
> 在应用程序中,经常需要全局唯一的ID作为数据库主键。在一台节点容易全局唯一,那在多台节点呢?
### 有两个思路:
- 1使用散列函数,如sha256,加上时间戳、mac地址、cpu负荷、随机数等组成,id足够长,引入多个不确定因素,以至于碰撞几率非常小,可以认为是全局唯一。例如uuid就是这种。但是uuid是字符串的形式,对于DB来说,占用的空间至少大一倍,DB的索引是需要存储和对比的,因此在存储空间和查询时间上面都比整形要低,这种情况在DB的数据条数越多时越明显。
- 2使用分割法。每个节点都保证自己生成的所有id在本机唯一,每个节点都有一个人为分配的不重复节点编号,插入id中,这样所有节点的id都是全局唯一的。
- 3利用DB自带的主键唯一性来确保id唯一。但是db的自增id是需要等到事务提交后,ID才算是有效的。有些双向引用的数据,不得不插入后再做一次更新,比较麻烦。
> 第二种方式是类似Twitter的Snowflake算法,它给每台机器分配一个唯一标识,然后通过时间戳+标识+自增实现全局唯一ID。这种方式好处在于ID生成算法完全是一个无状态机,无网络调用,高效可靠。缺点是如果唯一标识有重复,会造成ID冲突。
> Snowflake算法采用41bit毫秒时间戳,加上10bit机器ID(最多支持1024台id服务器),加上12bit序列号,理论上最多支持1024台机器每秒生成4096000个序列号。409万个id每秒,在任何交易平台目前都是够用的。
推特的id构成(从最高位往最低位方向):
- 1位 ,不用。固定是0
- 41位 ,毫秒时间戳
- 5位 ,数据中心ID (用于对数据中心进行编码)
- 5位 ,WORKERID (用于对工作进程进行编码)
- 12位 ,序列号。用于同一毫秒产生ID的序列 (自增id)
下面是用golang实现的uuid方法(uuid类型为整形):
```go
package main
import (
"fmt"
idworker "github.com/gitstliu/go-id-worker"
)
func main() {
currWoker := &idworker.IdWorker{}
currWoker.InitIdWorker(1000, 1)
newID, err := currWoker.NextId()
if err == nil {
fmt.Println(newID)
}
}
````
下载库
```shell
go get github.com/gitstliu/go-id-worker
```
下面是在vscode中的调试结果
```shell
API server listening at: 127.0.0.1:4442
4917572028174794752
Process exiting with code: 0
```
## 用mysql自带的自增id生成全局唯一id
```go
package main
import (
"database/sql"
"errors"
"log"
"time"
"fmt"
_ "github.com/go-sql-driver/mysql"
)
type logger interface {
Error(error)
}
// Logger Log接口,如果设置了Logger,就使用Logger打印日志,如果没有设置,就使用内置库log打印日志
var Logger logger
// ErrTimeOut 获取uid超时错误
var ErrTimeOut = errors.New("get uid timeout")
type Uid struct {
db *sql.DB // 数据库连接
businessId string // 业务id
ch chan int64 // id缓冲池
min, max int64 // id段最小值,最大值
}
// NewUid 创建一个Uid;len:缓冲池大小()
// db:数据库连接
// businessId:业务id
// len:缓冲池大小(长度可控制缓存中剩下多少id时,去DB中加载)
func NewUid(db *sql.DB, businessId string, len int) (*Uid, error) {
lid := Uid{
db: db,
businessId: businessId,
ch: make(chan int64, len),
}
go lid.productId()
return &lid, nil
}
// Get 获取自增id,当发生超时,返回错误,避免大量请求阻塞,服务器崩溃
func (u *Uid) Get() (int64, error) {
select {
case <-time.After(1 * time.Second):
return 0, ErrTimeOut
case uid := <-u.ch:
return uid, nil
}
}
