

UGeek大咖说是优维科技为技术爱好者研讨云原生技术演进趋势而创办的系列活动,邀请一线互联网大厂的核心骨干主讲,分享原厂实践。本年度主题为可观测,我们希望通过一场场有趣、有料、有深度的活动,让运维圈的小伙伴聚集在一起,深度交流与学习。
#深入探索浙江移动监控体系升级历程
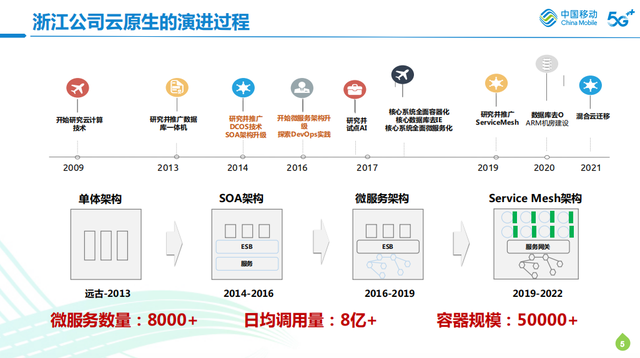
蒋老师带领大家深入了解了浙江移动云生原生的演进过程,以及监控体系的升级历程,让我们认识了浙江移动是如何从数据分散在各专业组独立监控一个初始状态,一步步演进到引入智能化场景,构建起全景融合式的关键能力。
# 传统监控到可观测的转变
2018年,为了配合云原生的演进,提出了可观测的概念。我们发现从监控到可观测,它的背后的逻辑是基于整个行业做数字化转型的时候探索出来的思路。
转型过程中发现,云原生其实就是驱动转型的利器。但是在整个系统做云原生升级改造的情况下,浙江移动面临的问题对运维团队来说是极其复杂的依赖架构,超大型部署量的级别对数据观测体系是一个很大的挑战,在这个过程中也可以发现传统的IT监控,其实是以系统的可用性为核心的,随着整个数字化升级,观测的重点转移到了以业务或者服务/用户为核心,而可观测性最关键目标其实就是服务跟用户体验。

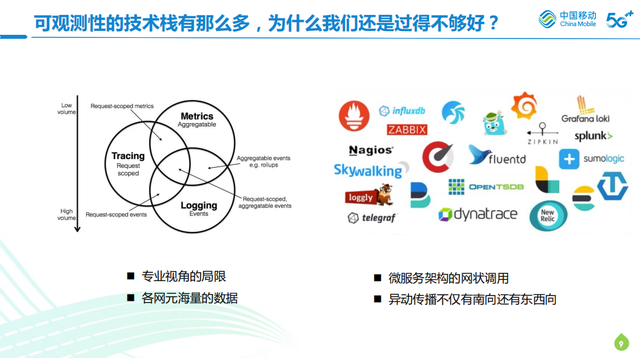
# 用了可观测为何还是过得不够好?
因为多数数据无法让我们获得更有价值的东西,这是大部分企业都会遇到的问题。比如:专业视角的局限,比如在分层组织形式下,每个组织条件虽然用各类技术站去获得了很多的观测数据,但可能不会对对象去做很大的延伸。
比如做pass维护,我可能不会管底层,只会管到组件的可用性,不会去关联底层存储的信息,而是向上去关注这个组件出问题会影响哪些业务和应用。所以一旦碰到问题的情况,更多的反而是应用先改造问题。这样的话,我们对整个数据其实没有做更多的关联,于是便增加了很多其他的问题。
# 在线问答
在优维科技UGeek大咖说微信视频号直播过程中,我们的评论区出现了很多来自同学们的提问,小编已将问答部分整理成文字版,以方便大家阅读学习。
Q:移动的监控体系在升级过程中遇到最难的事情是什么?如何解决的?
A:我们在整个升级过程中碰到最难的问题是:数据融合的拉通信息意识统一。组织上的一些隔离会影响整个观测体系数据的融合融通,所以我们第一步要做到的是在整个部门/层面做到意识上的宣导,把数据共享的氛围开放起来,要不然我们在做观测工具的时候,我们不可能去把每个都做一遍,因为本来就是现成的东西,也没有这么大的人力跟成本,那么还是会依赖于原有的团队的关注数据去做一个综合性的分析。而原有团队的拉通意识是较难解决的问题。
Q:如何做好业务的稳定性、健康巡检、监控,需要包含哪些维度、指标?它是怎么样呈现的?
A:我们原先在做端到端业务监控的尝试时就对核心业务做了链路的梳理,包括经验、调用链。三个业务从前往后,每个应用和组件在上一层去把组建的依赖的关系构建起来,然后再往下去把数据的过程串联起来,比如说他经历了哪些进程,在这个过程中去建立每个节点的业务关键监控,但是在做整个业务的监控前,实际的路径的梳理上还有更多监控指标的分层。我们对每个业务去做一个分层的的指标拆解,比如说我们移动很多核心的用户要开卡,需要激活或更换套餐这样的核心业务,每个核心业务设计一个顶层指标,比如开户量或开户成功率,再往下到它每个节点经过哪些服务,每个服务的成功率的指标的监控,从上往下去建立业务的健康监测。
Q:拉通整合多层对象的可观测与传统的运行可视化最关键的区别是什么?
A:最关键的是我们能否建立每一层的依赖物。比如单个指标目录式的架构,每一层到底有哪些监控,每一层的观测指标或观测移动是相对独立的,能不能做到上下层的联。我们在做多层拉通的情况下,优先建立一个套骨架,比如说用户层应用层,服务层往下的的时候,除了每一层之间的的横向骨架以外,上下层之间的依赖关系,同样也需要给它去做建立。这样的话,每一层观测的移动就是相应的观测。结果出来了之后,可以通过这个依赖关系去做一个向上的动作。我们在做实际的观测分析时,对所有条链的依赖关系上的观测问题全部做六结合关联,可以快速看到故障的传播链。
Q:拓扑可观测性中的东西向和南北向关系如何实现的?
A:拓扑东西向需要看是哪个层,因为有些层的关系它是可以天然建立的,比如说服务层之间通过一些trace的调用关系,再往下网络层的那些,它本身就有一些端口流量的关系,但是在网上业务层,我们更多的还是依赖于整个专家知识的整合。因为我们现在还没有办法做到,单业务整条横向依赖的关系自动识别上,所以这部分还是依赖于人为梳理或专家经验上。
Q:应用日志拥有非常多类型的报错信息,所有的信息都会化成指标吗?
A:我们在做应用日志检测的时候,最终都会画成指标,因为就算是关键字,它取的也是关键字量,去做相应的移动的告警。就算我我们后面引入了模板,报错类别识别的做法,也会做每一类的具体报错。它的指标量统计,每个量级到底是达到什么样的程度,在实际应用的时候,我们还是会转化成相应的指标,再去做相应的判定。
Q:平台组件的健康度打分机制是怎么实现的呢?
A:我们Paas组件层其实都是一些标准的技术站,每一类技术站都是观测指标的体系,比如命中率,内存使用率等等。其他组件,主机或者操作系统的cpu负载,都有它自己的关注指标体系。我们在这个指标里面,筛选相应的黄金指标概念,然后去抽选相应的环境指标去做观测模型,再做综合性打分。通过这种形式,把整个组件观测做个收敛和整体可用性的评比。
有疑问加站长微信联系(非本文作者)




