转载请注明出处:www.huamo.online
前言
本文记录了自己深入理解goroutine栈布局的过程,潜入了一圈之后,发现底下的世界确实别有洞天,感觉很多东西都开阔明晰了许多。
内存布局是一个强相关于操作系统,处理器,机器架构的领域,和语言关系反而会少一些。只是golang诞生于plan9,在机器汇编层面,总是有一些自己特立独行的惯例规约,所以用golang切入,也是一个不错的契机。本文以x86架构为准进行讲解,都走了一遍,才发现其实都是在搞清楚一个话题:调用惯例。有兴趣的可以搜calling convention。
x86寄存器
我们在深挖golang runtime的时候,需要频繁和汇编打交道,其中寄存器尤为常见。常用到的寄存器有3类:
SP / ESP / RSP: 栈指针寄存器,总是指向栈顶。在x86架构下,这个寄存器有3个,分别对应16位SP/ 32位ESP/ 64位RSPBP / EBP / RBP: 基准指针寄存器,维护当前栈帧的基准地址,以便用来索引变量和参数,就像一个锚点一样,在其它架构中它等价于帧指针FP,只是在x86架构下,变量和参数都可以通过SP来索引,所以BP在x86下并不是那么的专用了,更像是个通用寄存器。同上面一样,这个寄存器有3个,分别对应16位BP/ 32位EBP/ 64位RBPIP / EIP / RIP: 指令指针寄存器,总是指向下一个指令的内存地址。就是我们熟知的PC,只是在x86架构下,它叫做IP。同上面一样,这个寄存器有3个,分别对应16位IP/ 32位EIP/ 64位RIP
对于同一个寄存器,我们可以用不同的名字引用这个寄存器上的不同部分。例如可以用
%ESP指向%RSP的低32位部分。 图示:
图片来自:https://en.wikibooks.org/wiki/X86_Assembly/X86_Architecture

x86寄存器如下图所示:
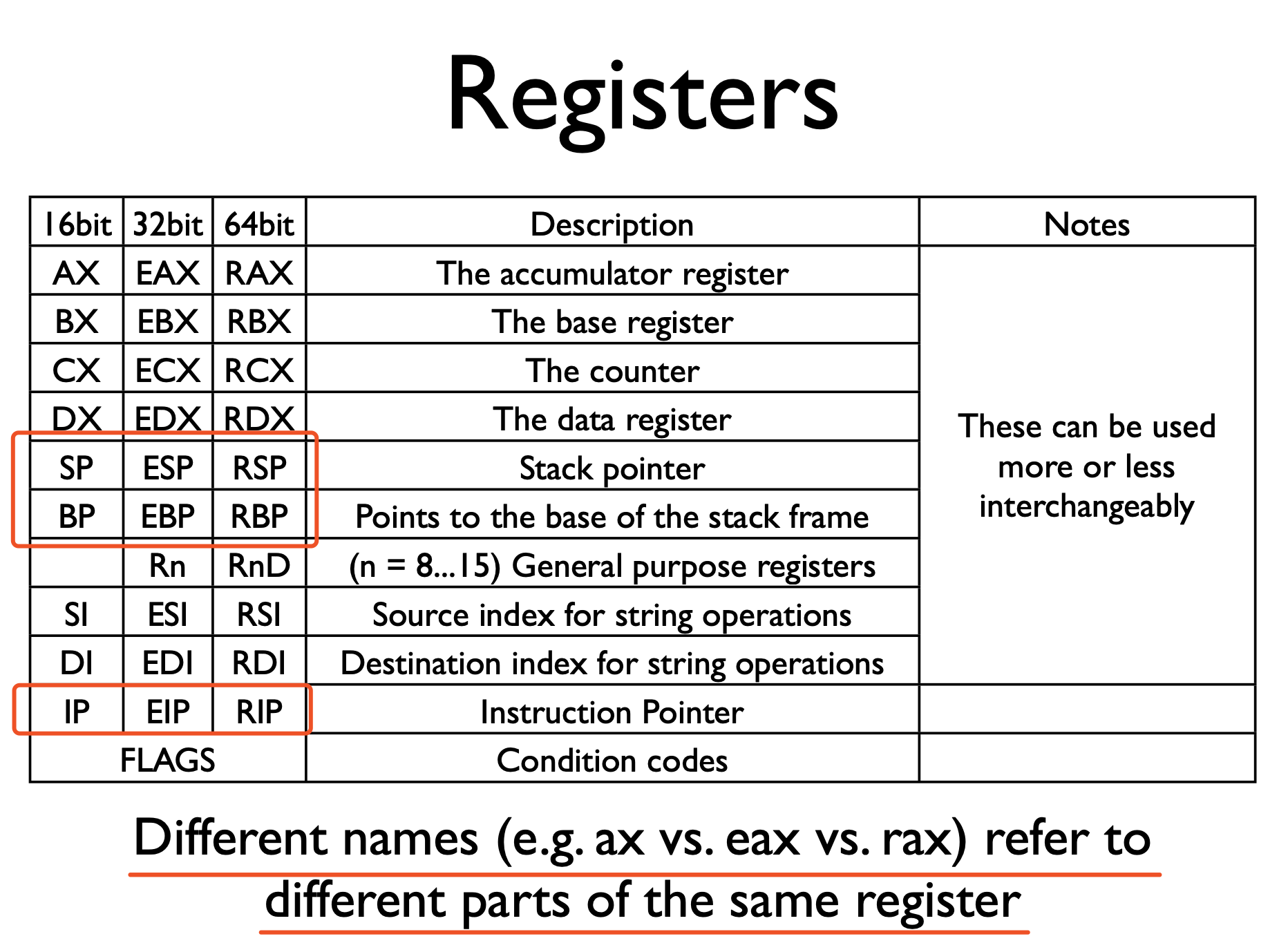
图片来自:https://cseweb.ucsd.edu/classes/sp10/cse141/pdf/02/S01_x86_64.key.pdf
golang没有采用x86-64架构函数传参优化
虽然在x86-64架构下,增加了很多通用寄存器,使得调用惯例(calling convention)变为函数传参可以部分(最多6个)使用寄存器直接传递,但是在golang中,编译器强制规定函数的传参全部都用栈传递,不使用寄存器传参。可以在下图中看到区别:
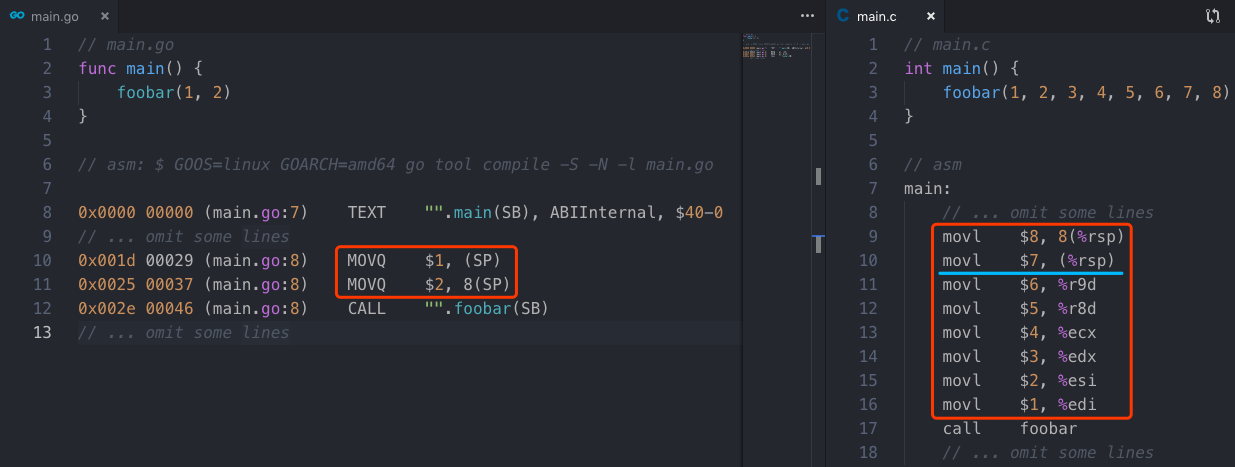
个人猜测原因有2:一方面是为了使生成的伪汇编方便跨平台,另一方面是基于连续栈的拷贝考虑。而这一强制规定同样也利于我们窥探golang栈帧的内存布局(stack frame layout)
x86-64二进制单元
在x86-64架构下,intel定义了一组二进制单元:
- a byte(字节): 8位
- a word(字): 16位
- a double word(双字): 32位
- a quadword(四字): 64位
- a double quadword(双四字): 128位
intel存储字节的顺序为小端优先:即低有效字节存储在内存低地址中。
栈是什么,栈帧是什么,堆又是什么
在runtime环境中执行程序时,常常会提到这3个名词。这并不是数据结构与算法中的抽象数据类型,而是属于运行时范畴。
堆是用来存储动态读写数据的内存区域。在golang里面,凡是在编译期逃逸分析结果为”逃逸”的数据,都会分配在堆上托管。
栈其实是调用栈(call stack)的简称。对应于一系列活动的subroutine。在golang里面,就是一个栈对应一个goroutine。现在的golang runtime都是使用了连续栈管理方式,详情会在后文描述。
