
问题引入
生产环境Golang服务有时会产生502报警,排查发现大多是以下三种原因造成的:
- http.Server配置了WriteTimeout,请求处理超时,Golang服务断开连接;
- http.Server配置了IdleTimeout,且网关和Golang之间使用长连接,Golang服务主动断开连接;
- Golang服务处理HTTP请求时出现了panic。
本篇文章主要介绍这三种502产生的具体原因,另外本篇文章提到的网关是基于Nginx搭建的。
WriteTimeout
WriteTimeout的含义是:从接收到客户端请求开始,到返回响应的最大超时时间,默认为0意味着不超时。注释如下:
type Server struct {
// WriteTimeout is the maximum duration before timing out
// writes of the response. It is reset whenever a new
// request's header is read. Like ReadTimeout, it does not
// let Handlers make decisions on a per-request basis.
// A zero or negative value means there will be no timeout.
WriteTimeout time.Duration
}
注释表明,当接收到新的请求时,超时时间会重置。那么什么时候设置写超时时间呢?当然是在http.Server读取客户端请求完成时了,参考readRequest方法:
func (c *conn) readRequest(ctx context.Context) (w *response, err error) {
if d := c.server.WriteTimeout; d != 0 {
//defer,也就是函数返回时设置定时器
defer func() {
c.rwc.SetWriteDeadline(time.Now().Add(d))
}()
}
}
可是,为什么WriteTimeout会导致502呢?如果你恰巧也遇到了之类问题,可以查看网关访问日志,你会看到所有请求的响应request_time都大于WriteTimeout,并且错误日志显示的是"upstream prematurely close connection while reading response header from upstream",也就是在网关等到上游响应时,上游关闭连接了。剩下的问题就是为什么上游会关闭连接了。
一个小小的实验
我们先模拟以下请求处理超时的现象:
package main
import (
"net/http"
"time"
)
type GinHandler struct {
}
func (* GinHandler) ServeHTTP(w http.ResponseWriter, r *http.Request){
time.Sleep(time.Duration(5) * time.Second)
w.Write([]byte("hello golang"))
}
func main() {
server := &http.Server{
Addr:"0.0.0.0:8080",
Handler: &GinHandler{},
ReadTimeout: time.Second * 3,
WriteTimeout: time.Second *3,
}
server.ListenAndServe()
}
请求结果如下:
time curl http://127.0.0.1/test -H "Host:test.xxx.com"
502 Bad Gateway
real 0m5.011s
查看Nginx的错误日志,可以看到是上游主动关闭连接造成的:
21:18:07 [error] 30217#0: *8105 upstream prematurely closed connection while reading response header from upstream, client: 127.0.0.1, server: test.xxx.com, request: "GET /test HTTP/1.1", upstream: "http://127.0.0.1:8080/test", host: "test.xxx.com"
通过tcpdump再抓包验证下;可以看到,35秒接受到客户端请求,40秒时,服务端主动断开了连接。
20:52:35.660325 IP 127.0.0.1.31227 > 127.0.0.1.8080: Flags [S], seq 3442614457, win 43690, length 0
14:05:54.073175 IP 127.0.0.1.8080 > 127.0.0.1.31227: Flags [S.], seq 3655119156, ack 3442614458, win 43690, length 0
20:52:35.660353 IP 127.0.0.1.31227 > 127.0.0.1.8080: Flags [.], ack 1, win 86, length 0
20:52:35.660415 IP 127.0.0.1.31227 > 127.0.0.1.8080: Flags [P.], seq 1:106, ack 1, win 86, length 105: HTTP: GET /test HTTP/1.0
20:52:35.660425 IP 127.0.0.1.8080 > 127.0.0.1.31227: Flags [.], ack 106, win 86, length 0
20:52:40.662303 IP 127.0.0.1.8080 > 127.0.0.1.31227: Flags [F.], seq 1, ack 106, win 86, length 0
20:52:40.662558 IP 127.0.0.1.31227 > 127.0.0.1.8080: Flags [F.], seq 106, ack 2, win 86, length 0
20:52:40.662605 IP 127.0.0.1.8080 > 127.0.0.1.31227: Flags [.], ack 107, win 86, length 0
看到这里有个疑惑,5秒后Golang服务才断开连接的,我们不是设置了WriteTimeout=3秒吗?为什么3秒超时不断开,而是5秒后才断开?
