本文基于我今年早些时候在 OSCON 所做的一场演讲。为了简明扼要,并针对我在演讲后收到的一些反馈意见进行了编辑。
谈到 Go 的时候,一个常见的说法是,Go 是一种在服务器上运行良好的语言;静态二进制文件、强大的并发性和高性能。
本文重点讨论最后两项,Go 语言和它的运行时是如何透明地让程序员编写高度可伸缩的网络服务器,而不必担心线程管理或 I/O 阻塞。
需要高效编程语言的一个依据
但在我开始技术讨论之前,我想用两个指标来说明 Go 语言的目标市场。
摩尔定律
oft mis 援引摩尔定律称,每平方英寸晶体管的数量大约每 18 个月翻一番。
然而,时钟频率却是一个功能完全不同的特性,十年 Intel 设计的 Pentium 4 就在时钟频率上达到了峰值,并在那之后 CPU 的时钟频率一直在倒退。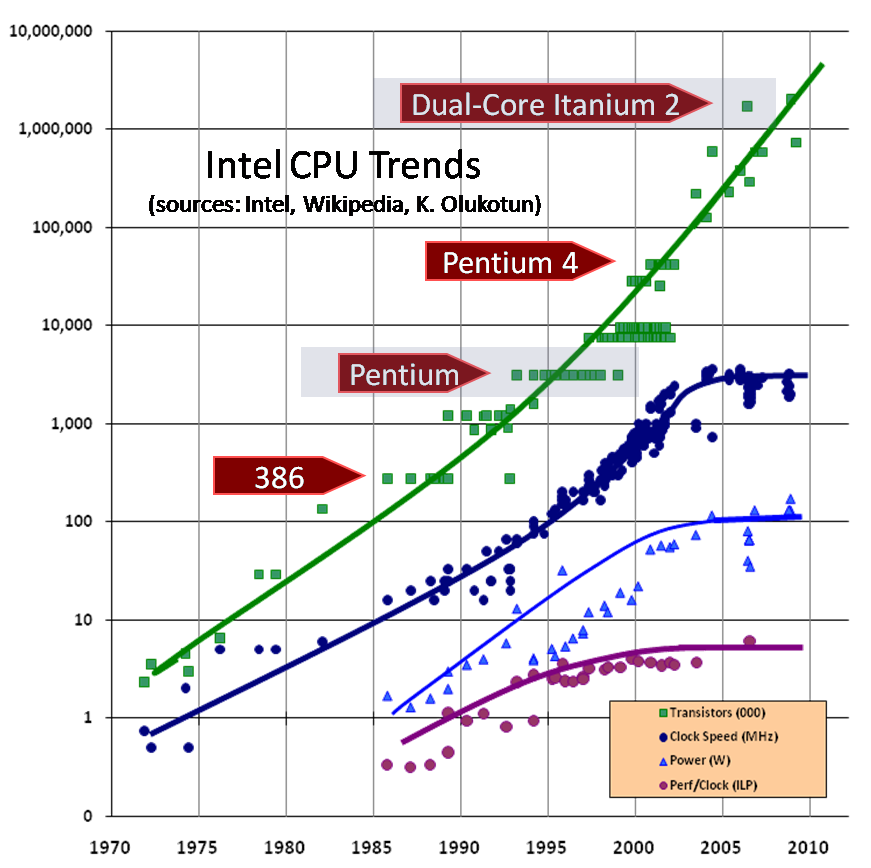
Image credit: Herb Sutter (Dr. Dobb’s Journal, March 2005)
空间和功率限制

Sun Enterprise e450—about the size of a bar fridge, about the same power consumption. Image credit: eBay
这是 SUN 公司的 e450。当我开始我的职业生涯时,他们是这个行业的主力。
这些东西是非常大的。三个这样的机器叠在一起,将装满 19 英寸的架子。它们每个功率大约 500 瓦。
在过去的十年里,数据中心已经从空间受限转向电力受限。在我参与的前两次数据中心部署中,当机架仅仅装满 1/3 时,我们就达到了用电上限。
由于计算密度提高得如此之快,数据中心空间不再是一个问题。然而,现代服务器在更小的体积内消耗了更多的能源,这使得给机房降温更加困难,但同时也是至关重要的。
在宏观层面上受到功率上限的限制,你无法为一个机架 1200 瓦 1RU serverser 获得足够的功率配额,而在微观层面上,每一个微小的硅片上消耗了数百瓦能源。
能源被消耗到哪里去了?

