
大家好,我是Go学堂的渔夫子。今天跟大家聊聊结构体字段内存对齐相关的知识点。
原文链接:https://mp.weixin.qq.com/s/H3399AYE1MjaDRSllhaPrw
大家在写Go时有没有注意过,一个struct所占的空间不见得等于各个字段加起来的空间之和,甚至有时候把字段的顺序调整一下,struct的所占空间又有不同的结果。
本文就从cpu读取内存的角度来谈谈内存对齐的原理。
**01 结构体字段对齐示例**
我们先从一个示例开始。T1结构体,共有3个字段,类型分别为int8,int64,int32。所以变量t1所属的类型占用的空间应该是1+8+4=13字节。但运行程序后,实际上是24字节。和我们计算的13字节不一样啊。如果我们把该结构体的字段调整成T2那样,结果是16字节。但和13字节还是不一样。这是为什么呢?
```
type T1 struct {
f1 int8 // 1 byte
f2 int64 // 8 bytes
f3 int32 // 4 bytes
}
type T2 struct {
f1 int8 // 1 byte
f3 int32 // 4 bytes
f2 int64 // 8 bytes
}
func main() {
fmt.Println(runtime.GOARCH) // amd64
t1 := T1{}
fmt.Println(unsafe.Sizeof(t1)) // 24 bytes
t2 := T2{}
fmt.Println(unsafe.Sizeof(t2)) // 16 bytes
}
```
**02 CPU按字的方式从内存读取数据**
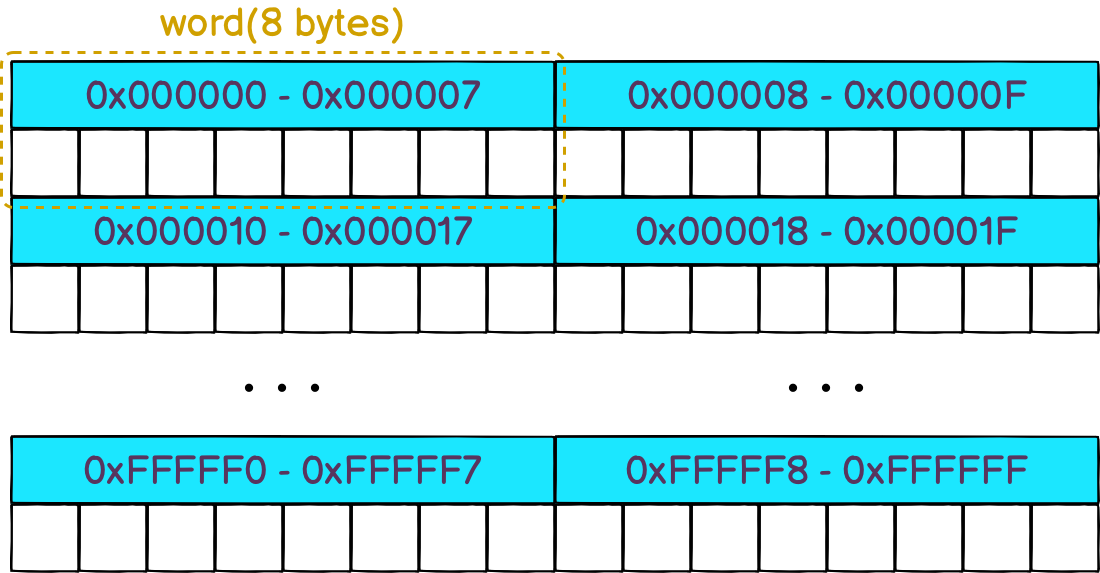
在买电脑时或看自己电脑的属性时,都会发现CPU的规格是64位或32位的,近些年的都是64位的。而这64位指的就是CPU一次可以从内存中读取64位的数据,即8个字节。这个长度也称为CPU的字长(注意这里和字节的区别,字节是固定的8位,而字长随着CPU的规格变化,32位的字长是4字节,64位的字长是8字节)。
