
本教程演示如何使用向量检索服务(DashVector),结合ModelScope上的中文CLIP多模态检索模型,构建实时的“文本搜图片”的多模态检索能力。作为示例,我们采用多模态牧歌数据集作为图片语料库,用户通过输入文本来跨模态检索最相似的图片。
整体流程
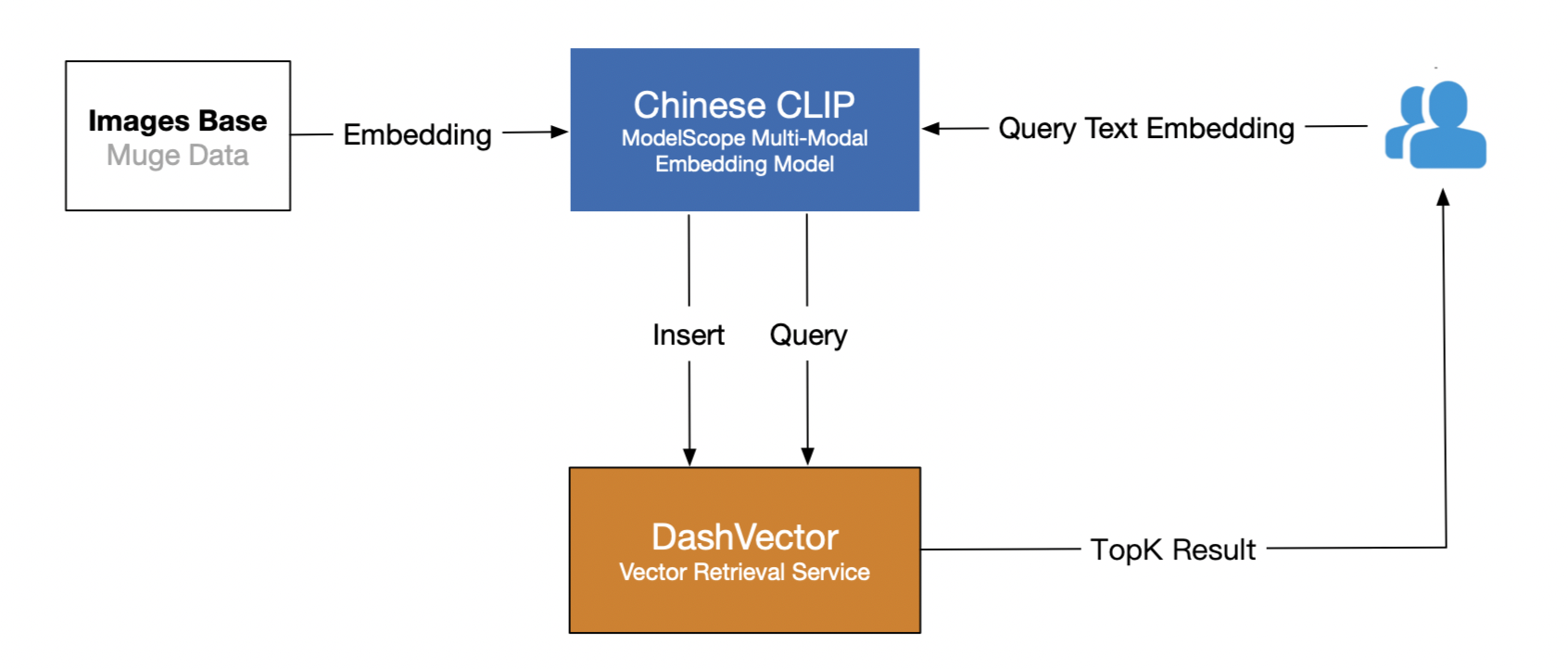
主要分为两个阶段:
-
图片数据Embedding入库。将牧歌数据集通过中文CLIP模型Embedding接口转化为高维向量,然后写入DashVector向量检索服务。
-
文本Query检索。使用对应的中文CLIP模型获取文本的Embedding向量,然后通过DashVector检索相似图片。
前提准备
1. API-KEY 准备
2. 环境准备
本教程使用的是ModelScope最新的CLIP Huge模型(224分辨率),该模型使用大规模中文数据进行训练(~2亿图文对),在中文图文检索和图像、文本的表征提取等场景表现优异。根据模型官网教程,我们提取出相关的环境依赖如下:
说明
需要提前安装 Python3.7 及以上版本,请确保相应的 python 版本
# 安装 dashvector 客户端
pip3 install dashvector
# 安装 modelscope
# require modelscope>=0.3.7,目前默认已经超过,您检查一下即可
# 按照更新镜像的方法处理或者下面的方法
pip3 install --upgrade modelscope -f https://modelscope.oss-cn-beijing.aliyuncs.com/releases/repo.html
# 需要单独安装decord
# pip3 install decord
# 另外,modelscope 的安装过程会出现其他的依赖,当前版本的依赖列举如下
# pip3 install torch torchvision opencv-python timm librosa fairseq transformers unicodedata2 zhconv rapidfuzz
3. 数据准备
本教程使用多模态牧歌数据集的validation验证集作为入库的图片数据集,可以通过调用ModelScope的数据集接口获取。
from modelscope.msdatasets import MsDataset
dataset = MsDataset.load("muge", split="validation")
具体步骤
说明
本教程所涉及的 your-xxx-api-key 以及 your-xxx-cluster-endpoint,均需要替换为您自己的API-KAY及CLUSTER_ENDPOINT后,代码才能正常运行。
1. 图片数据Embedding入库
多模态牧歌数据集的 validation 验证集包含 30588 张多模态场景的图片数据信息,这里我们需要通过CLIP模型提取原始图片的Embedding向量入库,另外为了方便后续的图片展示,我们也将原始图片数据编码后一起入库。代码实例如下:
import torch
from modelscope.utils.constant import Tasks
from modelscope.pipelines import pipeline
from modelscope.msdatasets import MsDataset
from dashvector import Client, Doc, DashVectorException, DashVectorCode
from PIL import Image
import base64
import io
def image2str(image):
image_byte_arr = io.BytesIO()
image.save(image_byte_arr, format='PNG')
image_bytes = image_byte_arr.getvalue()
return base64.b64encode(image_bytes).decode()
if __name__ == '__main__':
# 初始化 dashvector client
client = Client(
api_key='{your-dashvector-api-key}',
endpoint='{your-dashvector-cluster-endpoint}'
)
# 创建集合:指定集合名称和向量维度, CLIP huge 模型产生的向量统一为 1024 维
rsp = client.create('muge_embedding', 1024)
if not rsp:
raise DashVectorException(rsp.code, reason=rsp.message)
# 批量生成图片Embedding,并完成向量入库
collection = client.get('muge_embedding')
pipe = pipeline(task=Tasks.multi_modal_embedding,
model='damo/multi-modal_clip-vit-huge-patch14_zh',
model_revision='v1.0.0')