栈帧(stack frame)又常被称为帧(frame)。一个栈其实就是由很多帧构成的,它描述了函数之间的调用关系。简单来说,你可以把帧看作是栈中栈,每一帧就对应了一次尚未返回的函数调用,它本身也是以栈的形式存放数据的。 例如:在一个goroutine里面,函数foo()正在调用函数bar(),那么这个调用栈的内存布局将会如下图所示:
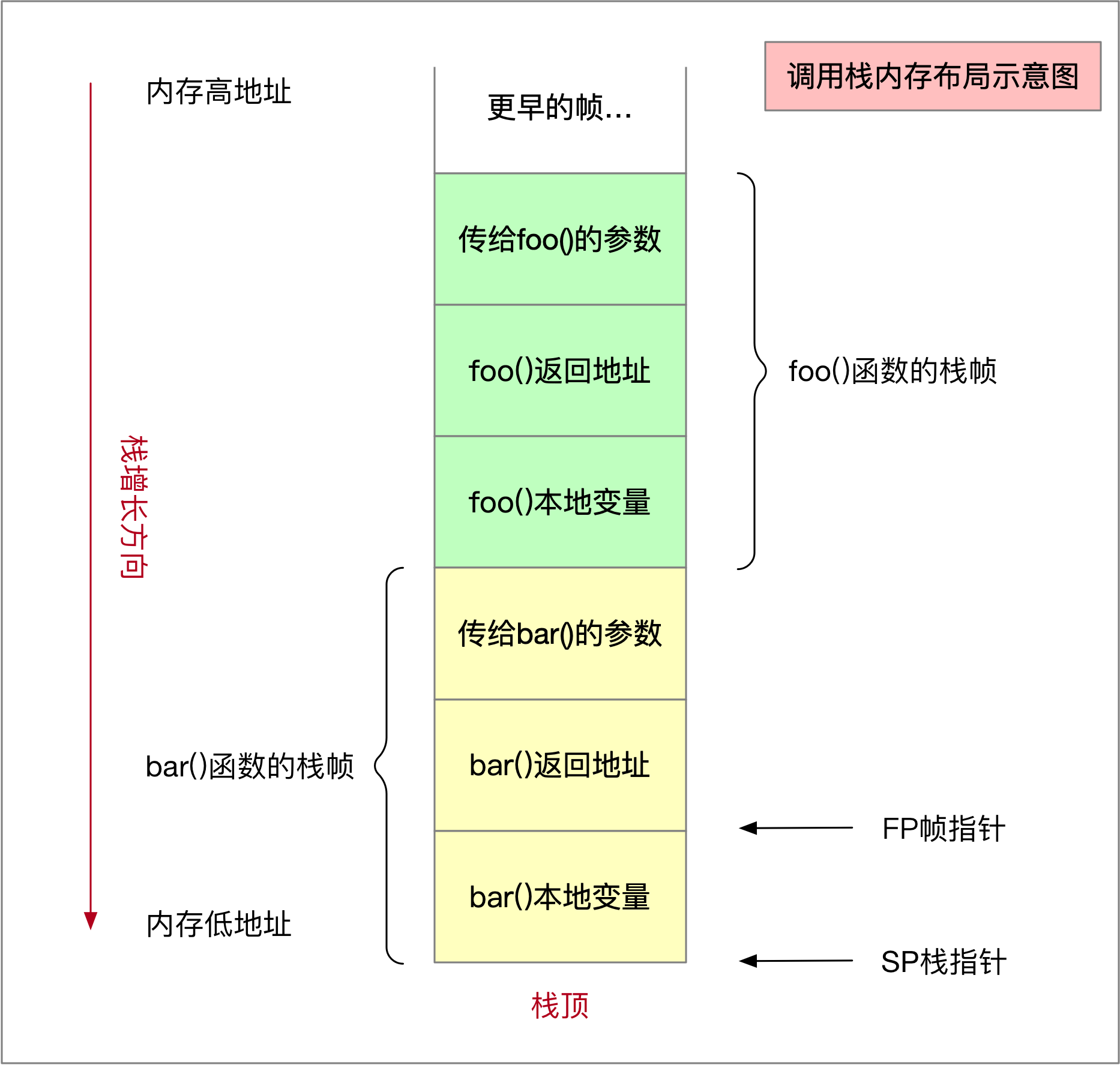
内存布局是语言无关的,这是操作系统的内存设计。该示意图基本是架构无关的,不同架构的区别是栈的生长方向是向低地址(如本图)还是向高地址。
按照push入栈的顺序,一个栈帧一般会包含如下几个部分:
- 传入该函数的参数值,如果有的话。对于golang来说,所有的传参都是值拷贝,所以都会复制一份到新的函数栈帧里存储。
- 返回地址,可以用来返回到调用者代码。在上图中,
bar()的栈帧这个部分记录的就是返回到foo()代码的地址。 - 函数本地变量,如果有的话。
SP和FP的用法原理
在x86架构下,已经没有FP这个物理寄存器,如果你非想找到一个等价的替代品,RBP可能符号你的要求。
当栈帧的大小不相同时,函数调用完成后,pop一个帧会使栈指针SP的变化量不固定。所以就需要有一个返回地址来标记返回的位置,这就是帧指针FP。
当函数返回时,当前SP替换为当前FP的值,就能够返回到上一层函数,之所以能做到这些,是因为FP存储了当该函数被调用前栈顶指针SP的值。这样层层回溯,就能双向链接起整个调用栈。
SP是在一个调用栈中所有调用之间共享的可变寄存器。而帧指针FP则是该帧对应的函数被调用前,栈顶指针SP的值快照。
FP实践习惯
在大多数操作系统中,栈帧都会留出一个区域来保存FP寄存器的旧值,即这个栈帧的调用者执行时FP寄存器的值。例如foo()函数调用bar()函数,那么bar()帧就会有一块内存区域维护着能够指向foo()帧的指针。该值在进入帧时保存,并在return时恢复。这个结合上面的用法原理就能连续的访问每个帧。
栈为什么是向下生长
这里说的“向下生长”,指的是向着内存低地址方向生长。在现代主流机器架构上(例如x86)中,栈都是向下生长的。然而,也有一些处理器(例如B5000)栈是向上生长的,还有一些架构(例如System Z)允许自定义栈的生长方向,甚至还有一些处理器(例如SPARC)是循环栈的处理方式。
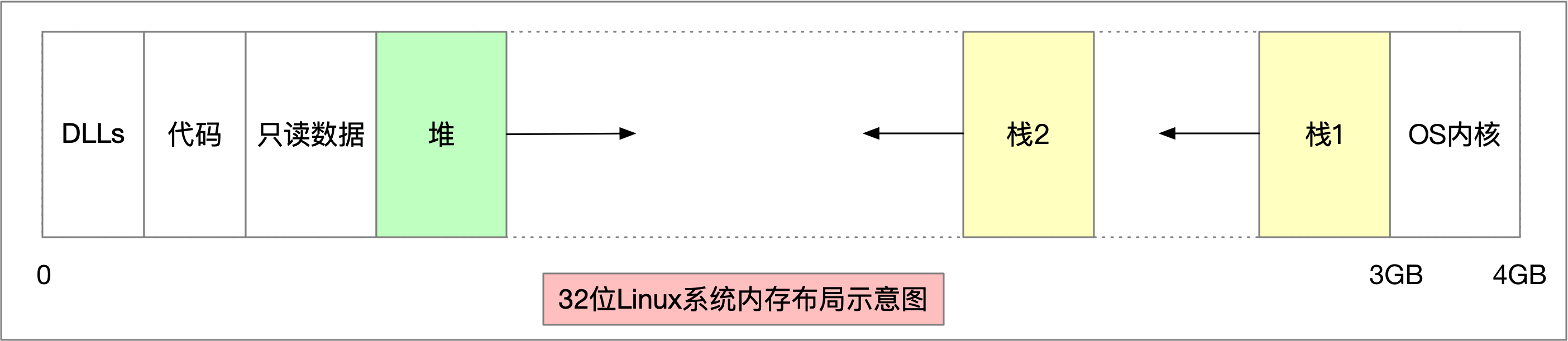
任何一个执行中的进程都有多种内存域:代码,只读数据,可读写数据等等。像代码和只读数据是静态且不变的,而有些数据是动态生成和销毁的,这就涉及到了内存域的扩张和缩小。
在32位Linux系统中,内存布局的解决方案如下所示:
- 代码,共享库,只读数据映射到了内存最开端
- 然后是堆,并向上生长
- 操作系统内核映射到了内存最末端的1GB空间
- 栈从内核最底部边界开始,并向下生长
对于多线程程序,同时会有多个栈存在,这个时候,主线程栈依然从内核底部边界开始。每一个线程都有最大栈尺寸,所以下一个线程偏移主线程最大栈尺寸位置开始,以此类推。
至于栈为什么是向下生长的原因,需要追溯到1974年4月Intel发布的8080(8-bit)处理器,该处理器影响了第一版x86的设计。在计算机时间线关于intel历史一章中,Stanley Mazor(世界上第一款处理器Intel 4004的发明人之一)有过简单的解释:之所以选择将栈指针向下延伸,是为了简化从用户程序(正索引)到调用栈的索引,同时也为了简化显示调用栈的内容。其实至于怎么简化了,没有任何解释,所以这更像是一个向后兼容的历史设计惯例
汇编语法
