uid是服务端给客户端种下的cookie。比如访问百度,同一台电脑同一个浏览器,不管是百度哪个页面,都是这个uid: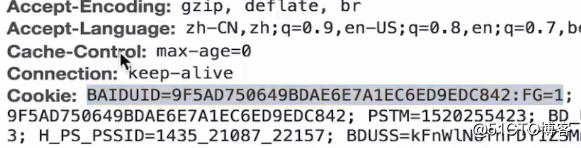
区分PV、IV、UV如下:
1、pv访问量(Page View),即页面访问量,每打开一次页面PV计数+1,刷新页面也是。2、UV访问数(Unique Visitor)指独立访客访问数,一台电脑终端为一个访客。
3、IV是初始向量(IV,Initialization Vector)。
redis数据结构HyperLogLog
如果我们要实现记录网站每天访问的独立IP数量这样的一个功能集合实现:
使用集合来储存每个访客的 IP ,通过集合性质(集合中的每个元素都各不相同)来得到多个独立 IP ,
然后通过调用 SCARD 命令来得出独立 IP 的数量。
举个例子,程序可以使用以下代码来记录 2014 年 8 月 15 日,每个网站访客的 IP :
ip = get_vistor_ip()
SADD '2014.8.15::unique::ip' ip
然后使用以下代码来获得当天的唯一 IP 数量:
SCARD '2014.8.15::unique::ip'集合实现的问题
使用字符串来储存每个 IPv4 地址最多需要耗费 15 字节(格式为 'XXX.XXX.XXX.XXX' ,比如
'202.189.128.186')。
下表给出了使用集合记录不同数量的独立 IP 时,需要耗费的内存数量:
独立 IP 数量一天一个月一年
一百万15 MB 450 MB 5.4 GB
一千万150 MB 4.5 GB 54 GB
一亿1.5 GB 45 GB 540 GB
随着集合记录的 IP 越来越多,消耗的内存也会越来越多。
另外如果要储存 IPv6 地址的话,需要的内存还会更多一些为了更好地解决像独立 IP 地址计算这种问题,
Redis 在 2.8.9 版本添加了 HyperLogLog 结构。HyperLogLog介绍
HyperLogLog 可以接受多个元素作为输入,并给出输入元素的基数估算值:
• 基数:集合中不同元素的数量。比如 {'apple', 'banana', 'cherry', 'banana', 'apple'} 的基数就是 3 。
• 估算值:算法给出的基数并不是精确的,可能会比实际稍微多一些或者稍微少一些,但会控制在合
理的范围之内。
HyperLogLog 的优点是,即使输入元素的数量或者体积非常非常大,计算基数所需的空间总是固定
的、并且是很小的。
在 Redis 里面,每个 HyperLogLog 键只需要花费 12 KB 内存,就可以计算接近 2^64 个不同元素的基
数。这和计算基数时,元素越多耗费内存就越多的集合形成鲜明对比。
但是,因为 HyperLogLog 只会根据输入元素来计算基数,而不会储存输入元素本身,所以
HyperLogLog 不能像集合那样,返回输入的各个元素。将元素添加至 HyperLogLog
PFADD key element [element ...]
将任意数量的元素添加到指定的 HyperLogLog 里面。
这个命令可能会对 HyperLogLog 进行修改,以便反映新的基数估算值,如果 HyperLogLog 的基数估算
值在命令执行之后出现了变化, 那么命令返回 1 , 否则返回 0 。
命令的复杂度为 O(N) ,N 为被添加元素的数量。返回给定 HyperLogLog 的基数估算值
PFCOUNT key [key ...]
