
# 现象
article-go微服务有请求502,之前稀稀拉拉有少量的502(有同学排查过,未果),但是运维同学最近升级了ingress,502变多了。

# 信息收集
## 大量的TW
登录article-go容器,使用`lsof -p 1`查看进程的fd信息,发现大量的TIME_WAIT。查询了下目标地址,都是ingress pod的地址。
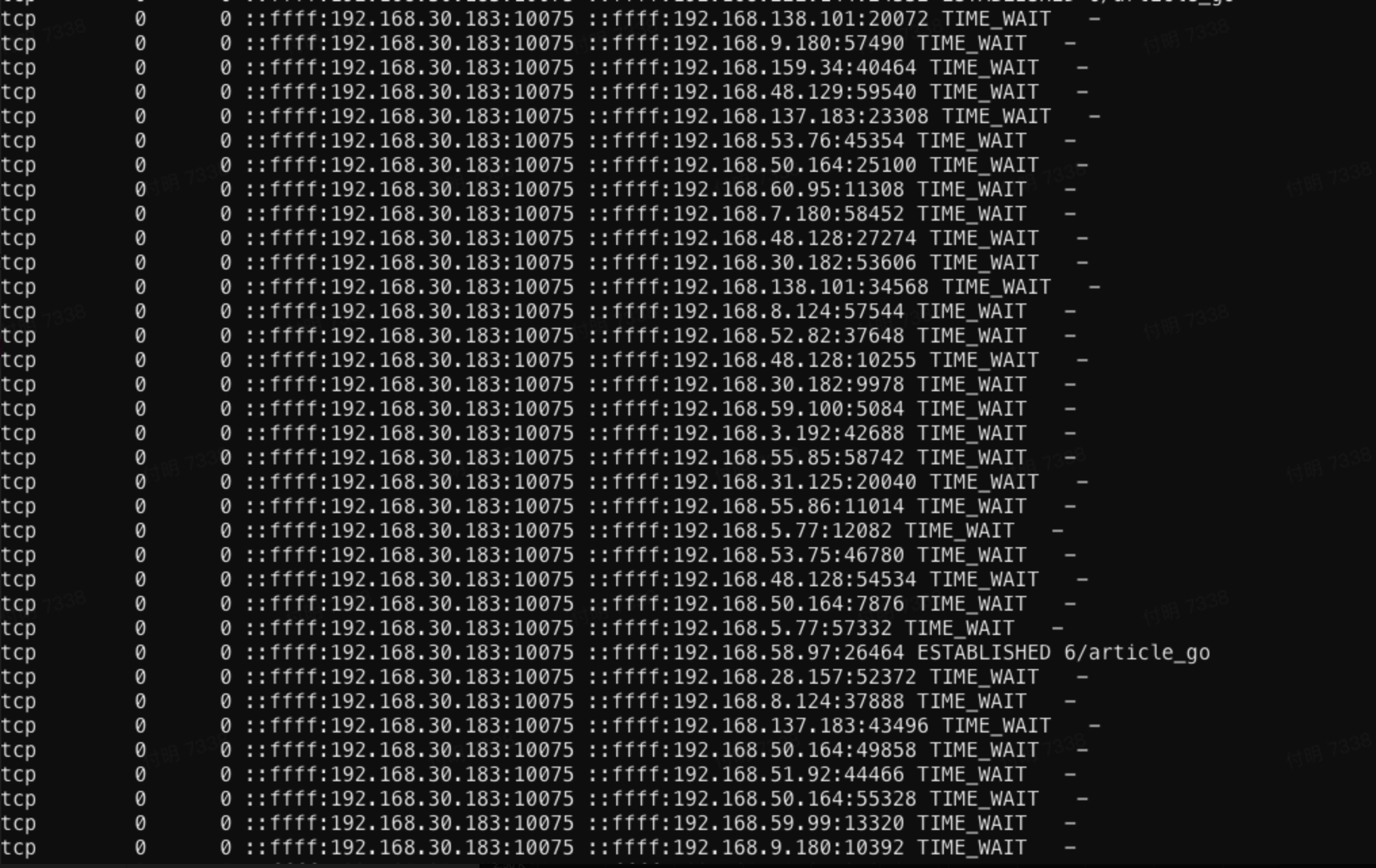
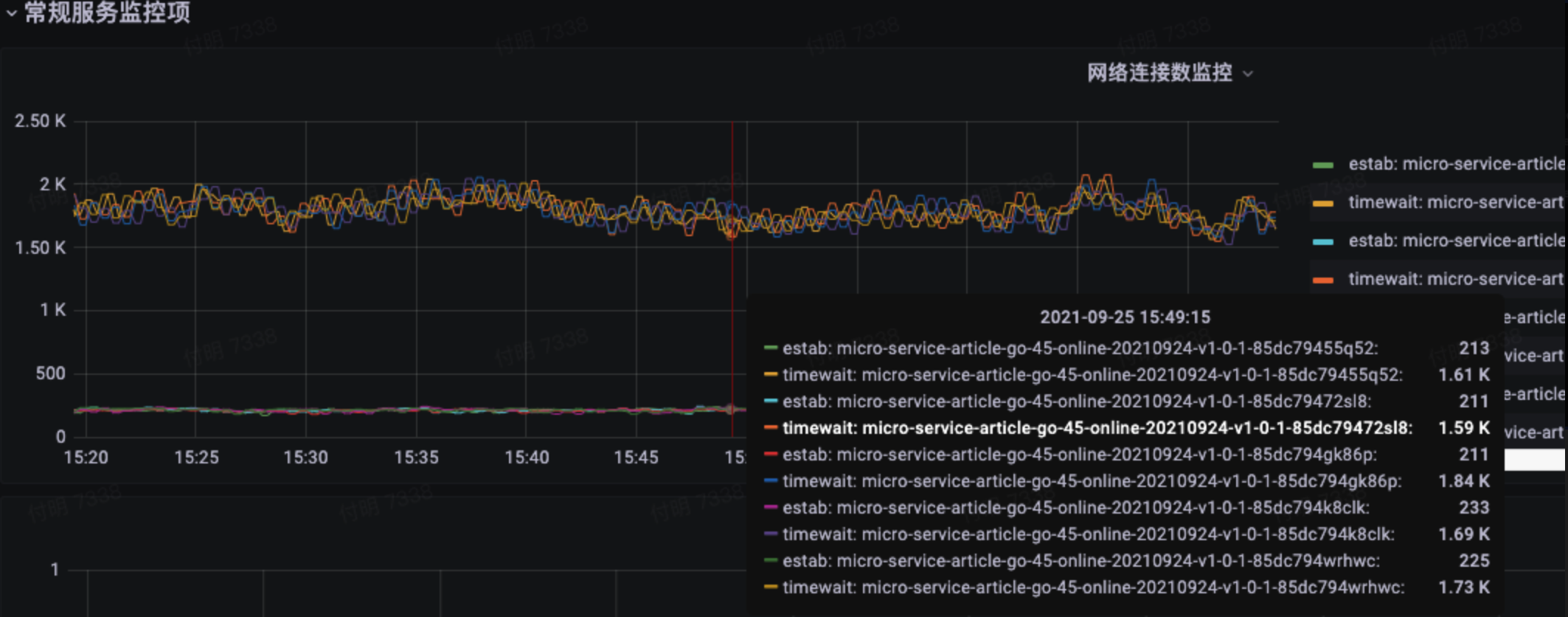