在Golang中编译出来的伪汇编代码中,使用的是GAS汇编语法(Gnu ASsembler),采用AT&T汇编格式。而我们常常见到的其它各种汇编器,例如Windows推出的MASM,免费开源的NASM,都是基于Intel汇编语法。这两者有一些明显的区别,需要分清。
- 最重要的区别,就是两者指令的源操作数和目标操作数的位置正好相反。例如下面两行汇编都做了相同的事情
GAS: movl %eax %ebx // 将eax寄存器的值复制到ebx寄存器中
Intel: mov ebx eax // 将eax寄存器的值复制到ebx寄存器中
- 在GAS中,操作数字长由命令后缀表示,例如
movq(64位), movl(32位)。而Intel则是用单独的标识符,例如byte ptr。下面两行汇编都实现了:将val值复制一个字节到AL寄存器中
GAS: movb val %al
Intel: mov al, byte ptr val
OK,开始剖析Golang调用栈帧内存布局
从golang runtime源码获取指导
翻看runtime/stack.go源码,无意中在一段注释里发现了 x86架构下golang栈帧布局示意图
// Stack frame layout
//
// (x86)
// +------------------+
// | args from caller |
// +------------------+ <- frame->argp
// | return address |
// +------------------+
// | caller's BP (*) | (*) if framepointer_enabled && varp < sp
// +------------------+ <- frame->varp
// | locals |
// +------------------+
// | args to callee |
// +------------------+ <- frame->sp
这张图我看了好久才看明白上下边缘两句话的意思,也就是说在 x86架构下,golang栈帧布局从上(高地址)到下(低地址)依次为:这个函数帧的调用者传入的参数, 这个函数帧的返回地址,调用者调用时的BP快照(见上文FP用法原理),该帧本地变量,该帧调用其它函数需要传递的参数。
golang 工具链
- 禁止内联编译代码
$ GOOS=linux GOARCH=amd64 go build -gcflags=all="-N -l" main.go
- 禁止内联生成伪汇编代码
$ GOOS=linux GOARCH=amd64 go tool compile -S -N -l main.go
- 反汇编,生成伪汇编代码,这样生成的汇编更完整,并翻译了很多符号表
$ 编译出golang可执行文件
$ go tool objdump -S -s main main.o
来个实例
package main
// 为了避免add帧尺寸为0,所以强行加入一个局部变量tmp
func add(a, b int64) (int64, int64) {
var tmp int64 = 1
tmp = tmp + a
return a + b, a - b
}
func main() {
var c int64 = 10
var d int64 = 12
add(c, d)
}
剖析内存布局,编译时记得要禁止内联优化,使用如下命令显示汇编代码:
$ GOOS=linux GOARCH=amd64 go tool compile -S -N -l main.go
分析main帧
去除掉golang实现连续栈机制的大量prolog和epilog,以及GC相关的FUNCDATA & PCDATA,我们可以得到main()函数对应的伪汇编代码,并由此构造出main帧内存布局。