虽然CPU一次可以抓取8字节,但也是想从哪里抓就从哪里抓取的。因为内存也会以8字节为单位分成一个一个的字(如下图),而CPU一次只能拿某一个字。所以,如果所需要读取的数据正好跨了两个字,那就得花两个CPU周期的时间去读取了。
**03 struct字段内存对齐**
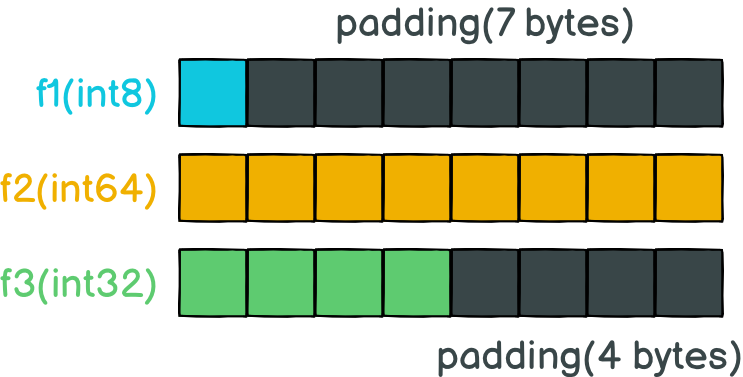
了解了CPU从内存读取数据是按块读取的之后,我们再来看看开头的T1结构体各字段在内存中如果紧密排列的话会是怎么样的。在T1结构体中各字段的顺序是按int8、int64、int32定义的,所以把各字段在内存中的布局应该形如下面这样:因为第2个字段需要8字节,所以会有一个字节的数据排列到第2个字中。

那这样排列会有什么问题呢?如果我们的程序想要读取t1.f2字段的数据,那CPU就得花两个时钟周期把f2字段从内存中读取出来,因为f2字段分散在两个字中。
所以,为了能让CPU可以更快的存取到各个字段,Go编译器会帮你把struct结构体做数据的对齐。**所谓的数据对齐,是指内存地址是所存储数据大小(按字节为单位)的整数倍,以便CPU可以一次将该数据从内存中读取出来。** 编译器通过在T1结构体的各个字段之间填充一些空白已达到对齐的目的。
重新排列后,内存的布局会长如下这样,有13个字节的空间是真正存储数据的,而深色的11个字节的空间则是为了对齐而填充上的,不存储任何数据,以确保每个字段的数据都会落到同一个字长里面,所以才会有了开头的13个字节的数据类型实际上变成了24字节。
**04 如何减少struct的填充**
虽然通过填充的方式可以提高CPU读写数据的效率,但这些填充的内存实际上是不存数任何数据的,也就相当于浪费掉了。以T1结构体为例,实际存储数据的只有13字节,但实际用了24字节,浪费了将近一半,那有没有什么办法既可以做到内存对齐提高CPU读取效率又能减少内存浪费的吗?
答案就是调整struct字段的顺序。我们再观察下T1结构体的字段分布,就会发现下面的f3字段的4个字节可以挪到f1字段所在的那一排的填充位置,毕竟第一排的填充空间超大,不用也是浪费,而且挪上去之后,每个字段还是都在同一个字里面。