首先TIME_WAIT就非常可疑,先看下TCP的四次挥手过程:
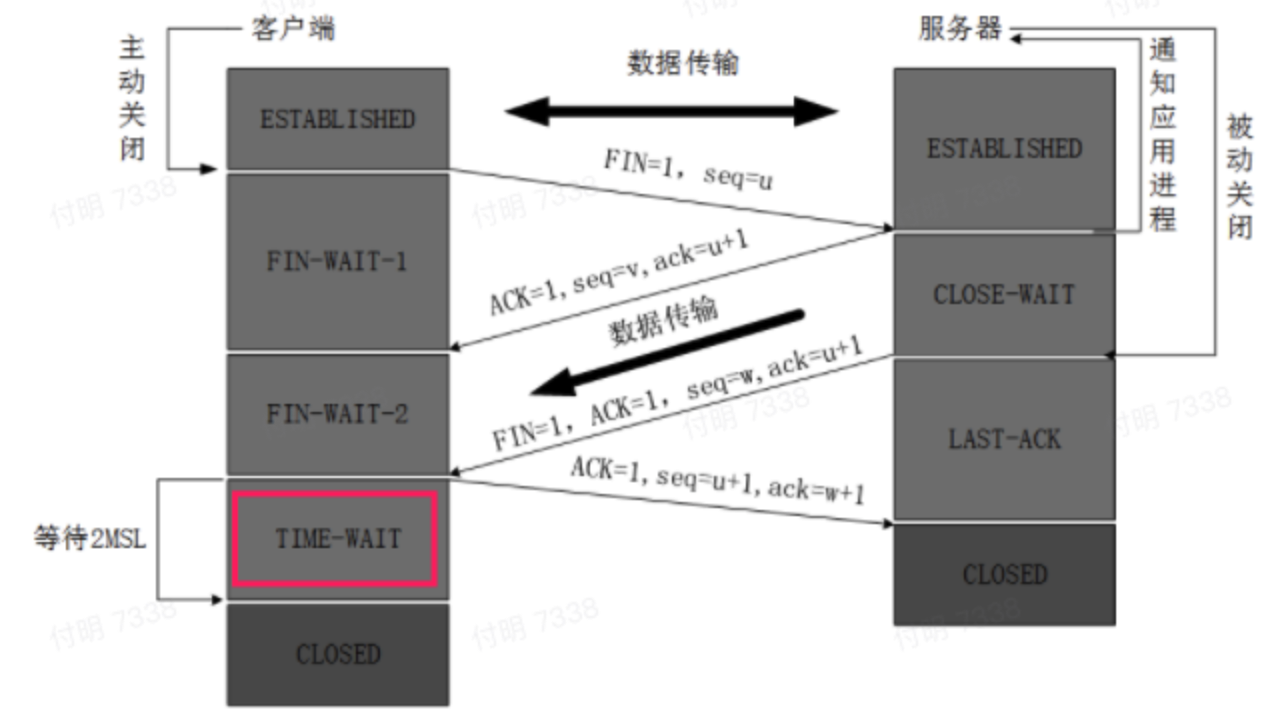
发现只有客户端的连接状态才可能是TIME_WAIT,我们article_go明明是服务端,怎么会有TIME_WAIT状态呢(这个是(我)一个认知错误,后面会提到)?
## 抓包
随便找了一次接口请求,发现是正常的,先3次握手建立连接,然后request、response都很正常。

