注意,转发的文章时间为2011年,时间比较老了,所以数据只做参考。可以体现出golang的优势。
原文在此:http://en.munknex.net/2011/12/golang-goroutines-performance.html
————————–翻译分割线————————–
概述
在这篇文章里,我将尝试评估 goroutine 的性能。goroutine 是类似轻量级线程的东西。为了提供原生的多任务,它(协同 channel 一起)被内建于Go中。
文档告诉我们:
它实际上是在同一个地址空间里创建成百上千个 goroutine。
因此,这个文章的重点就是测试并明确在如此巨大的并发运行函数的情况下所能承受的性能压力上限。
内存
创建一个新的goroutine所需空间并未记录在文档中。只是说需要几千字节。在不同的机制下测试,帮助确认这个数值为4—4.5kB。因此,5GB差不多足够运行一百万个goroutine。
性能
让我们算算在一个 goroutine 里运行函数会损失多少的性能吧。可能你已经知道这非常简单——只要在函数调用前添加 go 关键字:
go testFunc()
|
goroutine 复用于线程。默认情况下,如果没有设定 GOMAXPROCS 环境变量,程序只使用一个线程。为了利用全部 CPU 内核,则必须制定它的值。例如:
export
GOMAXPROCS=2
|
这个值在运行时使用。因此没有必要在每次修改这个值之后,重新编译程序。
以我的推断,大多数时间花费在创建 goroutine,切换它们,以及从一个线程迁移 goroutine 到另外的线程,还有在不同的线程之间的 goroutine 进行通讯。为了避免无尽的论述,让我们从仅用一个线程的情况开始。
所有测试都是在我的 nettop(译注:英特尔公司的低成本简易台式机解决方案)上完成的:
Atom D525 Dual Core 1.8 GHz
4Gb DDR3
Go r60.3
Arch Linux x86_64
方法
这是测试函数生成器:
func genTest (n
int
) func (res chan <- interface {}) {
return
func(res chan <- interface {}) {
for
i := 0; i < n; i++ {
math.Sqrt(13)
}
res <-
true
}
}
|
然后这里是一系列分别计算 sqrt(13) 1、10、100、1000 和 5000 次的函数集合:
