在上一篇文章 详解分布式协调服务 ZooKeeper 中,我们介绍过分布式协调服务 Zookeeper 的实现原理以及应用,今天想要介绍的 etcd 其实也是在生产环境中经常被使用的协调服务,它与 Zookeeper 一样,也能够为整个集群提供服务发现、配置以及分布式协调的功能。
![]()
这篇文章将会介绍 etcd 的实现原理,其中包括 Raft 协议、存储两大模块,在最后我们也会简单介绍 etcd 一些具体应用场景。
简介
etcd 的官方将它定位成一个可信赖的分布式键值存储服务,它能够为整个分布式集群存储一些关键数据,协助分布式集群的正常运转。

我们可以简单看一下 etcd 和 Zookeeper 在定义上有什么不同:
- etcd is a distributed reliable key-value store for the most critical data of a distributed system…
- ZooKeeper is a centralized service for maintaining configuration information, naming, providing distributed synchronization, and providing group services.
其中前者是一个用于存储关键数据的键值存储,后者是一个用于管理配置等信息的中心化服务。
etcd 的使用其实非常简单,它对外提供了 gRPC 接口,我们可以通过 Protobuf 和 gRPC 直接对 etcd 中存储的数据进行管理,也可以使用官方提供的 etcdctl 操作存储的数据。
service KV {
rpc Range(RangeRequest) returns (RangeResponse) {
option (google.api.http) = {
post: "/v3beta/kv/range"
body: "*"
};
}
rpc Put(PutRequest) returns (PutResponse) {
option (google.api.http) = {
post: "/v3beta/kv/put"
body: "*"
};
}
}
文章并不会展开介绍 etcd 的使用方法,这一小节将逐步介绍几大核心模块的实现原理,包括 etcd 使用 Raft 协议同步各个节点数据的过程以及 etcd 底层存储数据使用的结构。
Raft
在每一个分布式系统中,etcd 往往都扮演了非常重要的地位,由于很多服务配置发现以及配置的信息都存储在 etcd 中,所以整个集群可用性的上限往往就是 etcd 的可用性,而使用 3 ~ 5 个 etcd 节点构成高可用的集群往往都是常规操作。
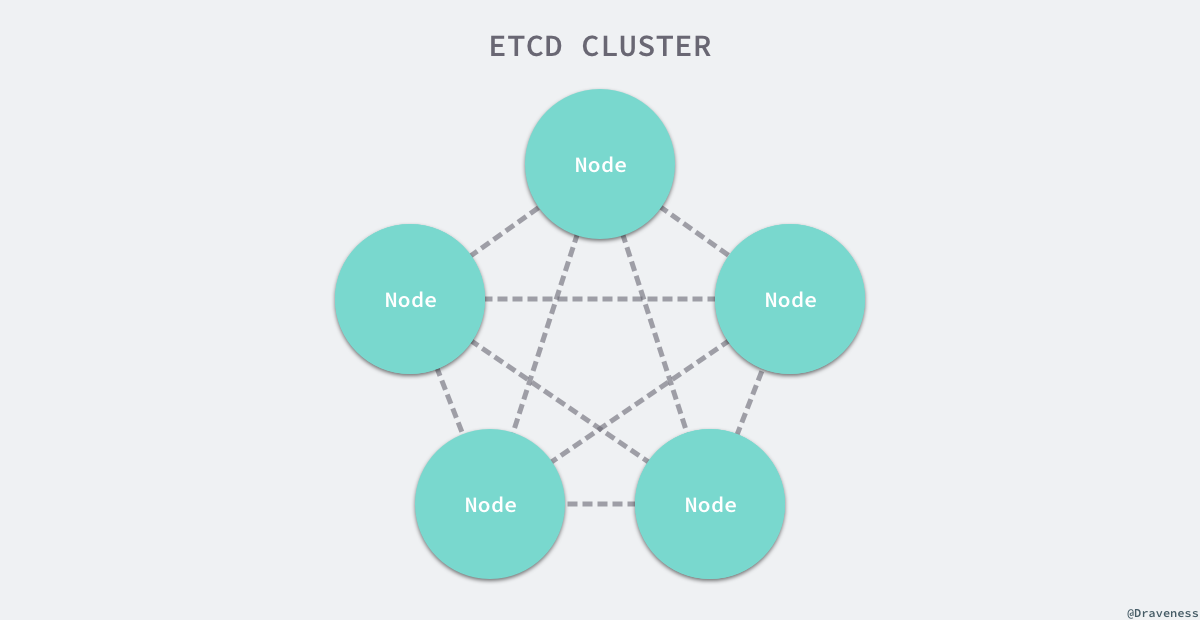
正是因为 etcd 在使用的过程中会启动多个节点,如何处理几个节点之间的分布式一致性就是一个比较有挑战的问题了。
解决多个节点数据一致性的方案其实就是共识算法,在之前的文章中我们简单介绍过 Zookeeper 使用的 Zab 协议 以及常见的 共识算法 Paxos 和 Raft,etcd 使用的共识算法就是 Raft,这一节我们将详细介绍 Raft 以及 etcd 中 Raft 的一些实现细节。
介绍
Raft 从一开始就被设计成一个易于理解和实现的共识算法,它在容错和性能上与 Paxos 协议比较类似,区别在于它将分布式一致性的问题分解成了几个子问题,然后一一进行解决。
每一个 Raft 集群中都包含多个服务器,在任意时刻,每一台服务器只可能处于 Leader、Follower 以及 Candidate 三种状态;在处于正常的状态时,集群中只会存在一个 Leader,其余的服务器都是 Follower。

上述图片修改自 In Search of an Understandable Consensus Algorithm 一文 5.1 小结中图四。
所有的 Follower 节点都是被动的,它们不会主动发出任何的请求,只会响应 Leader 和 Candidate 发出的请求,对于每一个用户的可变操作,都会被路由给 Leader 节点进行处理,除了 Leader 和 Follower 节点之外,Candidate 节点其实只是集群运行过程中的一个临时状态。
Raft 集群中的时间也被切分成了不同的几个任期(Term),每一个任期都会由 Leader 的选举开始,选举结束后就会进入正常操作的阶段,直到 Leader 节点出现问题才会开始新一轮的选择。
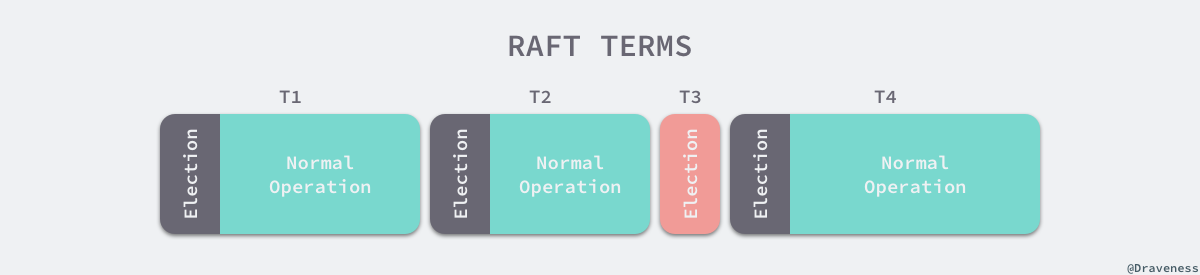
每一个服务器都会存储当前集群的最新任期,它就像是一个单调递增的逻辑时钟,能够同步各个节点之间的状态,当前节点持有的任期会随着每一个请求被传递到其他的节点上。
Raft 协议在每一个任期的开始时都会从一个集群中选出一个节点作为集群的 Leader 节点,这个节点会负责集群中的日志的复制以及管理工作。
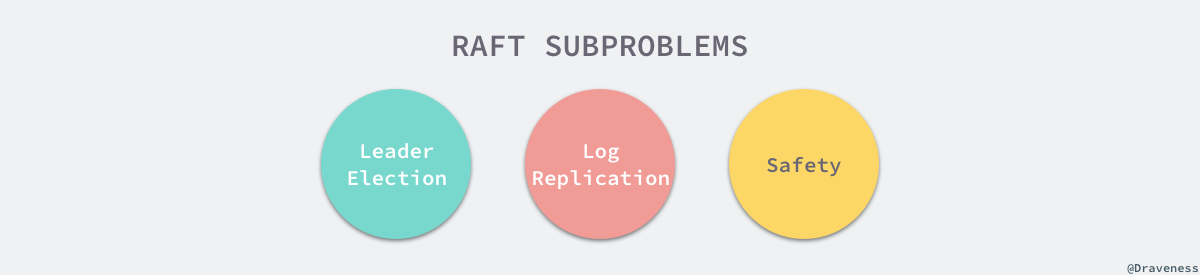
我们将 Raft 协议分成三个子问题:节点选举、日志复制以及安全性,文章会以 etcd 为例介绍 Raft 协议是如何解决这三个子问题的。
节点选举
使用 Raft 协议的 etcd 集群在启动节点时,会遵循 Raft 协议的规则,所有节点一开始都被初始化为 Follower 状态,新加入的节点会在 NewNode 中做一些配置的初始化,包括用于接收各种信息的 Channel:
// https://sourcegraph.com/github.com/etcd-io/etcd@1cab49e/-/blob/raft/node.go#L190-225
func StartNode(c *Config, peers []Peer) Node {
r := newRaft(c)
r.becomeFollower(1, None)
r.raftLog.committed = r.raftLog.lastIndex()
for _, peer := range peers {
r.addNode(peer.ID)
}
n := newNode()
go n.run(r)
return &n
}
在做完这些初始化的节点和 Raft 配置的事情之后,就会进入一个由 for 和 select 组成的超大型循环,这个循环会从 Channel 中获取待处理的事件:
// https://sourcegraph.com/github.com/etcd-io/etcd@1cab49e/-/blob/raft/node.go#L291-423
func (n *node) run(r *raft) {
lead := None
for {
if lead != r.lead {
lead = r.lead
}
select {
case m := <-n.recvc:
r.Step(m)
case <-n.tickc:
r.tick()
case <-n.stop:
close(n.done)
return
}
}
}
作者对整个循环内的代码进行了简化,因为当前只需要关心三个 Channel 中的消息,也就是用于接受其他节点消息的 recvc、用于触发定时任务的 tickc 以及用于暂停当前节点的 stop。
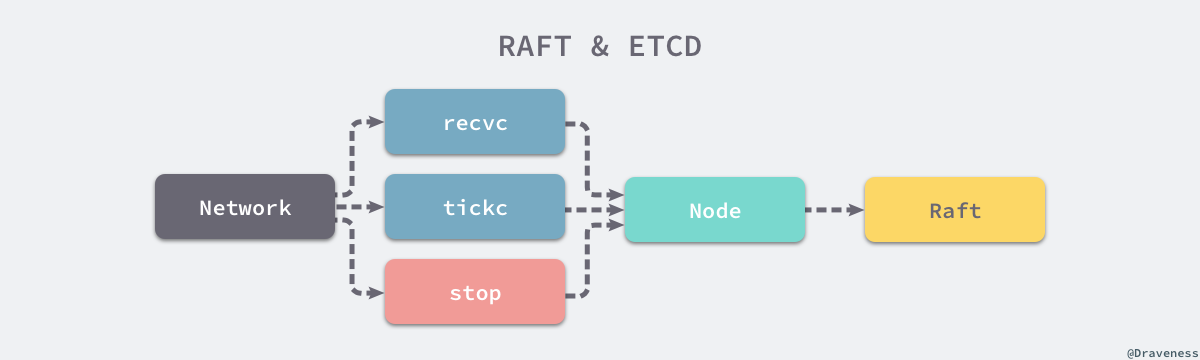
除了 stop Channel 中介绍到的消息之外,recvc 和 tickc 两个 Channel 中介绍到事件时都会交给当前节点持有 Raft 结构体处理。