阅读go汇编,最好先要阅读下Go汇编语言
0x0000 00000 (main.go:9) TEXT "".main(SB), ABIInternal, $56-0
// ... omit some lines:栈分裂prolog
0x000f 00015 (main.go:9) SUBQ $56, SP
0x0013 00019 (main.go:9) MOVQ BP, 48(SP)
0x0018 00024 (main.go:9) LEAQ 48(SP), BP
// ... omit some lines:GC相关
0x001d 00029 (main.go:10) MOVQ $10, "".c+40(SP)
0x0026 00038 (main.go:11) MOVQ $12, "".d+32(SP)
0x002f 00047 (main.go:12) MOVQ "".c+40(SP), AX
0x0034 00052 (main.go:12) MOVQ AX, (SP)
0x0038 00056 (main.go:12) MOVQ $12, 8(SP)
0x0041 00065 (main.go:12) CALL "".add(SB)
0x0046 00070 (main.go:13) MOVQ 48(SP), BP
0x004b 00075 (main.go:13) ADDQ $56, SP
0x004f 00079 (main.go:13) RET
// ... omit some lines:栈分裂epilog
构造如下图:

分析add帧
同样的道理可以得到add()函数的伪汇编代码:
0x0000 00000 (main.go:3) TEXT "".add(SB), NOSPLIT|ABIInternal, $16-32
0x0000 00000 (main.go:3) SUBQ $16, SP
0x0004 00004 (main.go:3) MOVQ BP, 8(SP)
0x0009 00009 (main.go:3) LEAQ 8(SP), BP
// ... omit some lines:GC相关
0x000e 00014 (main.go:3) MOVQ $0, "".~r2+40(SP)
0x0017 00023 (main.go:3) MOVQ $0, "".~r3+48(SP)
0x0020 00032 (main.go:4) MOVQ $1, "".tmp(SP)
0x0028 00040 (main.go:5) MOVQ "".a+24(SP), AX
0x002d 00045 (main.go:5) INCQ AX
0x0030 00048 (main.go:5) MOVQ AX, "".tmp(SP)
0x0034 00052 (main.go:6) MOVQ "".a+24(SP), AX
0x0039 00057 (main.go:6) ADDQ "".b+32(SP), AX
0x003e 00062 (main.go:6) MOVQ AX, "".~r2+40(SP)
0x0043 00067 (main.go:6) MOVQ "".a+24(SP), AX
0x0048 00072 (main.go:6) SUBQ "".b+32(SP), AX
0x004d 00077 (main.go:6) MOVQ AX, "".~r3+48(SP)
0x0052 00082 (main.go:6) MOVQ 8(SP), BP
0x0057 00087 (main.go:6) ADDQ $16, SP
0x005b 00091 (main.go:6) RET
