
GoBatch是一款用go语言实现的企业级批处理框架,其设计思想来源于SpringBatch,相当于golang下的SpringBatch框架。
项目仓库地址:
Github:
https://github.com/chararch/gobatch
Gitee:
https://gitee.com/chararch/gobatch
## 功能
GoBatch的主要功能包括:
1. 以模块化方式构建批处理应用程序。
1. 管理多个批处理任务的运行。
1. 任务被分为多个串行执行的步骤,一个步骤可以通过分区由多线程并行执行。
1. 自动记录任务执行状态,支持任务失败后断点续跑。
1. 内置文件读写组件,支持tsv、csv、json等格式的文件读写及校验。
1. 提供多种Listener,便于对任务和步骤进行扩展。
## 架构
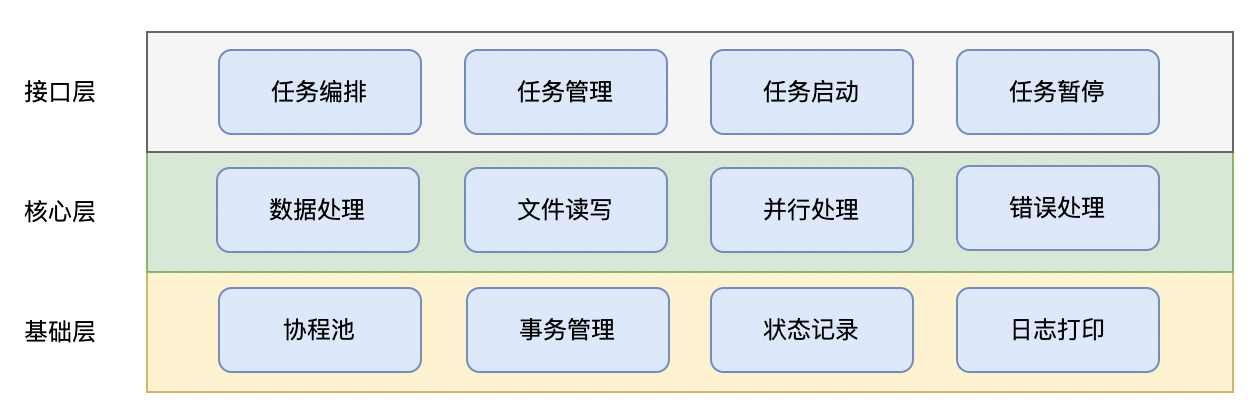
GoBatch整体架构分为三层:
1. 接口层:提供上层应用调用的接口,主要包括任务编排、任务管理、任务的启动和暂停。
1. 核心层:提供一套任务执行引擎,包括数据处理、文件读写、并行处理和错误处理等通用组件或能力。
1. 基础层:包括协程池、事务管理、任务执行状态记录、日志打印等
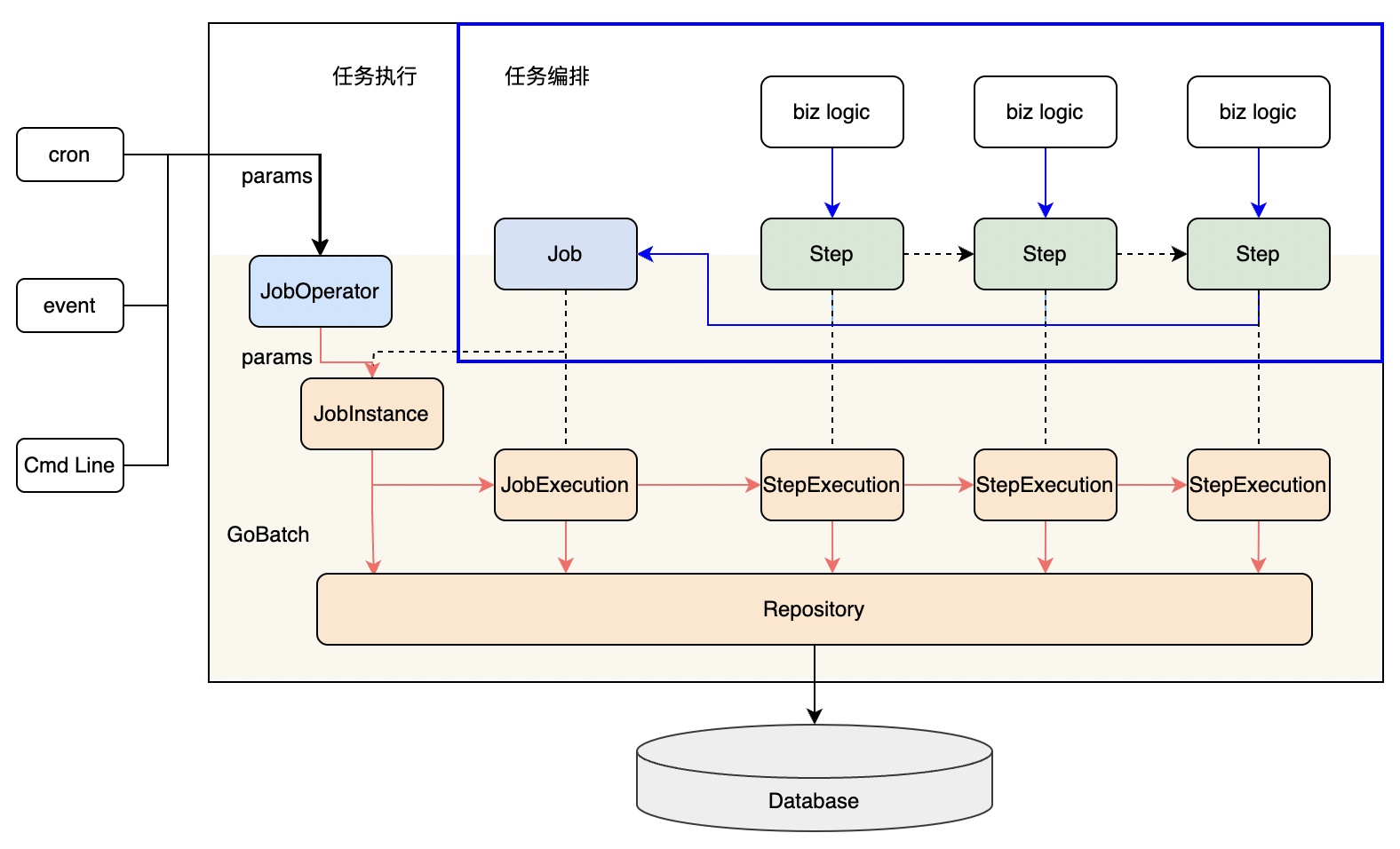
作为一款批处理框架,GoBatch的核心能力是任务编排和任务执行。应用程序需要首先通过GoBatch接口完成任务编排,才可以执行任务。
从任务结构编排上来说,一个任务(Job)由多个步骤(Step)构成,每个步骤包含一段业务逻辑,各步骤按照先后顺序依次执行。
任务编排即是将不同的业务逻辑构造成多个步骤(Step)并按照一定顺序组装成任务(Job),交由GoBatch运行时管理。作为批处理框架,GoBatch可以管理多个任务。