想到http 1.1里面服务端response的时候是可以加一个 `connection: close`header头来主动断开链接的,看下请求header信息:
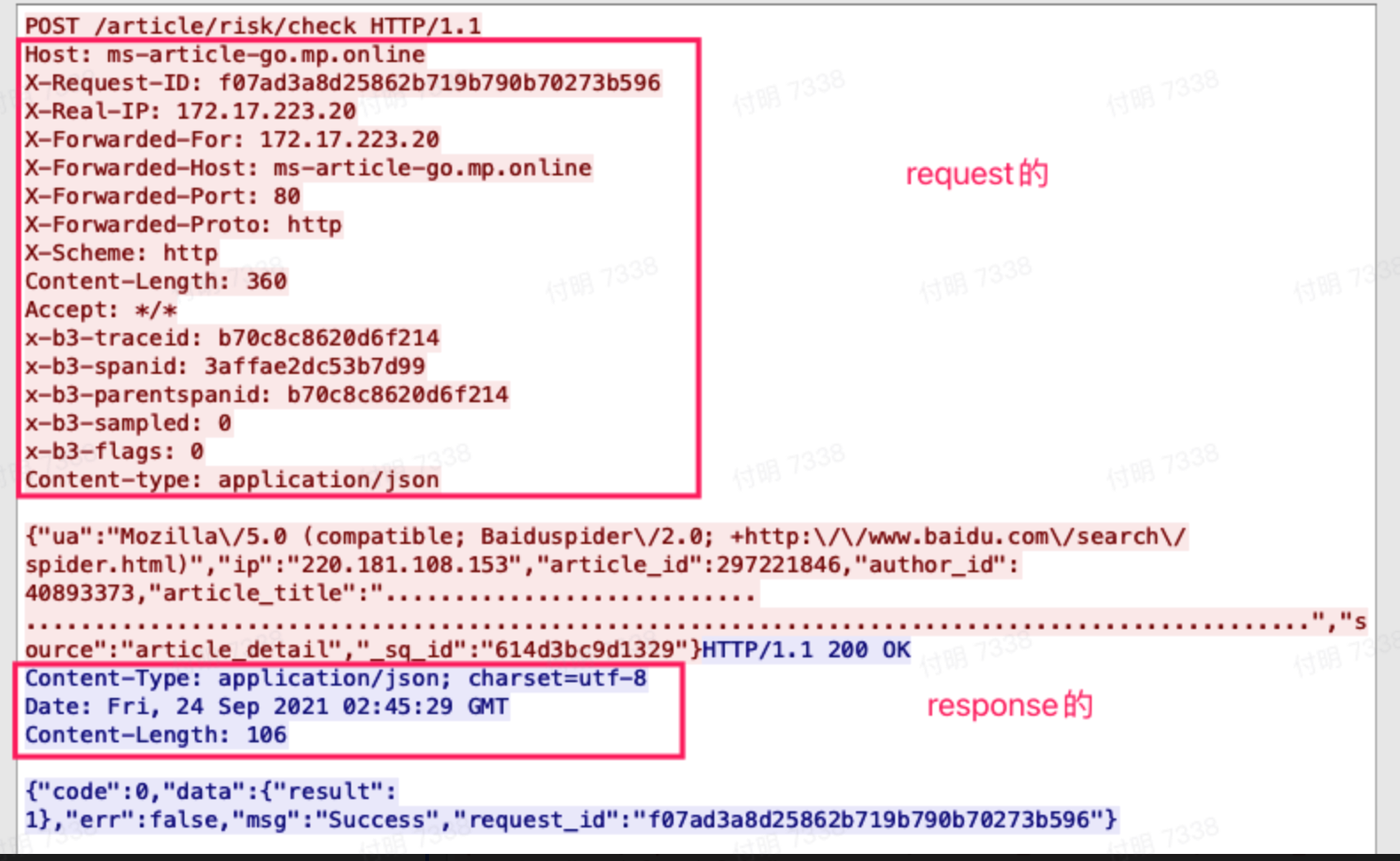
发现正常,服务端没有设置header头主动断开链接。
**那是咋回事?脱发中。。。**
# 查疑解惑
## 第一个疑惑
**为什么服务端会有TIME_WAIT状态?**
这其实是我的一个认知错误(也是下面这个图有歧义的地方,不知道你们有没有,如果有,请点赞👍)。