CMOS Inverter. Image credit: Wikipedia
这是一个反向器,可能是最简单的逻辑门之一。如果输入 A 为高,那么输出 Q 为低,反之亦然。
今天所有的消费电子产品都是用 CMOS 逻辑构建的。CMOS 代表互补金属氧化物半导体。互补部分是关键。CPU 内部的每个逻辑元件都由一对晶体管实现,一个开关打开,另一个开关关闭。
当电路接通或断开时,没有电流直接从源极流向漏极。然而,在过渡期间有一个短暂的时期,两个晶体管都导电,造成直接短路。
功耗,和因此导致的散热,与每秒晶体管状态转换的次数成正比——CPU 时钟频率。
[1]
CMOS power consumption is not only caused by the short circuit current when the circuit is switching. Additional power consumption comes from charging the output capacitance of the gate, and leakage current through the MOSFET gate increases as the size of the transistor decreases. You can read more about this from in a the lecture materials from CMU’s ECE322 course. Bill Herd has a published a series of articles on how CMOS works.
CPU 特征尺寸的降低主要是为了降低功耗。减少电力消耗并不仅仅意味着“绿色”。其主要目标是将功耗和散热保持在导致 CPU 损坏的水平以下。
随着时钟频率的下降,以及与功耗的直接冲突,性能的提高主要来自于微体系结构的调整和深奥的向量指令,它们对一般计算没有直接的用处。总的来说,每一个微架构(5 年一个周期)的变化在每一代中最多产生 10%的改进,最近只有 4-6%。
“免费午餐结束了”
希望现在你已经很清楚,硬件并没有变得更快。如果性能和规模对你很重要,那么你会同意我的观点,即至少在传统意义上,靠堆硬件来解决这个问题的日子已经结束了。正如赫伯•萨特(Herb Sutter)所言:“免费午餐结束了。”
你需要一种高效的语言,因为低效的语言在生产上,在规模上,在资本支出的基础上都是不合理的。
需要并发编程语言的一个依据
我的第二个论点紧跟着我的第一个论点。CPU 并没有变快,而是变宽了。这就是晶体管的发展方向,这并不令人惊讶。

Image credit: Intel
多线程并行,或者如 Intel 所称的超线程,允许一个内核在添加少量硬件的同时并行执行多个指令流。英特尔使用超线程来人为地细分处理器市场,甲骨文和富士通更积极地将超线程应用到他们的产品中,每个处理器核使用 8 或 16 个硬件线程。
自上世纪 90 年代末以来,Pentium Pro 就实现了 quad socket,现在大多数服务器都支持 dual socket 或者 quad socket 设计,dual socket 已成为主流。晶体管数量的增加使得整个 CPU 处理单元可以与同一硅片上的同级 CPU 处理单元共存。移动部件上的双核,桌面部件上的四核,甚至服务器部件上的更多核现在都成为了现实。在预算允许的情况下,您可以在服务器中购买尽可能多的核心。