WriteTimeout到底做了什么
net.http.(c * conn).serve方法是Golang sdk解析处理HTTP请求的主函数,我们可以找到WriteTimeout的设置入口,c.rwc.SetWriteDeadline。这里的rwc类型为net.Conn,是一个接口。真正的对象是由l.Accept()返回的,而l是对象TCPListener。往下追踪可以发现创建的是net.TCPConn对象,而该对象继承了net.conn,net.conn又实现了net.Conn接口(注意大小写)。
type TCPConn struct {
conn
}
type conn struct {
fd *netFD
}
func (c *conn) SetReadDeadline(t time.Time) error {
if err := c.fd.SetReadDeadline(t); err != nil {
}
}
再继续往下跟踪,调用链是这样的:
net.(c *conn).SetWriteDeadline()
net.(fd *netFD).SetWriteDeadline()
poll.(fd *FD).SetWriteDeadline()
poll.setDeadlineImpl()
poll.runtime_pollSetDeadline()
追到这,你会发现追不下去了,runtime_pollSetDeadline的实现逻辑是什么呢?我们全局搜素runtime_pollSetDeadline,可以找到在runtime/netpoll.go文件。
//go:linkname poll_runtime_pollSetDeadline internal/poll.runtime_pollSetDeadline
func poll_runtime_pollSetDeadline(pd *pollDesc, d int64, mode int) {
//写超时回调函数
pd.wt.f = netpollWriteDeadline
//定时器到期后,调用回调函数的传入参数
pd.wt.arg = pd
}
我们的问题即将水落石出,只需要分析回调函数netpollWriteDeadline(统一由netpolldeadlineimpl实现)做了什么,即可明白WriteTimeout到底是什么。
func netpolldeadlineimpl(pd *pollDesc, seq uintptr, read, write bool) {
if write {
pd.wd = -1
atomic.StorepNoWB(unsafe.Pointer(&pd.wt.f), nil)
wg = netpollunblock(pd, 'w', false)
}
if wg != nil {
netpollgoready(wg, 0)
}
}
可以看到,设置pd.wd=-1,后续以此判断该描述符上的写定时器是否已经过期。netpollunblock与netpollgoready,用于判断是否有协程因为当前描述符阻塞,如果有将其状态置为可运行,并加入可运行队列;否则什么都不做。
这下一切都明白了,WriteTimeout只是添加了读写超时定时器,待定时器过期时,也仅仅是设置该描述符读写超时。所以哪怕请求处理时间是5秒远超过WriteTimeout设置的超时时间,该请求依然不会被中断,会正常执行直到结束,在向客户端返回结果时才会发生异常。
该过程参照下图:
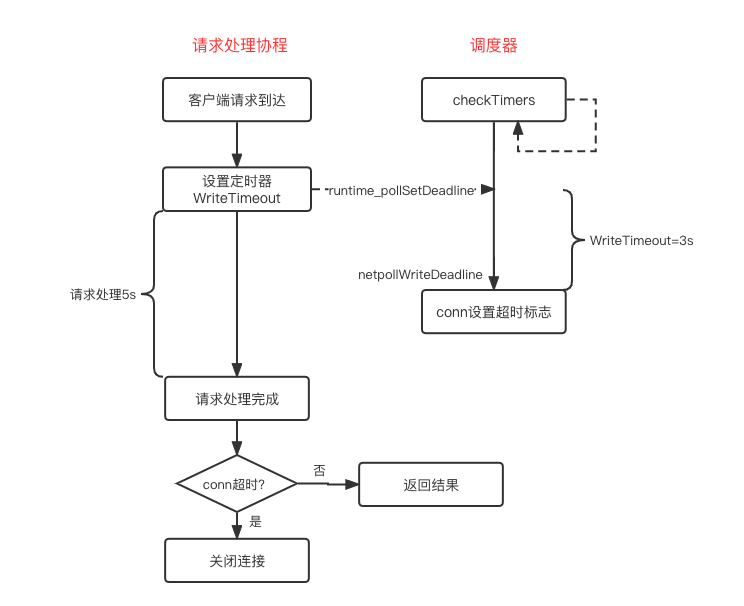
最后我们通过dlv调试,打印一下设置WriteTimeout的函数调用链。
0 0x0000000001034c23 in internal/poll.runtime_pollSetDeadline
at /usr/local/go/src/runtime/netpoll.go:224
1 0x00000000010ee3a0 in internal/poll.setDeadlineImpl
at /usr/local/go/src/internal/poll/fd_poll_runtime.go:155
2 0x00000000010ee14a in internal/poll.(*FD).SetReadDeadline
at /usr/local/go/src/internal/poll/fd_poll_runtime.go:132
3 0x00000000011cc868 in net.(*netFD).SetReadDeadline