定时器与心跳
当节点从任意状态(包括启动)调用 becomeFollower 时,都会将节点的定时器设置为 tickElection:
// https://sourcegraph.com/github.com/etcd-io/etcd@1cab49e/-/blob/raft/raft.go#L636-643
func (r *raft) tickElection() {
r.electionElapsed++
if r.promotable() && r.pastElectionTimeout() {
r.electionElapsed = 0
r.Step(pb.Message{From: r.id, Type: pb.MsgHup})
}
}
如果当前节点可以成为 Leader 并且上一次收到 Leader 节点的消息或者心跳已经超过了等待的时间,当前节点就会发送 MsgHup 消息尝试开始新的选举。
但是如果 Leader 节点正常运行,就能够同样通过它的定时器 tickHeartbeat 向所有的 Follower 节点广播心跳请求,也就是 MsgBeat 类型的 RPC 消息:
func (r *raft) tickHeartbeat() {
r.heartbeatElapsed++
r.electionElapsed++
if r.heartbeatElapsed >= r.heartbeatTimeout {
r.heartbeatElapsed = 0
r.Step(pb.Message{From: r.id, Type: pb.MsgBeat})
}
}
上述代码段 Leader 节点中调用的 Step 函数,最终会调用 stepLeader 方法,该方法会根据消息的类型进行不同的处理:
// https://sourcegraph.com/github.com/etcd-io/etcd@1cab49e/-/blob/raft/raft.go#L931-1142
func stepLeader(r *raft, m pb.Message) error {
switch m.Type {
case pb.MsgBeat:
r.bcastHeartbeat()
return nil
// ...
}
//...
}
bcastHeartbeat 方法最终会向所有的 Follower 节点发送 MsgHeartbeat 类型的消息,通知它们目前 Leader 的存活状态,重置所有 Follower 持有的超时计时器。
// https://sourcegraph.com/github.com/etcd-io/etcd@1cab49e/-/blob/raft/raft.go#L518-534
func (r *raft) sendHeartbeat(to uint64, ctx []byte) {
commit := min(r.getProgress(to).Match, r.raftLog.committed)
m := pb.Message{
To: to,
Type: pb.MsgHeartbeat,
Commit: commit,
Context: ctx,
}
r.send(m)
}
作为集群中的 Follower,它们会在 stepFollower 方法中处理接收到的全部消息,包括 Leader 节点发送的心跳 RPC 消息:
// https://sourcegraph.com/github.com/etcd-io/etcd@1cab49e/-/blob/raft/raft.go#L1191-1247
func stepFollower(r *raft, m pb.Message) error {
switch m.Type {
case pb.MsgHeartbeat:
r.electionElapsed = 0
r.lead = m.From
r.handleHeartbeat(m)
// ...
}
return nil
}
当 Follower 接受到了来自 Leader 的 RPC 消息 MsgHeartbeat 时,会将当前节点的选举超时时间重置并通过 handleHeartbeat 向 Leader 节点发出响应 —— 通知 Leader 当前节点能够正常运行。
而 Candidate 节点对于 MsgHeartBeat 消息的处理会稍有不同,它会先执行 becomeFollower 设置当前节点和 Raft 协议的配置:
// https://sourcegraph.com/github.com/etcd-io/etcd@1cab49e/-/blob/raft/raft.go#L1146-1189
func stepCandidate(r *raft, m pb.Message) error {
// ...
switch m.Type {
case pb.MsgHeartbeat:
r.becomeFollower(m.Term, m.From) // always m.Term == r.Term
r.handleHeartbeat(m)
}
// ...
return nil
}
Follower 与 Candidate 会根据节点类型的不同做出不同的响应,两者收到心跳请求时都会重置节点的选举超时时间,不过后者会将节点的状态直接转变成 Follower:
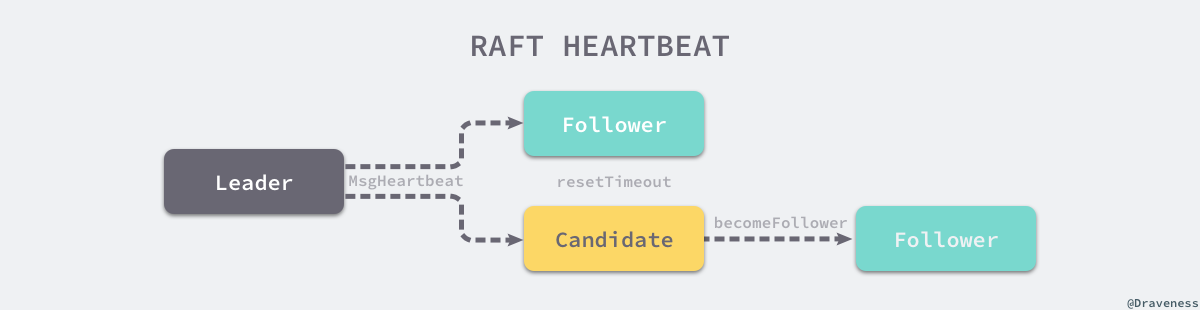
当 Leader 节点收到心跳的响应时就会将对应节点的状态设置为 Active,如果 Follower 节点在一段时间内没有收到来自 Leader 节点的消息就会尝试发起竞选。
// https://sourcegraph.com/github.com/etcd-io/etcd@1cab49e/-/blob/raft/raft.go#L636-643
func (r *raft) tickElection() {
r.electionElapsed++
if r.promotable() && r.pastElectionTimeout() {
r.electionElapsed = 0
r.Step(pb.Message{From: r.id, Type: pb.MsgHup})
}
}
到了这里,心跳机制就起到了作用开始发送 MsgHup 尝试重置整个集群中的 Leader 节点,接下来我们就会开始分析 Raft 协议中的竞选流程了。
竞选流程
如果集群中的某一个 Follower 节点长时间内没有收到来自 Leader 的心跳请求,当前节点就会通过 MsgHup 消息进入预选举或者选举的流程。
// https://sourcegraph.com/github.com/etcd-io/etcd@1cab49e/-/blob/raft/raft.go#L785-927
func (r *raft) Step(m pb.Message) error {
// ...
switch m.Type {
case pb.MsgHup:
if r.state != StateLeader {
if r.preVote {
r.campaign(campaignPreElection)
} else {
r.campaign(campaignElection)
}
} else {
r.logger.Debugf("%x ignoring MsgHup because already leader", r.id)
}
}
// ...
