
  Go语言实现了两种多线程同步方案,一种是传统多线程语言类似,基于共享内存方案;另一种称之为基于协程-管道的CSP(communicating sequential processes)并发编程模型,这也是Go语言推荐的方式。本篇文章主要讲解管道在并发编程中的典型应用,以及管道的底层实现原理。
## 典型应用场景
  顾名思义,管道可以从一端写入数据,一端读取数据,用户程序可以很方便的通过管道实现协程间通信,如下列方式:
```
package main
import (
"fmt"
"time"
)
func main() {
queue := make(chan int, 1)
go func() {
for {
data := <- queue //读取
fmt.Print(data, " ") //0 1 2 3 4 5 6 7 8 9
}
}()
for i := 0; i < 10; i ++ {
queue <- i //写入
}
time.Sleep(time.Second)
}
```
  管道可以在多协程间传递数据,管道的声明如"chan int"方式,声明包含了传递的数据类型。make初始化管道时候,第二个参数用于设置管道最大可以存储的数据量:管道容量满了之后,写入数据会阻塞当前协程;管道容量为空时,读取数据也会阻塞当前协程。那如果make初始化管道时,第二个参数是0呢?这意味着该管道最大容量为0,也就是,向管道写入数据时如果没有协程恰好等待读,一定会阻塞当前写协程;相应的,从管道读取数据时如果没有协程恰好等待写入,也一定会阻塞当前读协程。
  管道容量不为0时,我们通常称该管道为有缓冲管道,对应的管道容量为0就是无缓冲管道。有缓冲管道可供多个协程协同处理,在一定程度上可以提高程序的并发,这句话怎么理解呢?设想有这么一个需求:有一个脚本,从kafka等队列消费消息并处理,但是处理逻辑比较耗时,单线程/协程消费+处理效率太低,那就多协程处理呗。一个协程消费kafka等队列消息,写入管道,多个异步协程从管道获取消息并处理,这里我们就通过有缓冲管道 + 多协程提高了程序的并发。程序实例如下:
```
package main
import (
"fmt"
)
func main() {
//有缓冲管道
queue := make(chan int, 100)
//启动10个子协程消费管道消息
for i := 0; i < 10; i ++ {
go func() {
for {
data := <- queue
fmt.Println(data)
}
}()
}
//主协程循环向管道写入消息
for j := 0; j < 1000; j ++ {
queue <- j
}
}
```
  管道的写入或者读取可能会阻塞当前协程,问题就是当前管道是否可读或者可写是不知道的,如果一个协程需要同时操作多个管道呢?比如有多个异步协程从管道抓取数据(耗时),写入数据管道(每一个异步协程对应一个数据管道),主协程从多个数据管道消费数据,写入本地文件。主协程怎么同时读取多个管道呢?要知道读取管道可能会导致主协程阻塞的。Go语言还有一个关键字select,可以同时监听多个管道,非常类似IO多路复用的概念,如epoll。这时候程序应该是这样的:
```
package main
import (
"fmt"
"time"
)
func main() {
c1 := make(chan int, 10)
c2 := make(chan int, 10)
//协程1,循环向管道c1写入数据
go func() {
for i := 0; i < 1000; i ++ {
c1 <- i
time.Sleep(time.Second)
}
}()
//协程2,循环向管道c2写入数据
go func() {
for i := 1000; i < 2000; i ++ {
c2 <- i
time.Sleep(time.Millisecond * 500)
}
}()
//主协程,select case同时监听c1和c2两个管道,哪个管道先变为可读,先执行哪个case
for {
select {
case data := <- c1:
fmt.Println(data)
case data := <- c2:
fmt.Println(data)
}
}
}
```
  管道的读写操作可能导致协程的阻塞,有没有可能不阻塞协程呢?其实也可以,同样可以用select实现,不过这里还需要添加一个特殊的分支,default,意思是默认分支,即其他分支阻塞的时候,执行default分支。
```
package main
import (
"fmt"
"strconv"
)
