目录
“包排异”
可能有点危言耸听,但是标题中的“排异反应”确实是借用生物学上的概念:免疫系统攻击外来的异物,如病毒或细菌等。在这里,包排异攻击的是那些不应该被引入到代码里的包。
为什么要实现包排异?试想有包 A,代码引入 A 包后可以调用 A 包中的功能,且能正确工作,但因为某种原因,若代码里又引入了 B 包,会导致(或极易导致) A 包中的功能发生故障,出现意料之外的错误。为了避免这种情况,A 包实现了对 B 包的排异,当引入 B 包后 A 包会显式地抛出错误,拒绝工作,方便开发者第一时间发现问题,避免引起更严重的后果。
不是伪需求
确实,严格意义上讲,引入一个包造成另一个包无法工作(能编译通过但运行结果不符合预期)在 golang 中是不可能的。但是事事难有绝对,由于写代码时的疏忽,不正确地使用,还是可能造成这种情况的。不卖关子,我说我遇到了什么吧。
mongo 没有官方驱动,只用一个民间的驱动:github.com/go-mgo/mgo,但为了方便发布版本,建议使用别名 gopkg.in/mgo.v2。后来作者因为一些原因,没有再更新这个包了,也不回复 Issue 或合并 Pull Request,于是那些希望帮忙维护的人只能 fork 一份,更新自己 fork 的版本。结果 fork 的版本又被 fork,修复了一些问题后,又被另一个人 fork 去继续完善。造成的局面是:一个原版的驱动不再维护,一大堆复刻版的驱动群龙无首,继承关系错综复杂。我甚至在 mongo 官方文档建议使用的民间驱动中,见过同时列举 3 个 golang 驱动的情形——这 3 个驱动分别是 github.com/go-mgo/mgo 和它的 1 代 fork、3 代 fork。
这一度让我糟心,都不知道用哪个好。
好在最近事情有了转机,github.com/go-mgo/mgo 的作者半个月前声明了仓库不在维护,且建议使用 github.com/globalsign/mgo,它是一个 3 代 fork,现在上也是唯一一个被 mongo 官方建议使用的 golang 驱动。
github.com/globalsign/mgo 修复了大量已知问题且现在作为“独苗”被社区持续维护,我也终于知道该选哪个包了。最近也有一个新项目,我趁这个契机在新项目中换用了这个新包,在 mongo 持久化访问层里使用了它。
麻烦来了,由于历史原因,我不能号召同事删掉自己电脑里旧的包,也不能删掉自动发布系统里旧的包,以免引起线上业务无法编译。所以新包和旧包将同时使用,只是不会出现在同一个项目里。然而,“不会出现在同一个项目里”这是个理想情况,实际中由于疏忽等原因,还是容易造成在同一个项目同时使用了两个版本的包。
编译没有问题,但运行时就不对了。我发现的问题有两个:
一,每个包里都定义了若干名称相同 error,比如 ErrNotFound(指查询未找到),如果使用 A 包去做查询,将返回的 error 和 B 包中的 ErrNotFound 向比较,必然是不相等的,即 A.ErrNotFound != B.ErrNotFound,这会让程序错误判断 error 的含义,引起后续的不正确处理。
二,每个包里都用一个子包 bson,bson 中定义了 ObjectId,它是 mongo 一种重要的特殊数据类型,默认用于作为数据记录唯一 Id,如果将 A.bson.ObjectId 传给 B.Insert(),B 会错误地判断数据类型,将 ObjectId 当成普通的字符串插入,引起数据错误——是的,B 只认“B.bson.ObjectId”。
所以,我可以认为,同一个项目里同时引入多个 mongo 驱动包是不必要的,且容易造成错误。如果这种情况出现了,一定是编程过程中的失误,而程序编译或运行过程中应当主动报错,避免主人陷于麻烦。
github.com/globalsign/mgo 需要能排异其他 mongo 驱动包。
编译时检查
现在我们弄明白什么是包排异和为什么需要包排异了。
最佳情况下,包排异最好是在编译过程中实现,我臆想的情况是,每个包都会定义一个唯一 ID,不因包名的修改而修改,如果引入了两个包后,同一个 ID 被定义了两次,则触发排异。但是这只是我的臆想,灵感来自于 C/C++ 的 #define、#ifdef、#ifndef 等宏指令,golang 不支持宏指令,且也不可能强制每个包都定义一个 ID。