return nil
}
如果收到 MsgHup 消息的节点不是 Leader 状态,就会根据当前集群的配置选择进入 PreElection 或者 Election 阶段,PreElection 阶段并不会真正增加当前节点的 Term,它的主要作用是得到当前集群能否成功选举出一个 Leader 的答案,如果当前集群中只有两个节点而且没有预选举阶段,那么这两个节点的 Term 会无休止的增加,预选举阶段就是为了解决这一问题而出现的。
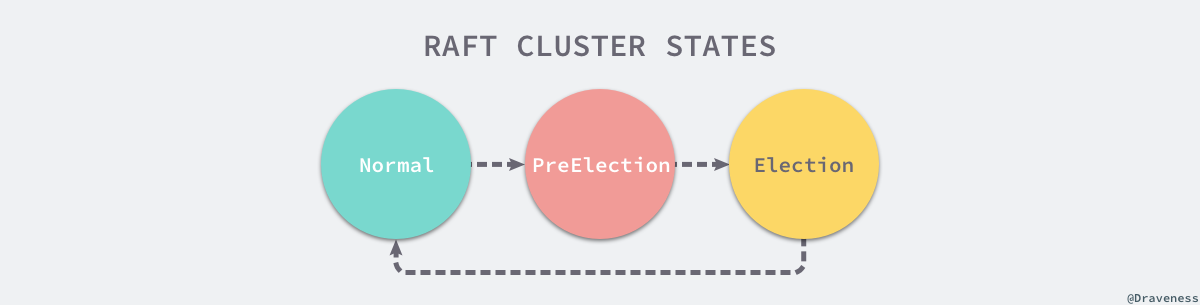
在这里不会讨论预选举的过程,而是将目光主要放在选举阶段,具体了解一下使用 Raft 协议的 etcd 集群是如何从众多节点中选出 Leader 节点的。
我们可以继续来分析 campaign 方法的具体实现,下面就是删去预选举相关逻辑后的代码:
// https://sourcegraph.com/github.com/etcd-io/etcd@1cab49e/-/blob/raft/raft.go#L730-766
func (r *raft) campaign(t CampaignType) {
r.becomeCandidate()
if r.quorum() == r.poll(r.id, voteRespMsgType(voteMsg), true) {
r.becomeLeader()
return
}
for id := range r.prs {
if id == r.id {
continue
}
r.send(pb.Message{Term: r.Term, To: id, Type: pb.MsgVote, Index: r.raftLog.lastIndex(), LogTerm: r.raftLog.lastTerm(), Context: ctx})
}
}
当前节点会立刻调用 becomeCandidate 将当前节点的 Raft 状态变成候选人;在这之后,它会将票投给自己,如果当前集群只有一个节点,该节点就会直接成为集群中的 Leader 节点。
如果集群中存在了多个节点,就会向集群中的其他节点发出 MsgVote 消息,请求其他节点投票,在 Step 函数中包含不同状态的节点接收到消息时的响应:
// https://sourcegraph.com/github.com/etcd-io/etcd@1cab49e/-/blob/raft/raft.go#L785-927
func (r *raft) Step(m pb.Message) error {
// ...
switch m.Type {
case pb.MsgVote, pb.MsgPreVote:
canVote := r.Vote == m.From || (r.Vote == None && r.lead == None)
if canVote && r.raftLog.isUpToDate(m.Index, m.LogTerm) {
r.send(pb.Message{To: m.From, Term: m.Term, Type: pb.MsgVoteResp})
r.electionElapsed = 0
r.Vote = m.From
} else {
r.send(pb.Message{To: m.From, Term: r.Term, Type: pb.MsgVoteResp, Reject: true})
}
}
// ...
return nil
}
如果当前节点投的票就是消息的来源或者当前节点没有投票也没有 Leader,那么就会向来源的节点投票,否则就会通知该节点当前节点拒绝投票。
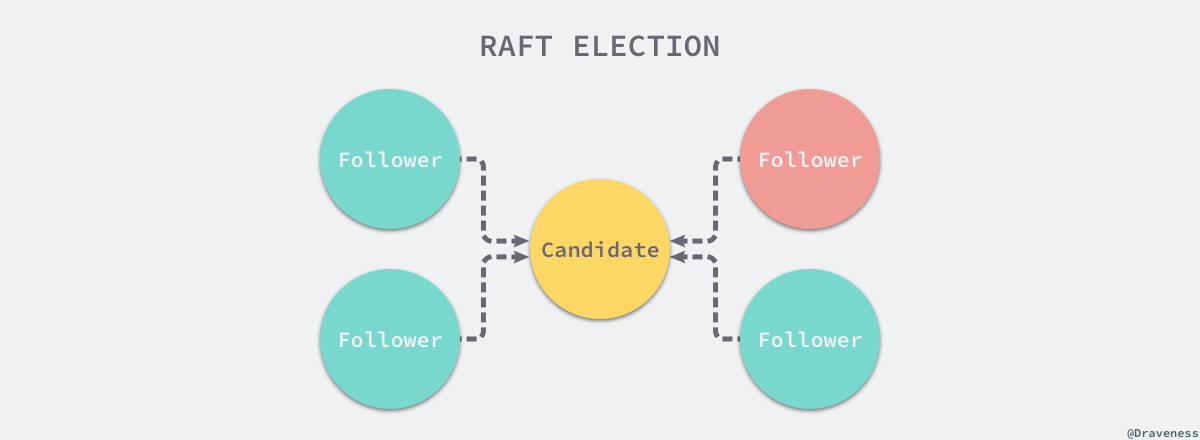
在 stepCandidate 方法中,候选人节点会处理来自其他节点的投票响应消息,也就是 MsgVoteResp:
// https://sourcegraph.com/github.com/etcd-io/etcd@1cab49e/-/blob/raft/raft.go#L1146-1189
func stepCandidate(r *raft, m pb.Message) error {
switch m.Type {
// ...
case pb.MsgVoteResp:
gr := r.poll(m.From, m.Type, !m.Reject)
switch r.quorum() {
case gr:
r.becomeLeader()
r.bcastAppend()
// ...
}
}
return nil
}
每当收到一个 MsgVoteResp 类型的消息时,就会设置当前节点持有的 votes 数组,更新其中存储的节点投票状态并返回投『同意』票的人数,如果获得的票数大于法定人数 quorum,当前节点就会成为集群的 Leader 并向其他的节点发送当前节点当选的消息,通知其余节点更新 Raft 结构体中的 Term 等信息。
节点状态
对于每一个节点来说,它们根据不同的节点状态会对网络层发来的消息做出不同的响应,我们会分别介绍下面的四种状态在 Raft 中对于配置和消息究竟是如何处理的。
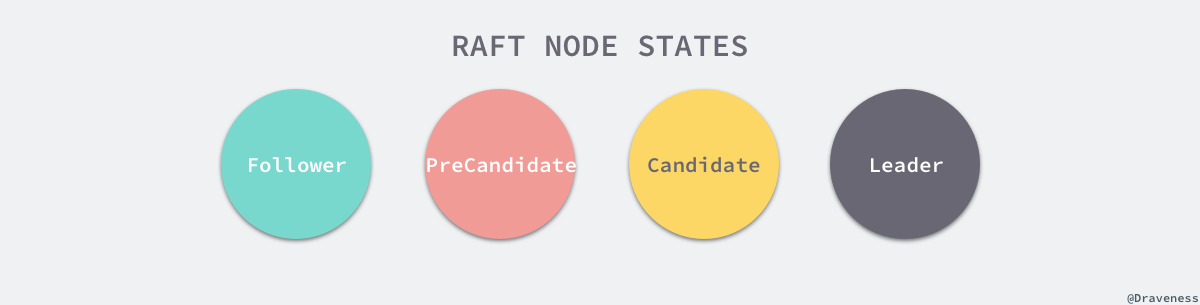
对于每一个 Raft 的节点状态来说,它们分别有三个比较重要的区别,其中一个是在改变状态时调用 becomeLeader、becomeCandidate、becomeFollower 和 becomePreCandidate 方法改变 Raft 状态有比较大的不同,第二是处理消息时调用 stepLeader、stepCandidate 和 stepFollower 时有比较大的不同,最后是几种不同状态的节点具有功能不同的定时任务。
对于方法的详细处理,我们在这一节中不详细介绍和分析,如果一个节点的状态是 Follower,那么当前节点切换到 Follower 一定会通过 becomeFollower 函数,在这个函数中会重置节点持有任期,并且设置处理消息的函数为 stepFollower:
// https://sourcegraph.com/github.com/etcd-io/etcd@1cab49e/-/blob/raft/raft.go#L671-678
func (r *raft) becomeFollower(term uint64, lead uint64) {
r.step = stepFollower
r.reset(term)
r.tick = r.tickElection
r.lead = lead
r.state = StateFollower
}
// https://sourcegraph.com/github.com/etcd-io/etcd@1cab49e/-/blob/raft/raft.go#L636-643
func (r *raft) tickElection() {
r.electionElapsed++
if r.promotable() && r.pastElectionTimeout() {
r.electionElapsed = 0
r.Step(pb.Message{From: r.id, Type: pb.MsgHup})
}
}
除此之外,它还会设置一个用于在 Leader 节点宕机时触发选举的定时器 tickElection。
Candidate 状态的节点与 Follower 的配置差不了太多,只是在消息处理函数 step、任期以及状态上的设置有一些比较小的区别:
// https://sourcegraph.com/github.com/etcd-io/etcd@1cab49e/-/blob/raft/raft.go#L680-691
func (r *raft) becomeCandidate() {
r.step = stepCandidate
r.reset(r.Term + 1)
r.tick = r.tickElection
r.Vote = r.id
r.state = StateCandidate
}
最后的 Leader 就与这两者有其他的区别了,它不仅设置了处理消息的函数 step 而且设置了与其他状态完全不同的 tick 函数:
// https://sourcegraph.com/github.com/etcd-io/etcd@1cab49e/-/blob/raft/raft.go#L708-728
func (r *raft) becomeLeader() {
r.step = stepLeader
r.reset(r.Term)
r.tick = r.tickHeartbeat
r.lead = r.id
r.state = StateLeader
r.pendingConfIndex = r.raftLog.lastIndex()
r.appendEntry(pb.Entry{Data: nil})
}
这里的 tick 函数 tickHeartbeat 每隔一段时间会通过 Step 方法向集群中的其他节点发送 MsgBeat 消息:
// https://sourcegraph.com/github.com/etcd-io/etcd@1cab49e/-/blob/raft/raft.go#L646-669
func (r *raft) tickHeartbeat() {
r.heartbeatElapsed++
r.electionElapsed++
if r.electionElapsed >= r.electionTimeout {
r.electionElapsed = 0
if r.checkQuorum {
r.Step(pb.Message{From: r.id, Type: pb.MsgCheckQuorum})
}
}
if r.heartbeatElapsed >= r.heartbeatTimeout {
r.heartbeatElapsed = 0
r.Step(pb.Message{From: r.id, Type: pb.MsgBeat})
}
}
上述代码中的 MsgBeat 消息会在 Step 中被转换成 MsgHeartbeat 最终发送给其他的节点,Leader 节点超时之后的选举流程我们在前两节中也已经介绍过了,在这里就不再重复了。
存储