func main() {
queue := make(chan int, 0)
for i := 0; i < 10; i ++ {
select {
case queue <- i:
fmt.Println("insert: " + strconv.Itoa(i))
default:
fmt.Println("skip: " + strconv.Itoa(i))
}
}
}
```
  queue是无缓冲管道,理论上主协程向管道queue写入数据都会阻塞,但是通过select default的组合,管道的写入变成非阻塞了。此时,如果无法向管道写入数据,执行defualt分支,并没有阻塞协程。
  select与default的组合可以实现管道的非阻塞操作,而select与定时器的组合,可以为管道的操作加上超时时间(其实就是select监听多个管道),也就是如果管道不可读或不可写,会阻塞协程,但是待定时器触发时,协程就会解除阻塞。
```
package main
import (
"fmt"
"time"
)
func main() {
queue := make(chan int, 0)
//定时器1秒后触发;
t := time.After(time.Second)
go func() {
select {
case <- queue:
fmt.Println("recv data")
case <- t:
fmt.Println("timeout") //time.After返回的其实就是管道,1秒后管道t变为可读;
}
}()
time.Sleep(time.Second * 3)
}
```
  我们前面介绍,管道的声明一般包含传递的数据类型,但是在某些场景,我们使用管道只是想传递一个信号,比如上面的程序你会关心定时器管道t读取的数据吗?再比如下面的程序,主协程需要等待子协程运行结束后再退出,就能通过管道实现,而这里管道声明为chan struct{},因为数据不重要,我们只关注他的可读可写状态。初始主协程读管道而阻塞,而等到子协程执行完毕后,向管道写入任意数据,主协程就会解除阻塞,恢复执行。
```
package main
import (
"fmt"
"time"
)
func main() {
queue := make(chan struct{}, 0)
go func() {
time.Sleep(time.Second)
queue <- struct{}{}
}()
<- queue
fmt.Println("time end")
}
```
## 实现原理
  chan是如何实现在多个协程间传递数据呢?思考一下,有缓冲管道是不是需要存储数据,那肯定需要一个数组了,而且这个数组应该作为循环队列使用(一边写入数据一边读取数据,数组没必要无限扩容,而且管道是FIFO模式,先写入的数据先读取,循环队列就能满足条件);另外,协程操作管道时还有可能被阻塞,阻塞的协程也有可能因为其他协程的写入或者读取而解除阻塞,阻塞的协程队列保存在哪呢?存储在管道变量就可以了;最后,多个协程可能并发的操作管道,所以肯定是需要加锁的。
  结合这三点思考,管道的数据类型定义也呼之欲出了:
```
// runtime/chan.go
type hchan struct {
//当前管道存储的元素数目
qcount uint // total data in the queue
//管道容量
dataqsiz uint // size of the circular queue
//数组
buf unsafe.Pointer // points to an array of dataqsiz elements
//标识管道是否被close
closed uint32
//管道存储的元素类型 & 元素大小
elemtype *_type // element type
elemsize uint16
//读/写索引,循环队列
sendx uint // send index
recvx uint // receive index
//读阻塞协程队列,写协程堵塞队列
recvq waitq // list of recv waiters
sendq waitq // list of send waiters
//锁
lock mutex
}
```
  管道数据结构定义如下图所示:
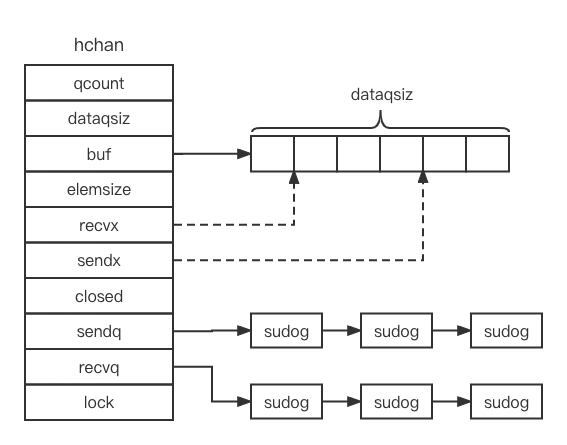
  文件runtime/chan.go不仅定义了管道的数据类型,好包括基本操作方法:
```
// chan初始化;size就是chan容量
func makechan(t *chantype, size int) *hchan