我原本是寄希望于 golang 的 Build Constraints 特性,在编译时做一些约束,但是,它并不支持我的需求,甚至它的功能和我的需求根本不在一个频道上。于是我不得不放弃编译时检查这一美好愿景,毕竟,需要包排异的情况着实罕见,且是开发者的锅,不属于 golang 的设计缺陷。自己的锅要自己背。
运行时检查
我另一个寄希望于的是反射,如果是 java,我会尝试使用反射,在运行时尝试加载一个应当被排异的包,如果加载成功了,则抛出异常。实时上,这样做也有缺陷,因为可能存在项目没有引入,但当前环境了存在该包的情况。
言归正传,golang 编译时是静态链接的,这就不可能做到运行时加载一个包,此路不通,完全不通。
另一条路子是指望堆栈信息里保存的源代码路径信息,这些路径信息原本用于出错时指明出错的源代码位置。分析源代码路径可以推断是哪一个包,进而判断有没有引入被排异的包。
然而,虽然知道信息就在那里,想要利用就困难了,用代码获取当前的堆栈信息只能获取程序运行到当前位置的堆栈信息,如果此前并没有(极有可能没有)调用某个包里的函数,堆栈信息里是找不到那个包的相关信息的。
但我想要的信息就在那里,要是要不到了,那就只能抢了……
最终实现
介绍一个 linux 命令,strings,可以将一个二进制文件中的所有可打印字符输出出来,如果对一个 golang 编译结果使用,再 grep 目标内容,可以看到:
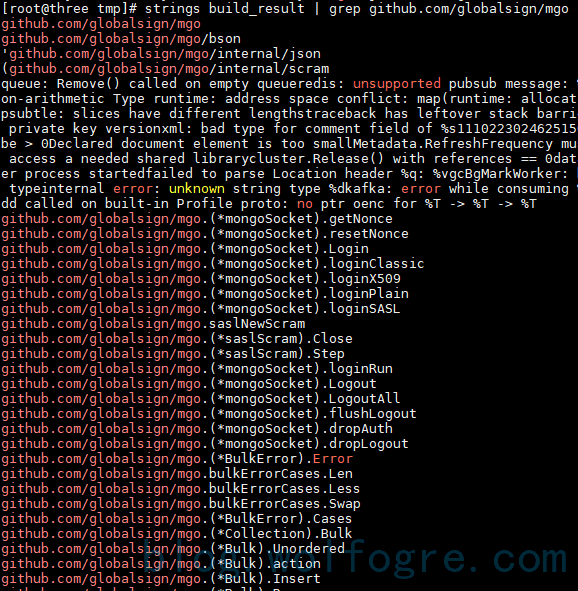
可见,编译结果明文保存了相关类、函数及其所在包的名字,这就为包排异反应的实现提供了可乘之机。最后的实现思路是:
init 函数通过 os.Args 获取当前可执行文件位置,读取文件,扫描文件内容,匹配需要排异的包的名字,如果匹配命中且超过指定次数,比如 5 次,则判定当前可执行文件引用了被排异的包,panic 中止程序运行。
实现代码:
package mongo
import (
"io/ioutil"
"os"
"fmt"
"bytes"
)
const (
_MIN = 5 // 至少出现 5 次
)
var (
// 需要排异的包
reject = []string{
"gopkg.in/mgo.v2",
"github.com/go-mgo/mgo",
"camlistore.org/third_party/labix.org/v2/mgo",
"github.com/siddontang/go/bson",
}
)
func init() {
buffer, err := ioutil.ReadFile(os.Args[0])
if err != nil {
fmt.Println("mongo reject failed: ", err)
return // let it go
}
for _, v := range reject {
if containsImport(buffer, v) {
panic(fmt.Sprintf("use github.com/globalsign/mgo, not %v", v))
}
}
}
func containsImport(data []byte, imp string) bool {
if len(imp) == 0 {
return false
}
impBytes := []byte(imp)
count := 0
index := 0
for count < _MIN && index >= 0 {
index = bytes.Index(data[index:], impBytes)
if index >= 0 {
count++
index += len(impBytes)
if index >= len(data) {
index = -1
}
}
}
return count >= _MIN
}
蹩脚的思路,性能不佳的代码,但好歹算解决问题了:
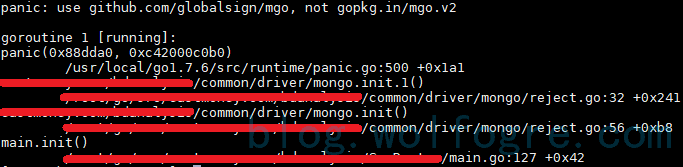
希望以后又更好的实现办法。
就到这里。这是过年前最后一篇博客了,准备回家过年了。
明年再接再厉。
后记
2018.03.09
在本文发布的第二天,也就是 2 月 14 号,Mongo 官方发布了官方的 Golang 驱动 mongo-go-driver。
虽然目前只是 alpha 测试版,官方网站驱动列表上也没有它的名字,但其发展还是非常迅速的,2 月 14 日发布了 alpha v0.0.1,3 月 8 日发布了 alpha v0.0.2,相信过不了多久一个可用的 mongo golang 驱动便会诞生,拭目以待。
广大人民群众又一次迎来了希望。