任务执行时,应用程序可以传递参数给指定任务,GoBatch根据传入的任务参数生成一个任务实例(JobInstance)。一个任务实例可能会被多次执行,每次执行时,GoBatch会创建一条任务执行记录(JobExecution)用于记录任务的执行状态信息。
同理,每个Step的运行也会生成一条步骤执行记录(StepExecution)。GoBatch会将任务实例(JobInstance)、任务执行记录(JobExecution)、步骤执行记录(StepExecution)通过Repository存储到数据库中。
GoBatch没有限定任务执行的触发方式,应用程序既可以通过定时任务、也可以通过实时事件、还可以通过命令行触发任务的执行。
GoBatch批处理应用的执行流程如下:
## 核心设计
### 任务模型
1. 一个任务(Job)由多个步骤(Step)构成,Step包含业务逻辑
1. 任务带有*参数*、参数是一个KV map,不同的参数代表不同的*任务实例(JobInstance)*,在任务的步骤中可以获取参数值
1. 每个任务实例都会从头执行所有的任务步骤,如果执行失败,可以从断点继续执行
1. 任务的每次执行对应一个执行记录(JobExecution),Step每次执行也对应一个执行记录(StepExecution)
1. 在执行记录中会记录任务和步骤的开始、结束时间、状态,其中步骤执行记录中会记录该步骤处理的数据范围以及游标,以便在中断时从断点继续执行
### Step分类
步骤(Step)分为三类:
- *简单步骤(Simple Step)* :在单线程中执行用户编写的业务逻辑。
- *分块步骤(Chunk Step)* :在单线程中分块处理大量的数据。分块步骤包含Reader、Processor、Writer 3个用户自定义组件,执行顺序是按指定分块大小读取源数据、处理数据、写入结果数据,分片处理逻辑在一个事务中,重复执行该流程直到源数据读取完毕。
