中使用的这个变量 v2 会在每一次迭代中都被重新赋值,在赋值时也发生了拷贝,所以如果我们想要访问数组中元素所在的地址,不应该直接获取 range 返回的 v2 变量的地址 &v2,想要解决这个问题应该使用 &a[index] 这种方式获取数组中元素对应的地址。
func main() {
arr := []int{1, 2, 3}
newArr := []*int{}
for i, _ := range arr {
newArr = append(newArr, &arr[i])
}
for _, v := range newArr {
fmt.Println(*v)
}
}
当我们在遇到这种问题时,应该使用如上所示的代码来获取数组中元素的地址,而不应该使用编译器生成的、会被复用的临时变量。
哈希
当我们使用 range 遍历 哈希 时,这些用于遍历的循环都会在编译期间被展开,它会使用两个运行时函数 mapiterinit 和 mapiternext 替代 range 关键字,我们可以使用如下的代码表示转换后的循环:
ha := a
hit := hiter(n.Type)
th := hit.Type
mapiterinit(typename(t), ha, &hit)
for ; hit.key != nil; mapiternext(&hit) {
key := *hit.key
val := *hit.val
}
这里其实是 for key, val := range hash {} 生成的代码,其实在 walkrange 函数中对于 TMAP 类型的处理时会根据接受 range 返回值的数量在循环体中插入需要的赋值语句:
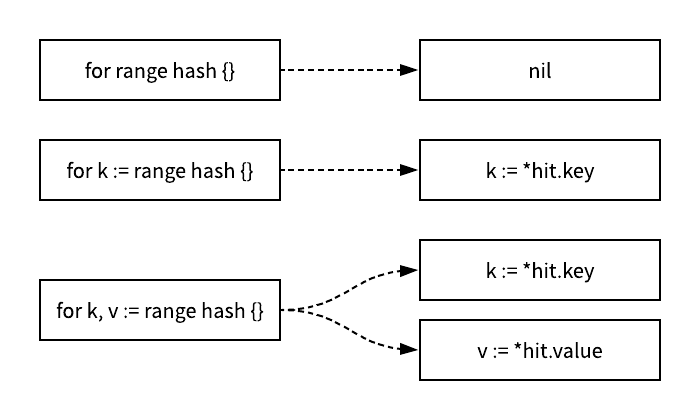
这三种不同的情况会向循环体中只插入被用到变量的赋值语句,在遍历哈希表的过程中会使用两个不同的函数,也就是 mapiterinit 和 mapiternext,这两个函数中的前者主要负责选择初始化遍历开始的元素:
func mapiterinit(t *maptype, h *hmap, it *hiter) {
it.t = t
it.h = h
it.B = h.B
it.buckets = h.buckets
if t.bucket.kind&kindNoPointers != 0 {
h.createOverflow()
it.overflow = h.extra.overflow
it.oldoverflow = h.extra.oldoverflow
}
r := uintptr(fastrand())
if h.B > 31-bucketCntBits {
r += uintptr(fastrand()) << 31
}
it.startBucket = r & bucketMask(h.B)
it.offset = uint8(r >> h.B & (bucketCnt - 1))
it.bucket = it.startBucket
mapiternext(it)
}