// 从chan读取数据;ep指针,读取到的数据就存储在ep;block表示如果chan不可读,是否阻塞协程
func chanrecv(c *hchan, ep unsafe.Pointer, block bool)
// 向chan写入数据;ep指针,待写入的数据就存储在ep;block表示如果chan不可写,是否阻塞协程
func chansend(c *hchan, ep unsafe.Pointer, block bool, callerpc uintptr)
// chan关闭
func closechan(c *hchan)
```
  我们以chansend函数为例,研究chan的基本操作:
```
func chansend(c *hchan, ep unsafe.Pointer, block bool, callerpc uintptr) bool {
//加锁
lock(&c.lock)
//如果有协程在等待读,直接将数据交给目标协程,并唤醒该协程
if sg := c.recvq.dequeue(); sg != nil {
send(c, sg, ep, func() { unlock(&c.lock) }, 3)
return true
}
//如果管道还有剩余容量
if c.qcount < c.dataqsiz {
//拷贝数据到chan数组
qp := chanbuf(c, c.sendx)
typedmemmove(c.elemtype, qp, ep)
//更新写入索引
c.sendx++
//循环队列,到最后一个索引了,从头开始
if c.sendx == c.dataqsiz {
c.sendx = 0
}
//管道目前存储元素数目
c.qcount++
//释放锁
unlock(&c.lock)
return true
}
//管道容量已经满了,直接返回false或者阻塞协程
//block为false表示不阻塞协程
if !block {
unlock(&c.lock)
return false
}
//协程阻塞时,会转化为sudog对象存储在管道的阻塞队列
mysg := acquireSudog()
mysg.g = gp
mysg.elem = ep
//阻塞协程入队
c.sendq.enqueue(mysg)
//协程换出
gopark(chanparkcommit, unsafe.Pointer(&c.lock), waitReasonChanSend, traceEvGoBlockSend, 2)
//走到这里,说明协程恢复执行,会执行一些释放任务
}
func send(c *hchan, sg *sudog, ep unsafe.Pointer, unlockf func(), skip int) {
//数据拷贝
if sg.elem != nil {
sendDirect(c.elemtype, sg, ep)
sg.elem = nil
}
gp := sg.g
unlockf()
//唤醒阻塞协程
goready(gp, skip+1)
}
```
  向管道写入数据时,如果当前有协程在阻塞等待读,send函数会调用goready唤醒该协程,即变更该协程状态为可运行_Grunnable,同时将该协程重新添加到P的协程队列。另外,协程阻塞时不是会转换为sudog对象么,而sudog.elem专用于数据的传递,send函数也会直接将待写入管道的数据,通过sudog.elem传递给读阻塞的协程。
  我们还注意到,参数block表示如果协程不可读或者不可写,是否阻塞协程。普通的协程读写都是阻塞时的,但是上一小节我们提到,select + default可以实现协程的非阻塞读写,这种语法会转换为runtime.selectnbrecv函数调用,其注释如下:
```
// compiler implements
//
// select {
// case v, ok = <-c:
// ... foo
// default:
// ... bar
// }
//
// as
//
// if selected, ok = selectnbrecv(&v, c); selected {
// ... foo
// } else {
// ... bar
// }
//
func selectnbrecv(elem unsafe.Pointer, c *hchan) (selected, received bool)
```
  我们再思考一个问题,管道如果被close了,或者是管道没有初始化(nil),这时候如果读、或者写、或者甚至close管道,会出现什么情况呢?阻塞吗?还是会抛panic异常?
