
资源准备
1,稳定运行的K8S集群一套(没有可使用Rancher快速部署一个)
2,Jenkins master一台
3,Jenkins pipeline基础知识:见 链接jenkinspipeline
传统Jenkins使用中暴露的问题
1,每个业务团队使用的编译环境不统一,需要准备大量的slave节点
2,Slave很多,空闲期(如夜里)资源浪费
3,虽然Slave很多,但高峰期队列等待构建任务依然在排队,资源抢占严重
4,构建任务多,workspace空间不足
5,性能瓶颈,偶尔有slave节点内存泄漏问题
将Jenkins的slave节点部署到K8S的原理
K8S有pod的概念,一个pod内可以有多个container。通过每次构建时创建一个新的pod,挂载一个容器的slave节点的方式构建。构建后将构建产物及结果报告输出,并在构建后销毁pod。
方案的优势
1,共享k8s集群资源,按需分配资源,不会出现slave机由于资源限制或者executor限制导致的资源抢占,构建任务排队现象。
2,空闲期释放掉在k8s集群上申请的资源 ,其他团队可以复用该资源。如大数据团队、AI团队可以定时在夜里申请k8s资源计算模型,跑spark任务等。
3,每次构建都是新环境,内存泄漏等问题不会互相影响,workspace空间不会共享。
4,可根据业务需求,灵活的启用不同环境的镜像用于构建。如jdk版本、maven版本、不同语言的编译环境等,都可以做到按需创建。
具体步骤
1,Jenkins master下载插件