为了利用这些额外的核心,您需要一种能有效开发出并发程序的编程语言。
处理器单元, 线程 和 goroutines
Go 有 goroutines,这是它能有效开发出并发程序的基础。我想先退一步,来看看产生 goroutines 的历史背景。
处理器单元
起初,计算机在批处理模型中一次运行一个任务。在 60 年代,对更多交互形式的计算的渴望导致了多处理,或分时操作系统的发展。到了 70 年代,这一想法已经在网络服务器、ftp、telnet、rlogin 以及后来 Tim Burners-Lee 的 CERN httpd 上得到了很好的应用,这些服务器通过划分子进程来处理每个传入的网络连接。
在分时系统中,操作系统通过记录当前进程的状态,然后恢复另一个进程的状态,从而在活动进程之间快速切换 CPU,从而保持并发的假象。这称为上下文切换。
上下文切换

Image credit: Immae (CC BY-SA 3.0)
上下文切换有三个主要成本。
- 内核需要存储该进程的所有 CPU 寄存器的内容,然后恢复另一个进程的值。因为进程切换可以在进程执行的任何位置发生,所以操作系统需要存储所有这些寄存器的内容,因为它不知道当前正在使用哪些寄存器
[2]
This is an oversimplification. In some cases the operating system can avoid saving and restoring infrequently used architectural registers by starting the the process in a mode where access to floating point or MMX/SSE registers will cause the program to fault, thereby informing the kernel that the process will now use those registers and it should from then on save and restore them. - 内核需要将 CPU 的虚拟地址刷新为物理地址映射(TLB 缓存)
[3]
Some CPUs have what is known as a tagged TLB. In the case of tagged TLB support the operating system can tell the processor to associate particular TLB cache entries with an identifier, derived from the process ID, rather than treating each cache entry as global. The upside is this avoids flushing out entries on each process switch if the process is placed back on the same CPU in short order. - 操作系统上下文切换的开销,以及选择下一个进程占用 CPU 的调度程序函数的开销。
由于与硬件相关,这些成本相对固定,并且依赖于上下文切换之间所做的工作量来摊销它们的成本-快速上下文切换往往会超过上下文切换之间所做的工作量。
线程