ds = MsDataset.load("muge", split="validation")
BATCH_COUNT = 10
TOTAL_DATA_NUM = len(ds)
print(f"Start indexing muge validation data, total data size: {TOTAL_DATA_NUM}, batch size:{BATCH_COUNT}")
idx = 0
while idx < TOTAL_DATA_NUM:
batch_range = range(idx, idx + BATCH_COUNT) if idx + BATCH_COUNT <= TOTAL_DATA_NUM else range(idx, TOTAL_DATA_NUM)
images = [ds[i]['image'] for i in batch_range]
# 中文 CLIP 模型生成图片 Embedding 向量
image_embeddings = pipe.forward({'img': images})['img_embedding']
image_vectors = image_embeddings.detach().cpu().numpy()
collection.insert(
[
Doc(
id=str(img_id),
vector=img_vec,
fields={'png_img': image2str(img)}
)
for img_id, img_vec, img in zip(batch_range, image_vectors, images)
]
)
idx += BATCH_COUNT
print("Finish indexing muge validation data")
说明
上述代码里模型默认在 cpu 环境下运行,在 gpu 环境下会视 gpu 性能得到不同程度的性能提升
2. 文本Query检索
完成上述图片数据向量化入库后,我们可以输入文本,通过同样的CLIP Embedding模型获取文本向量,再通过DashVector向量检索服务的检索接口,快速检索相似的图片了,代码示例如下:
import torch
from modelscope.utils.constant import Tasks
from modelscope.pipelines import pipeline
from modelscope.msdatasets import MsDataset
from dashvector import Client, Doc, DashVectorException
from PIL import Image
import base64
import io
def str2image(image_str):
image_bytes = base64.b64decode(image_str)
return Image.open(io.BytesIO(image_bytes))
def multi_modal_search(input_text):
# 初始化 DashVector client
client = Client(
api_key='{your-dashvector-api-key}',
endpoint='{your-dashvector-cluster-endpoint}'
)
# 获取上述入库的集合
collection = client.get('muge_embedding')
# 获取文本 query 的 Embedding 向量
pipe = pipeline(task=Tasks.multi_modal_embedding,
model='damo/multi-modal_clip-vit-huge-patch14_zh', model_revision='v1.0.0')
text_embedding = pipe.forward({'text': input_text})['text_embedding'] # 2D Tensor, [文本数, 特征维度]
text_vector = text_embedding.detach().cpu().numpy()[0]
# DashVector 向量检索
rsp = collection.query(text_vector, topk=3)
image_list = list()
for doc in rsp:
image_str = doc.fields['png_img']
image_list.append(str2image(image_str))
return image_list
if __name__ == '__main__':
text_query = "戴眼镜的狗"
images = multi_modal_search(text_query)
for img in images:
# 注意:show() 函数在 Linux 服务器上可能需要安装必要的图像浏览器组件才生效
# 建议在支持 jupyter notebook 的服务器上运行该代码
img.show()
运行上述代码,输出结果如下:



免费体验阿里云高性能向量检索服务:https://www.aliyun.com/product/ai/dashvector

有疑问加站长微信联系(非本文作者)