etcd 目前支持 V2 和 V3 两个大版本,这两个版本在实现上有比较大的不同,一方面是对外提供接口的方式,另一方面就是底层的存储引擎,V2 版本的实例是一个纯内存的实现,所有的数据都没有存储在磁盘上,而 V3 版本的实例就支持了数据的持久化。
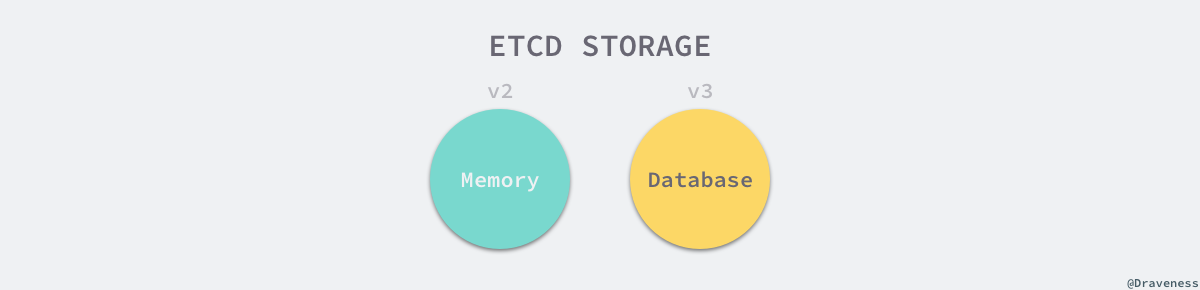
在这一节中,我们会介绍 V3 版本的 etcd 究竟是通过什么样的方式存储用户数据的。
后端
在 V3 版本的设计中,etcd 通过 backend 后端这一设计,很好地封装了存储引擎的实现细节,为上层提供一个更一致的接口,对于 etcd 的其他模块来说,它们可以将更多注意力放在接口中的约定上,不过在这里,我们更关注的是 etcd 对 Backend 接口的实现。
// https://sourcegraph.com/github.com/etcd-io/etcd@1cab49e/-/blob/mvcc/backend/backend.go#L51-69
type Backend interface {
ReadTx() ReadTx
BatchTx() BatchTx
Snapshot() Snapshot
Hash(ignores map[IgnoreKey]struct{}) (uint32, error)
Size() int64
SizeInUse() int64
Defrag() error
ForceCommit()
Close() error
}
etcd 底层默认使用的是开源的嵌入式键值存储数据库 bolt,但是这个项目目前的状态已经是归档不再维护了,如果想要使用这个项目可以使用 CoreOS 的 bbolt 版本。
![]()
这一小节中,我们会简单介绍 etcd 是如何使用 BoltDB 作为底层存储的,首先可以先来看一下 pacakge 内部的 backend 结构体,这是一个实现了 Backend 接口的结构:
// https://sourcegraph.com/github.com/etcd-io/etcd@1cab49e/-/blob/mvcc/backend/backend.go#L80-104
type backend struct {
size int64
sizeInUse int64
commits int64
mu sync.RWMutex
db *bolt.DB
batchInterval time.Duration
batchLimit int
batchTx *batchTxBuffered
readTx *readTx
stopc chan struct{}
donec chan struct{}
lg *zap.Logger
}
从结构体的成员 db 我们就可以看出,它使用了 BoltDB 作为底层存储,另外的两个 readTx 和 batchTx 分别实现了 ReadTx 和 BatchTx 接口:
// https://sourcegraph.com/github.com/etcd-io/etcd@1cab49e/-/blob/mvcc/backend/read_tx.go#L30-36
type ReadTx interface {
Lock()
Unlock()
UnsafeRange(bucketName []byte, key, endKey []byte, limit int64) (keys [][]byte, vals [][]byte)
UnsafeForEach(bucketName []byte, visitor func(k, v []byte) error) error
}
// https://sourcegraph.com/github.com/etcd-io/etcd@1cab49e/-/blob/mvcc/backend/batch_tx.go#L28-38
type BatchTx interface {
ReadTx
UnsafeCreateBucket(name []byte)
UnsafePut(bucketName []byte, key []byte, value []byte)
UnsafeSeqPut(bucketName []byte, key []byte, value []byte)
UnsafeDelete(bucketName []byte, key []byte)
Commit()
CommitAndStop()
}
从这两个接口的定义,我们不难发现它们能够对外提供数据库的读写操作,而 Backend 就能对这两者提供的方法进行封装,为上层屏蔽存储的具体实现:
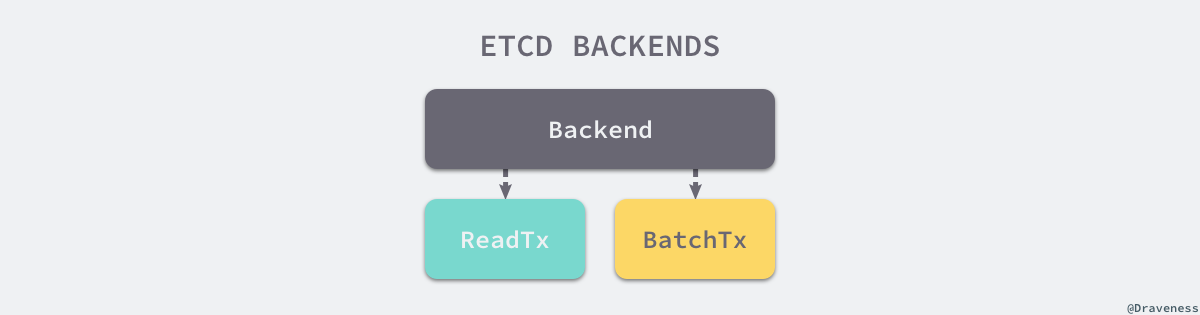
每当我们使用 newBackend 创建一个新的 backend 结构时,都会创建一个 readTx 和 batchTx 结构体,这两者一个负责处理只读请求,一个负责处理读写请求:
// https://sourcegraph.com/github.com/etcd-io/etcd@1cab49e/-/blob/mvcc/backend/backend.go#L137-176
func newBackend(bcfg BackendConfig) *backend {
bopts := &bolt.Options{}
bopts.InitialMmapSize = bcfg.mmapSize()
db, _ := bolt.Open(bcfg.Path, 0600, bopts)
b := &backend{
db: db,
batchInterval: bcfg.BatchInterval,
batchLimit: bcfg.BatchLimit,
readTx: &readTx{
buf: txReadBuffer{
txBuffer: txBuffer{make(map[string]*bucketBuffer)},
},
buckets: make(map[string]*bolt.Bucket),
},
stopc: make(chan struct{}),
donec: make(chan struct{}),
}
b.batchTx = newBatchTxBuffered(b)
go b.run()
return b
}
当我们在 newBackend 中进行了初始化 BoltDB、事务等工作后,就会开一个 goroutine 异步的对所有批量读写事务进行定时提交:
// https://sourcegraph.com/github.com/etcd-io/etcd@1cab49e/-/blob/mvcc/backend/backend.go#L289-305
func (b *backend) run() {
defer close(b.donec)
t := time.NewTimer(b.batchInterval)
defer t.Stop()
for {
select {
case <-t.C:
case <-b.stopc:
b.batchTx.CommitAndStop()
return
}
if b.batchTx.safePending() != 0 {
b.batchTx.Commit()
}
t.Reset(b.batchInterval)
}
}
对于上层来说,backend 其实只是对底层存储的一个抽象,很多时候并不会直接跟它打交道,往往都是使用它持有的 ReadTx 和 BatchTx 与数据库进行交互。
只读事务
目前大多数的数据库对于只读类型的事务并没有那么多的限制,尤其是在使用了 MVCC 之后,所有的只读请求几乎不会被写请求锁住,这大大提升了读的效率,由于在 BoltDB 的同一个 goroutine 中开启两个相互依赖的只读事务和读写事务会发生死锁,为了避免这种情况我们还是引入了 sync.RWLock 保证死锁不会出现:
// https://sourcegraph.com/github.com/etcd-io/etcd@1cab49e/-/blob/mvcc/backend/read_tx.go#L38-47
type readTx struct {
mu sync.RWMutex
buf txReadBuffer
txmu sync.RWMutex
tx *bolt.Tx
buckets map[string]*bolt.Bucket
}
你可以看到在整个结构体中,除了用于保护 tx 的 txmu 读写锁之外,还存在另外一个 mu 读写锁,它的作用是保证 buf 中的数据不会出现问题,buf 和结构体中的 buckets 都是用于加速读效率的缓存。
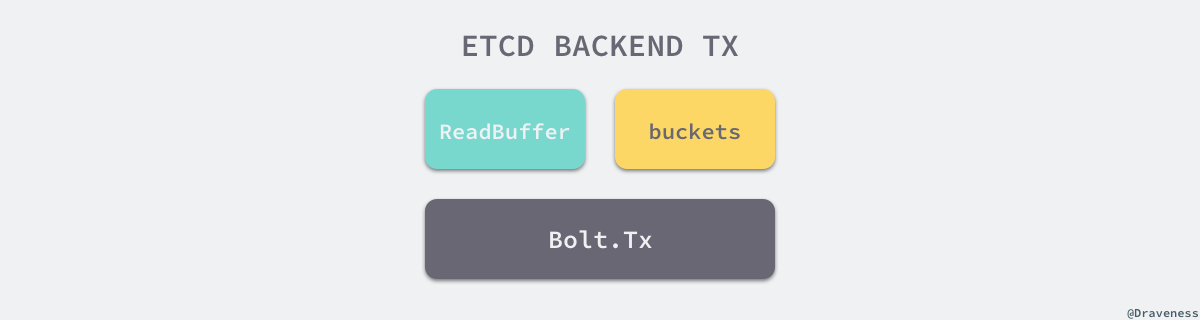
对于一个只读事务来说,它对上层提供了两个获取存储引擎中数据的接口,分别是 UnsafeRange 和 UnsafeForEach,在这里会重点介绍前面方法的实现细节:
// https://sourcegraph.com/github.com/etcd-io/etcd@1cab49e/-/blob/mvcc/backend/read_tx.go#L52-90
func (rt *readTx) UnsafeRange(bucketName, key, endKey []byte, limit int64) ([][]byte, [][]byte) {
if endKey == nil {
limit = 1
}
keys, vals := rt.buf.Range(bucketName, key, endKey, limit)
if int64(len(keys)) == limit {
return keys, vals
}
bn := string(bucketName)
bucket, ok := rt.buckets[bn]
if !ok {
bucket = rt.tx.Bucket(bucketName)
rt.buckets[bn] = bucket
}
if bucket == nil {
return keys, vals
}
c := bucket.Cursor()
k2, v2 := unsafeRange(c, key, endKey, limit-int64(len(keys)))
return append(k2, keys...), append(v2, vals...)
