

上周,UGeek大咖说第六期
「可观测之超融合存储系统的应用与设计」
专题分享活动完美落幕
此次直播由优维研发总监陈安礼Linus主讲
分享了优维对可观测的看法与实践
此次活动细数了可观测平台面临的高频问题,也针对性地提供了一些常规的解决方案,而优维首创性地提出了超融合存储系统的解决方案,重点介绍了融合存储系统在化解可观测平台难点问题上的创新技术。
那么,和优维亦菲一起回顾本场活动的精彩内容吧!
1
可观测平台需要解决的问题
| 需求场景
· 按用户实时查看高负载业务列表(高负载:近10分钟cpu使用率>80%)
· 按业务和所属机房查看主机实时网络流量
· CMDB拓扑中展示指定的实时监控指标、属性等信息
| 需求分析
· 用户、业务、主机、机房等信息存储在CMDB
· 监控指标存储在监控系统
· 需要将两边的数据查询整合
| 常规解决方案
· 先查CMDB,再查监控数据,然后过滤整合?
· 先查监控数据,再查CMDB,然后过滤整合?
· 将需要的CMDB信息作为Tag存到监控数据库?
· 将监控数据直接存储到CMDB?
2
优维解决方案-融合存储
| 优维的解决方案——融合存储。

① 优维CMDB的实例数据。需要用户自定义属性,所以它适合文档类的,因为文档类可以灵活修改数据。
② 优维的关系数据。业务主机用户、机房、这些集群之间的关系其实是一个图的关系,多个实例之间可以建立多个多种关系。
③ 优维的监控指标数据,时间是完全相关的,所以是一个时序数据。把这三类数据融合起来,全放到一起统一查询,去实现这几个数据的融合。

详细的解决步骤与建模过程,请观看直播回放哦
3
超融合数据库easy_core
· 同时支持文档、图、时序数据存储
· 做到了OLTP和OLAP的有机结合
· 强一致、高可用、自动容灾
· 容量可平行扩展
通过上述方案,优维在上层业务层有了更加丰富、广阔的空间和想象力去做各种上层的业务功能。还做到了OLTP和OLAP的一个有机结合,即TPT的数据和OAP的数据,通过我们的智能查询引擎。直接就结合起来。另外,通过高可用方案,做到了数据强一致,若某个节点坏了,可以自动做一个主层切换和数据的切换。
也做到了一个数据数据的可平行扩展,某个节点负载高了,直接把对应的数据分散出去即可。
4
融合存储的优势
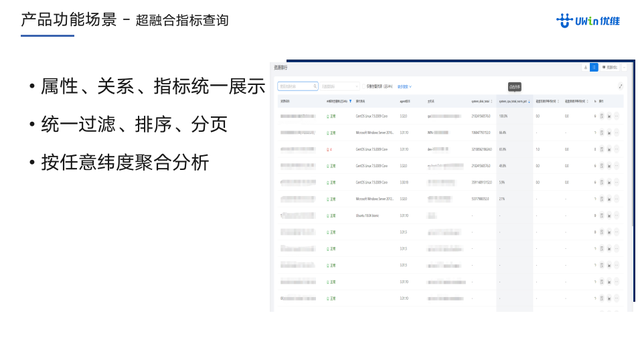
| 产品功能
· 属性、关系、指标统一维护和使用
· 业务拓扑信息更加丰富
· 可以基于cmdb关系做指标的OLAP分析
| 后台实现
· 监控指标存储简洁高效
· 简化业务逻辑
· 一个查询语句即可完成大部分需求
· 接口性能提升10倍以上
6
在线问答
直播过程中,我们的评论区出现了很多来自同学们的提问,小编已将问答部分整理成文字版,供大家温习。
问题1:图数据库和时序数据库是怎么关联的?图数据库关系怎么自动构建?
分为两个,我们的时序数据和图数据是分开存储的。结合的一个关键问题,就是查询引擎。图数据库里有文档数据以及图数据,相当于再加了一个时序数据。唯一不同是,时序数据是独立,是通过远程调用的。
比如一个请求过来之后,查询引擎会自动分析查询条件,是要去时序数据库查,还是到文档查,智能分析并分解成不同的算子。这里会牵扯到很多的细节。比如怎么保证查询是高效的?先查CMDB还是先查Easycore?查询的算子是怎么样的?如何组合查询算子下推。优化之后就整合起来了。这里的关系是,我们对外主要面向的都是Easycore,提供Easycore的产品入口,而时序数据库是不直接对外的。
问题2:Influxdb数据库对比怎么样?
我们研发的时候做了性能对比,有1.0版、2.0版,以及一个未发布的成版。我们的TSDB数据库架构是最新的,和未发布的成功版一样,与它们2.0数据库对比,在一些小数据量查询时比它稍微差一点,大数量查询比较好,比如几十个Tag的查询,数据量在上亿时,性能是比它强很多的,所以目前来看是各有优缺点,在小数据量查询这一块我们还会继续优化。目前的架构应该是未来的架构,因为它们未发布的那一版也是用这个架构的,它们还在积极开发的过程中,并且也是开源的。
问题3:数据库的性能怎么样?
企业成立之初,我们的数据库最早用的是CMDB是用MongoDB的。后面改用了OracleDB,但发现它的性能,稳定性等各方面都达不到我们的要求。所以我们才自研了图数据库。我们的图数据库里面图的引擎是直接传输在内存里的。所以这一块性能相比Oracle有很大提高。因为现在已经使用好多年,性能和稳定性也有了很大提升。
问题4:为什么要自研TSDB不用开源方案?
有两方面的考虑。
为了融合,首先时序数据库要能够解析查询引擎发出来的查询算子,给我做什么预算。如果是用传统的开源数据库,就相当于绕了一层,要转成你的查询语言,再返回,本来可以做一些更优化的查询,由于你的接口限制,导致没法做优化查询,这是最重要的一方面。另外一块,我们这里是可以针对的应用场景去做一些个性化的优化,比如我只需要监控,专存的数据。还可以把CMDB的一些核心的数据就比如我们的CMDB里的InstanceId,可以作为一个核心的标签拿过来,就可以针对这个标签去做特殊的优化了,之后只要按这个标查询,就会有性能极大的提高,这也是为什么说我们在数据量大的时候能够比InfluxDB查询效率高的原因,因为有了CMDB查询的场景,查询的时候必然会带某些Tag过来。那我就可以针对这些必然带的数据做一些个性化的优化,去提升整体的性能。
问题5:图数据库会开源吗?
我们有开源的计划。目前由于一些外部接口和内部的依赖都和CMDB强绑定,后续把更多东西处理好之后,我们会做成开源的,把成果让大家一起分享。
问题6:数据库是用什么语言实现的?
我们用了Rust。Rust有个特点就是它的性能是和C/C++差不多的,具有高性能,而且在实现的时候能够从语言层面去解决一些数据竞争、数据安全的问题,所以用Rust来写可以达到高性能,用以实现数据库是非常合适的。
有疑问加站长微信联系(非本文作者)