当只给定一个 HyperLogLog 时,命令返回给定 HyperLogLog 的基数估算值。
当给定多个 HyperLogLog 时,命令会先对给定的 HyperLogLog 进行并集计算,得出一个合并后的
HyperLogLog ,然后返回这个合并 HyperLogLog 的基数估算值作为命令的结果(合并得出的
HyperLogLog 不会被储存,使用之后就会被删掉)。
当命令作用于单个 HyperLogLog 时, 复杂度为 O(1) , 并且具有非常低的平均常数时间。
当命令作用于多个 HyperLogLog 时, 复杂度为 O(N) ,并且常数时间也比处理单个 HyperLogLog 时要
大得多。PFADD 和 PFCOUNT 的使用示例
redis> PFADD unique::ip::counter '192.168.0.1'
(integer) 1
redis> PFADD unique::ip::counter '127.0.0.1'
(integer) 1
redis> PFADD unique::ip::counter '255.255.255.255'
(integer) 1
redis> PFCOUNT unique::ip::counter
(integer) 3合并多个 HyperLogLog
PFMERGE destkey sourcekey [sourcekey ...]
将多个 HyperLogLog 合并为一个 HyperLogLog ,合并后的 HyperLogLog 的基数估算值是通过对所有
给定 HyperLogLog 进行并集计算得出的。
命令的复杂度为 O(N) , 其中 N 为被合并的 HyperLogLog 数量, 不过这个命令的常数复杂度比较高。PFMERGE 的使用示例
redis> PFADD str1 "apple" "banana" "cherry"
(integer) 1
redis> PFCOUNT str1
(integer) 3
redis> PFADD str2 "apple" "cherry" "durian" "mongo"
(integer) 1
redis> PFCOUNT str2
(integer) 4
redis> PFMERGE str1&2 str1 str2
OK
redis> PFCOUNT str1&2
(integer) 5HyperLogLog 实现独立 IP 计算功能
独立 IP 数量一天一个月一年一年(使用集合)
一百万12 KB 360 KB 4.32 MB 5.4 GB
一千万12 KB 360 KB 4.32 MB 54 GB
一亿12 KB 360 KB 4.32 MB 540 GB
下表列出了使用 HyperLogLog 记录不同数量的独立 IP 时,需要耗费的内存数量:
可以看到,要统计相同数量的独立 IP ,HyperLogLog 所需的内存要比集合少得多。

package main
import (
"flag"
"github.com/sirupsen/logrus"
"time"
"os"
"bufio"
"io"
"strings"
"github.com/mgutz/str"
"net/url"
"crypto/md5"
"encoding/hex"
"github.com/mediocregopher/radix.v2/pool"
"strconv"
)
const HANDLE_DIG = " /dig?"
const HANDLE_MOVIE = "/movie/"
const HANDLE_LIST = "/list/"
const HANDLE_HTML = ".html"
type cmdParams struct {
logFilePath string
routineNum int
}
type digData struct{
time string
url string
refer string
ua string
}
type urlData struct {
data digData
uid string
unode urlNode
}
type urlNode struct {
unType string // 详情页 或者 列表页 或者 首页
unRid int // Resource ID 资源ID
unUrl string // 当前这个页面的url
unTime string // 当前访问这个页面的时间
}
type storageBlock struct {
counterType string
storageModel string
unode urlNode
}
var log = logrus.New()
func init() {
log.Out = os.Stdout //声明用什么输出日志
log.SetLevel( logrus.DebugLevel ) //设置日志的等级
}
func main() {
// 获取参数
logFilePath := flag.String( "logFilePath", "F:/phpStudy/PHPTutorial/nginx/logs/access.log", "log file path" ) //日志文件路径
routineNum := flag.Int( "routineNum", 5, "consumer numble by goroutine" ) //routine数量,默认为5
l := flag.String( "l", "./log.log", "this programe runtime log target file path" ) //go生成的日志存放路径
flag.Parse()
params := cmdParams{ *logFilePath, *routineNum }
// 打日志
logFd, err := os.OpenFile( *l, os.O_CREATE|os.O_WRONLY, 0644 ) //打开go生成的日志
if err == nil {
log.Out = logFd //打开出错,则用日志文件存错误信息
defer logFd.Close() //关闭文件
}
log.Infof( "Exec start." ) //提示日志文件启动
log.Infof( "Params: logFilePath=%s, routineNum=%d", params.logFilePath, params.routineNum ) //提示输入的/默认参数
// 初始化一些channel,用于数据传递
var logChannel = make(chan string, 3*params.routineNum) //读取日志文件量更大,设置为3倍