关于
ABIInternal,是实验版本的calling convention,详见相关的golang proposal
call指令:call指令会做两件事情,首先会把当前指令位置push到栈顶(即当前RIP寄存器的值),然后会无条件跳转到参数指定的代码位置。
ret指令:ret指令也会做两件事情,首先会弹出栈顶元素,然后会无条件跳转到弹出的元素值指定的代码位置
遇到类似””.tmp(SP)这种符号,可以通过
go tool objdump来翻译出符号地址
分析如下图

goroutine栈管理机制
前面说了那么多,可以归类为探究goroutine的栈内存布局(stack memory layout)。现在可以把轮廓调大一点,探究下goroutine的栈管理的理念和实现,也就是常常听到的连续栈。
golang的一个最重要的特性就是令人瞩目的goroutine,非常轻量,廉价(开销极低),便捷(通信简单)。goroutine是如何做到单机上万个并存的,其内存管理是至关重要的一点。
Golang在栈管理上,类似于其它很多语言的管理方式,但是在实现细节上又有很多不同。
C语言栈管理方式
在C语言中,当要启动一个线程时,标准库会分配好一块内存作为该线程的栈。并告诉内核这块内存的位置,以便让内核处理线程执行。当这块内存区域不足时,例如执行一个高度递归的函数,程序就会执行错误。
要想解决这个问题,可以有2种办法
- 修改标准库代码,将栈内存块的分配尺寸改大一点,但是这样以后所有的线程启动时都会分配更大的内存。
- 根据不同的线程分配不同的内存块,但是这样每次创建线程时,都要确定好需要的内存大小,很麻烦也很难确定。
Golang栈管理方式
Golang runtime则尝试为goroutine按需分配栈空间,不需要程序员去决定。以前用分段栈实现,现在的Go版本则用连续栈实现。
分段栈
在以前的分段栈方式下,当一个goroutine创建时,运行时会分配8KB区域作为栈供协程使用。
但是在每个goroutine函数入口处都会被插入一小段前置代码,它能够检查栈空间是否被消耗殆尽,如果用完了,它会调用morestack()函数来扩展空间。
morestack()函数机理,即分段栈扩张机理:为栈空间分配一块新的内存区域。然后在这个新栈的底部的结构体中填充关于该栈的各种数据,包括刚刚来自的旧栈的地址。当得到了一个新的栈分段之后,通过重试导致用完栈的函数来重启goroutine。这就被称为栈的分裂
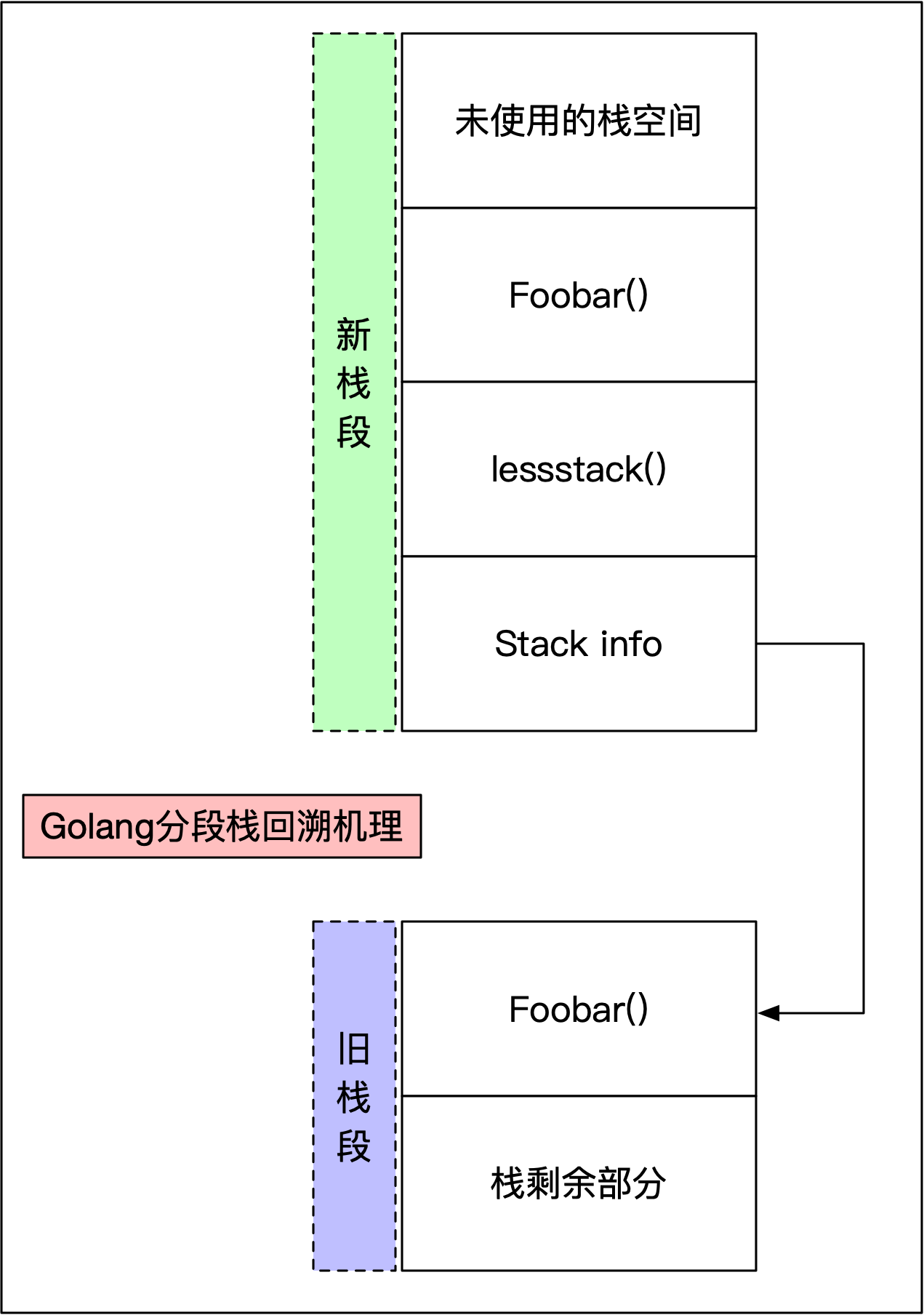
分段栈回溯机理:如上图所示,新栈会为lessstack()插入一个栈条目。这个函数并不实际显式调用。它会在耗尽旧栈的那个函数返回的时候被设置,例如图中的Foobar(),当Foobar()运行完毕返回时,会返回到lessstack()中,它会查询栈底部的结构体信息,并调整栈指针(SP),以便能够回溯到上一个栈分段。然后,就可以释放新栈段空间了。
分段栈的问题: 热点分裂
分段栈机制使得栈可以按需扩张收缩。而程序员不需要在意栈的大小。
但是分段栈也有瑕疵。收缩栈是一个相对昂贵的操作。如果是在一个循环中分裂栈情况更明显。函数会增长栈,分裂栈,返回栈,并且释放栈分段。如果是在循环里面做这些操作,那么将会付出很大的开销。例如循环一次经历了这些过程,当下一次循环时栈又被耗尽,又得重新分配栈分段,然后又被释放掉,周而复始,循环往复,开销就会巨大。
这就是熟知的 hot split problem (热点分裂问题)。这是Golang开发组切换到新的栈管理方式的主要原因,新方式称为栈拷贝。
连续栈(栈拷贝)
从GO1.4之后,开始正式使用了连续栈机制。
栈拷贝开始很像分段栈。协程运行,使用栈空间,当栈将要耗尽时,触发相同的栈溢出检测。