点击系统管理 ——> 插件管理,选择要安装的插件Kubernetes plugin安装
2,配置K8S serverapi地址
在点击系统管理 ——> 系统设置 ——> Add a new cloud ——> 选择kubernetes,填写相关信息
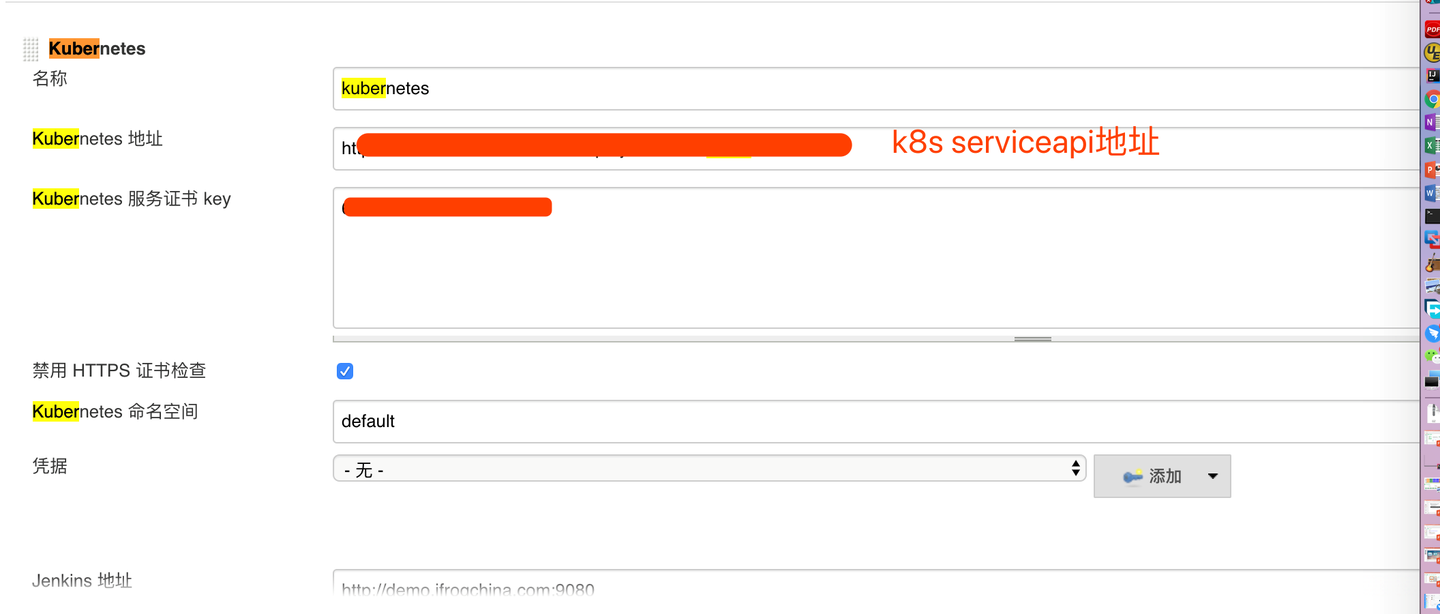
为了所有构建步骤由pipeline代码管理比较灵活,所以这里只配置k8s集群地址,不设置pod模版
3,创建pipeline任务
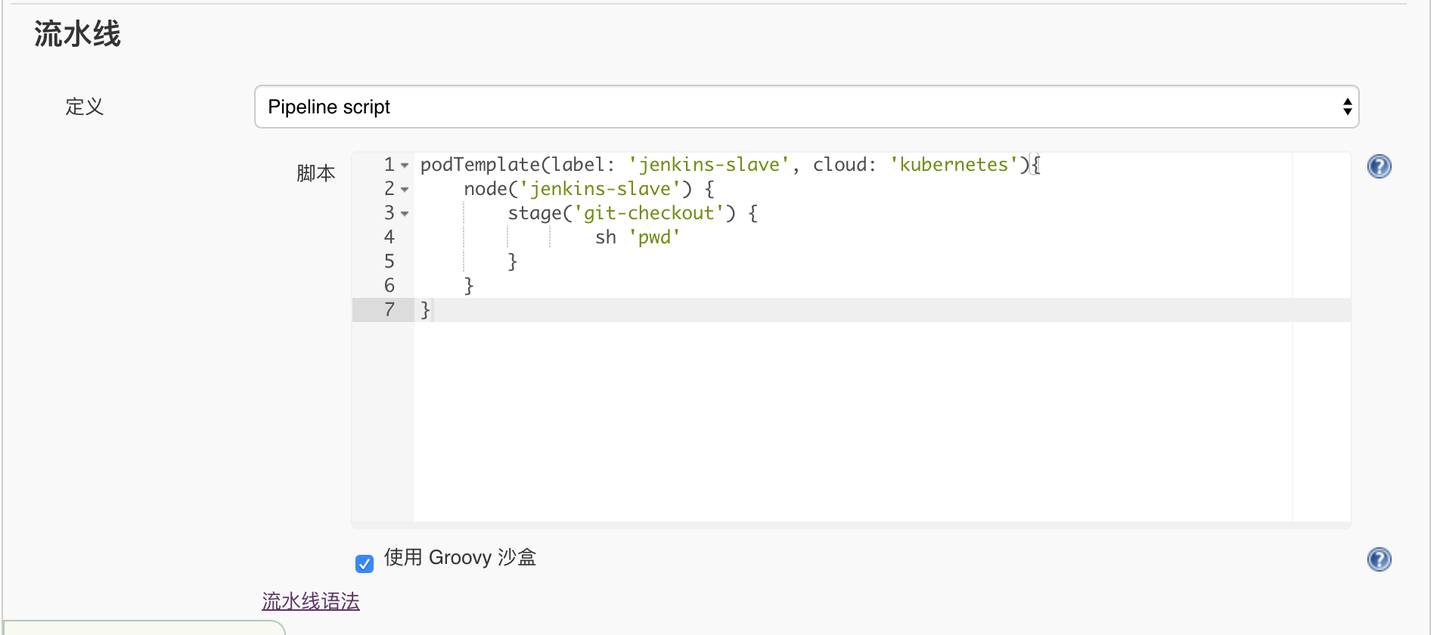
podTemplate(label: 'jenkins-slave', cloud: 'kubernetes'){
node('jenkins-slave') {