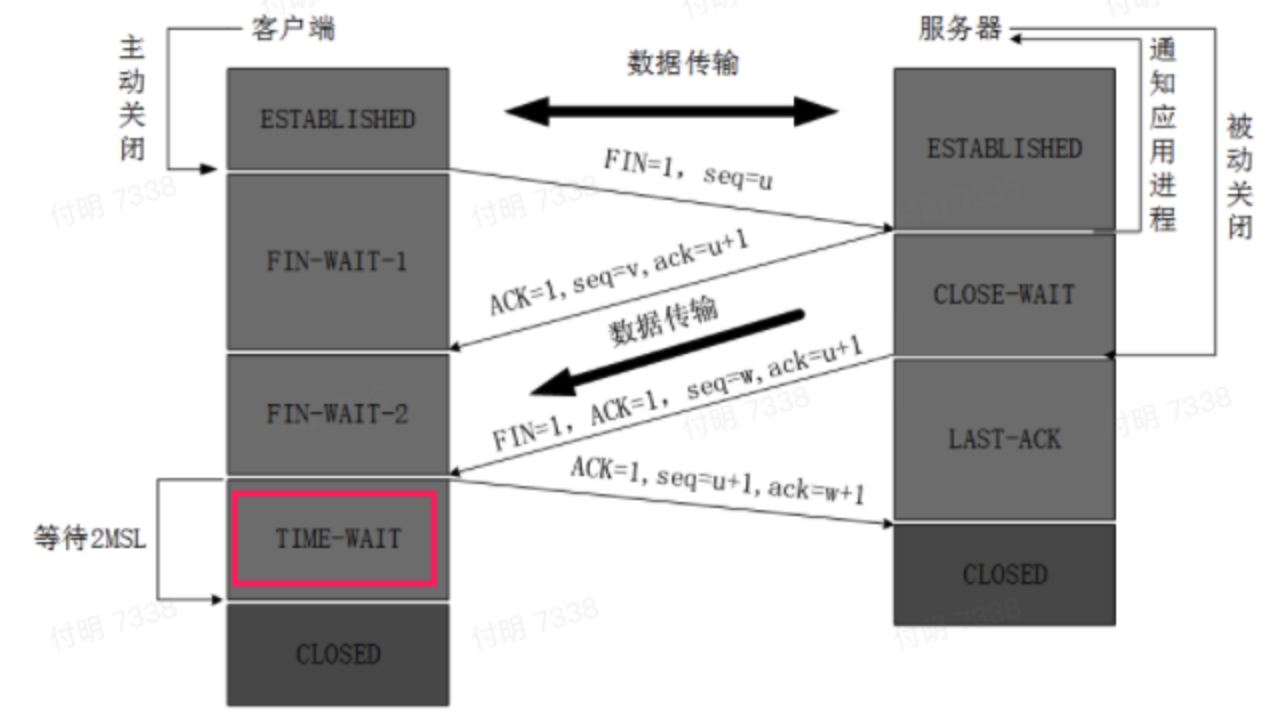
> **先说结论:**
- 一个链接,并不是只有客户端可以主动断开链接,服务端也可以
- 主动断开链接的一方,主动发起断开链接请求(FIN),就是对应上图左边这块(最上面写的是客户端,就是这个地方有歧义,其实服务端也可以)
> **本地实验下:**
客户端在建立连接之后,等待5秒之后关闭连接,服务端在接受到请求之后,立即调用`close`方法关闭链接。以此来模拟服务端主动关闭链接的场景。
