Mesos 按照官方的介绍,是分布式操作系统的内核。目标是 ”Program against your datacenter like it’s a single pool of resources”,即可以将整个数据中心当做一台电脑一样使用。可以说这个目标是所有宣称自己是DCOS的系统的共同目标,本文从架构和源码层面分析Mesos以及周边框架,看看Mesos是如何实现这个目标的,当前距这个目标还有多大差距。最后比较了一下Mesos和Kubernetes这两个都受Google的Borg影响的系统的异同。
阅读对象:对Mesos或者分布式系统感兴趣的技术人
设计理念以及架构
引用Mesos paper里的一句话,来说明Mesos的设计理念:
define a minimal interface that enables efficient resource sharing across frameworks, and otherwise push control of task scheduling and execution to the frameworks
定义一个最小化的接口来支持跨框架的资源共享,其他的调度以及执行工作都委托给框架自己来控制。
这句话标志Mesos不试图作为一个一栈式解决问题的系统,而是以最小的成本来实现资源共享。先来看看官方提供的架构图:

主要组件以及概念:
- Zookeeper 主要用来实现Master的选举,支持Master的高可用。
- Master Mesos的主节点,接收Slave和Framework scheduler的注册,分配资源。
- Slave 从节点,接收master发来的task,调度executor去执行。
- Framework 比如上图中的Hadoop,MPI就是Framework,包括scheduler,executor两部分。scheduler独立运行,启动后注册到master,接收master发送的Resource Offer消息,来决定是否接受。Executor是给slave调用的,执行framework的task。Mesos内置了CommandExecutor(直接调用shell)和DockerExecutor两种executor,其他的自定义Executor需要提供uri,供slave下载。
- Task Mesos最主要的工作其实就是分配资源,然后询问scheduler是否可以利用该资源执行Task,scheduler将资源和Task绑定后交由Master发送给指定的Slave执行。Task可以是长生命周期的,也可以使用批量的短生命周期的。
官方提供的另外一个资源分配的例子:

- Slave1 向 Master 报告,有4个CPU和4 GB内存可用
- Master 发送一个 Resource Offer 给 Framework1 来描述 Slave1 有多少可用资源
- FrameWork1 中的 FW Scheduler会答复 Master,我有两个 Task 需要运行在 Slave1,一个 Task 需要<2个CPU,1 GB内存=””>,另外一个Task需要<1个CPU,2 GB内存=””>
- 最后,Master 发送这些 Tasks 给 Slave1。然后,Slave1还有1个CPU和1 GB内存没有使用,所以分配模块可以把这些资源提供给 Framework2
这个例子可以看出来,Mesos的核心工作其实很少,资源管理和分配以及task转发。调度由Framework实现,task的定义以及具体执行也由Framework实现,Mesos的资源分配粒度是按task的,但由于executor执行task可能在同一个进程中实现,所以资源限制只是一种流控的机制,并不能实际的控制到task这个粒度。
看了上面官方的架构说明,大约应该明白了Mesos的大致架构,但具体Mesos为什么要做成这样,下面我们具体分析下。
历史演进
我们把时间回退到Mesos发明的2009年,那时候Hadoop逐渐成熟,并广泛应用,正在吞噬着大家的服务器。Spark当时也在酝酿中。而服务器配置管理领域Puppet还没发布1.0,Chef才刚出现,『Configuration management Infrastructure as Code』的思想才慢慢被接受,Ansible/Salt还没出现。大家管理服务器还是静态划分的方式,购买服务器的时候就安排好了,这几台服务器上运行什么服务,应该配置多少CPU/内存/磁盘,安装维护还多用的是shell脚本。
静态管理服务器,无论是用shell还是Puppet这种工具,一方面是比较浪费资源,另外一方面服务故障恢复,服务迁移都需要人工介入,因为这种工具都只在部署时进行管理,服务进程运行后就不归部署工具管理了。而Mesos则看到了这种方式的弊端,试图实现一个资源共享的平台,提高资源利用率,实现动态运维。
按照这种方式就比较容易理解Mesos的做法,Mesos的master相当于Puppet/Salt的master,Mesos的slave相当于Puppet/Salt的agent,二者干的事情都是把指令通过master发送给slave/agent执行,区别是Puppet/Salt成功执行后就不关心了,而Mesos执行后会在Master维护task的状态,task挂掉后可以重启或者迁移。
同时Mesos看到Hadoop等分布式系统都自己实现了scheduler以及executor,所以将scheduler以及executor的具体实现让出来,通过制定Framework标准,由第三方分布式框架自己实现,自己只负责转发task到slave,由slave调用Framework的executor去执行task。
也就是说由于历史时机的问题,Mesos采用了一种保守的策略来进行演进。
资源冲突以及隔离机制
资源共享导致的首要问题就是如何解决资源冲突问题:
- cpu/mem 这个Mesos默认内置了一个Mesos Containerizer,可以通过cgroups和namespaces进行限制。
- 网络端口 Mesos默认会给每个task分配一个(可以分配多个端口)随机的未使用的端口,需要应用从环境变量中获取到这个端口进行使用,是一种约定的规则,并不强制限制。