stage('git-checkout') {
sh 'pwd'
}
}
}
4,简单功能验证
执行流水线,可以看到jenkins master自动在k8s集群上拉起一个slave节点,并执行了stage内的命令

5,准备构建环境镜像
因为默认启动的jenkins slave节点只具备基础功能,不具备类似maven这种构建环境。所以我们需要准备不同语言所需要的携带不同构建环境的镜像。
可以通过docker search需要对应需求的镜像

也可以自己做镜像,具体dockerfile写法参考如下:
https://github.com/jenkinsci/docker-jnlp-slave
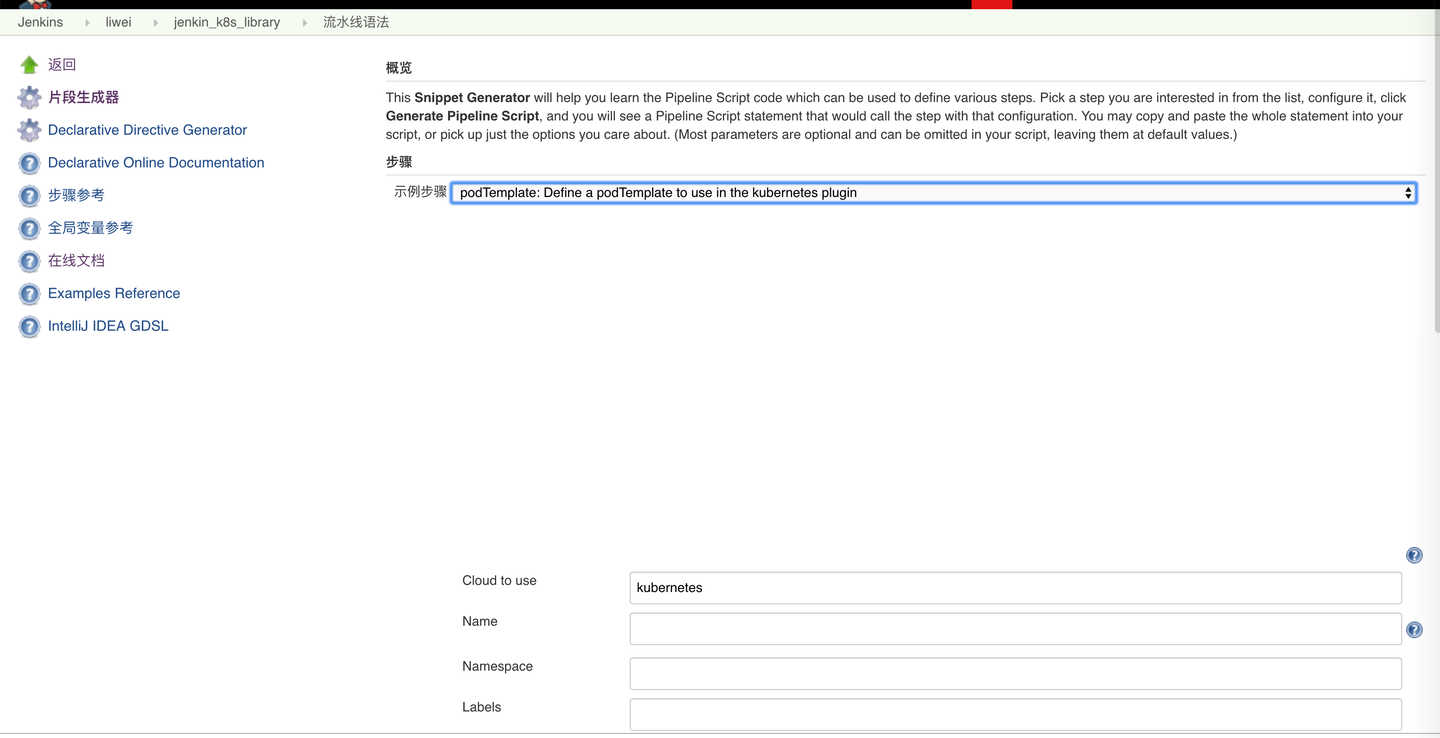