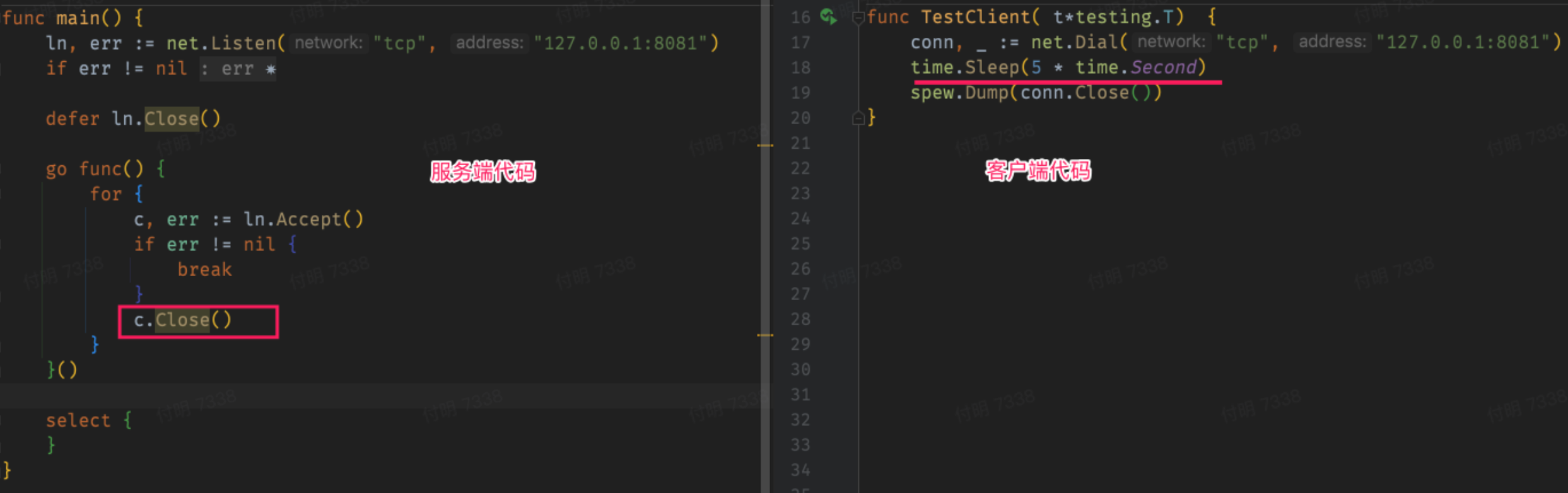
> **抓包看下:**
在5秒内,server发布fin,并且已经得到了client的ACK
- 服务端进入FIN_WAIT_2
- 客户端因为还没有CLOSE,状态是CLOSE_WAIT


5秒后,client close,服务端状态变成TIME_WAIT,客户端完全释放


> **小结:**
服务端主动断开链接确实会有TIME_WAIT状态,和线上现象一致。所以问题排查方向就改成为什么服务端会断开链接?