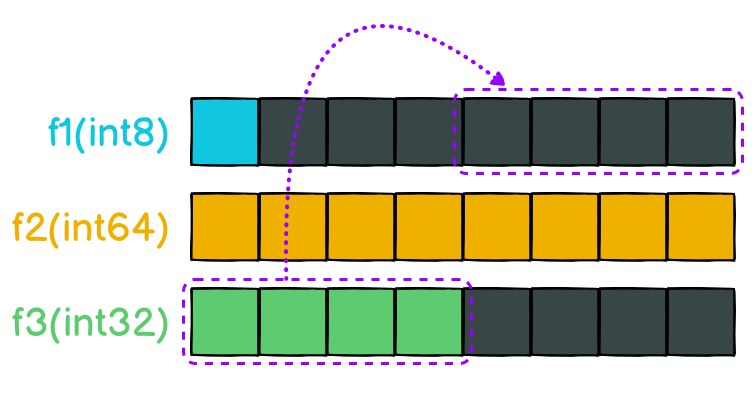
一旦把 f3 移上去,就可以省掉最下面一整個 word(8 bytes) 的空间,所以 T2 整个 struct 就只需要 16 bytes,是原本 T1 24 bytes 的三分之二。
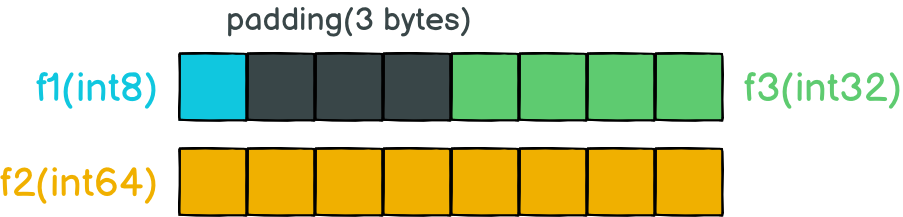
在Go程序中,Go会按照结构体中字段的顺序在内存中进行布局,所以需要将字段f2和f3的位置交换,定义的顺序变成int8、int32、int64,这样Go编译器才会顺利的按上图那样排列。
**05 在同一个字(8字节)中的内存分布**
上面都是看到的跨字长(64位系统下是8字节)的存储示例来说明CPU需要从内存读取两次才能将一个完整的数据完整的读取出来。那如果是有n个小于一个字长的类型在同一个字长中是否可以连续分配呢?我们通过示例来讲解一下:
```
var x struct {
a bool
b int16
}
```
我们计算一下各个字段占用的内存空间:1字节(a)+2字节(b)= 3字节。没超过1个字长(8字节),但在内存中的分布是如下图这样:
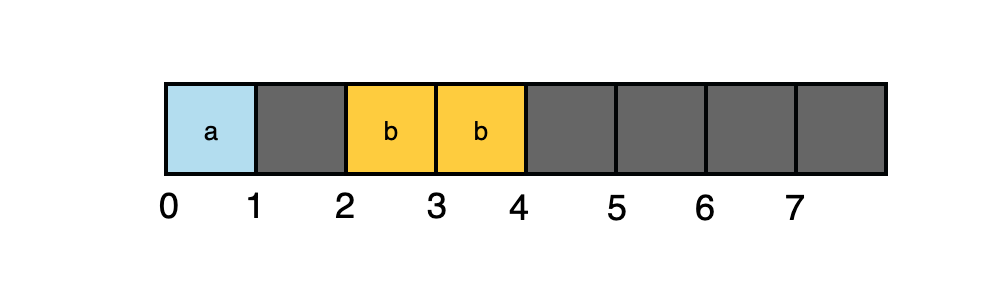
我们发现b并没有直接在a的后面,而是在a中填充了一个空白后,放到了偏移量为2的位置上。为什么呢?
答案还是从内存对齐的定义中推导出来。我们上面说过,内存对齐是指数据存放的地址是数据大小的整数倍。也就是说会有**数据存放的起始地址%数据的大小=0**
我们来验证下上面的结构体的排列。假设结构体的起始地址为0,那么a从0开始占用1个字节。b字段如果放在地址1处,套用上面的公式 1 % 2 = 1,就不满足对齐的要求。所以在地址为2处开始存放b字段。 这也就解释了很多文章中列出的原则:**构体变量中成员的偏移量必须是成员大小的整数倍**
**06 什么时候该关注结构体字段顺序**
由此可知,对结构体字段的重新排列会让结构体更节省内。但我们需要这么做吗?以Student为例,我们看下Student的定义:
```
type Student struct {
id int8 //学号