6,编写构建pipeline
语法参见jenkins语法生成器中podTemplate,可自行生成相关流水线语法
7,收集构建过程数据
由于构建环境镜像在job执行成功后会被销毁,所以收集过程中的数据成为这种方案中最关键的一个步骤。下述三个点是我们一定需要收集的信息:
构建产物
所有构建产物应该交给制品库统一管理,pod中的slave节点机构建后即可将制品传输到制品库中,完成后pod销毁
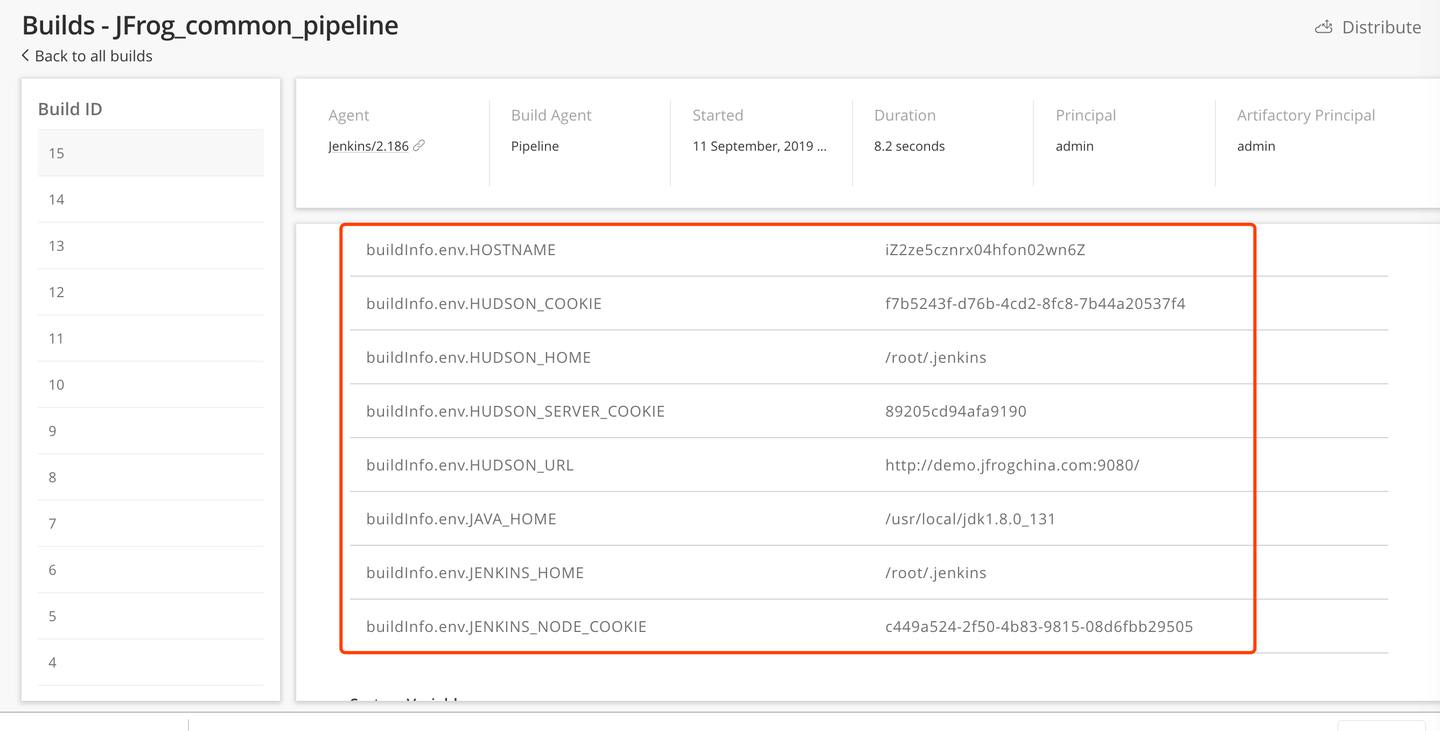
构建环境变量
由于构建环境已经销毁,所以需要通过统一平台管理每次构建时对应的构建环境,如jdk版本,maven版本等,所以该环境最好交由制品库管理,推荐使用Artifactory记录构建过程。