}
上述代码中省略了加锁保护读缓存以及 Bucket 中存储数据的合法性,也省去了一些参数的检查,不过方法的整体接口还是没有太多变化,UnsafeRange 会先从自己持有的缓存 txReadBuffer 中读取数据,如果数据不能够满足调用者的需求,就会从 buckets 缓存中查找对应的 BoltDB bucket 并从 BoltDB 数据库中读取。
// https://sourcegraph.com/github.com/etcd-io/etcd@1cab49e/-/blob/mvcc/backend/batch_tx.go#L121-141
func unsafeRange(c *bolt.Cursor, key, endKey []byte, limit int64) (keys [][]byte, vs [][]byte) {
var isMatch func(b []byte) bool
if len(endKey) > 0 {
isMatch = func(b []byte) bool { return bytes.Compare(b, endKey) < 0 }
} else {
isMatch = func(b []byte) bool { return bytes.Equal(b, key) }
limit = 1
}
for ck, cv := c.Seek(key); ck != nil && isMatch(ck); ck, cv = c.Next() {
vs = append(vs, cv)
keys = append(keys, ck)
if limit == int64(len(keys)) {
break
}
}
return keys, vs
}
这个包内部的函数 unsafeRange 实际上通过 BoltDB 中的游标来遍历满足查询条件的键值对。
到这里为止,整个只读事务提供的接口就基本介绍完了,在 etcd 中无论我们想要后去单个 Key 还是一个范围内的 Key 最终都是通过 Range 来实现的,这其实也是只读事务的最主要功能。
读写事务
只读事务只提供了读数据的能力,包括 UnsafeRange 和 UnsafeForeach,而读写事务 BatchTx 提供的就是读和写数据的能力了:
// https://sourcegraph.com/github.com/etcd-io/etcd@1cab49e/-/blob/mvcc/backend/batch_tx.go#L40-46
type batchTx struct {
sync.Mutex
tx *bolt.Tx
backend *backend
pending int
}
读写事务同时提供了不带缓存的 batchTx 实现以及带缓存的 batchTxBuffered 实现,后者其实『继承了』前者的结构体,并额外加入了缓存 txWriteBuffer 加速读请求:
// https://sourcegraph.com/github.com/etcd-io/etcd@1cab49e/-/blob/mvcc/backend/batch_tx.go#L243-246
type batchTxBuffered struct {
batchTx
buf txWriteBuffer
}
后者在实现接口规定的方法时,会直接调用 batchTx 的同名方法,并将操作造成的副作用的写入的缓存中,在这里我们并不会展开介绍这一版本的实现,还是以分析 batchTx 的方法为主。
当我们向 etcd 中写入数据时,最终都会调用 batchTx 的 unsafePut 方法将数据写入到 BoltDB 中:
// https://sourcegraph.com/github.com/etcd-io/etcd@1cab49e/-/blob/mvcc/backend/batch_tx.go#L65-67
func (t *batchTx) UnsafePut(bucketName []byte, key []byte, value []byte) {
t.unsafePut(bucketName, key, value, false)
}
// https://sourcegraph.com/github.com/etcd-io/etcd@1cab49e/-/blob/mvcc/backend/batch_tx.go#L74-103
func (t *batchTx) unsafePut(bucketName []byte, key []byte, value []byte, seq bool) {
bucket := t.tx.Bucket(bucketName)
if err := bucket.Put(key, value); err != nil {
plog.Fatalf("cannot put key into bucket (%v)", err)
}
t.pending++
}
这两个方法的实现非常清晰,作者觉得他们都并不值得展开详细介绍,只是调用了 BoltDB 提供的 API 操作一下 bucket 中的数据,而另一个删除方法的实现与这个也差不多:
// https://sourcegraph.com/github.com/etcd-io/etcd@1cab49e/-/blob/mvcc/backend/batch_tx.go#L144-169
func (t *batchTx) UnsafeDelete(bucketName []byte, key []byte) {
bucket := t.tx.Bucket(bucketName)
err := bucket.Delete(key)
if err != nil {
plog.Fatalf("cannot delete key from bucket (%v)", err)
}
t.pending++
}
它们都是通过 Bolt.Tx 找到对应的 Bucket,然后做出相应的增删操作,但是这写请求在这两个方法执行后其实并没有提交,我们还需要手动或者等待 etcd 自动将请求提交:
// https://sourcegraph.com/github.com/etcd-io/etcd@1cab49e/-/blob/mvcc/backend/batch_tx.go#L184-188
func (t *batchTx) Commit() {
t.Lock()
t.commit(false)
t.Unlock()
}
// https://sourcegraph.com/github.com/etcd-io/etcd@1cab49e/-/blob/mvcc/backend/batch_tx.go#L210-241
func (t *batchTx) commit(stop bool) {
if t.tx != nil {
if t.pending == 0 && !stop {
return
}
start := time.Now()
err := t.tx.Commit()
rebalanceSec.Observe(t.tx.Stats().RebalanceTime.Seconds())
spillSec.Observe(t.tx.Stats().SpillTime.Seconds())
writeSec.Observe(t.tx.Stats().WriteTime.Seconds())
commitSec.Observe(time.Since(start).Seconds())
atomic.AddInt64(&t.backend.commits, 1)
t.pending = 0
}
if !stop {
t.tx = t.backend.begin(true)
}
}
在每次调用 Commit 对读写事务进行提交时,都会先检查是否有等待中的事务,然后会将数据上报至 Prometheus 中,其他的服务就可以将 Prometheus 作为数据源对 etcd 的执行状况进行监控了。
索引
经常使用 etcd 的开发者可能会了解到,它本身对于每一个键值对都有一个 revision 的概念,键值对的每一次变化都会被 BoltDB 单独记录下来,所以想要在存储引擎中获取某一个 Key 对应的值,要先获取 revision,再通过它才能找到对应的值,在里我们想要介绍的其实是 etcd 如何管理和存储一个 Key 的多个 revision 记录。
在 etcd 服务中有一个用于存储所有的键值对 revision 信息的 btree,我们可以通过 index 的 Get 接口获取一个 Key 对应 Revision 的值:
// https://sourcegraph.com/github.com/etcd-io/etcd@1cab49e/-/blob/mvcc/index.go#L68-76
func (ti *treeIndex) Get(key []byte, atRev int64) (modified, created revision, ver int64, err error) {
keyi := &keyIndex{key: key}
if keyi = ti.keyIndex(keyi); keyi == nil {
return revision{}, revision{}, 0, ErrRevisionNotFound
}
return keyi.get(ti.lg, atRev)
}
上述方法通过 keyIndex 方法查找 Key 对应的 keyIndex 结构体,这里使用的内存结构体 btree 是 Google 实现的一个版本:
// https://sourcegraph.com/github.com/etcd-io/etcd@1cab49e/-/blob/mvcc/index.go#L84-89
func (ti *treeIndex) keyIndex(keyi *keyIndex) *keyIndex {
if item := ti.tree.Get(keyi); item != nil {
return item.(*keyIndex)
}
return nil
}
可以看到这里的实现非常简单,只是从 treeIndex 持有的成员 btree 中查找 keyIndex,将结果强制转换成 keyIndex 类型后返回;获取 Key 对应 revision 的方式也非常简单:
// https://sourcegraph.com/github.com/etcd-io/etcd@1cab49e/-/blob/mvcc/key_index.go#L149-171
func (ki *keyIndex) get(lg *zap.Logger, atRev int64) (modified, created revision, ver int64, err error) {
g := ki.findGeneration(atRev)
if g.isEmpty() {
return revision{}, revision{}, 0, ErrRevisionNotFound
}
n := g.walk(func(rev revision) bool { return rev.main > atRev })
if n != -1 {
return g.revs[n], g.created, g.ver - int64(len(g.revs)-n-1), nil
}
return revision{}, revision{}, 0, ErrRevisionNotFound