- 文件系统 默认情况下Mesos的文件系统是多应用共享的,默认给每个task分配一个sandbox目录作为工作目录,sandbox在主机上的目录是和taskid相关的,不会冲突,生命周期和task绑定。另外也支持Persistent Volume,用于应用保存持久数据,也是通过目录映射的方式实现的。Persistent Volume的生命周期独立于task,由scheduler决定是否复用,也就是说Mesos将持久化数据和动态迁移之间的冲突问题交给了scheduler自己处理。另外可以选择使用Docker Containerizer,通过Docker的方式隔离文件系统。
- 服务发现以及负载均衡 Mesos默认不支持服务发现和负载均衡,需要用户自己实现。Mesos之上的Marathon Framework提供了一个marathon-lb,通过监听Marathon的event修改HAProxy,实现动态的负载均衡,不过只支持通过Marathon部署的应用。
- 容器的改进 Mesos内置的容器不是基于Image的,但Docker是基于Image的,带来的问题就是有些功能要通过两种方式实现(比如磁盘隔离等)。另外Docker本身的daemon机制让Mesos不好直接管理容器进程,所以Mesos也在计划改进内置的容器支持Image,兼容Docker/Appc的Image,不会把Docker作为默认的容器。具体参看:https://github.com/apache/mesos/blob/master/docs/container-image.md,MESOS-2840。
源码架构分析
Mesos的核心是用c++写的,主要使用了一个libprocess的库,这是一个c++的actor模型的库(不太了解actor模型的可以参看我的前一篇文章:并发之痛 Thread,Goroutine,Actor,这个库顺带把Option,Nothing,Try, Future,Lambda,Defer这些都实现了,让我充分体会了c++的魔法)。libprocess基本是参考erlang的模式实现的,其中的actor都叫做process,每个process有一个独立的ID,我们这里为了方便理解,把其中的抽象都叫做actor,具体actor协作模式见下图:
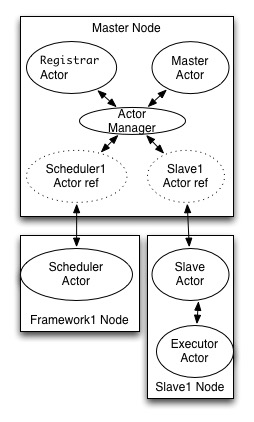
在Mesos的master节点中,每个Framework以及Slave都是一个远程的actor。而slave节点上,每个executor是一个actor,只不过内置的executor是在同一个进程中的,而其他自定义的executor是独立的进程,executor和slave之间通过进程间通信方式(网络端口)交互。
Mesos通过actor模型,简化了分布式系统的调用以及并发编程的复杂度,actor之间都通过消息异步通信,只需要知道对方的ID即可,无需了解对方和自己是否在同一个节点上。libprocess封装的actor manager知道接收方是本地的actor还是远程的actor,如果是远程的则通过请求接口转发消息。libprocess也封装了网络层,传输层使用的是http协议,使用方对不同的消息注册不同的handler即可,也支持http的长轮询模式订阅事件。mesos为了提高消息传递解析效率,消息传递支持json和protobuf两种格式。
这种架构的好处是Mesos省去了对消息队列的依赖。一般情况下这种分布式消息分发系统都需要消息队列或者中心存储的支持,比如Salt使用的是ZeroMQ,Kubenetes使用的是Etcd,而Mesos则不依赖外部的资源支持,只通过actor模型的容错机制来实现。而缺点也是actor本身的缺点,因为消息都是异步的,需要actor处理消息的丢失以及超时逻辑,Mesos不保证消息的可靠投递,提供的投递策略是 “at-most-once”,actor需要通过超时重试机制解决消息丢失的问题。不过任何需要远程调用的分布式系统需要处理的类似的问题吧。
Framework的实现解析
从上面的分析可以了解到,Framework在Mesos中扮演着重要的角色。如果你自己要开发一个分布式系统,打算运行在Mesos中,就需要考虑自己实现一个Framework。
Mesos提供了一个Framework的基础库,第三方只需要实现scheduler,和executor两个接口即可。基础库是用c++实现了,通过jni提供了java版本,通过python的native方式提供了python版本。而golang的版本是独立开发的,没有依赖c++库,代码架构比较优雅,想用go实现actor的可以参考。这个Framework基础库(SchedulerDriver以及ExecutorDriver的实现)主要做的事情就是实现前面我们提到的actor模型,和master以及slave交互,收到消息后回调用户自定义的scheduler和executor。
下面是java的Scheduler接口:
public interface Scheduler {
void registered(SchedulerDriver driver,
FrameworkID frameworkId,
MasterInfo masterInfo);
void reregistered(SchedulerDriver driver, MasterInfo masterInfo);
//这个是最主要的一个方法,当系统有空闲资源的时候,会询问Scheduler,
//是否接受或者拒绝该Offer。如果接受,则同时需要封装使用该Offer的task信息,调用driver去执行。
void resourceOffers(SchedulerDriver driver, List<Offer> offers);
//如果Offer被取消或者被别的Framework使用,则回调本方法
void offerRescinded(SchedulerDriver driver, OfferID offerId);
//该Framework启动的task状态变化时回调。