```
func closechan(c *hchan) {
//抛panic
if c == nil {
panic(plainError("close of nil channel"))
}
//抛panic
if c.closed != 0 {
unlock(&c.lock)
panic(plainError("close of closed channel"))
}
//标识被关闭
c.closed = 1
//唤醒所有读阻塞、写阻塞的协程
release all readers
for {
sg := c.recvq.dequeue()
}
// release all writers (they will panic)
for {
sg := c.sendq.dequeue()
}
}
func chansend(c *hchan, ep unsafe.Pointer, block bool, callerpc uintptr) bool {
if c == nil {
if !block {
return false
}
//永久阻塞
gopark(nil, nil, waitReasonChanSendNilChan, traceEvGoStop, 2)
throw("unreachable")
}
//如果关闭,不可写,抛panic
if c.closed != 0 {
unlock(&c.lock)
panic(plainError("send on closed channel"))
}
}
func chanrecv(c *hchan, ep unsafe.Pointer, block bool) (selected, received bool) {
if c == nil {
if !block {
return
}
//永久阻塞
gopark(nil, nil, waitReasonChanReceiveNilChan, traceEvGoStop, 2)
throw("unreachable")
}
//如果管道没有数据,返回该类型空数据
if c.closed != 0 && c.qcount == 0 {
unlock(&c.lock)
if ep != nil {
typedmemclr(c.elemtype, ep)
}
return true, false
}
// 正常数据读取流程
}
```
  首先明确了一件事情,管道只能关闭一次,并且如果管道为nil,也是不能关闭的;而且管道关闭时,也会唤醒所有因为该管道而阻塞的协程。当管道为nil时,如果block为true,读写管道都会导致协程的永久阻塞。当管道被close时,向管道写入数据是会抛panic的,但是可以正常读取数据,即使管道为空,读取也会立即返回(空数据)。
  最后,select时如何实现同时监听多个管道的呢?想象一下如果将当前协程添加多多个管道的阻塞队列呢,是不是任意管道可读或可写时,都会唤醒该协程?select的实现逻辑有些复杂,这里我们就不再赘述,有兴趣的可以研究下runtime.selectgo函数:
```
// selectgo implements the select statement.
// cas0指向多个case数组首地址,nsends、nrecvs 读、写管道的数目;block是否阻塞
func selectgo(cas0 *scase, order0 *uint16, pc0 *uintptr, nsends, nrecvs int, block bool) (int, bool)
```
## 管道与调度器schedule
  还记得之前介绍的吗?协程因为某些原因阻塞了(chan的读写,socket的读写等等),或者是协程执行结束了,这时候也是需要重新调度其他协程的。协程阻塞通常是通过runtime.gopark函数完成的,而灰度协程调度通常是通过函数runtime.goready完成。
  管道的读操作以及写操作都有可能阻塞协程,参考函数chanrecv以及chansend:
```
func chansend(c *hchan, ep unsafe.Pointer, block bool, callerpc uintptr) bool {
//协程阻塞
gopark(chanparkcommit, unsafe.Pointer(&c.lock), waitReasonChanSend, traceEvGoBlockSend, 2)
}
func chanrecv(c *hchan, ep unsafe.Pointer, block bool) (selected, received bool) {
//协程阻塞
gopark(chanparkcommit, unsafe.Pointer(&c.lock), waitReasonChanReceive, traceEvGoBlockRecv, 2)
}
```
  协程因管道阻塞后,什么时候能恢复执行呢?当然是其他协程读/写管道时了,从函数chansend的流程可以看到,协程阻塞时,转换为sudog结构,存储在sendq阻塞队列。所以在chanrecv函数中,肯定可以找到对应的从sendq获取协程并恢复调度的逻辑。
```
func chanrecv(c *hchan, ep unsafe.Pointer, block bool) (selected, received bool) {
if sg := c.sendq.dequeue(); sg != nil {
recv(c, sg, ep, func() { unlock(&c.lock) }, 3)
return true, true
}
}
func recv(c *hchan, sg *sudog, ep unsafe.Pointer, unlockf func(), skip int) {
if c.dataqsiz == 0 {
//无缓冲管道,直接拷贝数据
if ep != nil {
// copy data from sender
recvDirect(c.elemtype, sg, ep)
}
} else {
//有缓冲管道,该阻塞协程是因为管道满了
qp := chanbuf(c, c.recvx)
//从缓冲区拷贝数据
if ep != nil {
typedmemmove(c.elemtype, ep, qp)
}
// 拷贝发送协程的数据到管道
typedmemmove(c.elemtype, qp, sg.elem)
c.recvx++
if c.recvx == c.dataqsiz {
c.recvx = 0
}
c.sendx = c.recvx // c.sendx = (c.sendx+1) % c.dataqsiz
}
//恢复协程调度
goready(gp, skip+1)
}
```
## 总结
  管道是Go语言并发编程非常重要的数据类型,本篇文章先介绍了管道的一些典型应用场景,最后深入底层,讲解了管道读写操作的实现逻辑,以及管道与调度器schedule之间的关系。
有疑问加站长微信联系(非本文作者))