但是,不像分段栈里有一个回溯链接,栈拷贝的方式则是创建了一个新的分段,它是旧栈的两倍大小,并且把旧栈完全拷贝进来。 这样当栈收缩为旧栈大小时,runtime不会做任何事情。收缩变成了一个no op免费操作。此外,当栈再次增长时,runtime也不需要做任何事情,重新使用刚才扩容的空间即可。
栈是如何拷贝的
不像听起来那么容易,其实拷贝栈是一项艰巨的任务。由于栈中的变量在Golang中能够获取其地址,因此最终会出现指向栈的指针。而如果轻易拷贝移动栈,任何指向旧栈的指针都会失效。
而Golang的内存安全机制规定,任何能够指向栈的指针都必须存在于栈中。
所以可以通过垃圾收集器协助栈拷贝,因为垃圾收集器需要知道哪些指针可以进行回收,所以可以查到栈上的哪些部分是指针,当进行栈拷贝时,会更新指针信息指向新目标,以及它相关的所有指针。
但是,runtime中大量核心调度函数和GC核心都是用C语言写的,这些函数都获取不到指针信息,那么它们就无法复制。这种都会在一个特殊的栈中执行,并且由runtime开发者分别定义栈尺寸。
还是从汇编角度剖析连续栈的实现
在机器架构层面,很多关于函数的公用操作都会被提取为固定代码,在函数运行时插入到代码片段的前后部分中,其中函数代码前插入汇编,称为prolog,一般只会有一个prolog。在函数代码后插入汇编,称为epilog,一般可以有多个epilog。这个起名有点像写小说的“序章”和“后记”。
golang就是用prolog + epilog的方式来实现连续栈的检测和复制的。
还是上面的main.go程序,这次重点看下关于连续栈的汇编代码
0x0000 00000 (main.go:9) TEXT "".main(SB), ABIInternal, $56-0
0x0000 00000 (main.go:9) MOVQ (TLS), CX
0x0009 00009 (main.go:9) CMPQ SP, 16(CX)
0x000d 00013 (main.go:9) JLS 80
// ... omit function body code
0x0050 00080 (main.go:9) CALL runtime.morestack_noctxt(SB)
栈溢出检测实现
TLS也是一个伪寄存器,表示的是thread-local storage,它存放了g结构体。并且只能被载入到另一个寄存器中。16(TLS)正好指向了g->stackguard,准确的说在我们这个程序中,它指向了g->stackguard0。而这就是prolog中检测栈溢出的精髓:每一个goroutine的g->stackguard0都被设置为指向stack.lo + StackGuard的位置。所以每一个函数在真正执行前都会将SP和stackguard0进行比较。
栈溢出发生在整个函数执行前就能被侦测到,而不是函数内某条语句执行时
结构体
g属于Golang GMP调度的范畴,它详细定义了golang栈的各种参数。
// runtime/runtime2.go
type stack struct {
lo uintptr // 64位机器上占8字节
hi uintptr // 64位机器上占8字节
}
type g struct {
stack stack
stackguard0 uintptr // 用于golang的栈溢出检测
stackguard1 uintptr // 用于clang的栈溢出检测
下面是栈溢出检测相关的一些底层实现细节
StackGuard & StackSmall & StackBig & StackLimit & StackPreempt
这些字段均定义在runtime/stack.go中,但是在cmd/internal/objabi中都会重复定义一次,提供给内部各模块使用。