void statusUpdate(SchedulerDriver driver, TaskStatus status);
//自定义的框架消息
void frameworkMessage(SchedulerDriver driver,ExecutorID executorId,SlaveID slaveId,byte[]() data);
void disconnected(SchedulerDriver driver);
void slaveLost(SchedulerDriver driver, SlaveID slaveId);
void executorLost(SchedulerDriver driver,ExecutorID executorId,SlaveID slaveId,int status);
void error(SchedulerDriver driver, String message);
}
Mesos的Framework是独立于Mesos系统的,具体的部署方式,以及高可用都需要Framework自己解决,所以要实现一个完备的,高可用的Framework,复杂度还是挺高的。另外Framwork的机制比较适合需要任务分发以及调度的分布式系统,比如Hadoop,Jenkins等。其他的分布式数据库比如Cassandra,Mesos做的事情是通过Scheduler调度CassandraExecutor部署和管理(包括节点上的维护操作,比如备份)Cassandra节点,详细可参看 https://github.com/mesosphere/cassandra-mesos 。
另外Mesos Master本身没有持久化存储,所有数据都在内存,重启后数据会丢失。但活跃的Framework和Slave注册时会把自己当前的状态发送给Master,Master通过这种方式恢复数据。所以如果Framework需要持久化Task的执行记录,需要自己实现持久化存储。
Mesos Slave提供了recovery的机制,用于实现Slave进程重启后的恢复。默认情况下,Slave进程重启后,和该进程相关的executor/task都会被杀掉,但如果Framework配置开启了checkpoint设置,则该Framework相关的executor/task信息会被持久化到磁盘上,用于重启后的recovery。
Marathon
Marathon按照官方的说法是个基于Mesos的私有PaaS。它实现了Mesos的Framework,支持通过shell命令和Docker部署应用,提供Web界面,支持cpu/mem,实例数等参数设置,支持单应用的scale,但不支持复杂的集群定义。
Marathon本身是通过Scala实现的,也使用了actor模型。它提供了event bus接口,允许其他应用通过监听event bus来实现动态配置,比如前面提到的marathon-lb。
Marathon由于是基于jvm的,做系统安装包分发略麻烦,结果人家为了方便直接分发了一个70多M的shell脚本。初看吓我一跳,70多M的shell得写多少行,结果打开一看,java的二进制jar的也嵌在里面。这倒也是个办法。
Aurora
Aurora试图用一种自定义的配置语言去定义Mesos之上的task以及顺序关系,解决各种环境的异构问题,降低用shell脚本的复杂度。可以理解为Mesos之上的一种粘合剂语言,地位类似于Salt/Ansible的yaml,只不过Mesos本身没支持类似的配置语言,于是Aurora通过Framework的方式来支持。
Mesos和Kubernetes比较
Mesos和Kubernetes虽然都借鉴了Borg的思想,终极目标类似,但解决方案是不同的。Mesos有点像联邦制,承认各邦(Framework)的主权,但各邦让渡一部分公用的机制出来由Mesos来实现,最大化的共享资源,提高资源利用率,Framework和Mesos是相对独立的关系。而Kubernetes有点像单一制,搭建一个通用的平台,尽量提供全面的能力(网络,磁盘,内存,cpu),制定一个集群应用的定义标准,任何复杂的应用都可以按照该标准定义并以最小的变更成本在上面部署运行,主要的变更需求也是因为想享受Kubernetes的动态伸缩能力带来的。所以Mesos尽量做的比较少,而Kubernetes尽量做的比较多。Mesos定义是DCOS的kernel,但OS的kernel具体应该承担哪些职责,相关争论也从来没停止过。
相对来说Kubernetes使用要比较容易些,而Mesos更灵活些,需要做的定制开发工作也比较多。拿前面提到的cassandra来比较,cassandra-mesos的实现很复杂,而Kubernetes的cassandra例子则只有一个类,就是实现了KubernetesSeedProvider,通过Kubernetes的服务发现机制寻找cassandra的seed节点。当然Mesos上的cassandra可以通过Mesos发送备份等管理任务,而Kubernetes不提供任务转发的功能,这类需求用户可以通过kubectl的exec方法实现。从这个例子也大致能明白二者的差异点。
Kubernetes下的Kubernetes on Mesos项目的目的就是利用Mesos的这个特性,实现Kubernetes和Mesos上的其他Framework共享资源。如果想了解Kubernetes的更多资料可以看我去年写的Kubernetes 架构浅析。

相关阅读
- Return of the Borg: How Twitter Rebuilt Google’s Secret Weapon
- Mesos: A Platform for Fine-Grained Resource Sharing in the Data Center
- Infoq 深入浅出Mesos系列
- libprocess c++的actor模型库
- marathon-lb 基于marathon的负载均衡器
- cassandra-mesos
- kubernetes cassandra example
- Mesos的部署教程
有疑问加站长微信联系(非本文作者)