该函数会在 hiter 结构体中存储哈希表的相关信息,并通过 fastrand 生成一个随机数帮助我们随机选择一个桶开始遍历,这也是我们在上一节中每次运行遍历哈希的代码时都会得到不同的结果,Go 语言在设计哈希的遍历时就不想让使用者依赖一些固定的遍历顺序,所以引入了随机数的确保哈希遍历的随机性。
对于函数的遍历过程中使用 mapiternext 函数,我们其实简化了非常多的逻辑,这里省去了一些边界条件的处理以及哈希表扩容时的兼容操作等逻辑,我们只需要关注处理遍历逻辑的核心代码:
func mapiternext(it *hiter) {
h := it.h
t := it.t
bucket := it.bucket
b := it.bptr
i := it.i
alg := t.key.alg
next:
if b == nil {
if bucket == it.startBucket && it.wrapped {
it.key = nil
it.value = nil
return
}
b = (*bmap)(add(it.buckets, bucket*uintptr(t.bucketsize)))
bucket++
if bucket == bucketShift(it.B) {
bucket = 0
it.wrapped = true
}
i = 0
}
上述这段代码的主要有两个作用,一个是在待遍历的桶为空时选择需要遍历的新桶,第二个作用是在所有的桶都已经被遍历过时返回 (nil, nil) 键值对,上层在发现返回的键值对都是空时就会结束遍历。
mapiternext 函数中第二段代码的主要作用就是从桶中找到下一个遍历的元素,在大多数情况下都会直接操作内存获取目标键值的内存地址,如果当前的哈希表处于扩容期间就会调用 mapaccessK 函数获取键值对:
for ; i < bucketCnt; i++ {
offi := (i + it.offset) & (bucketCnt - 1)
k := add(unsafe.Pointer(b), dataOffset+uintptr(offi)*uintptr(t.keysize))
v := add(unsafe.Pointer(b), dataOffset+bucketCnt*uintptr(t.keysize)+uintptr(offi)*uintptr(t.valuesize))
if (b.tophash[offi] != evacuatedX && b.tophash[offi] != evacuatedY) ||
!(t.reflexivekey() || alg.equal(k, k)) {
it.key = k
it.value = v
} else {
rk, rv := mapaccessK(t, h, k)
it.key = rk
it.value = rv
}
it.bucket = bucket
it.i = i + 1
return
}
b = b.overflow(t)
i = 0
goto next
}
总的来说,哈希表的遍历会随机选择开始的位置,然后依次遍历桶中的元素,桶中元素如果被遍历完,就会遍历当前桶对应的溢出桶,溢出桶都遍历结束之后才会遍历哈希中的下一个桶,直到所有的桶都被遍历完成。