构建元数据
构建过程中会执行一些如代码静态扫描,单元测试等,我们把这种结果数据称之为软件生命周期的元数据,同样这些结果会随着构建环境的销毁一起丢失,我们需要通过api收集结果数据,并与本次构建过程或构建产物相关联。建议使用Artifactory管理构建过程中的元数据。
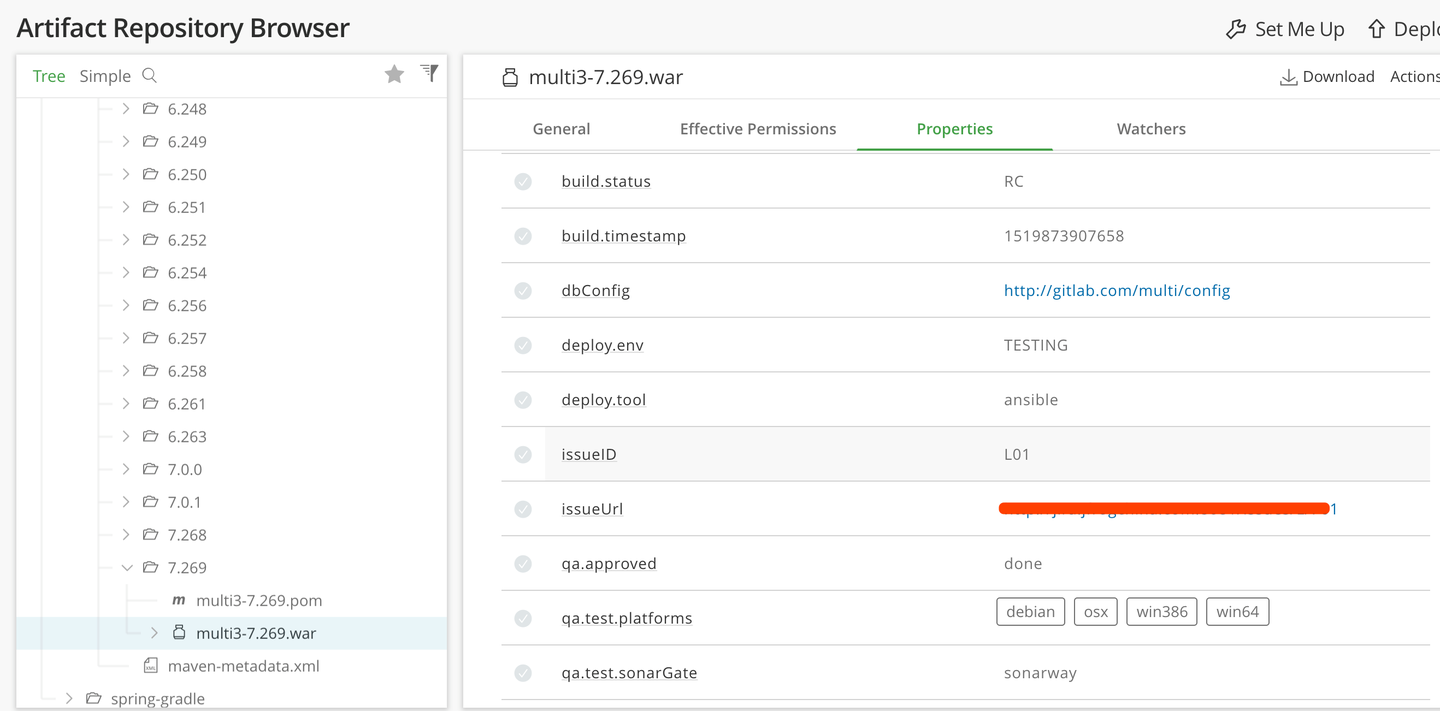
最佳实践
1,统一管理构建环境
由运维维护K8S及Jenkins服务稳定,并按需求制作携带不同构建环境的jenkins slave镜像。
2,由持续集成团队统一编写、统一管理pipeline模版,将模版存储在git仓库中,并提供详细说明文档,指导开发人员如何调用,如何传参。