- *分区步骤(Partition Step)* :将要处理的数据划分为多个分区,每个分区由一个单独的线程(子步骤)分别处理,最后将各个分区的处理结果进行聚合。Partitioner和Aggregator由用户自定义,处理每个分区的子步骤可以是简单步骤或分块步骤。
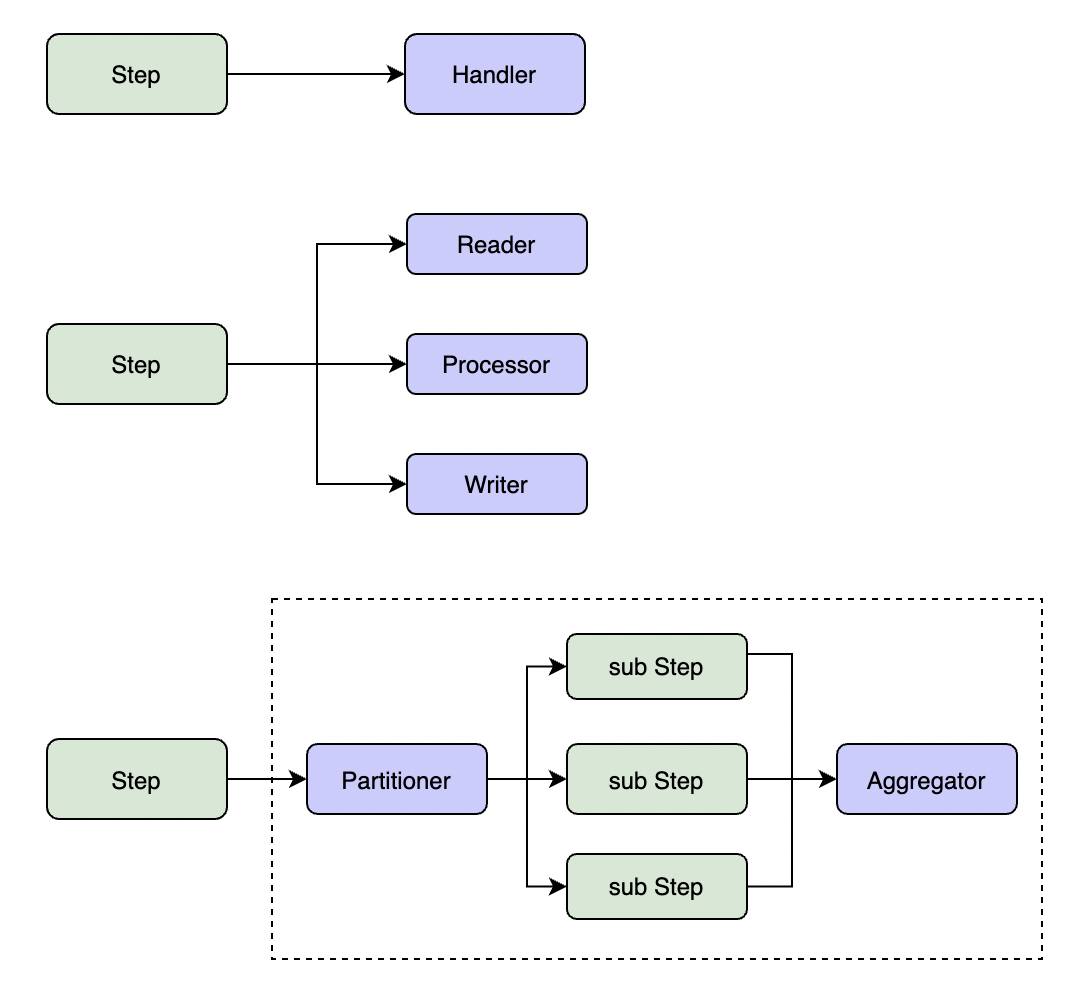
上图中的Handler、Reader、Processor、Writer、Partitioner、Aggregator是接口类型,需要应用程序自己实现。
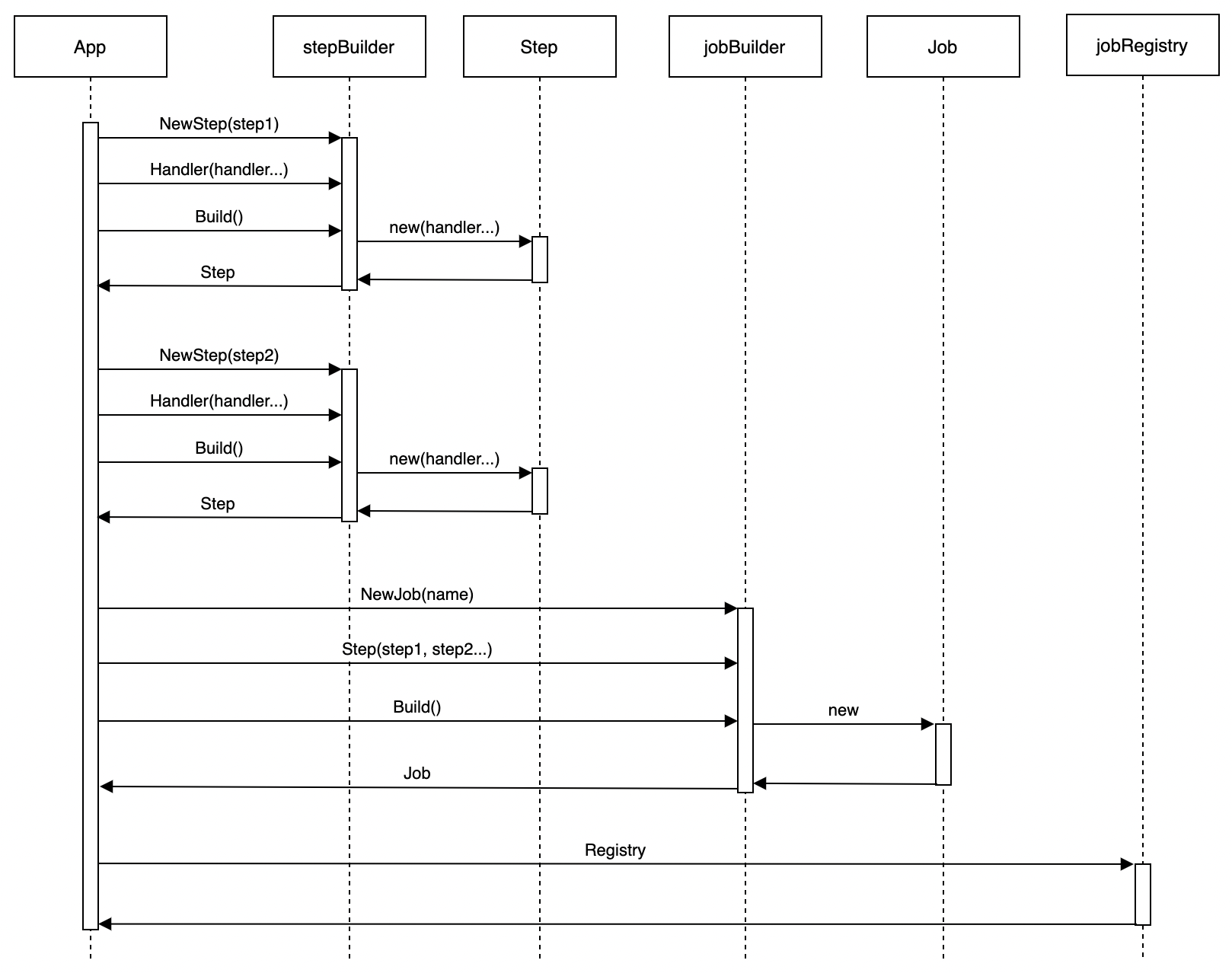
### 任务编排
任务编排主要由stepBuilder和jobBuilder两个对象来完成,应用程序先将不同的业务逻辑handler通过stepBuilder生成Step对象,再将Step对象传给jobBuilder生成Job。
如下图:
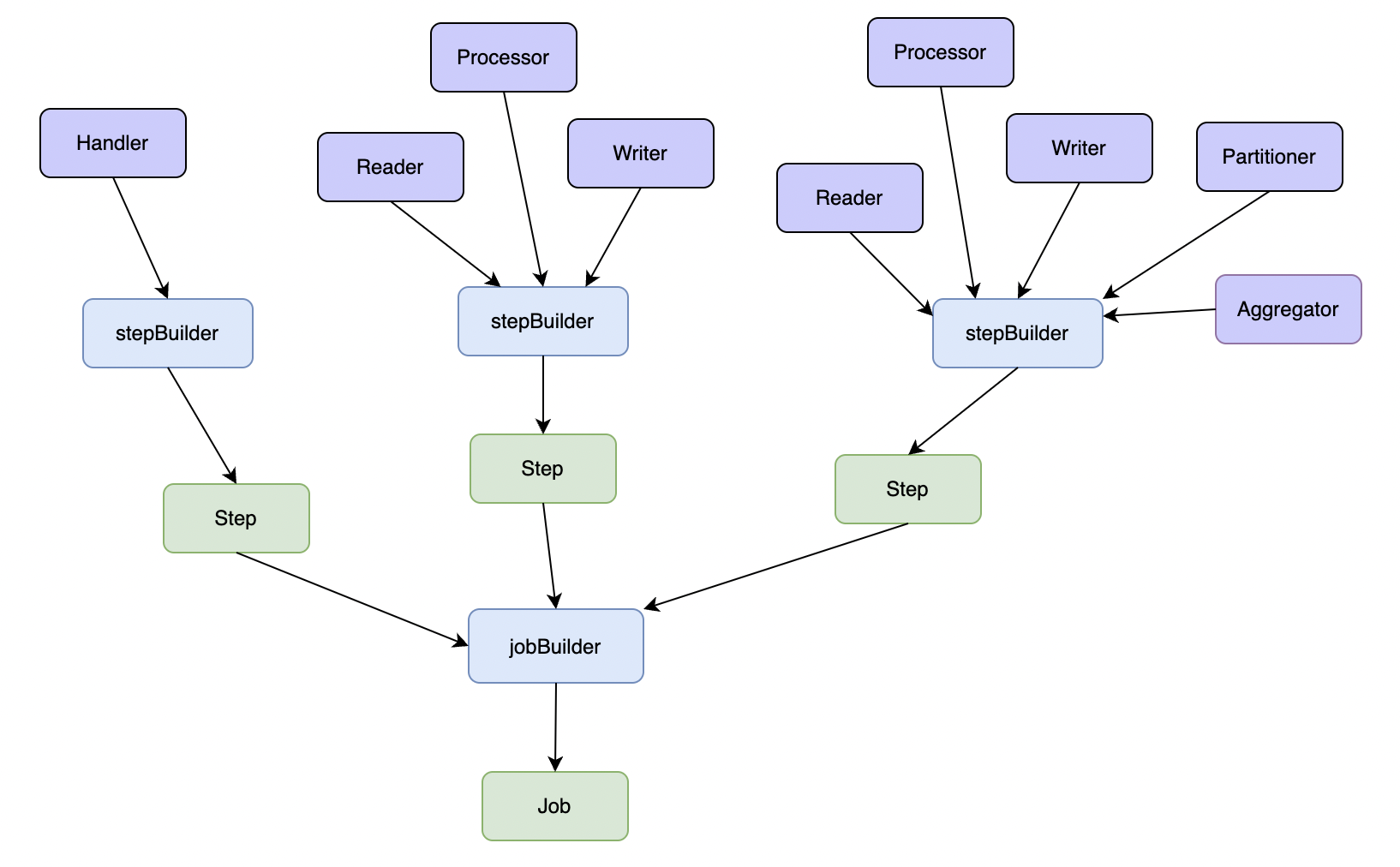
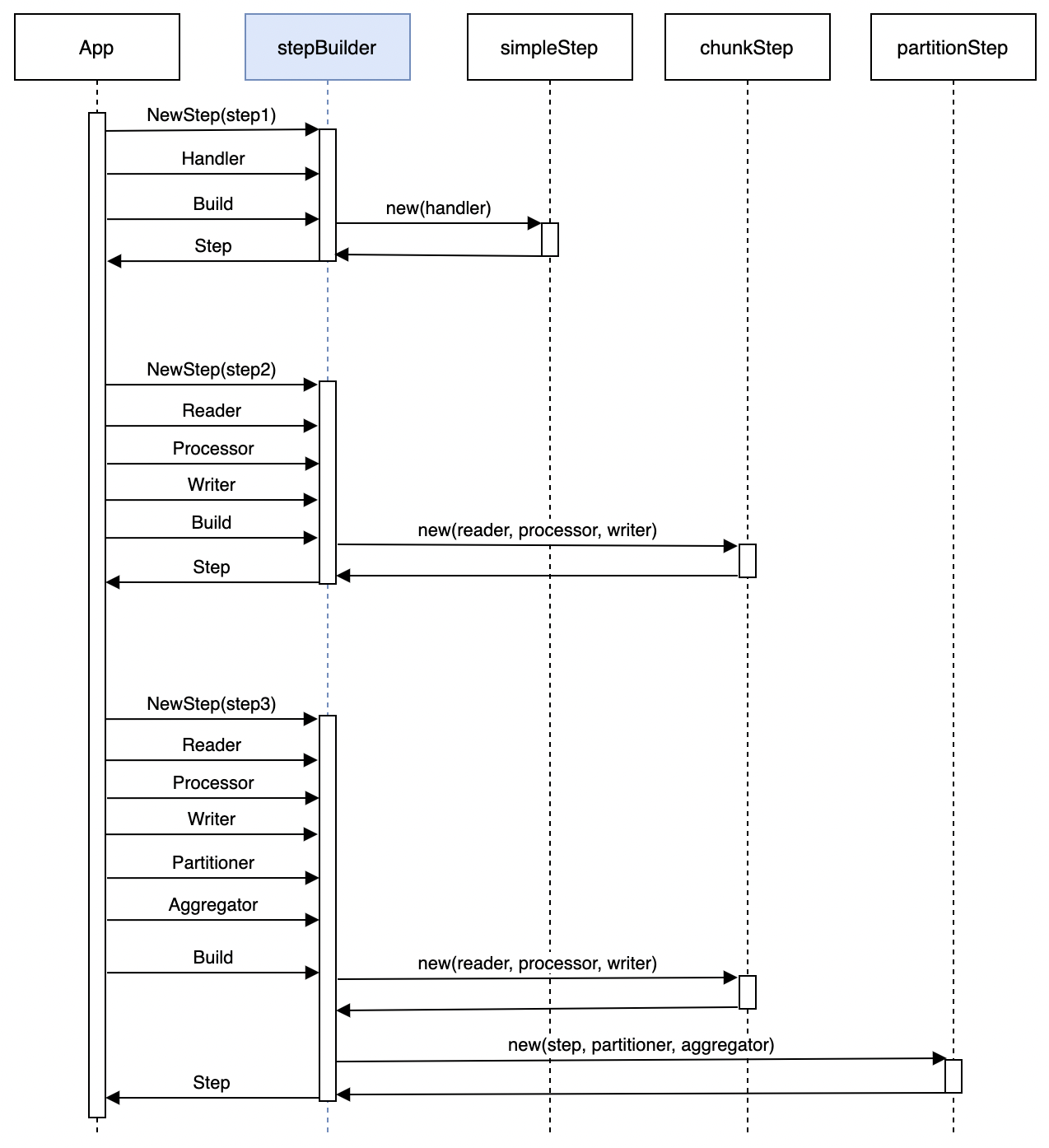
在构造Step对象时,stepBuilder会根据传入的handler类型选择合适的Step类型:
1. 如果传入了普通Handler,则会生成simpleStep。
1. 如果传入了Reader对象(以及可选的Processor和Writer),则会生成chunkStep。
1. 在满足前两个条件之一时,如果还传入了Partitioner对象,则会生成partitionStep。
stepBuilder的执行流程如下:
任务编排的整体流程如下:
### 任务执行
应用层可以根据定时任务、外部请求/事件、命令行等触发GoBatch任务的执行。应用程序通过调用jobOperator的Start()/StartAsync()方法启动任务的执行,在启动任务时,需要指定任务名称并传递参数。
1. StartAsync()方法为异步执行任务,调用该方法后,会启动一个goroutine用于执行任务并立即返回。