testFuncs := [] func (chan <- interface {}) { genTest(1), genTest(10), genTest(100), genTest(1000), genTest(5000) }
|
我将每个函数在循环中执行 X 遍,然后在 goroutine 中执行 X 遍。然后比较结果。当然,应当留意垃圾回收。为了降低其带来的影响,我在 goroutine 结束后显式调用了 runtime.GC() 并记录结束时间。当然,为了测试精确性,每个测试执行了许多遍。整个运行时间用了大约 16 小时。
一个线程
export
GOMAXPROCS=1
|

图表显示在 goroutine 中运行的 sqrt() 计算工作大约比在函数中运行慢四倍。
来看看剩余的四个函数的情况:
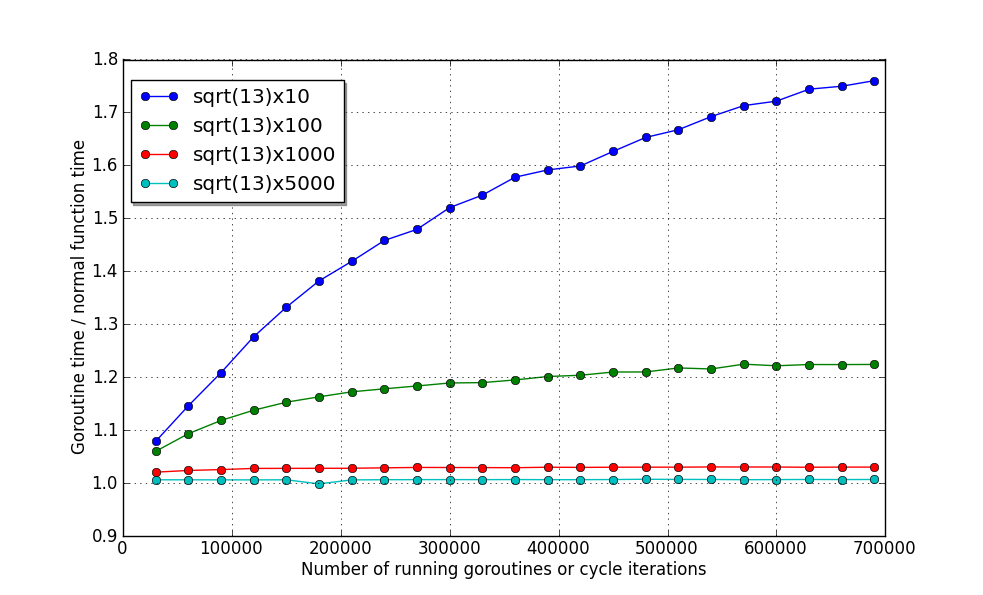
你会注意到,即使并发执行70万 goroutine 也不会使得性能下降到 80% 以下。现在是最值得敬佩的地方。从 sqrt()x1000 开始,总体消耗低于 2%。5000 次——只有 1%。看起来这个数值与 goroutine 的数量无关!因此唯一的制约因素是内存。
概要:
如果互不依赖的代码的执行时间高于计算平方跟的10倍,并且你希望它并发执行,应毫不犹豫的让其在 goroutine 中运行。虽然,可以轻松的将10或者100个这样的代码放在一起,不过损失的性能仅仅分别是 20% 和 2%。
多线程
现在来看看当我们希望使用若干个处理器内核时的情况。在我的用例中是 2 个:
export
GOMAXPROCS=2
|
再次执行我们的测试程序:
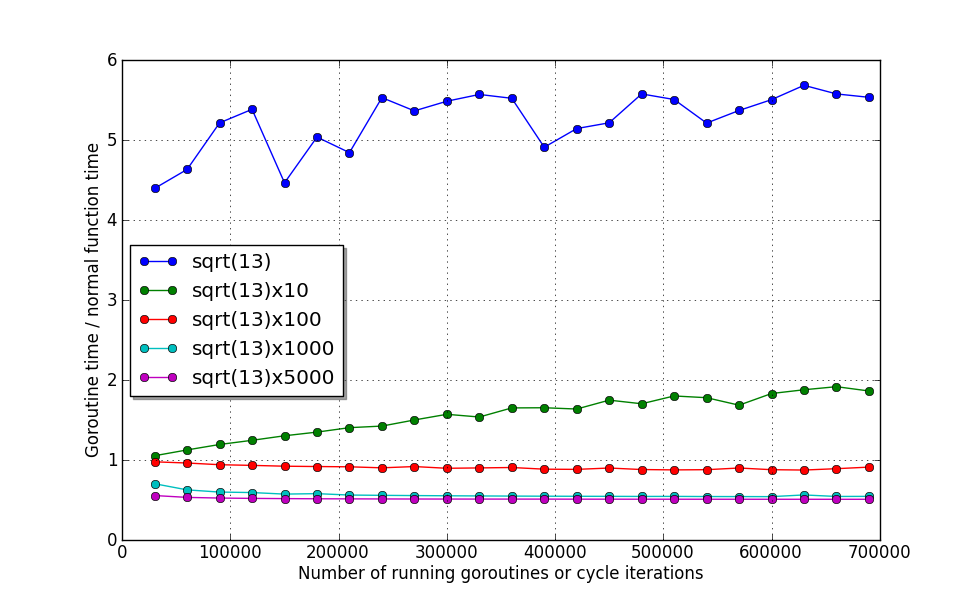
这里你会发现,尽管内核数增加了一倍,但是前两个函数的运行时间却增加了!这极可能是在线程之间移动比执行它们的开销要大得多。:)当前的调度器还不能处理,不过 Go 的开发者承诺在未来会解决这种情况。
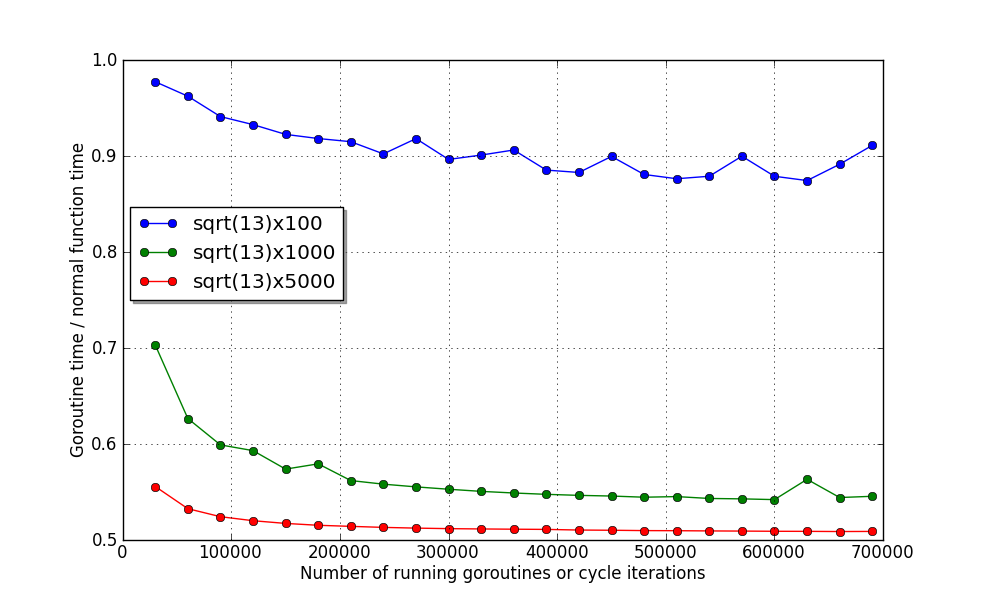
你已经看到了,最后的两个函数完全使用了两个核。在我的 nettop 上,他们的执行时间分别是 ~45µs 和 ~230µs。
总结
尽管这是一个年轻的语言,并且有着一个临时的调度器实现,goroutine 的性能让人觉得兴奋。尤其是与 Go 的简单易用结合起来的时候。这令我印象深刻。感谢 Go 开发团队!
当运行时间少于 1µs 我会在执行 goroutine 之前深思熟虑一下,而如果运行时间超过 1ms,那就决不犹豫的使用 goroutine 了。:)
有疑问加站长微信联系(非本文作者)