这导致线程的被设计开发出来,线程在概念上与进程相同,但共享相同的内存空间。由于线程共享地址空间,所以它们的调度比进程更轻松,因此创建和切换更快。
线程仍然有一个昂贵的上下文切换成本;必须保留许多状态。Goroutines 将线程的概念又向前推进了一步。
Goroutines
goroutine 不是依赖内核来管理它们之间的调度,而是通过协作的方式调度的。goroutine 之间的切换只发生在预先设计好的时间点,当显式调用 Go 运行时调度程序时。goroutine 被调度器抢占的主要原因包括:
- 在 Channel(Go 特有的语言特性,另一个是 goroutine)上产生阻塞的收发操作。
- Go 语言中 go 这个关键字的使用,虽然不能保证新的 goroutine 会立即被调度。
- 文件操作和网络操作等系统调用。
- 由于进入内存垃圾回收周期而被暂停。
换句话说,goroutine 的调度会在这些时间点发生,在不能得到更多数据,一个 goroutine 无法继续执行时; 或者是在执行环境中,一个 goroutine 需要更多内存空间时。
许多 goroutine 在 Go 运行时被多路复用到一个操作系统线程上。这使得 goroutines 的制造成本和切换成本都很低。在一个进程中有成千上万的 goroutine 是正常的,成百上千的 goroutine 是低于预期的。
从语言的角度来看,调度看起来像一个函数调用,并且具有相同的语义。编译器知道当前正在使用寄存器并自动保存它们。线程调用包含一个特定 goroutine 栈的调度器,这个调度器返回另外一个不同的 goroutine 栈。将此与线程应用程序进行比较,在线程应用程序中,可以在任何时间、任何指令抢占线程。
这导致每个 Go 进程的操作系统线程相对较少,而 Go 的 runtime 负责将一个可运行的 goroutine 分配给一个空闲的操作系统线程。
栈的管理
在前一节中,我讨论了 goroutine 如何减少管理(有时是数十万个)过多并发执行线程时的开销。goroutine 还有另一个方面,那就是堆栈管理。
进程地址空间
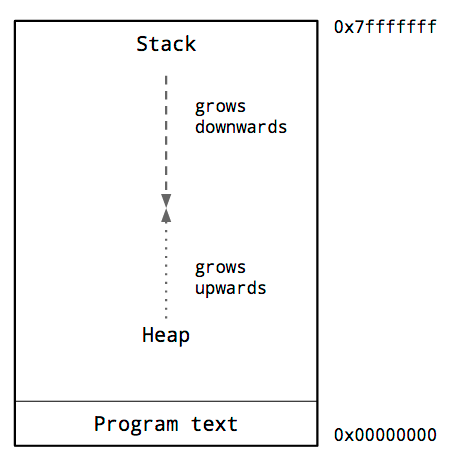
这是一个典型的进程内存布局图。我们感兴趣的关键是堆和栈的位置。
在进程的地址空间中,堆通常位于内存的底部,位于程序代码之上,并向上增长。
堆栈位于虚拟地址空间的顶部,并向下增长。
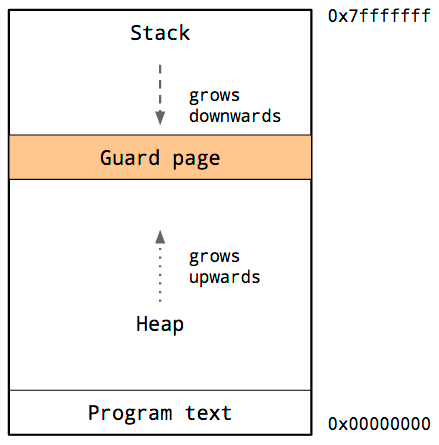
因为堆和栈相互覆盖将是灾难性的,所以操作系统在堆栈和堆之间安排了一个不可访问的内存区域。
这称为保护页,它有效地限制了进程的栈大小,通常按几兆字节的顺序。
线程栈
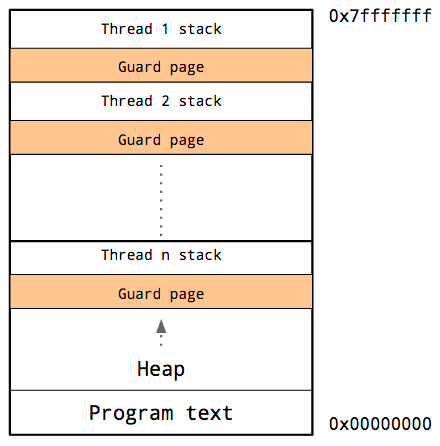
线程共享相同的地址空间,因此对于每个线程,它必须有自己的栈和自己的保护页。
由于很难预测特定线程的栈需求,因此必须为每个线程的栈保留大量内存。并寄希望于需求会比这低,同时作为警戒的保护页永远不会被触发。
缺点是,随着程序中线程数量的增加,可用地址空间的数量会减少。
管理 Goroutine 的栈
早期的进程模型允许程序员查看堆和栈,一边观察其是否足够大,而不必为此担心。缺点是复杂而昂贵的子进程模型。
线程稍微改善了这种情况,但要求程序员猜测最合适的栈大小;太小,程序将中止;太大,虚拟地址空间将耗尽。
我们已经看到,Go 运行时将大量 goroutine 调度到少量线程上,但是这些 goroutine 的栈需求如何呢?