## 第二个疑惑
**为什么服务端要主动断开链接?**
这个问题问得好,看代码没有可疑的地方,一时间不知道如何排查了(此处掉了2根头发)。
但是有一个现象可疑是——**只有article-go服务会502,api-go服务不会。**
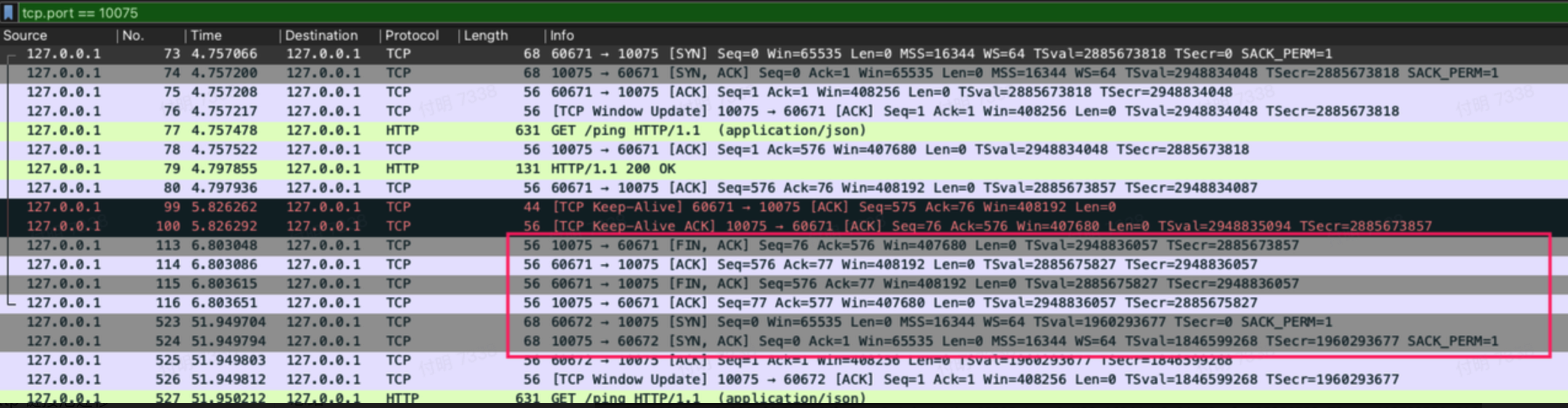
我本地分别启动了`api-go`服务和`article-go`服务,分别请求并抓包:
- Article-go response之后有一次`TCP Keep-Alive`,然后就close链接了
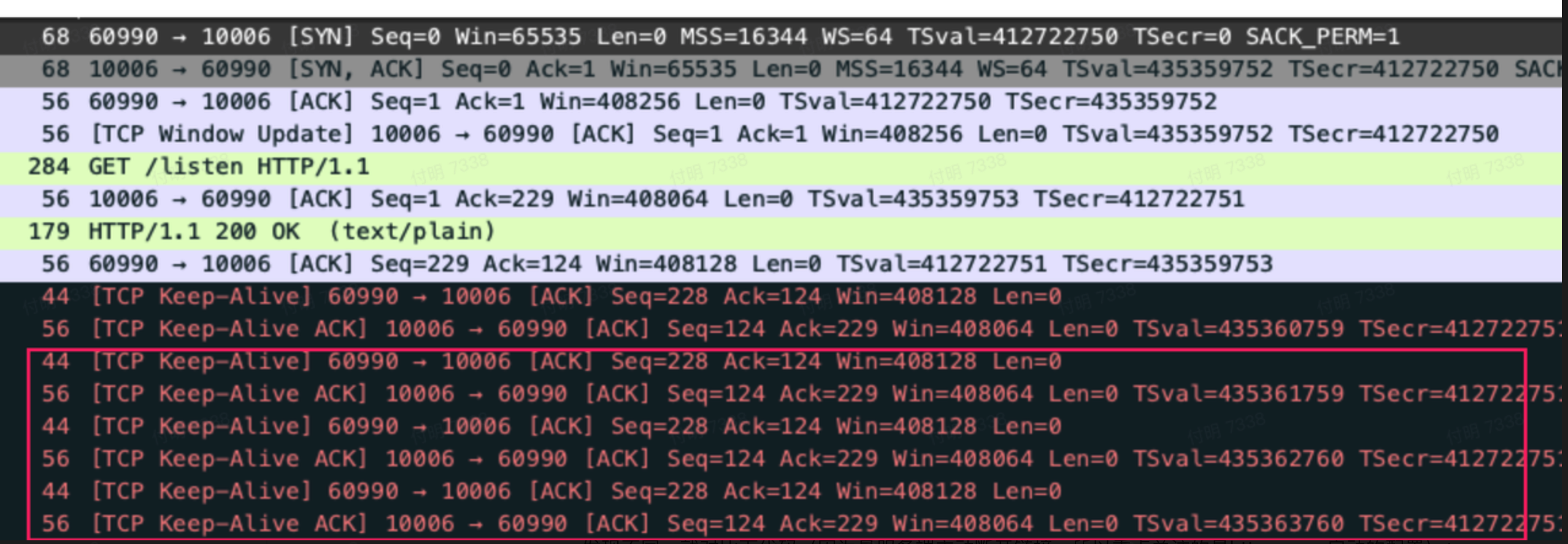
- Api-go response之后有很多次`TCP Keep-Alive`
发现不同,就对比下代码(因为是服务端主动断开链接,所以重点关注的是http server启动的配置):
Article_go的:
```
s := &http.Server{
Addr: addr,
Handler: engine,
ReadTimeout: 2 * time.Second,
MaxHeaderBytes: 1 << 20,
}
fmt.Println("Server listen on", addr)
err := s.ListenAndServe()
```
Api-go的:
```
s := &http.Server{
Addr: ":" + port,
Handler: router,
ReadTimeout: timeout * time.Second,
// WriteTimeout: timeout * time.Second,
MaxHeaderBytes: 1 << 20,
}
// graceful restart
err := gracehttp.Serve(s)
```