1. Start()方法为同步执行任务,调用该方法后,会一直阻塞直到整个任务的所有步骤执行完毕才返回。
同步执行任务的流程图如下:
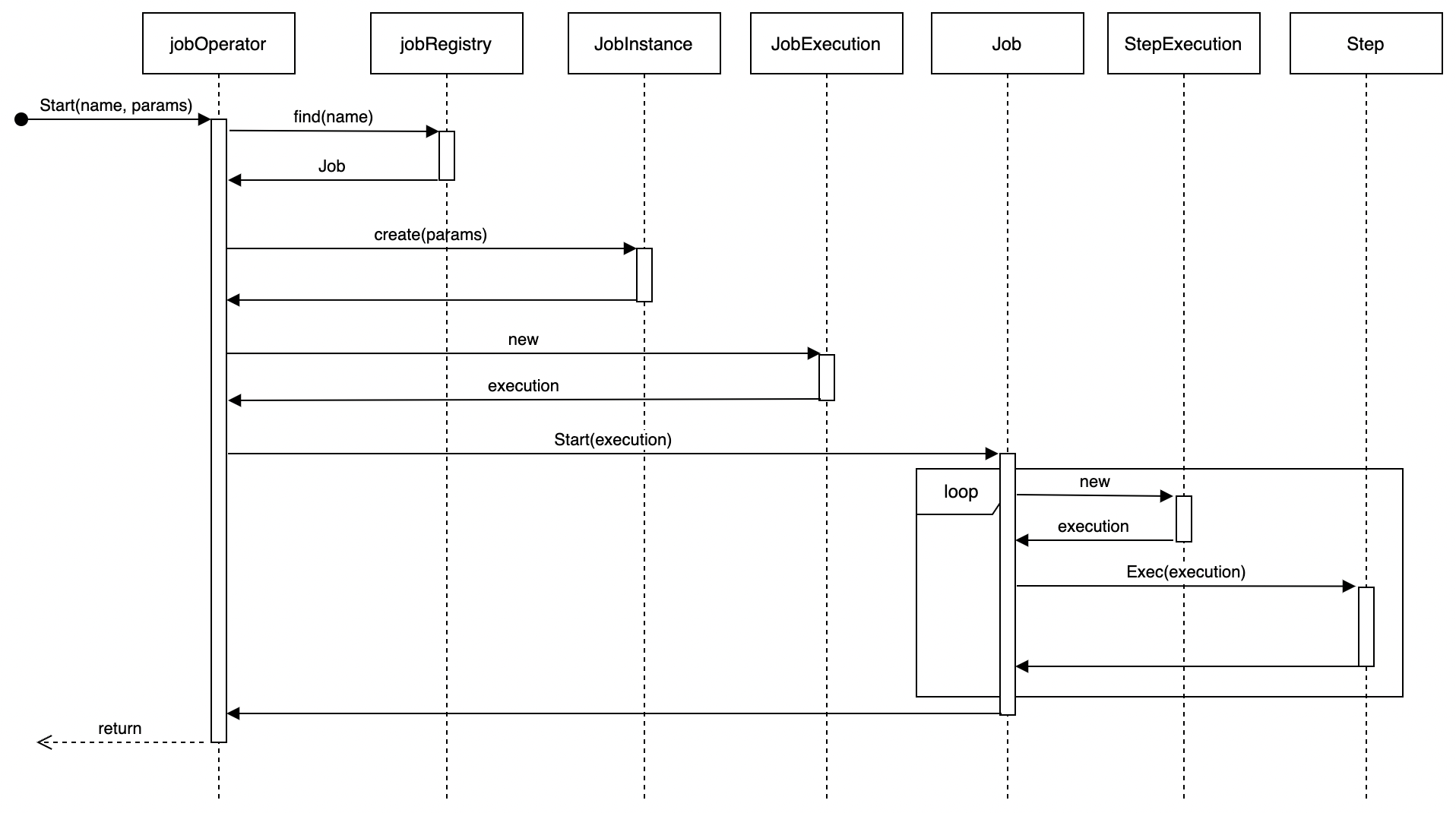
从流程图中可以看出,Job的执行就是遍历所有的Step并执行Step中的业务逻辑。Step有三种类型,每种类型Step的执行流程有一定区别,我们可以根据业务需要使用不同Step类型。
#### 简单步骤的执行
简单步骤直接在当前Job的线程中执行Handler中的业务逻辑,Handler中的业务逻辑应当是原子性的或具有幂等性。执行流程如下:
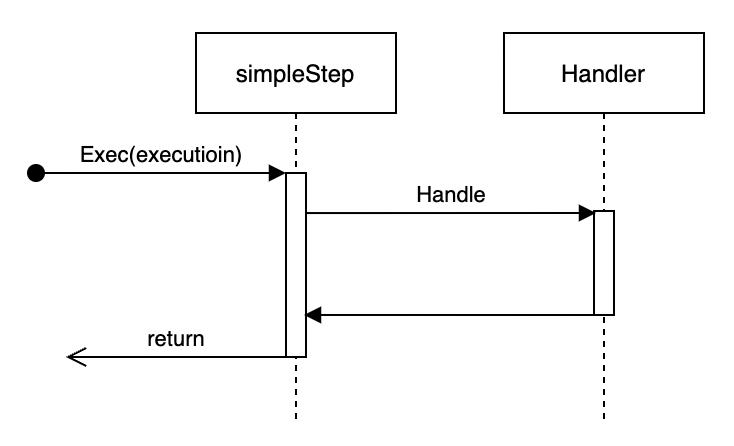
从名称可知,简单步骤适合于业务逻辑比较简单的场景。
#### 分块步骤的执行
分块步骤也是在当前任务的线程中执行(单线程),它的执行流程是:
1. 通过事务管理器启动一个事务。
1. 从Reader中读取分块大小数量的数据项(分块大小在构造Step时通过chunkSize参数指定)。
1. 调用Processor逐条处理从Reader中读取到的数据项,得到处理后的新数据项。
1. 调用Writer将Processor返回的数据项写入到底层存储。
1. 如果2~3步执行成功,则提交事务;否则回滚事务。
1. 如果前述事务提交成功,则重复执行1~5步,直到Reader返回空(nil)或事务失败。
流程图如下:
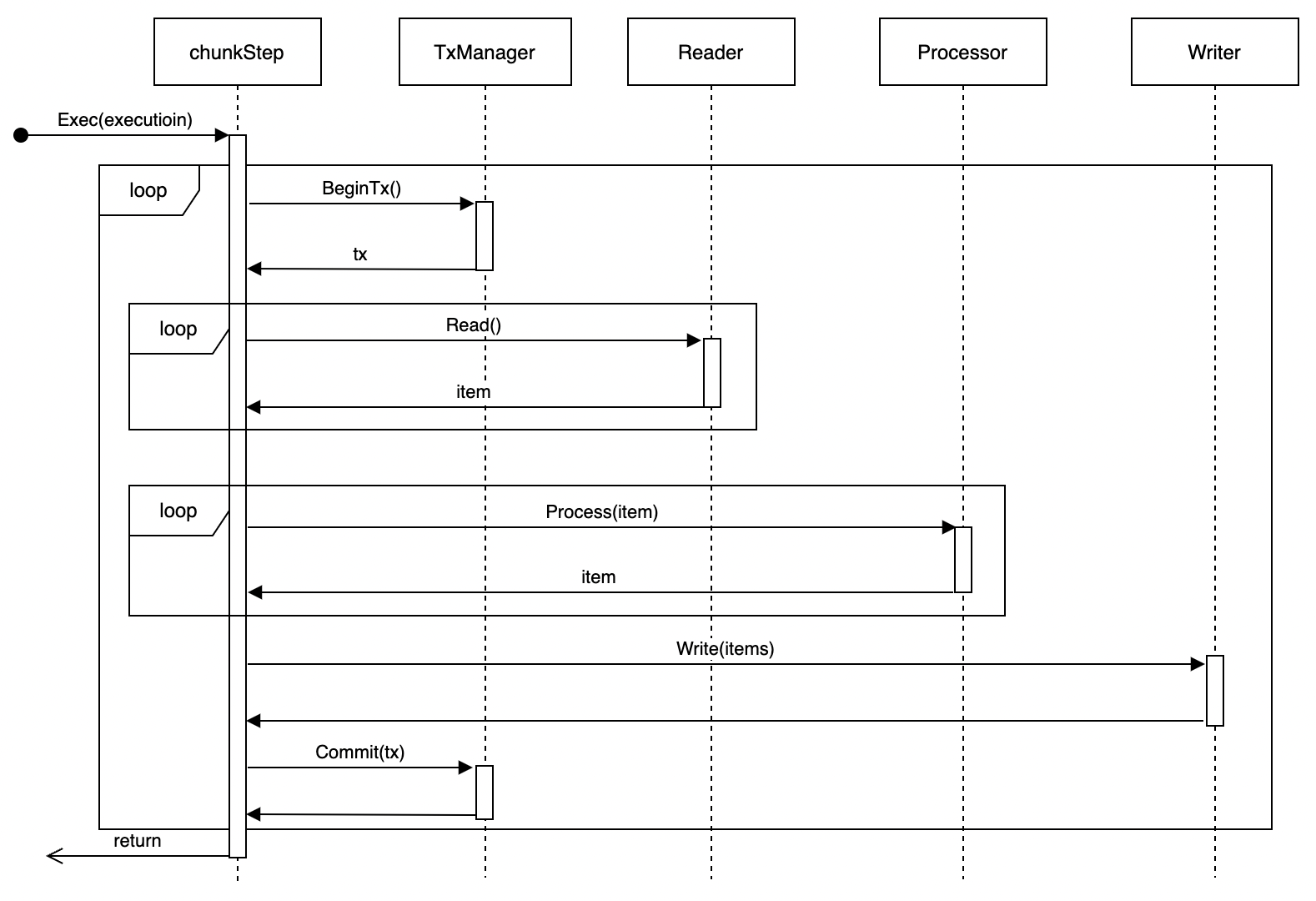
分块步骤适合用于处理大批量数据、但需要串行执行的场景,或者是数据量较大、计算资源有限、但对处理时限要求不高的场景。
#### 分区步骤的执行
分区步骤的执行流程是:
1. 调用Partitioner对该步骤需要处理的全部数据进行分区,生成子步骤的StepExecution实例列表,分区信息存储在返回的StepExecution中。
1. 对Partitioner生成的分区StepExecution列表,逐个生成子步骤task并提交到taskpool执行。