at /usr/local/go/src/net/fd_unix.go:276
4 0x00000000011dffca in net.(*conn).SetReadDeadline
at /usr/local/go/src/net/net.go:251
5 0x000000000131491f in net/http.(*conn).readRequest
at /usr/local/go/src/net/http/server.go:953
6 0x000000000131bd5a in net/http.(*conn).serve
at /usr/local/go/src/net/http/server.go:1822
刚才设置超时时间会调用poll.(fd FD).SetWriteDeadline,FD结构封装了底层描述符,其必然提供读写处理函数。我们在poll.(fd FD).Write打断点,看一下调用链路:
(dlv) b poll.Write
Breakpoint 1 set at 0x10ef40b for internal/poll.(*FD).Write() /usr/local/go/src/internal/poll/fd_unix.go:254
(dlv) bt
0 0x00000000010ef40b in internal/poll.(*FD).Write
at /usr/local/go/src/internal/poll/fd_unix.go:254
1 0x00000000011cc0ac in net.(*netFD).Write
at /usr/local/go/src/net/fd_unix.go:220
2 0x00000000011df765 in net.(*conn).Write
at /usr/local/go/src/net/net.go:196
3 0x000000000132276c in net/http.checkConnErrorWriter.Write
at /usr/local/go/src/net/http/server.go:3434
4 0x0000000001177e91 in bufio.(*Writer).Flush
at /usr/local/go/src/bufio/bufio.go:591
5 0x000000000131a329 in net/http.(*response).finishRequest
at /usr/local/go/src/net/http/server.go:1594
6 0x000000000131c7c5 in net/http.(*conn).serve
at /usr/local/go/src/net/http/server.go:1900
与我们设想的一致,待请求处理完成后,哪怕超时了,上层业务依然会尝试写响应结果。继续往下追查,看看是什么时候判断描述符超时了:
poll.(fd *FD).Write
poll.(pd *pollDesc).prepareWrite
poll.(pd *pollDesc).prepare
poll.runtime_pollReset
//go:linkname poll_runtime_pollReset internal/poll.runtime_pollReset
func poll_runtime_pollReset(pd *pollDesc, mode int) int {
errcode := netpollcheckerr(pd, int32(mode))
if errcode != pollNoError {
return errcode
}
}
func netpollcheckerr(pd *pollDesc, mode int32) int {
if pd.closing {
return 1 // ErrFileClosing or ErrNetClosing
}
if (mode == 'r' && pd.rd < 0) || (mode == 'w' && pd.wd < 0) {
return 2 // ErrTimeout
}
……
return 0
}
函数runtime_pollReset的实现逻辑同样是在runtime/netpoll.go文件。其通过netpollcheckerr实现校验逻辑,判断描述符是否关闭,是否超时等等,这里返回了超时错误。最终,最顶层http.(c * conn).serve方法判断写响应出错,直接返回,返回前执行defer做收尾工作,比如关闭连接,由此引发网关返回502错误。
超时怎么控制?