}
KeyIndex
在我们具体介绍方法实现的细节之前,首先我们需要理解 keyIndex 包含的字段以及管理同一个 Key 不同版本的方式:
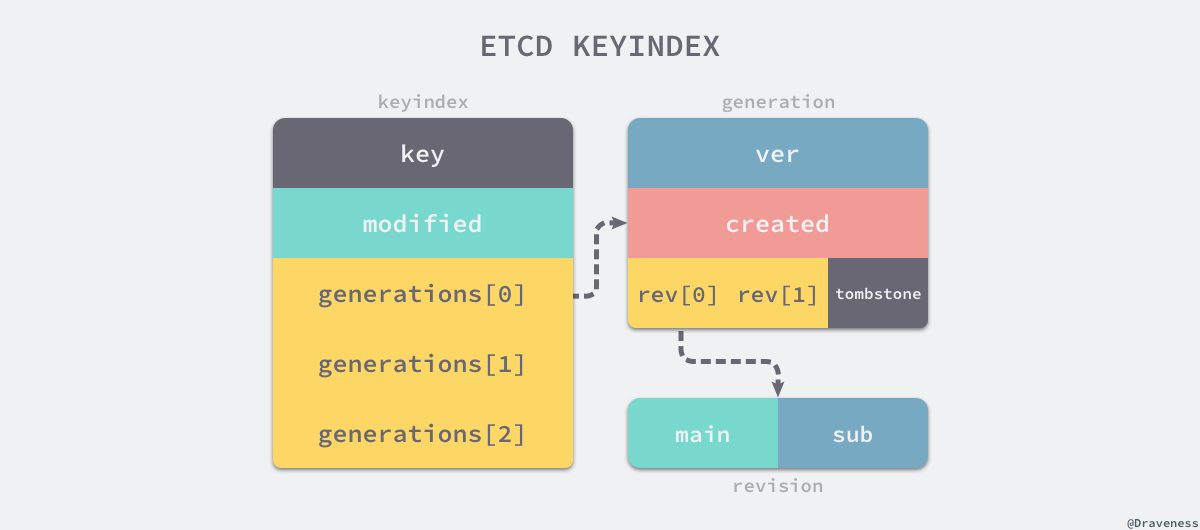
每一个 keyIndex 结构体中都包含当前键的值以及最后一次修改对应的 revision 信息,其中还保存了一个 Key 的多个 generation,每一个 generation 都会记录当前 Key『从生到死』的全部过程,每当一个 Key 被删除时都会调用 timestone 方法向当前的 generation 中追加一个新的墓碑版本:
// https://sourcegraph.com/github.com/etcd-io/etcd@1cab49e/-/blob/mvcc/key_index.go#L127-145
func (ki *keyIndex) tombstone(lg *zap.Logger, main int64, sub int64) error {
if ki.generations[len(ki.generations)-1].isEmpty() {
return ErrRevisionNotFound
}
ki.put(lg, main, sub)
ki.generations = append(ki.generations, generation{})
return nil
}
这个 tombstone 版本标识这当前的 Key 已经被删除了,但是在每次删除一个 Key 之后,就会在当前的 keyIndex 中创建一个新的 generation 结构用于存储新的版本信息,其中 ver 记录当前 generation 包含的修改次数,created 记录创建 generation 时的 revision 版本,最后的 revs 用于存储所有的版本信息。
读操作
etcd 中所有的查询请求,无论是查询一个还是多个、是数量还是键值对,最终都会调用 rangeKeys 方法:
// https://sourcegraph.com/github.com/etcd-io/etcd@1cab49e/-/blob/mvcc/kvstore_txn.go#L112-165
func (tr *storeTxnRead) rangeKeys(key, end []byte, curRev int64, ro RangeOptions) (*RangeResult, error) {
rev := ro.Rev
revpairs := tr.s.kvindex.Revisions(key, end, rev)
if len(revpairs) == 0 {
return &RangeResult{KVs: nil, Count: 0, Rev: curRev}, nil
}
kvs := make([]mvccpb.KeyValue, int(ro.Limit))
revBytes := newRevBytes()
for i, revpair := range revpairs[:len(kvs)] {
revToBytes(revpair, revBytes)
_, vs := tr.tx.UnsafeRange(keyBucketName, revBytes, nil, 0)
kvs[i].Unmarshal(vs[0])
}
return &RangeResult{KVs: kvs, Count: len(revpairs), Rev: curRev}, nil
}
为了获取一个范围内的所有键值对,我们首先需要通过 Revisions 函数从 btree 中获取范围内所有的 keyIndex:
// https://sourcegraph.com/github.com/etcd-io/etcd@1cab49e/-/blob/mvcc/index.go#L106-120
func (ti *treeIndex) Revisions(key, end []byte, atRev int64) (revs []revision) {
if end == nil {
rev, _, _, err := ti.Get(key, atRev)
if err != nil {
return nil
}
return []revision{rev}
}
ti.visit(key, end, func(ki *keyIndex) {
if rev, _, _, err := ki.get(ti.lg, atRev); err == nil {
revs = append(revs, rev)
}
})
return revs
}
如果只需要获取一个 Key 对应的版本,就是直接使用 treeIndex 的方法,但是当上述方法会从 btree 索引中获取一个连续多个 revision 值时,就会调用 keyIndex.get 来遍历整颗树并选取合适的版本:
func (ki *keyIndex) get(lg *zap.Logger, atRev int64) (modified, created revision, ver int64, err error) {
g := ki.findGeneration(atRev)
if g.isEmpty() {
return revision{}, revision{}, 0, ErrRevisionNotFound
}
n := g.walk(func(rev revision) bool { return rev.main > atRev })
if n != -1 {
return g.revs[n], g.created, g.ver - int64(len(g.revs)-n-1), nil
}
return revision{}, revision{}, 0, ErrRevisionNotFound
}
因为每一个 Key 的 keyIndex 中其实都存储着多个 generation,我们需要根据传入的参数返回合适的 generation 并从其中返回主版本大于 atRev 的 revision 结构。
对于上层的键值存储来说,它会利用这里返回的 revision 从真正存储数据的 BoltDB 中查询当前 Key 对应 revision 的结果。
写操作
当我们向 etcd 中插入数据时,会使用传入的 key 构建一个 keyIndex 结构体并从树中获取相关版本等信息:
// https://sourcegraph.com/github.com/etcd-io/etcd@1cab49e/-/blob/mvcc/index.go#L53-66
func (ti *treeIndex) Put(key []byte, rev revision) {
keyi := &keyIndex{key: key}
item := ti.tree.Get(keyi)
if item == nil {
keyi.put(ti.lg, rev.main, rev.sub)
ti.tree.ReplaceOrInsert(keyi)
return
}
okeyi := item.(*keyIndex)
okeyi.put(ti.lg, rev.main, rev.sub)
}
treeIndex.Put 在获取内存中的 keyIndex 结构之后会通过 keyIndex.put 其中加入新的 revision:
// https://sourcegraph.com/github.com/etcd-io/etcd@1cab49e/-/blob/mvcc/key_index.go#L77-104
func (ki *keyIndex) put(lg *zap.Logger, main int64, sub int64) {
rev := revision{main: main, sub: sub}
if len(ki.generations) == 0 {
ki.generations = append(ki.generations, generation{})
}
g := &ki.generations[len(ki.generations)-1]
if len(g.revs) == 0 {
g.created = rev
}
g.revs = append(g.revs, rev)
g.ver++
ki.modified = rev
}
每一个新 revision 结构体写入 keyIndex 时,都会改变当前 generation 的 created 和 ver 等参数,从这个方法中我们就可以了解到 generation 中的各个成员都是如何被写入的。
写入的操作除了增加之外,删除某一个 Key 的函数也会经常被调用:
// https://sourcegraph.com/github.com/etcd-io/etcd@1cab49e/-/blob/mvcc/kvstore_txn.go#L252-309
func (tw *storeTxnWrite) delete(key []byte) {
ibytes := newRevBytes()
idxRev := revision{main: tw.beginRev + 1, sub: int64(len(tw.changes))}
revToBytes(idxRev, ibytes)
ibytes = appendMarkTombstone(tw.storeTxnRead.s.lg, ibytes)
kv := mvccpb.KeyValue{Key: key}
d, _ := kv.Marshal()
tw.tx.UnsafeSeqPut(keyBucketName, ibytes, d)
tw.s.kvindex.Tombstone(key, idxRev)
tw.changes = append(tw.changes, kv)
}
正如我们在文章前面所介绍的,删除操作会向结构体中的 generation 追加一个新的 tombstone 标记,用于标识当前的 Key 已经被删除;除此之外,上述方法还会将每一个更新操作的 revision 存到单独的 keyBucketName 中。
索引的恢复
因为在 etcd 中,所有的 keyIndex 都是在内存的 btree 中存储的,所以在启动服务时需要从 BoltDB 中将所有的数据都加载到内存中,在这里就会初始化一个新的 btree 索引,然后调用 restore 方法开始恢复索引:
// https://sourcegraph.com/github.com/etcd-io/etcd@1cab49e/-/blob/mvcc/kvstore.go#L321-433
func (s *store) restore() error {
min, max := newRevBytes(), newRevBytes()
revToBytes(revision{main: 1}, min)
revToBytes(revision{main: math.MaxInt64, sub: math.MaxInt64}, max)
tx := s.b.BatchTx()
rkvc, revc := restoreIntoIndex(s.lg, s.kvindex)
for {
keys, vals := tx.UnsafeRange(keyBucketName, min, max, int64(restoreChunkKeys))
if len(keys) == 0 {
break