1. taskpool并行执行所有子步骤。
1. 等待所有子步骤执行完成。
1. 调用Aggregator对子步骤结果进行聚合。
流程图如下:
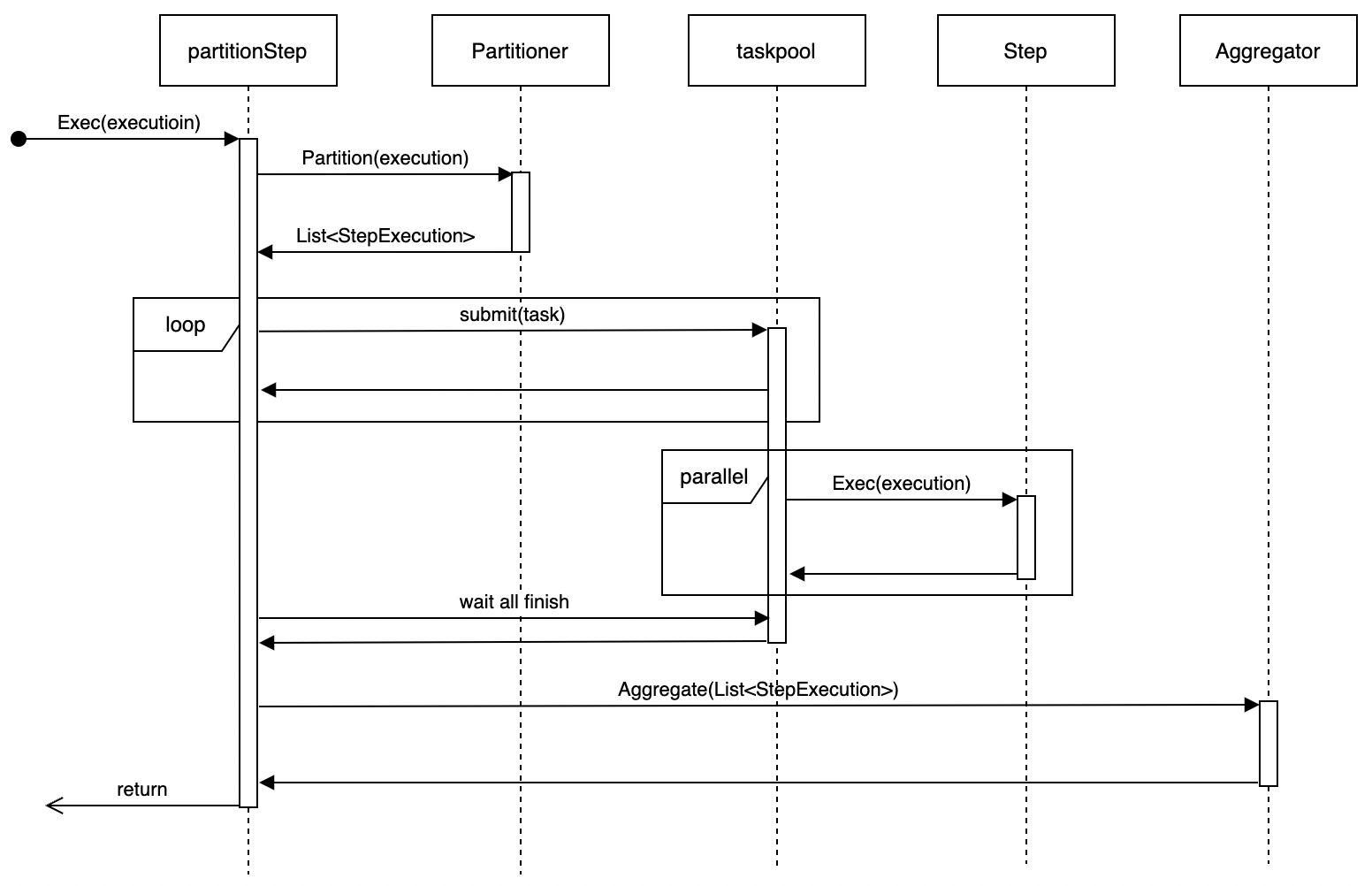
分区步骤适合用于处理大批量数据、计算资源比较充足的场景。
### 执行状态记录
GoBatch通过以下4个对象记录批量任务的运行时的状态信息:
* JobInstance - 对应某个Job的某一组不同的参数,使用相同的参数启动任务,只会对应同一个JobInstance
* JobExecution - 对应某个JobInstance的一次执行,如果中途暂停或失败之后重启,则会生成一个新的JobExecution
* StepContext - 对应某个JobInstance下某个Step的上下文信息,该上下文只和JobInstance和step_name有关,与Job或Step的执行次数无关。
* StepExecution - 对应某个JobExecution下某个Step的一次执行,如果中途暂停或失败之后重启,则会生成一个新的StepExecution
这4个对象对应数据库里的4张表,主要的字段及相互关系如下图:
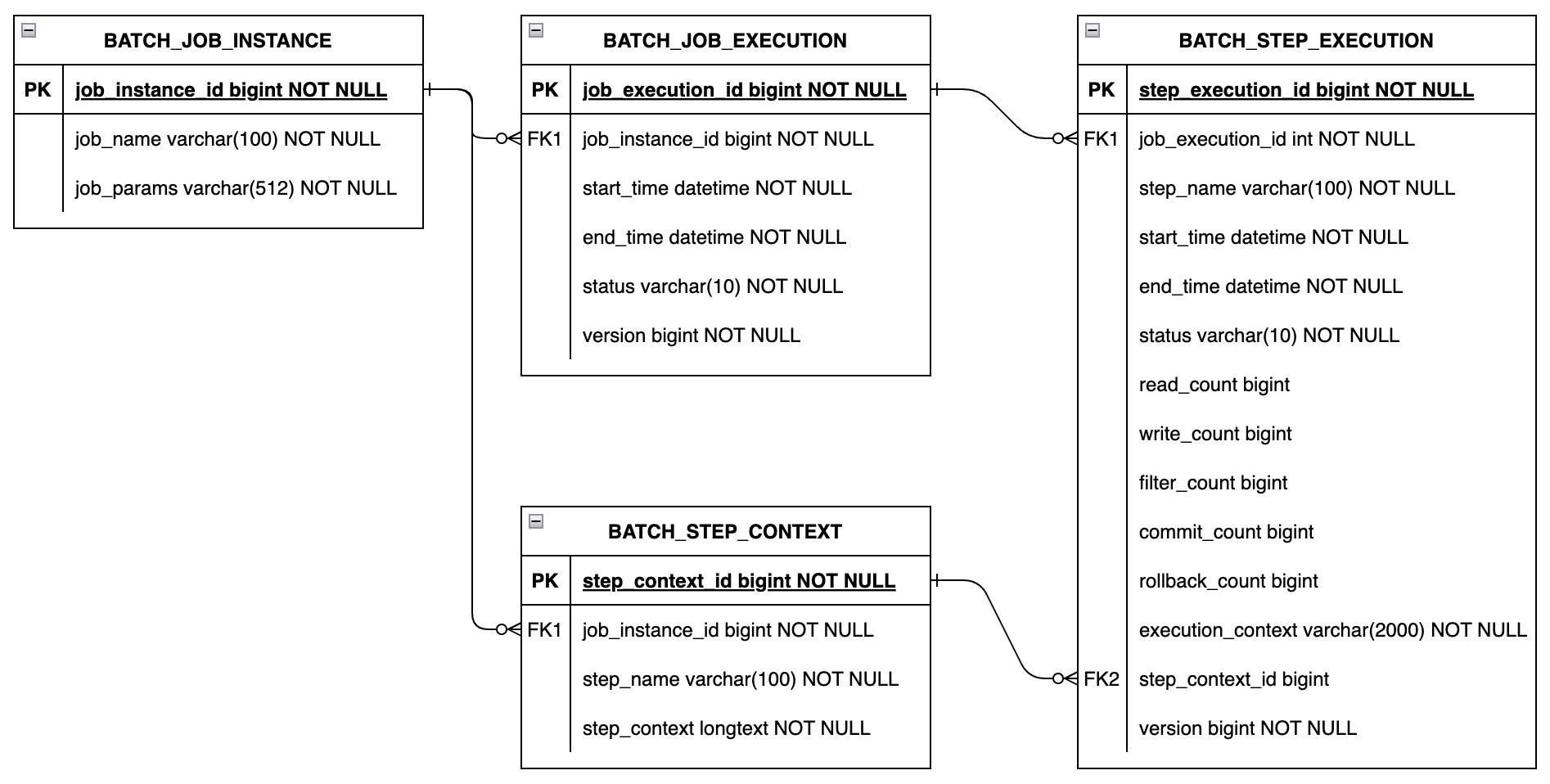
具体的表结构,可以查看:https://github.com/chararch/gobatch/blob/master/sql/schema_mysql.sql
JobExecution和StepExecution中包含Job和Step的运行开始和结束时间、状态等信息。对于chunkStep,在StepExecution里面会记录已经Read、Process、Write的数据量,已提交或回滚的chunk次数等。
Job和Step的执行状态有:
* STARTING: Job或Step提交到协程池等待执行