参照上面的分析,通过WriteTimeout控制请求的超时时间,存在两个问题:1)请求处理超时后Golang会断开连接,网关会出现502;2)请求不会因为WriteTimeout超时而被中断,需要等到请求真正处理完成,客户端等待响应时间较长;在遇到大量慢请求时,Golang服务资源占用会急剧增加。
那么如何优雅的控制超时情况呢?超时后Golang直接结束当前请求,并向客户端返回默认结果。可以利用context.Context实现,这是一个接口,有多种实现,如cancelCtx可取消的上下文,timerCtx可定时取消的上下文,valueCtx可基于上下文传递变量。
下面举一个小小的例子:
ctx := context.Background()
ctx, cancel := context.WithCancel(ctx)
go Proc()
time.Sleep(time.Second)
cancel()
func Proc(ctx context.Context) {
for {
select {
case <- ctx.Done():
return
default:
//do something
}
}
}
关于context更多使用与原理,可以参考之前的文章。
IdleTimeout + 长连接
Golang sdk的注释说明如下:
"IdleTimeout is the maximum amount of time to wait for the next request when keep-alives are enabled. If IdleTimeout is zero, the value of ReadTimeout is used. If both are zero, there is no timeout"。
可以看到只有当网关和上游Golang服务之间采用keep-alived长连接时,该配置才生效。需要特别注意的是,如果IdleTimeout等于0,则默认取ReadTimeout的值。
注意:Nginx在通过proxy_pass配置转发时,默认采用HTTP 1.0,且"Connection:close"。因此需要添加如下配置才能使用长连接:
proxy_http_version 1.1;
proxy_set_header Connection "";
一个小小的实验
该场景下的502存在概率问题,只有当上游Golang服务关闭连接,与新的请求到达,几乎同时发生时,才有可能出现。因此最终只是通过tcpdump抓包观察Golang服务端关闭连接。
这种场景产生的根本原因是,网关转发请求到上游的同时,上游服务关闭了长连接,此时TCP层次会返回RST包。所以这种502有一个明显的特征,upstream_response_time接近于0,并且查询网关错误日志可以看到"connection reset by peer"。
记得配置网关Nginx到Golang服务之间采用长连接,同时配置IdleTimeout=5秒。只请求一次,tcpdump抓包观察现象如下:
15:15:03.155362 IP 127.0.0.1.20775 > 127.0.0.1.8080: Flags [S], seq 3293818352, win 43690, length 0
01:50:36.801131 IP 127.0.0.1.8080 > 127.0.0.1.20775: Flags [S.], seq 901857004, ack 3293818353, win 43690, length 0
15:15:03.155385 IP 127.0.0.1.20775 > 127.0.0.1.8080: Flags [.], ack 1, win 86, length 0
15:15:03.155406 IP 127.0.0.1.20775 > 127.0.0.1.8080: Flags [P.], seq 1:135, ack 1, win 86, length 134: HTTP: GET /test HTTP/1.1
15:15:03.155411 IP 127.0.0.1.8080 > 127.0.0.1.20775: Flags [.], ack 135, win 88, length 0
15:15:03.155886 IP 127.0.0.1.8080 > 127.0.0.1.20775: Flags [P.], seq 1:130, ack 135, win 88, length 129: HTTP: HTTP/1.1 200 OK
15:15:03.155894 IP 127.0.0.1.20775 > 127.0.0.1.8080: Flags [.], ack 130, win 88, length 0
//IdleTimeout 5秒超时后,Golang服务主动断开连接
15:15:08.156130 IP 127.0.0.1.8080 > 127.0.0.1.20775: Flags [F.], seq 130, ack 135, win 88, length 0
15:15:08.156234 IP 127.0.0.1.20775 > 127.0.0.1.8080: Flags [F.], seq 135, ack 131, win 88, length 0
15:15:08.156249 IP 127.0.0.1.8080 > 127.0.0.1.20775: Flags [.], ack 136, win 88, length 0
Golang服务主动断开连接,网关就有可能产生502。怎么解决这个问题呢?只要保证每次都是网关主动断开连接即可。
ngx_http_upstream_module模块在新版本添加了一个配置参数,keepalive_timeout。注意这不是ngx_http_core_module模块里的,两个参数名称一样,但是用途不一样。
Syntax: keepalive_timeout timeout;
Default:
keepalive_timeout 60s;
Context: upstream
This directive appeared in version 1.15.3.