唯一的区别是`ReadTimeout`参数设置的不太一样,api-go设置的是10s,article-go是2s。三板斧第四招(😊),改下`ReadTimeout`参数试试,结果行了,请求之后会有多次`TCP Keep-Alive`了。
而且我发现(书读少了),`ReadTimeout`设置成几秒,`TCP Keep-Alive`就会有几次(每间隔1秒,一次`TCP Keep-Alive`)。
网上找了一个图,描述了ReadTimeout的计算范围。但是不太可能啊,这个过程不太可能会超过2s。
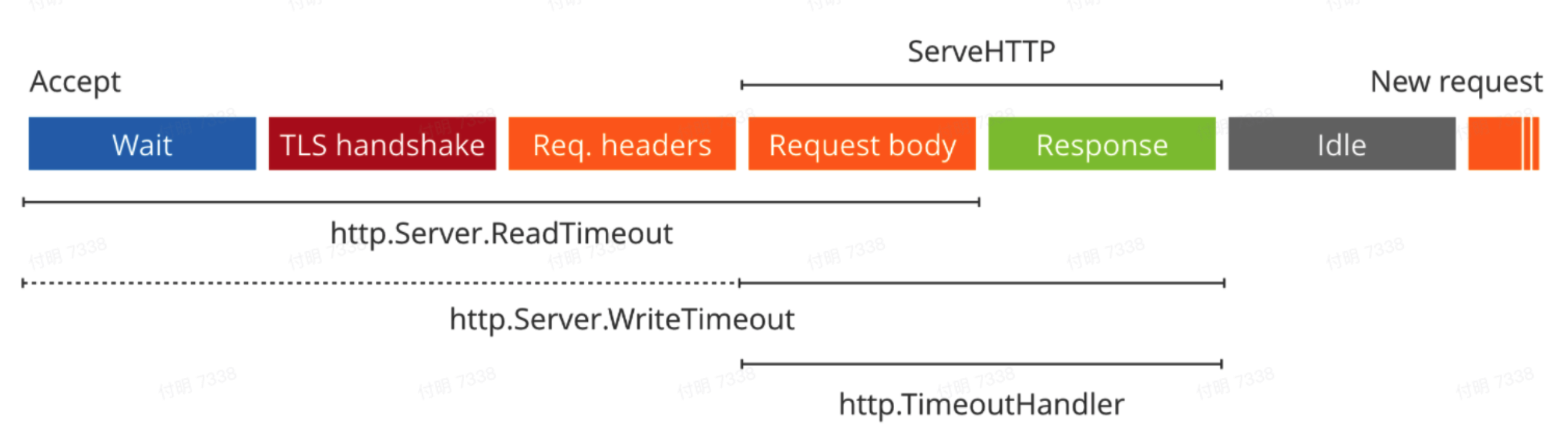
然后无意间看到这段段代码,原来go http server在没有设置`IdleTimeout`的情况下,会使用`ReadTimeout`作为`IdleTimeout`。
```
// net/conn/server.go
func (s *Server) idleTimeout() time.Duration {
if s.IdleTimeout != 0 {
return s.IdleTimeout
}
return s.ReadTimeout
}
```
终于,我,停.止.了.脱.发。。。
# 总结
> 问题总结
- 502现象是因为服务端主动关闭了链接,(正常情况下应该由客户端主动断开链接)
- 服务端主动断开链接,是因为设置了ReadTimeout,而net包把这个参数当成了IdleTimeout
- 一个链接在IdleTimeout时间内,就会一直Keep-Alive,超过这个时间,就会主动断开链接。另外一端如果没有没有及时释放,就会有问题。
> 改进代码
- 单独设置IdleTimeout,ingress设置的时间是300s,服务端设置IdleTimeout超过300s就行了。
- **个人**建议可以不用特别指定ReadTimeout、WriteTimeout和IdleTimeout的这些参数,默认值就是不限,然后让ingress来完全掌握链接的建立和关闭。安全问题,也是由ingress来控制