}
restoreChunk(s.lg, rkvc, keys, vals, keyToLease)
newMin := bytesToRev(keys[len(keys)-1][:revBytesLen])
newMin.sub++
revToBytes(newMin, min)
}
close(rkvc)
s.currentRev = <-revc
return nil
}
在恢复索引的过程中,有一个用于遍历不同键值的『生产者』循环,其中由 UnsafeRange 和 restoreChunk 两个方法构成,这两个方法会从 BoltDB 中遍历数据,然后将键值对传到 rkvc 中,交给 restoreIntoIndex 方法中创建的 goroutine 处理:
// https://sourcegraph.com/github.com/etcd-io/etcd@1cab49e/-/blob/mvcc/kvstore.go#L486-506
func restoreChunk(lg *zap.Logger, kvc chan<- revKeyValue, keys, vals [][]byte, keyToLease map[string]lease.LeaseID) {
for i, key := range keys {
rkv := r evKeyValue{key: key}
_ := rkv.kv.Unmarshal(vals[i])
rkv.kstr = string(rkv.kv.Key)
if isTombstone(key) {
delete(keyToLease, rkv.kstr)
} else if lid := lease.LeaseID(rkv.kv.Lease); lid != lease.NoLease {
keyToLease[rkv.kstr] = lid
} else {
delete(keyToLease, rkv.kstr)
}
kvc <- rkv
}
}
先被调用的 restoreIntoIndex 方法会创建一个用于接受键值对的 Channel,在这之后会在一个 goroutine 中处理从 Channel 接收到的数据,并将这些数据恢复到内存里的 btree 中:
// https://sourcegraph.com/github.com/etcd-io/etcd@1cab49e/-/blob/mvcc/kvstore.go#L441-484
func restoreIntoIndex(lg *zap.Logger, idx index) (chan<- revKeyValue, <-chan int64) {
rkvc, revc := make(chan revKeyValue, restoreChunkKeys), make(chan int64, 1)
go func() {
currentRev := int64(1)
defer func() { revc <- currentRev }()
for rkv := range rkvc {
ki = &keyIndex{key: rkv.kv.Key}
ki := idx.KeyIndex(ki)
rev := bytesToRev(rkv.key)
currentRev = rev.main
if ok {
if isTombstone(rkv.key) {
ki.tombstone(lg, rev.main, rev.sub)
continue
}
ki.put(lg, rev.main, rev.sub)
} else if !isTombstone(rkv.key) {
ki.restore(lg, revision{rkv.kv.CreateRevision, 0}, rev, rkv.kv.Version)
idx.Insert(ki)
}
}
}()
return rkvc, revc
}
恢复内存索引的相关代码在实现上非常值得学习,两个不同的函数通过 Channel 进行通信并使用 goroutine 处理任务,能够很好地将消息的『生产者』和『消费者』进行分离。

Channel 作为整个恢复索引逻辑的一个消息中心,它将遍历 BoltDB 中的数据和恢复索引两部分代码进行了分离。
存储
etcd 的 mvcc 模块对外直接提供了两种不同的访问方式,一种是键值存储 kvstore,另一种是 watchableStore 它们都实现了包内公开的 KV 接口:
// https://sourcegraph.com/github.com/etcd-io/etcd@1cab49e/-/blob/mvcc/kv.go#L100-125
type KV interface {
ReadView
WriteView
Read() TxnRead
Write() TxnWrite
Hash() (hash uint32, revision int64, err error)
HashByRev(rev int64) (hash uint32, revision int64, compactRev int64, err error)
Compact(rev int64) (<-chan struct{}, error)
Commit()
Restore(b backend.Backend) error
Close() error
}
kvstore
对于 kvstore 来说,其实没有太多值得展开介绍的地方,它利用底层的 BoltDB 等基础设施为上层提供最常见的增伤改查,它组合了下层的 readTx、batchTx 等结构体,将一些线程不安全的操作变成线程安全的。
// https://sourcegraph.com/github.com/etcd-io/etcd@1cab49e/-/blob/mvcc/kvstore_txn.go#L32-40
func (s *store) Read() TxnRead {
s.mu.RLock()
tx := s.b.ReadTx()
s.revMu.RLock()
tx.Lock()
firstRev, rev := s.compactMainRev, s.currentRev
s.revMu.RUnlock()
return newMetricsTxnRead(&storeTxnRead{s, tx, firstRev, rev})
}
它也负责对内存中 btree 索引的维护以及压缩一些无用或者不常用的数据,几个对外的接口 Read、Write 就是对 readTx、batchTx 等结构体的组合并将它们的接口暴露给其他的模块。
watchableStore
另外一个比较有意思的存储就是 watchableStore 了,它是 mvcc 模块为外界提供 Watch 功能的接口,它负责了注册、管理以及触发 Watcher 的功能,我们先来看一下这个结构体的各个字段:
// https://sourcegraph.com/github.com/etcd-io/etcd@1cab49e/-/blob/mvcc/watchable_store.go#L45-65
type watchableStore struct {
*store
mu sync.RWMutex
unsynced watcherGroup
synced watcherGroup
stopc chan struct{}
wg sync.WaitGroup
}
每一个 watchableStore 其实都组合了来自 store 结构体的字段和方法,除此之外,还有两个 watcherGroup 类型的字段,其中 unsynced 用于存储未同步完成的实例,synced 用于存储已经同步完成的实例。
在初始化一个新的 watchableStore 时,我们会创建一个用于同步watcherGroup 的 Goroutine,在 syncWatchersLoop 这个循环中会每隔 100ms 调用一次 syncWatchers 方法,将所有未通知的事件通知给所有的监听者,这可以说是整个模块的核心:
func (s *watchableStore) syncWatchers() int {
curRev := s.store.currentRev
compactionRev := s.store.compactMainRev
wg, minRev := s.unsynced.choose(maxWatchersPerSync, curRev, compactionRev)
minBytes, maxBytes := newRevBytes(), newRevBytes()
revToBytes(revision{main: minRev}, minBytes)
revToBytes(revision{main: curRev + 1}, maxBytes)
tx := s.store.b.ReadTx()
revs, vs := tx.UnsafeRange(keyBucketName, minBytes, maxBytes, 0)
evs := kvsToEvents(nil, wg, revs, vs)
wb := newWatcherBatch(wg, evs)
for w := range wg.watchers {
w.minRev = curRev + 1
eb, ok := wb[w]
if !ok {
s.synced.add(w)
s.unsynced.delete(w)
continue
}
w.send(WatchResponse{WatchID: w.id, Events: eb.evs, Revision: curRev})
s.synced.add(w)
s.unsynced.delete(w)
}
return s.unsynced.size()
}
简化后的 syncWatchers 方法中总共做了三件事情,首先是根据当前的版本从未同步的 watcherGroup 中选出一些待处理的任务,然后从 BoltDB 中后去当前版本范围内的数据变更并将它们转换成事件,事件和 watcherGroup 在打包之后会通过 send 方法发送到每一个 watcher 对应的 Channel 中。
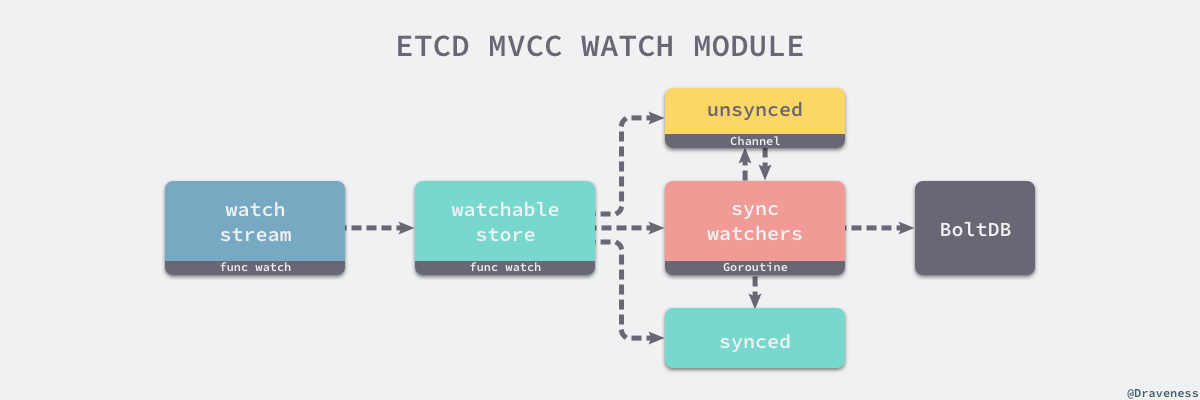
上述图片中展示了 mvcc 模块对于向外界提供的监听某个 Key 和范围的接口,外部的其他模块会通过 watchStream.watch 函数与模块内部进行交互,每一次调用 watch 方法最终都会向 watchableStore 持有的 watcherGroup 中添加新的 watcher 结构。
// https://sourcegraph.com/github.com/etcd-io/etcd@1cab49e/-/blob/mvcc/watcher.go#L108-135
func (ws *watchStream) Watch(id WatchID, key, end []byte, startRev int64, fcs ...FilterFunc) (WatchID, error) {
if id == AutoWatchID {
for ws.watchers[ws.nextID] != nil {
ws.nextID++
}
id = ws.nextID
ws.nextID++
}
w, c := ws.watchable.watch(key, end, startRev, id, ws.ch, fcs...)