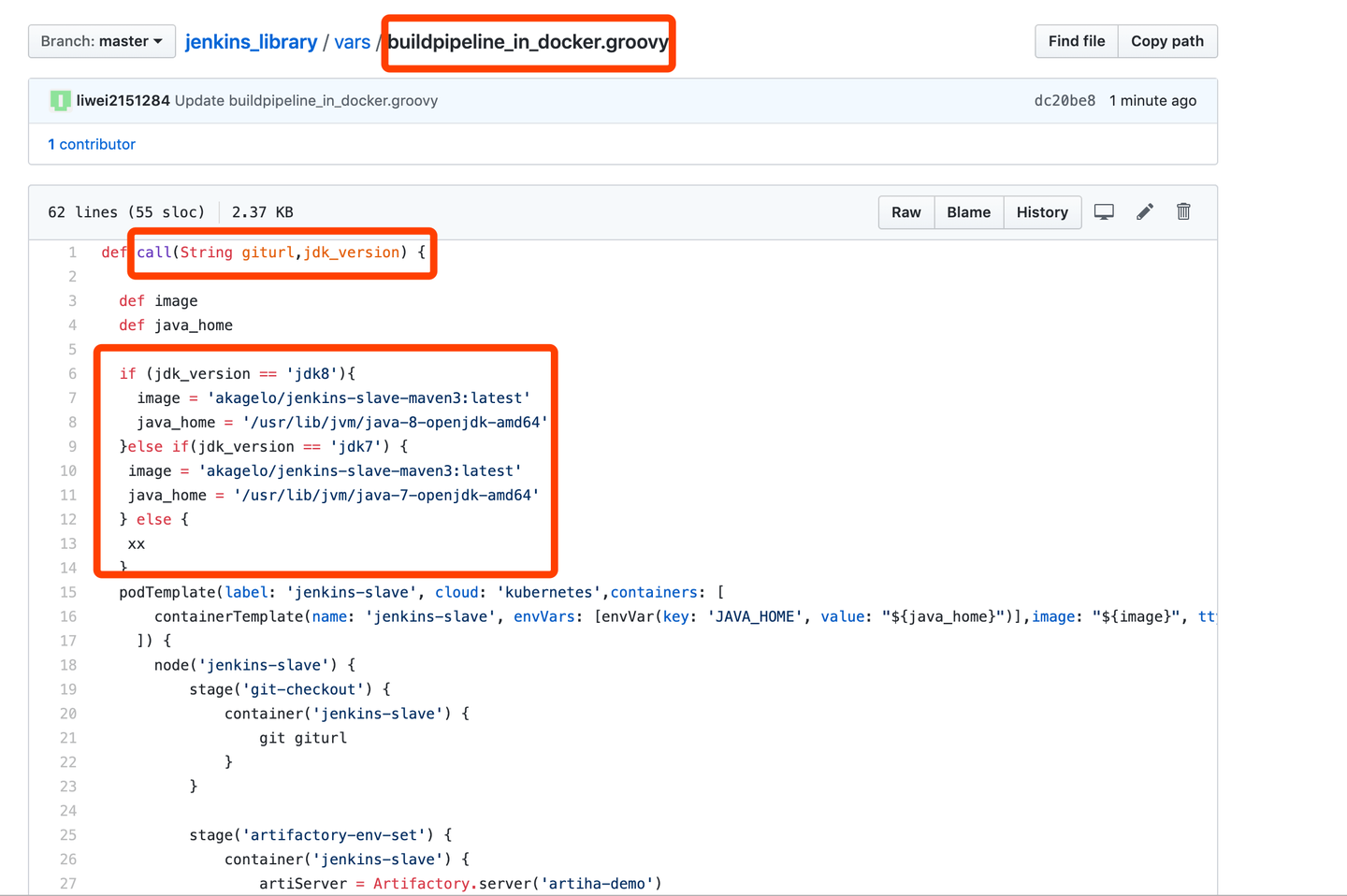
3,业务部门通过jenkins共享库特性调用git仓库中的构建模版,传入所需的构建环境和源码路径以及其他变量进行构建任务设置
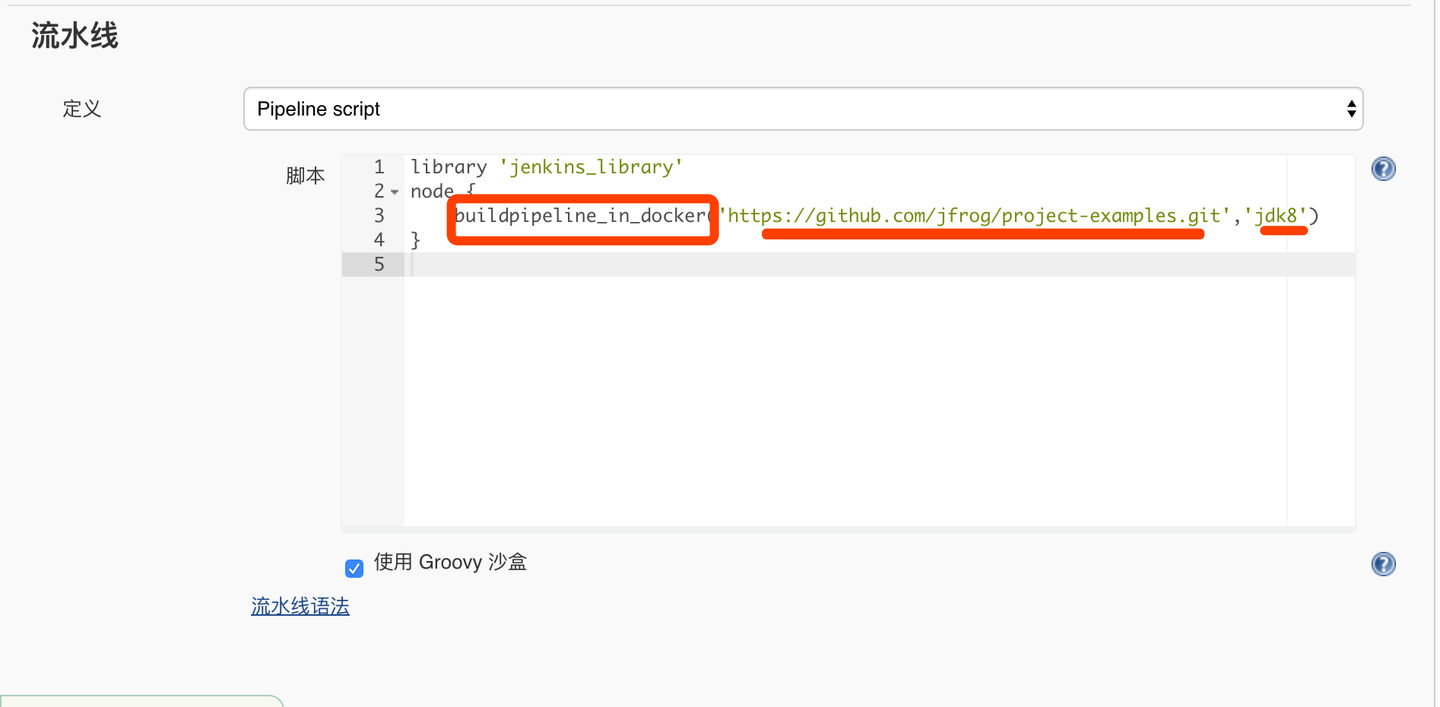
4,持续集成团队需要在构建模版中定义内容收集元数据,收集环境变量,设置质量关卡,做到让开发无感知的情况下,完成所有信息的收集。这样就可以做到,开发人员无需学习复杂的groovy语法编写pipeline;管理人员可以标准化构建流程,并收集所有质量关卡数据,并会写到统一制品仓库管理。
更多精彩内容可以专注我们的在线课堂
微信搜索公众号:jfrogchina 获取课程通知
有疑问加站长微信联系(非本文作者)