var pvChannel = make(chan urlData, params.routineNum)
var uvChannel = make(chan urlData, params.routineNum)
var storageChannel = make(chan storageBlock, params.routineNum)
// Redis Pool
redisPool, err := pool.New( "tcp", "localhost:6379", 2*params.routineNum ); //连接池,2*params.routineNum是连接池数
if err != nil{
log.Fatalln( "Redis pool created failed." )
panic(err)
} else {
//空闲时间过了后,客户端(也就是连接池和远端服务器会断开)。所以以一定的间隔去ping
go func(){
for{
redisPool.Cmd( "PING" )
time.Sleep( 3*time.Second )
}
}()
}
// 日志消费者
go readFileLinebyLine( params, logChannel )
// 创建一组日志处理
for i:=0; i<params.routineNum; i++ {
go logConsumer( logChannel, pvChannel, uvChannel )
}
// 创建PV UV 统计器
go pvCounter( pvChannel, storageChannel )
go uvCounter( uvChannel, storageChannel, redisPool )
// 可扩展的 xxxCounter(如果还有别的要统计的,则:go xxCounter(...))
// 创建 存储器
go dataStorage( storageChannel, redisPool )
time.Sleep( 1000*time.Second )
}
// HBase 劣势:列簇需要声明清楚。所以这里用redis来存储
func dataStorage( storageChannel chan storageBlock, redisPool *pool.Pool) {
for block := range storageChannel {
prefix := block.counterType + "_"
// 逐层添加,加洋葱皮的过程
// 维度: 天-小时-分钟
// 层级: 定级-大分类-小分类-终极页面
// 存储模型: Redis SortedSet
setKeys := []string{
prefix+"day_"+getTime(block.unode.unTime, "day"),
prefix+"hour_"+getTime(block.unode.unTime, "hour"),
prefix+"min_"+getTime(block.unode.unTime, "min"),
prefix+block.unode.unType+"_day_"+getTime(block.unode.unTime, "day"),
prefix+block.unode.unType+"_hour_"+getTime(block.unode.unTime, "hour"),
prefix+block.unode.unType+"_min_"+getTime(block.unode.unTime, "min"),
}
rowId := block.unode.unRid
for _,key := range setKeys {
ret, err := redisPool.Cmd( block.storageModel, key, 1, rowId ).Int()
if ret<=0 || err!=nil {
log.Errorln( "DataStorage redis storage error.", block.storageModel, key, rowId )
}
}
}
}
func pvCounter( pvChannel chan urlData, storageChannel chan storageBlock ) {
for data := range pvChannel {
sItem := storageBlock{ "pv", "ZINCRBY", data.unode }
storageChannel <- sItem
}
}
func uvCounter( uvChannel chan urlData, storageChannel chan storageBlock, redisPool *pool.Pool ) {
for data := range uvChannel {
//HyperLoglog redis
hyperLogLogKey := "uv_hpll_" + getTime(data.data.time, "day") //uv_hpll_ + 天级别的时间 组成集合中的键
ret, err := redisPool.Cmd( "PFADD", hyperLogLogKey, data.uid, "EX", 86400 ).Int()
if err!=nil {
log.Warningln( "UvCounter check redis hyperloglog failed, ", err )
}
if ret!=1 {
continue
}
sItem := storageBlock{ "uv", "ZINCRBY", data.unode }
storageChannel <- sItem
}
}
//消费一行行读取到的日志
func logConsumer( logChannel chan string, pvChannel, uvChannel chan urlData ) error {
for logStr := range logChannel {
// 切割日志字符串,扣出打点上报的数据
data := cutLogFetchData( logStr )
// uid
// 说明: 课程中模拟生成uid(不是现实环境中服务器给浏览器种下的cookie中的uid), md5(refer+ua)
hasher := md5.New()
hasher.Write( []byte( data.refer+data.ua ) )
uid := hex.EncodeToString( hasher.Sum(nil) )
// 很多解析的工作都可以放到这里完成
// ...