Sets a timeout during which an idle keepalive connection to an upstream server will stay open.
显然只要Golang服务配置的IdleTimeout大于这里的keepalive_timeout即可。
源码分析
整个处理过程在http.(c * conn).serve方法,逻辑如下:
func (c *conn) serve(ctx context.Context) {
defer func() {
//函数返回前关闭连接
c.close()
}()
//循环处理
for {
//读请求
w, err := c.readRequest(ctx)
//处理请求
serverHandler{c.server}.ServeHTTP(w, w.req)
//响应
w.finishRequest()
//没有开启keepalive,则关闭连接
if !w.conn.server.doKeepAlives() {
return
}
if d := c.server.idleTimeout(); d != 0 {
//设置读超时时间为idleTimeout
c.rwc.SetReadDeadline(time.Now().Add(d))
//阻塞读,待idleTimeout超时后,返回错误
if _, err := c.bufr.Peek(4); err != nil {
return
}
}
//接收到新的请求,清空ReadTimeout
c.rwc.SetReadDeadline(time.Time{})
}
}
可以看到在设置读超时时间为idleTimeout后,会再次从连接读取数据,此时会阻塞当前协程;待超时后,读取操作会返回错误,此时serve方法返回,而在返回前会关闭该连接。
panic
Golang服务级的panic会导致程序的异常终止,Golang服务都终止了,网关必然会产生瞬时大量502了(上游服务挂了,网关会出现大量错误日志"connection refused by peer")。所以对应的,通常我们会通过recover捕获异常,恢复程序的执行。
defer func() {
if err := recover(); err != nil {
//打印调用栈
stack := stack(3)
//记录请求详情
httprequest, _ := httputil.DumpRequest(c.Request, false)
logger.E("[Recovery]", " %s panic recovered:\n%s\n%s\n%s", time.Now().Format("2006/01/02 - 15:04:05"), string(httprequest), err, stack)
c.AbortWithStatus(500)
}
}()
另外,对于HTTP处理handler来说,如果出现panic且没有recover时,Golang sdk提供了recover逻辑,只是比较粗暴,简单的关闭连接罢了,而这一处理同样会导致Nginx返回502。这种502最容易排查了,只需要查找有无"http: panic serving"日志即可。
func (c *conn) serve(ctx context.Context) {
defer func() {
if err := recover(); err != nil && err != ErrAbortHandler {
const size = 64 << 10
buf := make([]byte, size)
buf = buf[:runtime.Stack(buf, false)]
c.server.logf("http: panic serving %v: %v\n%s", c.remoteAddr, err, buf)
}
if !c.hijacked() {
c.close()
c.setState(c.rwc, StateClosed)
}
}()
}
这种类型的502特征也比较明显,网关访问日志request_time一般比较短,比如几十毫秒等,与你请求的响应时间大体一致,而且网关错误日志是"upstream prematurely closed connection while reading response header from upstream"。
总结
本篇文章主要介绍了Golang服务常见的几种502错误,掌握502产生的本质,以及每种502的现象,如响应时间,错误日志等等,再遇到这种问题相信你很快就能解决了。
有疑问加站长微信联系(非本文作者))