ws.cancels[id] = c
ws.watchers[id] = w
return id, nil
}
// https://sourcegraph.com/github.com/etcd-io/etcd@1cab49e/-/blob/mvcc/watchable_store.go#L111-142
func (s *watchableStore) watch(key, end []byte, startRev int64, id WatchID, ch chan<- WatchResponse, fcs ...FilterFunc) (*watcher, cancelFunc) {
wa := &watcher{
key: key,
end: end,
minRev: startRev,
id: id,
ch: ch,
fcs: fcs,
}
synced := startRev > s.store.currentRev || startRev == 0
if synced {
s.synced.add(wa)
} else {
s.unsynced.add(wa)
}
return wa, func() { s.cancelWatcher(wa) }
}
当 etcd 服务启动时,会在服务端运行一个用于处理监听事件的 watchServer gRPC 服务,客户端的 Watch 请求最终都会被转发到这个服务的 Watch 函数中:
// https://sourcegraph.com/github.com/etcd-io/etcd@1cab49e/-/blob/etcdserver/api/v3rpc/watch.go#L136-206
func (ws *watchServer) Watch(stream pb.Watch_WatchServer) (err error) {
sws := serverWatchStream{
// ...
gRPCStream: stream,
watchStream: ws.watchable.NewWatchStream(),
ctrlStream: make(chan *pb.WatchResponse, ctrlStreamBufLen),
}
sws.wg.Add(1)
go func() {
sws.sendLoop()
sws.wg.Done()
}()
go func() {
sws.recvLoop()
}()
sws.wg.Wait()
return err
}
当客户端想要通过 Watch 结果监听某一个 Key 或者一个范围的变动,在每一次客户端调用服务端上述方式都会创建两个 Goroutine,这两个协程一个会负责向监听者发送数据变动的事件,另一个协程会负责处理客户端发来的事件。
// https://sourcegraph.com/github.com/etcd-io/etcd@1cab49e/-/blob/etcdserver/api/v3rpc/watch.go#L220-334
func (sws *serverWatchStream) recvLoop() error {
for {
req, err := sws.gRPCStream.Recv()
if err == io.EOF {
return nil
}
if err != nil {
return err
}
switch uv := req.RequestUnion.(type) {
case *pb.WatchRequest_CreateRequest:
creq := uv.CreateRequest
filters := FiltersFromRequest(creq)
wsrev := sws.watchStream.Rev()
rev := creq.StartRevision
id, _ := sws.watchStream.Watch(mvcc.WatchID(creq.WatchId), creq.Key, creq.RangeEnd, rev, filters...)
wr := &pb.WatchResponse{
Header: sws.newResponseHeader(wsrev),
WatchId: int64(id),
Created: true,
Canceled: err != nil,
}
select {
case sws.ctrlStream <- wr:
case <-sws.closec:
return nil
}
case *pb.WatchRequest_CancelRequest: // ...
case *pb.WatchRequest_ProgressRequest: // ...
default:
continue
}
}
}
在用于处理客户端的 recvLoop 方法中调用了 mvcc 模块暴露出的 watchStream.Watch 方法,该方法会返回一个可以用于取消监听事件的 watchID;当 gRPC 流已经结束后者出现错误时,当前的循环就会返回,两个 Goroutine 也都会结束。
如果出现了更新或者删除事件,就会被发送到 watchStream 持有的 Channel 中,而 sendLoop 会通过 select 来监听多个 Channel 中的数据并将接收到的数据封装成 pb.WatchResponse 结构并通过 gRPC 流发送给客户端:
func (sws *serverWatchStream) sendLoop() {
for {
select {
case wresp, ok := <-sws.watchStream.Chan():
evs := wresp.Events
events := make([]*mvccpb.Event, len(evs))
for i := range evs {
events[i] = &evs[i] }
canceled := wresp.CompactRevision != 0
wr := &pb.WatchResponse{
Header: sws.newResponseHeader(wresp.Revision),
WatchId: int64(wresp.WatchID),
Events: events,
CompactRevision: wresp.CompactRevision,
Canceled: canceled,
}
sws.gRPCStream.Send(wr)
case c, ok := <-sws.ctrlStream: // ...
case <-progressTicker.C: // ...
case <-sws.closec:
return
}
}
}
对于每一个 Watch 请求来说,watchServer 会根据请求创建两个用于处理当前请求的 Goroutine,这两个协程会与更底层的 mvcc 模块协作提供监听和回调功能:
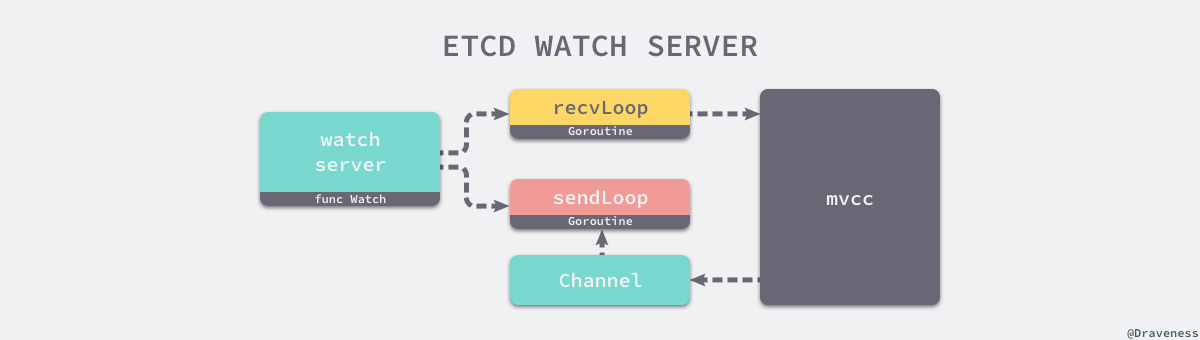
到这里,我们对于 Watch 功能的介绍就差不多结束了,从对外提供的接口到底层的使用的数据结构以及具体实现,其他与 Watch 功能相关的话题可以直接阅读 etcd 的源代码了解更加细节的实现。
应用
在上面已经介绍了核心的 Raft 共识算法以及使用的底层存储之后,这一节更想谈一谈 etcd 的一些应用场景,与之前谈到的 分布式协调服务 Zookeeper 一样,etcd 在大多数的集群中还是处于比较关键的位置,工程师往往都会使用 etcd 存储集群中的重要数据和元数据,多个节点之间的强一致性以及集群部署的方式赋予了 etcd 集群高可用性。
我们依然可以使用 etcd 实现微服务架构中的服务发现、发布订阅、分布式锁以及分布式协调等功能,因为虽然它被定义成了一个可靠的分布式键值存储,但是它起到的依然是一个分布式协调服务的作用,这也使我们在需要不同的协调服务中进行权衡和选择。
为什么要在分布式协调服务中选择 etcd 其实是一个比较关键的问题,很多工程师选择 etcd 主要是因为它使用 Go 语言开发、部署简单、社区也比较活跃,但是缺点就在于它相比 Zookeeper 还是一个比较年轻的项目,需要一些时间来成长和稳定。
总结
etcd 的实现原理非常有趣,我们能够在它的源代码中学习很多 Go 编程的最佳实践和设计,这也值得我们去研究它的源代码。
目前很多项目和公司都在生产环境中大规模使用 etcd,这对于社区来说是意见非常有利的事情,如果微服务的大部分技术栈是 Go,作者也更加推荐各位读者在选择分布式协调服务时选择 etcd 作为系统的基础设施。
相关文章
- 基础
- 数据库
- 分布式协调 & 服务发现
- 容器编排
- 谈 Kubernetes 的架构设计与实现原理
- 从 Kubernetes 中的对象谈起
- 详解 Kubernetes Pod 的实现原理
- 详解 Kubernetes Service 的实现原理
- 详解 Kubernetes Volume 的实现原理
- 详解 Kubernetes ReplicaSet 的实现原理
- 详解 Kubernetes Deployment 的实现原理
- 详解 Kubernetes StatefulSet 的实现原理
- 详解 Kubernetes DaemonSet 的实现原理
- 详解 Kubernetes Job 和 CronJob 的实现原理
- 详解 Kubernetes 垃圾收集器 的实现原理
Reference
- etcd · GitHub
- etcd Documentation
- The Raft Consensus Algorithm
- In Search of an Understandable Consensus Algorithm
- 详解分布式协调服务 ZooKeeper
关于图片和转载

本作品采用知识共享署名 4.0 国际许可协议进行许可。 转载时请注明原文链接,图片在使用时请保留图片中的全部内容,可适当缩放并在引用处附上图片所在的文章链接,图片使用 Sketch 进行绘制。
有疑问加站长微信联系(非本文作者)