Goroutine 栈的增长过程
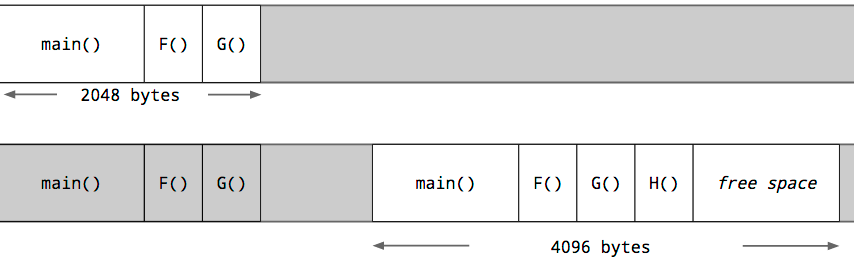
每个 goroutine 都从堆中分配的一个小尺寸的栈开始。大小随时间而变化,但在 Go 1.5 中,每一个 goroutine 都以 2k 的分配开始栈。
Go 编译器不使用保护页,而是在每个函数调用中插入一个检查,以测试是否有足够的栈空间供函数运行。如果有足够的栈空间,函数将正常运行。(在函数的汇编代码前面,由编译器插入一段检查代码。这个动作可以在函数定义前配置编译器指令,禁用掉,不过要非常非常谨慎地使用)
如果空间不足,Go 进程的 runtime 将在堆上分配一个更大的栈空间,将当前栈的内容复制到新的栈空间,释放旧的栈空间,然后重新启动函数调用。
由于这种检查,goroutine 的初始堆栈可以变得更小,这反过来又允许 Go 程序员将 goroutine 视为廉价的资源。如果有足够多的部分未被使用,Goroutine 栈也会收缩。这是在垃圾回收期间处理的。
集成的 network poller
2002 年,丹·凯格尔(Dan Kegel)发表了他所谓的c10k问题。简单地说,如何编写服务器软件来处理每天至少 10000 个 TCP 会话。自从那篇论文撰写以来,传统观点认为高性能服务器需要原生线程(native threads),而最近的几年,基于事件的循环代替了原生线程。
线程在调度成本和内存占用方面有很高的开销。事件循环降低了这些成本,但是这引入了回调驱动的复杂编程风格。
Go 为程序员提供了两全其美解决方案。
Go 对 c10k 问题给出的解决方案
在 Go 中,系统调用通常是阻塞操作,这包括读取和写入文件描述符。Go 的 runtime 调度器通过找到一个空闲线程或生成另一个线程来处理这个问题,以便在原始线程阻塞时继续为 goroutines 提供服务。实际上,这对于文件 IO 很有效,因为少量阻塞线程可以快速耗尽本地 IO 带宽。
但是对于网络套接字,按照设计,任何时候几乎所有的 goroutine 都将被阻塞,等待网络 IO。在一个简单的实现中,这将需要和 goroutine 一样多的线程,所有线程都被阻塞,等待网络流量。由于 runtime 和 net 包之间的协作,集成到 Go 的 runtime 中的 network poller 可以有效地处理这个问题。
在较早版本的 Go 中,network poller 是一个 goroutine,负责使用 kqueue 或 epoll 轮询准备就绪通知。轮询 goroutine 将通过 channel 与等待的 goroutine 通信。这实现了避免每个线程都做操作系统调用产生的瓶颈,而使用了通过 channel 发送消息这种通用唤醒机制。这意味着调度器不需要关心唤醒源,不需要把唤醒操作看的比较重要。
在 Go 的当前版本中,network poller 已经集成到 runtime 本身中。当 runtime 知道哪个 goroutine 正在等待网络套接字就绪时,它可以在数据包到达时立即将 goroutine 放回相同的 CPU 上,从而减少延迟并增加吞吐量。
Goroutines, 栈管理和被集成了的 network poller
总之,goroutines 提供了一个强大的抽象,使程序员不必担心线程池或事件循环。
goroutine 的栈已经足够大,而不需要考虑线程栈或线程池的大小。
被集成了的 network poller 允许程序员避免了复杂的回调风格代码,同时仍然利用操作系统中可用的最有效的 IO 完成逻辑。
runtime 确保有足够的线程来服务所有 goroutine 并保持 CPU 核处于活动状态。
所有这些特性对 Go 程序员来说都是透明的。
原文作者相关文章:
- Hear me speak about Go performance at OSCON
- Go 1.1 performance improvements
- Go 1.2 performance improvements
- Go 1.1 performance improvements, part 2
欢迎转载,请注明出处~
作者个人主页
有疑问加站长微信联系(非本文作者)