name string //姓名
classID int8 //班级
phone [10]byte //联系电话
address string // 地址
grade int32 //成绩
}
```
我们看下该结构体在内存中的分布如下,可以看到有很多深色的填充空间,总计浪费了16字节,好像还可以优化。
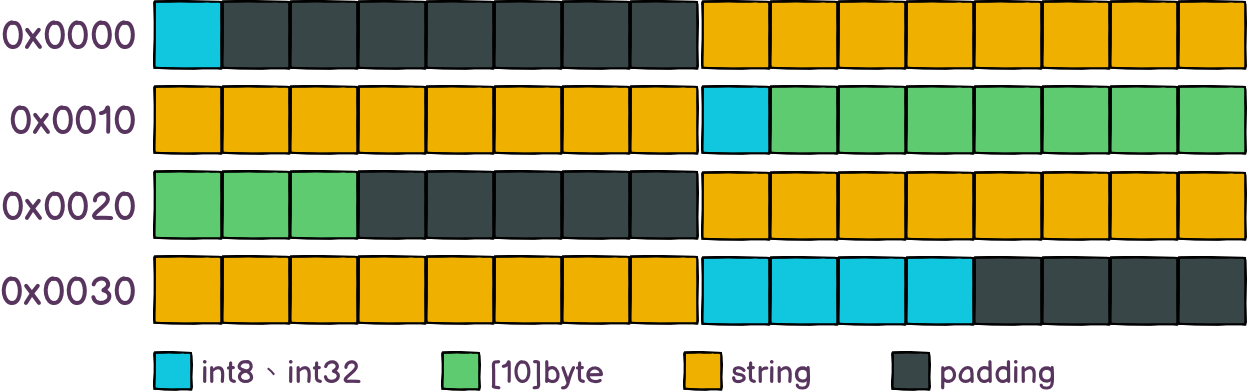
我们通过调整Student结构体的字段顺序来进行下优化,可以看到从开始的64字节,可以优化到48字节,共剩下了25%的空间。
```
type Student struct {
name string //姓名
address string // 地址
grade int32 //成绩
phone [10]byte //联系电话
id int8 //学号
classID int8 //班级
}
```
调整后的结构体在内存中的分布如下:
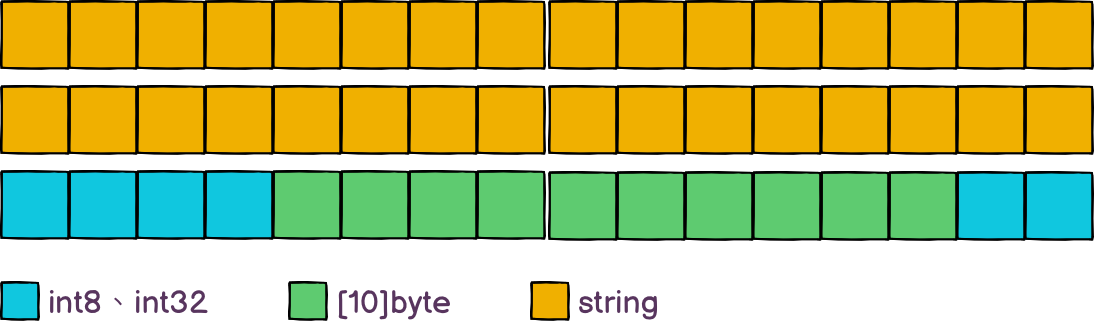
我们看到,通过调整结构体中的字段顺序确实节省了内存空间,那我们真的有必要这样节省空间吗?
以student结构体为例,经过重新排列后,节省了16字节的空间,假设我们在程序中需要排列全校同学的成绩,需要定义一个长度为10万的Student类型的数组,那剩下的内存也不过16MB的空间,跟现在个人电脑的8G到16G的内存比起来微不足道。而且在字段重新排列后,可读性也变的很差了。像Student原本是以学号,姓名,班级...这样依次排列的,而重新调整后变成了姓名,地址,成绩...,一直到最后才是学号跟班级,不符合人们的思维习惯。
所以,我的建议是对于结构体的字段排列不需要过早的进行优化,除非一开始就知道你的程序瓶颈就卡在这里。否则,就按照正常的习惯编写Go程序即可。
**07 总结**
本文从CPU读取内存的角度分析了为什么需要进行数据对齐。该文目的是为了让你更好的了解底层的运行机制,而非时刻关注结构体的字段顺序。在编写代码时顺其自然就好。到了这里成为瓶颈的时候再记着调整下字段顺序就好。
有疑问加站长微信联系(非本文作者))