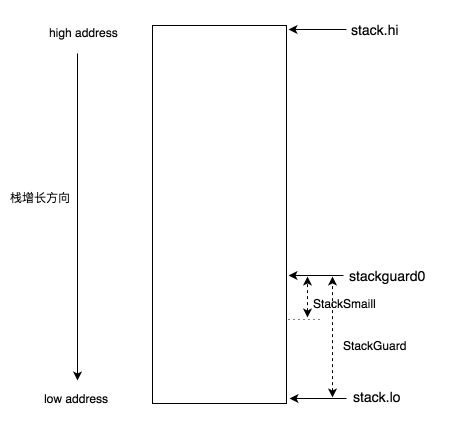
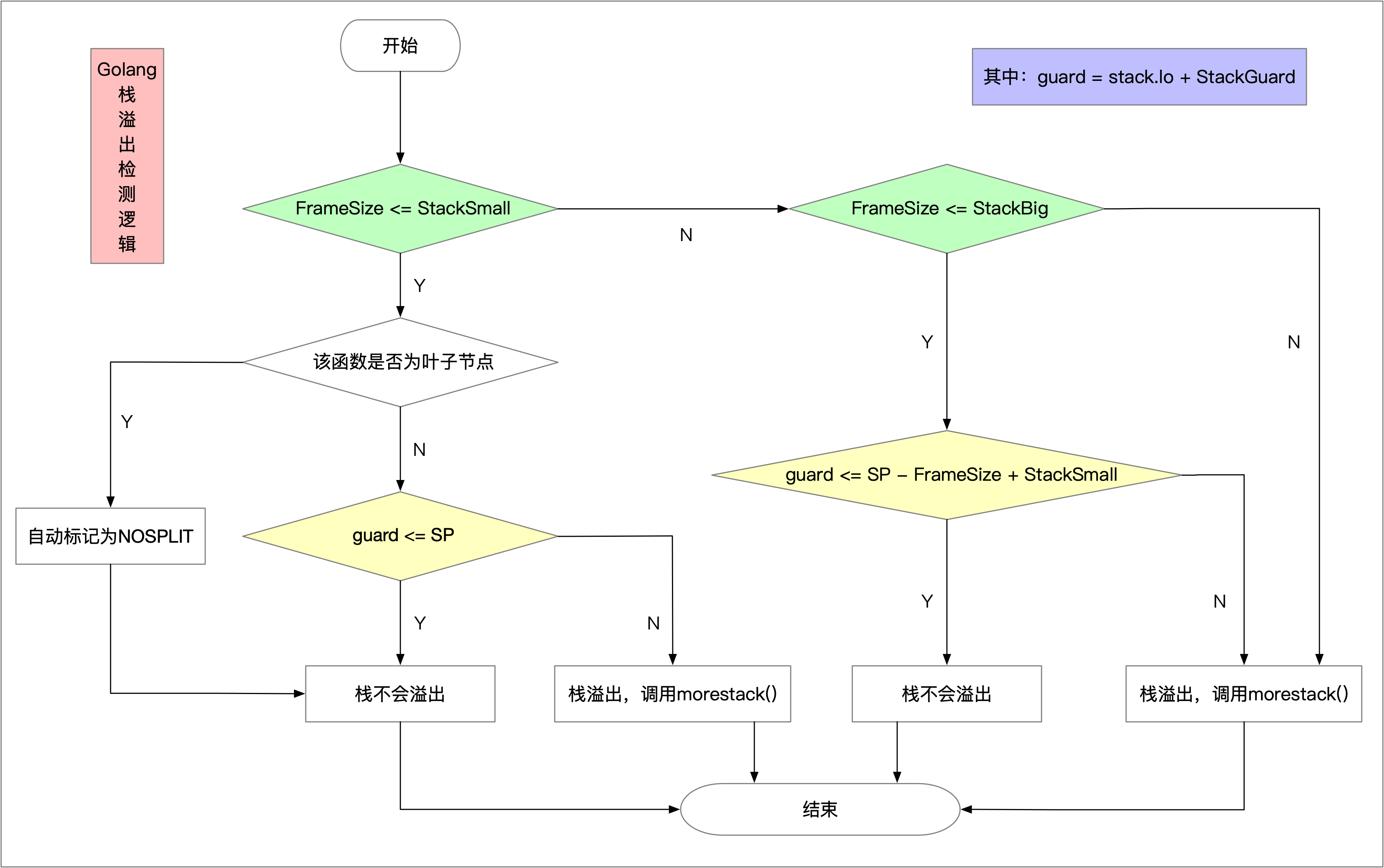
StackGuard = 880*sys.StackGuardMultiplier + _StackSystem:栈溢出门槛,表示在栈最低位之上StackGuard个字节是不溢出的。
StackSmall = 128:主要用于小函数优化,允许函数可以突破StackGuard防线后,再向下占用最多StackSmall个字节。
StackBig = 4096:则主要针对于大函数优化,对于这样的函数帧,必须启用另外一套栈溢出检测代码,会将StackPreempt赋值给StackGuard,保证该函数帧必然会栈溢出。
StackPreempt = uintptrMask & -1314:是一个必然大于所有SP的值,16进制表示为0xFFFFFADE,它是一个关于golang抢占调度范畴的参数,这个值赋予StackGuard,可以保证栈必然分裂,而morestack()函数在创建新栈时,如果发现stackguard = StackPreempt,则会触发调度。
StackLimit = _StackGuard - _StackSystem - _StackSmall:这就是栈溢出检测时,栈低位低于StackSmall剩余的那部分空间,这段空间表示了一个NOSPLIT拒绝栈溢出检测的函数最多还能使用的栈空间,例如留给defer函数使用。
因此,栈溢出检测逻辑如下图所示:
所有的栈溢出检测代码都在cmd/internal/obj包中,例如对于x86机器架构,对应代码为:
// cmd/internal/obj/x86/obj6.go
func stacksplit() {}
NOSPLIT的自动检测
我们在编写函数时,编译出汇编代码会发现,在一些函数的执行代码中,编译器很智能的加上了NOSPLIT标记。这个标记可以禁用栈溢出检测prolog,即该函数运行不会导致栈分裂,由于不需要再照常执行栈溢出检测,所以会提升一些函数性能。这是如何做到的
// cmd/internal/obj/s390x/objz.go
if p.Mark&LEAF != 0 && autosize < objabi.StackSmall {
// A leaf function with a small stack can be marked
// NOSPLIT, avoiding a stack check.
p.From.Sym.Set(obj.AttrNoSplit, true)
}
当函数处于调用链的叶子节点,且栈帧小于StackSmall字节时,则自动标记为NOSPLIT。 x86架构处理与之类似
自动标记为NOSPLIT的函数,链接器就会知道该函数最多还会使用StackLimit字节空间,不需要栈分裂。
备注:用户也可以使用//go:nosplit强制指定NOSPLIT属性,但如果函数实际真的溢出了,则会在编译期就报错nosplit stack overflow
$ GOOS=linux GOARCH=amd64 go build -gcflags="-N -l" main.go
# command-line-arguments
main.add: nosplit stack overflow
744 assumed on entry to main.add (nosplit)
-79264 after main.add (nosplit) uses 80008
栈拷贝实现
一旦检查到栈溢出,就会call runtime.morestack_noctxt(SB)执行栈拷贝功能。这包含新栈分配+旧栈拷贝两个部分。
顺带说一下