// ...
uData := urlData{ data, uid, formatUrl( data.url, data.time ) }
pvChannel <- uData
uvChannel <- uData
/* 如果有其他要塞入的:xxChannel <- uData */
}
return nil
}
func cutLogFetchData( logStr string ) digData {
logStr = strings.TrimSpace( logStr )
pos1 := str.IndexOf( logStr, HANDLE_DIG, 0)
if pos1==-1 {
return digData{}
}
pos1 += len( HANDLE_DIG )
pos2 := str.IndexOf( logStr, " HTTP/", pos1 )
d := str.Substr( logStr, pos1, pos2-pos1 )
urlInfo, err := url.Parse( "http://localhost/?"+d ) //url.Parse只认完整的网址,所以 加上:http://localhost/?
if err != nil {
return digData{}
}
data := urlInfo.Query()
return digData{
data.Get("time"),
data.Get("refer"),
data.Get("url"),
data.Get("ua"),
}
}
func readFileLinebyLine( params cmdParams, logChannel chan string ) error {
fd, err := os.Open( params.logFilePath ) //打开nginx日志文件
if err != nil {
log.Warningf( "ReadFileLinebyLine can't open file:%s", params.logFilePath )
return err
}
defer fd.Close() //关闭是好习惯
count := 0
bufferRead := bufio.NewReader( fd )
for {
line, err := bufferRead.ReadString( '\n' ) //一行行读
logChannel <- line //读出一行写入一次logChannel
count++
if count%(1000*params.routineNum) == 0 { //每1000*params.routineNum行日志输出一次信息到控制台
log.Infof( "ReadFileLinebyLine line: %d", count )
}
if err != nil { //error部位空有两种情况,一种是错误,一种是读到尾部了
if err == io.EOF { //读到尾部了(读完了),休息3秒钟
time.Sleep( 3*time.Second )
log.Infof( "ReadFileLinebyLine wait, raedline:%d", count ) //提醒在等待,已经读到了第n行
} else {
log.Warningf( "ReadFileLinebyLine read log error" ) //错误则打出错误
}
}
}
return nil
}
func formatUrl( url, t string ) urlNode{
// 一定从量大的着手, 详情页>列表页≥首页
pos1 := str.IndexOf( url, HANDLE_MOVIE, 0)
if pos1!=-1 {
pos1 += len( HANDLE_MOVIE )
pos2 := str.IndexOf( url, HANDLE_HTML, 0 )
idStr := str.Substr( url , pos1, pos2-pos1 )
id, _ := strconv.Atoi( idStr )
return urlNode{ "movie", id, url, t }
} else {
pos1 = str.IndexOf( url, HANDLE_LIST, 0 )
if pos1!=-1 {
pos1 += len( HANDLE_LIST )
pos2 := str.IndexOf( url, HANDLE_HTML, 0 )
idStr := str.Substr( url , pos1, pos2-pos1 )
id, _ := strconv.Atoi( idStr )
return urlNode{ "list", id, url, t }
} else {
return urlNode{ "home", 1, url, t}
} // 如果页面url有很多种,就不断在这里扩展
}
}
//去重需要在一定的时间内
func getTime( logTime, timeType string ) string {
var item string
switch timeType {
case "day":
item = "2006-01-02"
break
case "hour":
item = "2006-01-02 15"
break
case "min":
item = "2006-01-02 15:04"
break
}
t, _ := time.Parse( item, time.Now().Format(item) )
return strconv.FormatInt( t.Unix(), 10 ) //将unix时间戳转换为10位字符串
}有疑问加站长微信联系(非本文作者)