> 这次问题发现了自己很多认知错误
- 认知问题一:502现象多数是客户端和服务端设置的超时时间不一致导致的
认知不准确,超时时间是指什么?read超时?write超时? 其实链接的问题,主要是idle链接的问题。再直白点,就是idle链接的超时时间设置(对应nginx就是keepalive_timeout参数,对应go http就是idleTimeout参数)。此外服务端的WriteTimeout也会有影响。
- 认知问题二:链接断开一般都是客户端发起断开链接请求
一般情况下是这样,但是服务端也是可以主动断开链接的,重新学了下TCP4次挥手过程,有了深刻认识。
- 认知问题三:Http想要长链接需要再header里面加个connection: keep-alive
认知不准确,再http 1.0里面是需要显示的增加这个header头,但是在http 1.1里面这个header是默认值,可以不用加。
另外Connection: close这个header头在http 1.0里面是默认值(默认是短链接),在http 1.1里面需要手动增加该header头(通常用于服务端发布过程中,老服务响应时让客户端断开链接,然后和新服务建立连接)。
https://developer.mozilla.org/zh-CN/docs/Web/HTTP/Headers/Connection
> 如果再有502的问题,应该如何快速定位?
- 客户端和服务端的idleTimeout参数的设置是否匹配,原则是:客户端的idletimeout要比服务端设置的小。
- 直接看服务端的writeTimeout设置是否合理。
------
事后发现了一篇[文章](https://segmentfault.com/a/1190000023635278)总结的非常到位,推荐所有人都看下。
有疑问加站长微信联系(非本文作者))