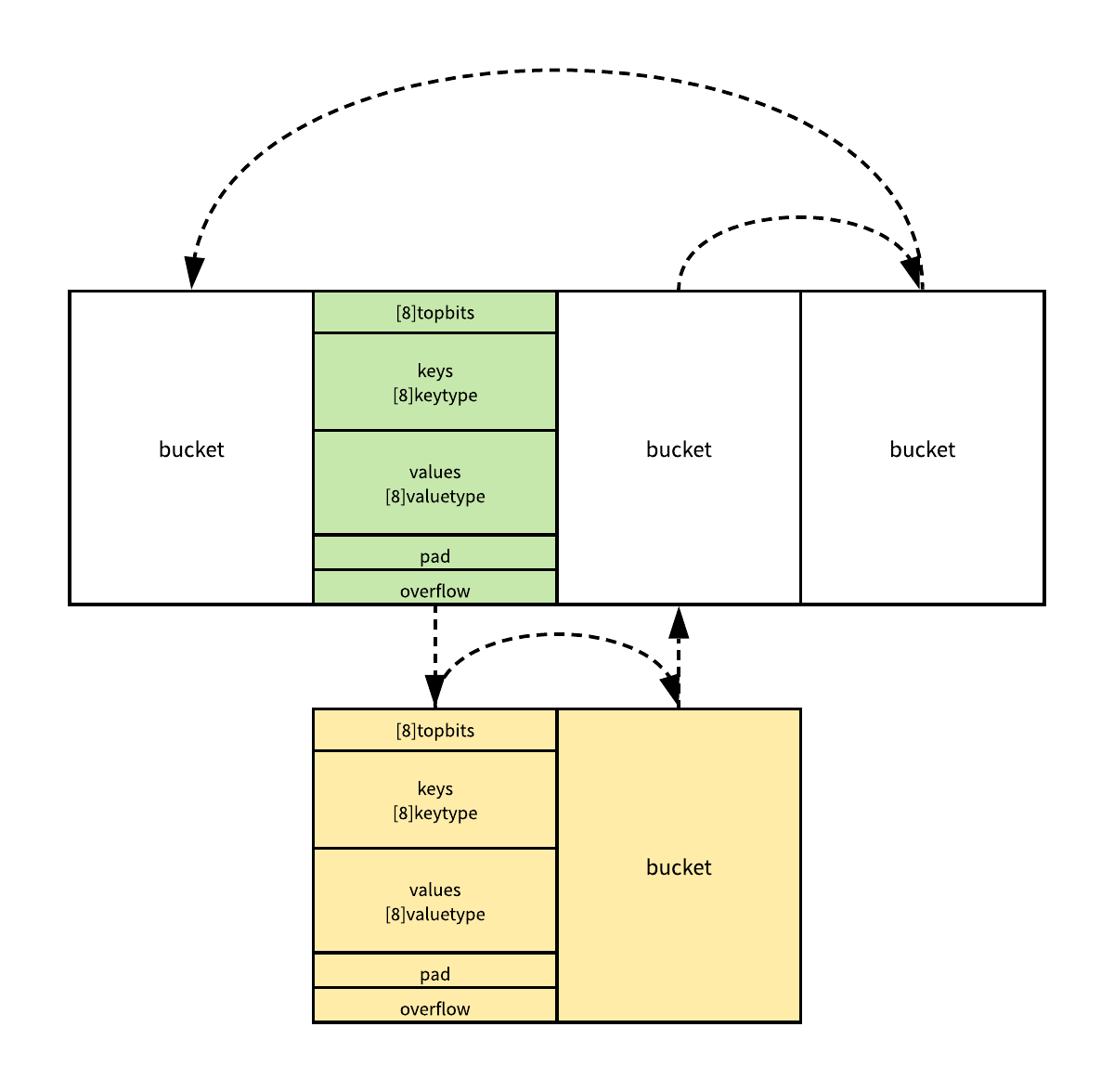
上图中其实就展示了哈希表遍历的顺序,首先会选出一个绿色的桶开始遍历,随后遍历该桶对应的所有黄色的溢出桶,最后依次按照索引遍历哈希表中其他的桶,在遍历到末尾时会重新回到哈希表中的第一个桶,当待遍历的桶与开始的绿色桶相等时就会停止遍历。
字符串
字符串的遍历与数组和哈希表非常相似,只是在遍历的过程中会获取字符串中索引对应的字节,然后将字节转换成 rune,我们在遍历字符串时拿到的值都是 rune 类型的变量,其实类似 for i, r := range s {} 的结构都会被转换成如下的形式:
ha := s
for hv1 := 0; hv1 < len(ha); {
hv1t := hv1
hv2 := rune(ha[hv1])
if hv2 < utf8.RuneSelf {
hv1++
} else {
hv2, hv1 = decoderune(h1, hv1)
}
v1, v2 = hv1t, hv2
}
这段代码的框架与上面提到的数组和哈希其实非常相似,只是细节有一些不同,在之前的介绍 字符串 的章节中我们曾经介绍过字符串其实就是一个只读的字节数组切片。
所以使用下标访问字符串中的元素时其实得到的就是字节,但是这段代码会将当前的字节转换成 rune 类型,如果当前的 rune 是 ASCII 的,那么只会占用一个字节长度,这时只需要将索引加一,但是如果当前的 rune 占用了多个字节就会使用 decoderune 进行解码,具体的过程就不在这一章中详细介绍了。
通道
在 range 循环中使用 Channel 其实也是比较常见的做法,一个形如 for v := range ch {} 的表达式会最终被转换成如下的格式:
ha := a
hv1, hb := <-ha
for ; hb != false; hv1, hb = <-ha {
v1 := hv1
hv1 = nil
// ...
}
这里的代码可能与编译器生成的稍微有一些出入,但是结构和效果是几乎完全相同的,该循环会使用 <-ch 从管道中取出等待处理的值,这个操作会调用 chanrecv2 并阻塞当前的协程,当 chanrecv2 返回时会根据 hb 来判断当前的值是否存在,如果不存在就意味着当前的管道已经被关闭了,在正常情况下都会为 v1 赋值并清除 hv1 中的数据,然后会陷入下一次的阻塞等待接受新的数据。
总结
这一节介绍的两个关键字 for 和 range 都是我们在学习和使用 Go 语言中无法绕开的,通过对他们底层原理的分析和研究,其实让我们对底层实现的一些细节有了更清楚的认识,包括 Go 语言遍历数组和切片时会复用变量、哈希随机遍历的原理以及底层的一些优化,这都能帮助我们更好地理解和使用 Go 语言。
Reference
关于图片和转载

本作品采用知识共享署名 4.0 国际许可协议进行许可。 转载时请注明原文链接,图片在使用时请保留图片中的全部内容,可适当缩放并在引用处附上图片所在的文章链接,图片使用 Sketch 进行绘制。
有疑问加站长微信联系(非本文作者)




