书接上文:Go的隐秘世界:Go程序的启动和runtime初始化
子曰:学而不思则罔,思而不学则殆。上文我们通过反汇编回溯了 Go 程序的启动过程如何引导 Go runtime。是为思。接下来,为了读懂 Go runtime 是如何调度 goroutines 的,最好先学习一下,从而在脑海中建立起核心概念的导图;这样,读 Go runtime 源码的时候可以沿着导图补充细节。
2020年9月15日注:感谢我的同事伟忠提醒雨痕的Go源码剖析 qyuhen/book 。篇章结构和分析方法让我很受启发。只是成书日久,其内容和目前的Go版本颇有差距了。我会读完此书后继续更新这个系列。
从哪儿学呢?当然是前人的总结以及 Go 语言的设计文档。首先,我们借用 https://www.ardanlabs.com/blog/2018/08/scheduling-in-go-part2.html 里的图,展示一下一个 Go 进程里有几个 P、M、和 G。
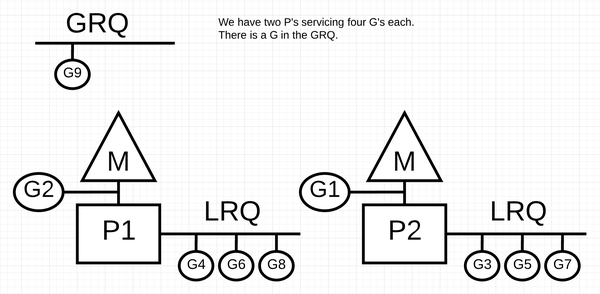

P 和 LRQ
上图中有两个 P。实际上会有几个 P 呢?大家还记得 runtime.GOMAXPROCS 函数吗?它指定一个 Go 进程里有几个 P。
P 对应 CPU core 吗?不。P 和 CPU core 没有直接关系。倒是利用 P 执行 G 的线程 M,被操作系统调度器(OS scheduler)调度到 core 上去执行;也就是说 M 和 core 的关系更直接。
P 的主要作用是描述执行 G 的“资源”。上图中的 LRQ 是 local run queue 的缩写,里面放的是准备好可以执行(ready to run、runnable)的 G 们。什么叫”准备好“?如果一个 G 没有在执行 I/O 操作并且等待网卡硬盘等,而是可以继续执行计算 —— 我们称这个 G 是准备好了。
那些处于等待中的 G 们在哪儿呢?在一个叫 netpoll 的概念里。上图没有画出来。我们下文细说。
回到 P 这个概念。我们说它表示的是执行 G 的资源 —— 这个资源到底是什么呢?是 stack 吗?不是 —— 每个 G 有自己的 stack,这是 G 可以调用函数的必备属性。类似的,每个 M 也有 stack,因为 M 是操作系统创建和维护的,所以 M 的 stack 也是 M 的属性。那么 P 的所谓”资源“到底是个啥?其实就是 LRQ。我们看看 P 的定义 golang/go ,除了各种计数、时间戳、timers,最重要的就是 LRQ 和它对应的 M 了:
type p struct {
m muintptr // back-link to associated m (nil if idle)
// Queue of runnable goroutines. Accessed without lock.
runqhead uint32
runqtail uint32
runq [256]guintptr
LRQ 和 GRQ
P 的存在很大程度上是为了有多个 LRQ。那么为什么要有这些 LRQ 呢?如果没有它们,所有的 G 们就都在 global run queue(上图中的 GRQ)里了。现代 CPU 都有多个 core,要用满它们就得有多个 M;这些 M 都从 GRQ 里取 runnable G 来执行,那么就得有个同步机制来保护 GRQ,比如一个 mutex;那么这些 M 在取 G 的时候就都得等待这个 mutex。反过来,每个 M 从自己的的 P 对应的 LRQ 里取 G 来执行,则不需要等这个 mutex。
上面这段话在 Go 1.11 重新设计 goroutine 调度机制的设计文档里简单地提了一句:
What's wrong with current implementation:
1. Single global mutex (Sched.Lock) and centralized state. The mutex protects all goroutine-related operations (creation, completion, rescheduling, etc).
那么 GRQ 还要不要了呢?还是要的,因为很多时候新建的 G 会被放进 GRQ 里。【感谢阿里的同事汪少军、曹春晖提醒】新 G 默认放在创建新 G 的老 G 所在的 P 的 LRQ。不过 P 的 LRQ 大小有限,就在上面贴的代码里 —— runq [256]guintptr;如果 LRQ 满了,则会放进 GRQ 里 —— 代码在这里。
那么,这些 GRQ 里的 G 们什么时候会被执行呢?我们看看 runtime.schedule 函数里的代码就知道了 golang/go 。这个函数在下文里还会再次出现,我们会细细分析它。
if gp == nil {
// Check the global runnable queue once in a while to ensure fairness.