* STARTED: Job或Step正在执行
* STOPPING: Job或Step正在停止(已收到停止指令)
* STOPPED: Job或Step已停止
* COMPLETED: Job或Step已成功完成
* FAILED: Job或Step已执行失败
* UNKNOWN: 未知状态(目前未使用)
状态转移如下:
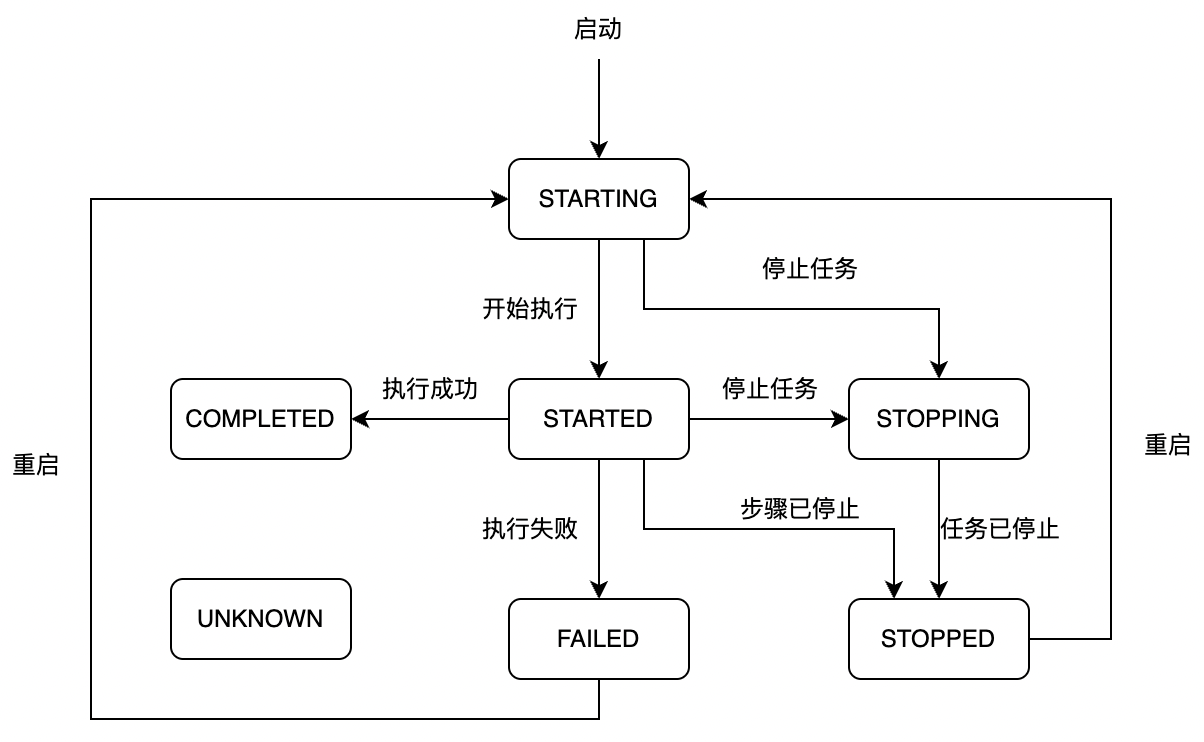
通过记录Job和Step的执行状态,GoBatch可以实现断点续跑功能。试想,当我们在运行一个处理大数据量、耗时很长的任务时,中途由于某些原因(如进程crash、部分数据不规整造成程序出错等)导致失败,
在我们解决问题后,如果从头开始运行势必会花费很长时间、甚至会造成重复处理。这时我们可能希望从中断位置继续处理剩余数据,GoBatch能够很好地满足这一诉求。
### 并行处理
GoBatch可以管理多个Job,每个Job又包含一个或多个Step,在Job和Step层级都可以并行执行。GoBatch在内部维护了两个协程池(大小可配置):一个用于Job的执行,一个用于Step(专指partitionStep)的执行。
### 事务管理
在执行分块步骤(chunkStep)时,对每个分块内一小批数据的处理需要处在一个事务之中,GoBatch引入了一个事务管理器组件,其接口定义如下:
```go
type TransactionManager interface {
BeginTx() (tx interface{}, err BatchError)
Commit(tx interface{}) BatchError
Rollback(tx interface{}) BatchError
}
```
这个事务管理器需要使用方根据自身的基础设施自行实现并注册到GoBatch。为简便起见,GoBatch提供了一个基于*sql.DB的默认事务管理器实现,如果使用方是采用关系数据库来进行数据处理,可以直接使用默认的事务管理器,如下:
```go
gobatch.SetTransactionManager(gobatch.NewTransactionManager(sqlDb))
```
## 三方依赖
1. GoBatch运行时需要将任务执行状态信息存储到关系数据库,因此依赖database/sql及数据库驱动github.com/go-sql-driver/mysql
1. 协程池使用了github.com/panjf2000/ants/v2
1. 错误处理使用了github.com/pkg/errors
1. FTP文件处理使用了github.com/jlaffaye/ftp
## 使用
1. 获取包
```go
go get -u github.com/chararch/gobatch
```
2. 创建gobatch数据库和批量任务执行状态表
```
create database xxx;
//create table from https://github.com/chararch/gobatch/blob/master/sql/schema_mysql.sql
```
3. 初始化数据库连接并注册*sql.DB到GoBatch:
```go
db, _ := sql.Open("mysql", "user:pswd@tcp(localhost:3306)/xxx?charset=utf8&parseTime=true")
gobatch.SetDB(db)
```
4. 如果使用chunkStep,还需要注册事务管理器:
```go
gobatch.SetTransactionManager(gobatch.NewTransactionManager(sqlDb))
```
5. 编写业务逻辑,实现Handler、Reader、Processor、Writer等接口。示例可以参考:https://github.com/chararch/gobatch/
6. 构造Step和Job,注册到GoBatch