golang的很多特性,都有经典的设计文档,在极早期都已经编写出来,实现的时候都是依照该设计理念执行的,几乎所有的设计文档都托管在google doc里面,有心的话可以详细google。
参考链接
- https://cseweb.ucsd.edu/classes/sp10/cse141/pdf/02/S01_x86_64.key.pdf
- https://en.wikibooks.org/wiki/X86_Assembly/X86_Architecture
- https://software.intel.com/en-us/articles/introduction-to-x64-assembly
- https://draveness.me/golang-function-call
- https://en.wikipedia.org/wiki/Subroutine
- https://en.wikipedia.org/wiki/Call_stack#STACK-FRAME
- https://gist.github.com/cpq/8598782
- http://tcm.computerhistory.org/ComputerTimeline/Chap37_intel_CS2.pdf
- https://www.quora.com/What-is-the-difference-between-movq-and-movl-assembly-instruction
- https://blog.csdn.net/kennyrose/article/details/7575952
- https://golang.org/doc/asm
- https://github.com/golang/proposal/blob/master/design/27539-internal-abi.md
- http://xargin.com/go-and-plan9-asm/
- http://www.cs.virginia.edu/~evans/cs216/guides/x86.html
- https://www.tenouk.com/Bufferoverflowc/Bufferoverflow2a.html
- https://softwareengineering.stackexchange.com/questions/342525/difference-between-assembly-code-and-disassembly-listing
- https://blog.cloudflare.com/how-stacks-are-handled-in-go/
- https://docs.microsoft.com/en-us/cpp/build/prolog-and-epilog?view=vs-2019
- https://kirk91.github.io/posts/2d571d09/
- https://zhuanlan.zhihu.com/p/27590998
- https://www.jianshu.com/p/469d0c7a7936
延伸阅读
这里是相关话题的深入,值得读,但我还没读,罗列在此
- https://eli.thegreenplace.net/2011/09/06/stack-frame-layout-on-x86-64 作者
Eli Bendersky目前在google AI,通晓编译器 - https://eli.thegreenplace.net/2011/02/04/where-the-top-of-the-stack-is-on-x86/
转载请注明出处:[www.huamo.online
有疑问加站长微信联系(非本文作者)