// Otherwise two goroutines can completely occupy the local runqueue
// by constantly respawning each other.
if _g_.m.p.ptr().schedtick%61 == 0 && sched.runqsize > 0 {
lock(&sched.lock)
gp = globrunqget(_g_.m.p.ptr(), 1)
unlock(&sched.lock)
}
}
if gp == nil {
gp, inheritTime = runqget(_g_.m.p.ptr())
// We can see gp != nil here even if the M is spinning,
// if checkTimers added a local goroutine via goready.
}
由上面代码可以看出来,调度器每执行 61 个 ticks,则试图从 GRQ 里取 G 来执行。如果 GRQ 里没有 G 可取,则去当前 P 的 LRQ 里取。这里函数 globrunqget 从 GRQ 里取,而 runqget 是从 LRQ 里取。
G
在 LRQ 和 GRQ 里装着 G 们。一个 G 长什么样儿呢?这里是其定义golang/go 。其中核心的内容如下:
type g struct {
stack stack // offset known to runtime/cgo
stackguard0 uintptr // offset known to liblink
stackguard1 uintptr // offset known to liblink
_panic *_panic // innermost panic - offset known to liblink
_defer *_defer // innermost defer
m *m // current m; offset known to arm liblink
sched gobuf
首先,stack, stackguard0, stackguard1 都是描述 goroutine 的 stack 的。我们甚至可以把 stack 理解成一个基本数据类型,就像 int 和 float 一样。这类型的一个实例(instance)就是一个 goroutine。而创建 goroutine 的操作(关键词 go)是一种控制流,就像 if 和 for 一样。
在 Go 的术语里,goroutine 的 stack 叫做 user stack,而 M 的 stack 叫做 system stack。上述 stack 类型描述 user stack。它包括的内容很简单:栈底和栈顶。
type stack struct {
lo uintptr
hi uintptr
}
这里顺便说一下,一个 Go 进程里可以有几万个 goroutine,隐含条件是每个 goroutine 的 stack 不会占用太大空间,否则内存就被消耗完了。这是怎么做到的呢?每个 user stack 开始都不大,就像 v:=make([]int, 0) 申请的空间不太大 —— 具体的说是 2KB。如果这个 goroutine 调用函数的深度很深,则 user stack 会动态增大,就像我们 v=append(v, 123) 可能会增加 v 的实际长度(cap)。User stack 的动态增长机制定义在 stack.go golang/go 这个文件里。
与之对应的,system stack 的长度是定死的(fixed)。这是应该是操作系统的设计决定的。毕竟操作系统不能替应用程序(或者其使用的编程语言的编译器)决定如何管理 stack,没法在运行时调整 stack 的大小。
上面 G 的定义里还包括等待被执行的 panic 和 defer 函数的链表。链表节点里都有指向下一个节点的指针:
type _defer struct {
link *_defer
type _panic struct {
link *_panic
类型是 gobuf 的 sched 是当前 goroutine 的上下文,包括 SP 和 PC 寄存器的值。下文还要详述。指针 m 指向当前在负责执行这个 G 的 M。
M
M 是操作系统创建的线程。Go runtime 里创建 M 的函数叫 newm —— 这是前文 Go的隐秘世界:一个Goroutine要几个Thread 中提到过的名字 —— 其定义在这里。
// Create a new m. It will start off with a call to fn, or else the scheduler.
// fn needs to be static and not a heap allocated closure.
// May run with m.p==nil, so write barriers are not allowed.
//
// id is optional pre-allocated m ID. Omit by passing -1.
//go:nowritebarrierrec
func newm(fn func(), _p_ *p, id int64) {
其中第一个参数是这个线程启动后要执行的 Go 函数。如果 fn 是 nil,则默认执行 scheduler。这个 scheduler 是什么呢?我们仔细看看源码。
在 newm 里创建了一个变量 mp,并且把 fn 放进去了,然后调用了 newm1(mp)。而 newm1(mp) 又调用了 newosproc(mp)。这个 newosproc 函数的定义在 os*.go 里。我们看看 os_linux.go 里的定义:
func newosproc(mp *m) {
...
ret := clone(cloneFlags, stk, unsafe.Pointer(mp),
unsafe.Pointer(mp.g0),
unsafe.Pointer(funcPC(mstart)))
它调用了一个叫 clone 的函数,来创建线程,并且执行 mstart 函数(当 fn 是 nil时)。
这个 clone 函数在同一个 .go 文件里,不过只有声明,没有定义。
//go:noescape
func clone(flags int32, stk, mp, gp, fn unsafe.Pointer) int32
这种情况有两种可能:(1)clone 定义在别的 package 里的某个 .go 文件里,通过 //go:linkname 暴露给当前 package 用;或者(2)clone 定义在汇编源码里。此处是第二种情况 —— 对于 Linux 和 AMD64 CPU 的情况下,clone 的定义在 sys_linux_amd64.s 里。它没有调用 C runtime 函数,而是直接通过 SYSCALL 指令,发起了操作系统调用。
#define SYS_clone 56
TEXT runtime·clone(SB),NOSPLIT,$0
...
MOVL $SYS_clone, AX
SYSCALL
// In parent, return.
...
RET
// In child, on new stack.