```go
step1 := gobatch.NewStep("mytask").Handler(mytask).Build()
//step2 := gobatch.NewStep("my_step").Handler(&myReader{}, &myProcessor{}, &myWriter{}).Build()
step2 := gobatch.NewStep("my_step").Reader(&myReader{}).Processor(&myProcessor{}).Writer(&myWriter{}).ChunkSize(10).Build()
job := gobatch.NewJob("my_job").Step(step1, step2).Build()
gobatch.Register(job)
```
7. 启动任务
```go
gobatch.Start(context.Background(), "my_job", "{\"k\":\"v\"}")
//gobatch.StartAsync(context.Background(), "my_job", "{\"k\":\"v\"}")
```
更多信息和示例代码,可以参见:https://github.com/chararch/gobatch
## 小结
本文对批处理框架GoBatch的功能、架构、设计和使用方法,做了一个简要介绍。GoBatch适合用于开发业务逻辑比较复杂的企业级批处理应用,例如金融等领域,也可用于企业在从Java向Go转型时替换SpringBatch的框架。
作为开源项目,GoBatch目前还处于比较早期的阶段,未来致力于将GoBatch打造成golang下的企业级批处理解决方案,后续会有更多相关内容介绍。
## 问题反馈
https://github.com/chararch/gobatch/issues/new
有疑问加站长微信联系(非本文作者))