// productId 生产id,当ch达到最大容量时,这个方法会阻塞,直到ch中的id被消费
func (u *Uid) productId() {
u.reLoad()
for {
if u.min >= u.max {
u.reLoad()
}
u.min++
u.ch <- u.min
}
}
// reLoad 在数据库获取id段,如果失败,会每隔一秒尝试一次
func (u *Uid) reLoad() error {
var err error
for {
err = u.getFromDB()
if err == nil {
return nil
}
// 数据库发生异常,等待一秒之后再次进行尝试
if Logger != nil {
Logger.Error(err)
} else {
log.Println(err)
}
time.Sleep(time.Second)
}
}
// getFromDB 从数据库获取id段
func (u *Uid) getFromDB() error {
var (
maxId int64
step int64
)
row := u.db.QueryRow("SELECT max_id, step FROM uid;")
//row = u.db.QueryRow("SELECT max_id, step FROM uid WHERE business_id = ? FOR UPDATE",1)
if err :=row.Scan(&maxId, &step); err != nil{
fmt.Printf("scan failed, err:%v",err)
return err
}
_, err := u.db.Exec("UPDATE uid SET max_id = ?", maxId+step)
if err != nil {
return err
}
u.min = maxId
u.max = maxId + step
return nil
}
const (
DeviceIdBusinessId = "device_id" // 设备id
)
var(
DeviceIdUid *Uid
)
func InitUID(db *sql.DB) {
var err error
DeviceIdUid, err = NewUid(db, DeviceIdBusinessId, 5)
if err != nil {
panic(err)
}
}
func check(err error) {
if err != nil {
panic(err)
}
}
const (
USER_NAME = "root"
PASS_WORD = "123456"
HOST = "localhost"
PORT = "3306"
DATABASE = "test"
CHARSET = "utf8"
)
//
func main() {
// http init
// http api goroutine
url := fmt.Sprintf("%s:%s@tcp(%s:%s)/%s?charset=%s", USER_NAME, PASS_WORD, HOST, PORT, DATABASE, CHARSET)
db, err := sql.Open("mysql", url)
if err != nil {
panic(err)
}
InitUID(db)
for i:=0; i<20; i++ {
id ,err := DeviceIdUid.Get()
if err == nil {
fmt.Println("id=", id)
} else {
fmt.Println(err)
}
}
}
```
测试结果:
```shell
[root@bogon uid]# go build main.go
[root@bogon uid]# ./main
id= 1706
id= 1707
id= 1708
id= 1709
id= 1710
id= 1711
id= 1712
id= 1713
id= 1714
id= 1715
id= 1716
id= 1717
id= 1718
id= 1719
id= 1720
id= 1721
id= 1722
id= 1723
id= 1724
id= 1725
[root@bogon uid]#
```
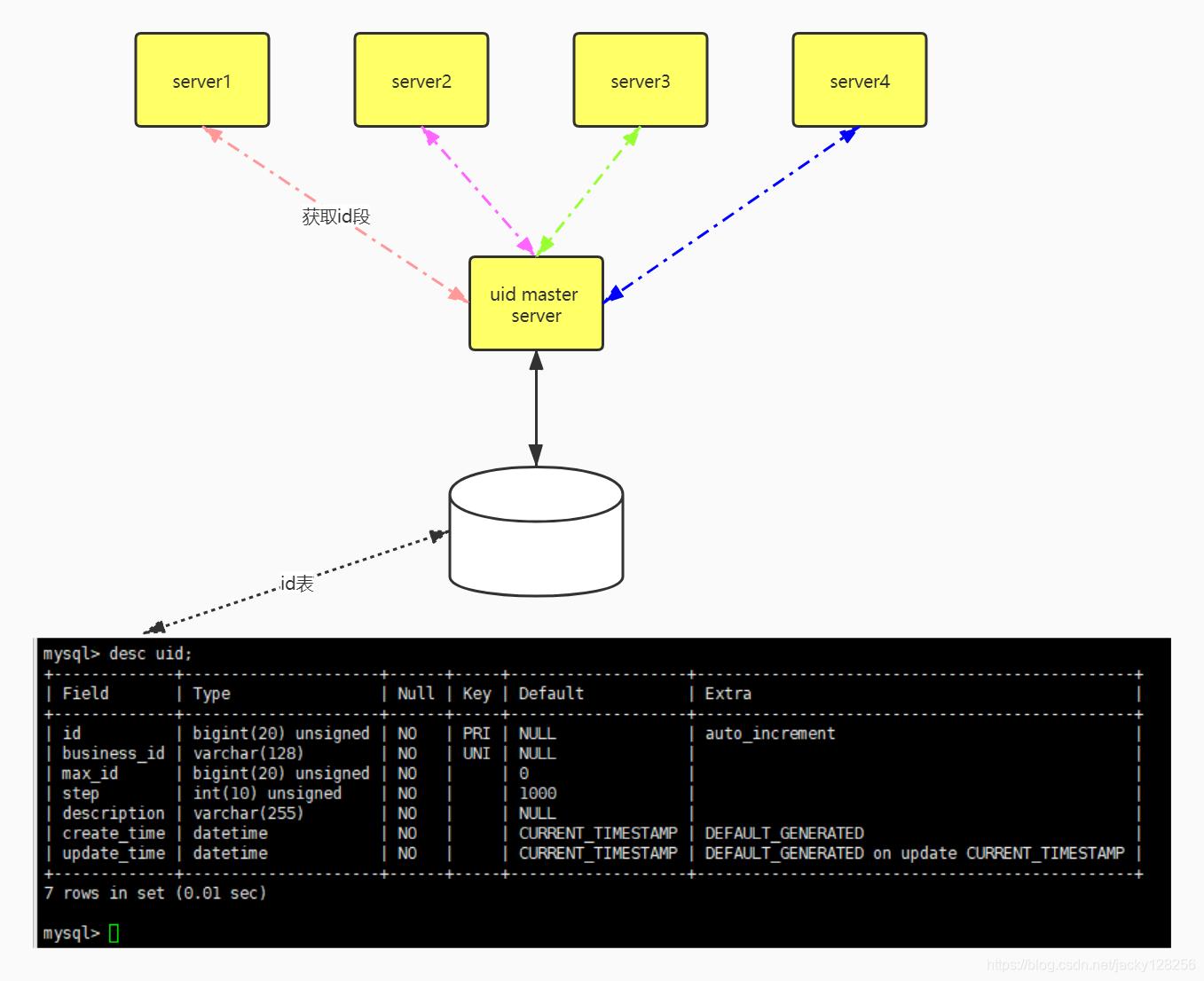
>改进:上面的是单机版本的uid生成器。单机的流量会有瓶颈。因此是实际的商业部署期间。如果一台不能满足uid,则设置一个单独的http server go程,其它业务节点从本节点获取一段uid(step需要调整,例如从5变成1w),其它节点请求一次,则返回1w个uid,不管这1w个uid有没有用完,都不再分配给其它节点,这样保证了全局唯一性。
以下为uid服务器的架构图:
有疑问加站长微信联系(非本文作者))