MOVQ fn+32(FP), R12
// Call fn
CALL R12首先,它把系统功能调用编号 56 写入 AX,然后调用 SYSCALL 指令 —— 这就发起了一次对 56 号操作系统功能的调用。此时,CPU 进入内核态,执行系统功能调用对应的中断处理程序(interrupt handler)。这个中断处理程序是 OS kernel 提供的;它一看 AX 的值是 56,就知道这是应用程序请操作系统创建一个新的线程。操作系统创建线程之后,新的线程也执行 clone 函数。此时老线程(父线程)执行 RET 指令返回。新线程执行参数 fn。如上面介绍,fn 是 nil 时,默认为 mstart。而这个 mstart 函数会调用 mstart1,而 mstart1 会调用 schedule 函数。
这个 schedule 函数就在上面一段里出现了 —— 它就是 M 执行的函数,它不断从 GRQ 或者 LRQ 里取 G 来执行。一个 M 是如何执行一个 G 的呢?
g0
上面说了,一个 M 执行的是 Go 代码 mstart/mstart1/schedule。这看起来就像一个 G 在执行 Go 代码一样啊。唯一不同的是, schedule 这个 Go 函数不仅可以调用其他函数,而且可以”切换“到其他 G 并执行之 —— 这个”切换“具体是个什么动作呢?
为了解释清楚 goroutine 的切换,我们得先说说函数调用,因为这两件事有相当程度的相似性。
我们都知道函数调用是通过执行 CALL 指令实现的。这条指令在 stack 上新建一个 frame,换句话说,把栈顶指针往上挪出去 frame size 的空间;这个栈顶指针通常存储在 CPU 的一个(虚拟)寄存器 SP(stack pointer)里。创建了新的 stack frame 之后,还需要把函数参数拷贝到新的 frame 里,然后让 CPU 执行被调用的函数 —— 也就是让 CPU 的 PC 寄存器的值变成被调用函数的起始地址;这样 CPU 接下来从 PC 包含的地址取指令来执行,也就开始执行被调用函数了。
CALL 指令修改 SP 和 PC 之前把它俩的值保存起来了,供 RET 指令使用。RET 指令是被调用函数的最后一条指令,它让 CPU 恢复事先保存的老的 SP 和 PC 的值,这样接下来 CPU 会执行调用函数在调用点之后的那条指令 —— 也就是继续执行调用函数了。
那么 goroutine 切换要做什么呢?其实和函数调用一样,也是要修改 CPU 的 SP 和 PC 寄存器的值 —— 只是 SP 的修改不是简单地在当前 stack 范围里挪动了,而是会指向另一个 goroutine 的 stack 里的某个 frame。类似的,通过 RET 指令恢复 SP 和 PC,则切换回了之前的那个 goroutine。
所以 goroutine 的切换和函数调用如此类似啊!理解了这个相似性,我们就可以逻辑上把 M 执行 schedule 函数这个事儿“想象”成一个 goroutine 在执行 —— 这个想象中的 G 叫做 M 上的 g0。
当 M 被创建的时候,就有 g0 了。这个 g0 用的是 system stack,也就是 M 的 stack,而不是某个 G 的 stack,来执行 schedule 函数。
当 schedule 函数从 LRQ 或者 GRQ 取到一个 G,并且发起 goroutine 切换的时候,我们说 M 不再执行 g0,而是在执行这个新取到的 G 了。因为 G 执行的是一个 Go 函数,而任何函数的最后一条指令是 RET,所以当 G 执行完了之后,SP 和 PC 的值恢复到继续执行 g0。而 g0 仍然在 schedule 函数的无限循环里 —— 它会继续去找下一个可以执行的 G,然后切换过去执行之。
小结
本文详述了 P、G、M 和 run queue 的逻辑关系。也解释了所谓的 goroutine context switch(切换)到底是怎么实现的。默认解释了为什么任何 G 执行完了之后,M 都会默认切换回到 g0。
本文提及但是未及详述的概念包括 netpoll 将在接下来的章节里解释。接下里的章节说什么呢?刚才提到 g0 如果取到了 G 则执行之,如果 LRQ 和 GRQ 里都没有 G 可执行呢?它会尝试去其他 LRQ 偷! —— 这个“偷” 是 schedule 函数描述的 Go 调度策略之一。接下里的章节当然就是讲讲调度策略了。
这个调度策略可讲的内容还挺多的。上面介绍的 g0 切换到其他的 G,再切换回来的过程是调度的基本过程。实际过程有更多的情况需要讨论,这是因为 M 除了执行定义 goroutine 的 Go 函数,还会执行 Go 函数(可能)发起的 Cgo 调用,Go 函数通过 Go 标准库函数发起的 system calls(操作系统功能调用),以及处理 Unix 系统里的信号(signal)。这些情况下,“调度”就不是简单地在 goroutines 之间切换这么简单的了。
好了,欲知 goroutines 调度器和 Cgo 以及 system calls 打交道的时候会发生什么,请听下文分解。
有疑问加站长微信联系(非本文作者)




