
- 可以直接看微信公众号文章:https://mp.weixin.qq.com/s/4uw_GTBrmIqKjBETlKAluQ
- 同时github上赏我一个star吧:https://github.com/mgtv-tech/redis-GunYu
- 也可以同时关注我微信公众号,有很多优质文章:【技术闲聊吧】
## **高可用之殇**
正开心地刷着手机,突然APP无法使用,正焦急地不知所措时,收到公告:“因施工意外挖断光缆,某某云数据中心故障,导致APP服务不可用”。
你是否经历过这种遭遇,或听说别人吐槽过?
在今天的全球化和分布式计算的大环境中,无论是企业级应用、云计算服务还是大规模网络平台,跨数据中心部署变得越来越重要。
那仅仅是将服务部署到多个数据中心就解决问题了吗?服务可以是无状态部署,那么数据呢?跨数据中心访问数据带来的延迟显然会影响用户体验。当今越来越多的服务都用redis来存储数据或缓存数据,那么如何将redis部署到不同的数据中心,不同数据中心的redis又如何进行数据同步,是很多企业必然要面临的问题。
## **数据是有状态的**
我们的服务都进行跨数据中心的部署,避免由于数据中心故障而影响用户的事情发生。我们同样面临跨数据中心数据同步的难题,在经过我们基础架构团队的努力后,自研了一个高可用的跨数据中心实时同步redis数据的工具。让有状态的redis数据可以在不同的数据中心之间进行同步,服务可以访问最近节点的数据,极大提高了用户体验。
我们的愿景是将工具建设成一个redis数据治理的分布式系统,以解决redis数据的“水患”问题,所以我们将其取名为“鲧禹”,为了简单起见,我们一般称为“大禹”。
## **大禹有哪些功能**
从产品需求上,对redis-GunYu和几个主流工具进行比较
| 功能点 | redis-shake/v2 | DTS | xpipe | redis-GunYu |
| ------- | -------------- | --- | ----- | ----------------- |
| 断点续传 | Y(无本地缓存) | Y | Y | Y |
| 支持分片不对称 | N | Y | N | Y |
| 拓扑变化 | N | N | N | Y |
| 高可用 | N | N | Y | Y |
| 过滤 | Y | Y | Y | Y |
| 数据一致性 | 最终 | 弱 | 弱 | 最终(分片对称) + 弱(不对称) |
大禹还有哪些优势呢?
* 对稳定性影响更小
* 复制优先级:可指定优先从从库进行复制或主库复制
* 本地缓存 + 断点续传:最大程度减少对源端redis的影响
* 可以对RDB中的大key进行拆分同步
* 更低的复制延迟:在保证一致性的前提下,并发地进行数据回放
* 数据安全性与高可用
* 本地缓存支持数据校验
* 工具高可用:支持主从模式,以最新记录进行自主选举,自动和手动failover;工具本身P2P架构,将宕机影响降低到最小
* 对redis限制更少
* 支持源和目标端不同的redis部署方式,如cluster或单实例
* 兼容源和目的redis不同版本,支持从redis4.0到redis7.2
* 数据一致性策略更加灵活,自动切换
* 当源端和目标端分片信息一致时,采用伪事务方式批量写入,实时更新快照信息,最大可能地保证一致性
* 当源端和目标端分片不一致时,采用定期更新快照信息
* 运维更加友好
* API:可以通过http API进行运维操作,如强制全量复制、同步状态、暂停同步等
* 监控:监控指标更丰富,如时间与空间维度的复制延迟指标
* 数据过滤:可以对key、db、命令等进行过滤
* 拓扑变化监控:实时监听源和目标端redis拓扑变更(如加减节点,主从切换等等),以更改一致性策略和调整其他功能策略
## **大禹是怎么做数据同步的呢**
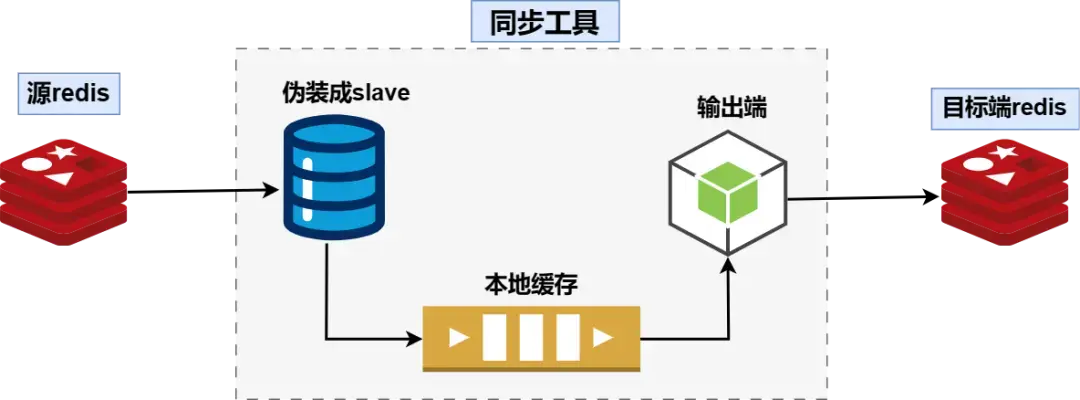
内部实现可以简单的看成是上图的三个模块。针对每一个源端redis的节点,大禹都会有一条对应的pipeline,每条pipeline结构如下:
* 输入端:伪装成redis slave,从源端redis实例同步数据
* 通道端:本地缓存
* 输出端:将数据写入到目标端
## **大禹也支持高可用部署**
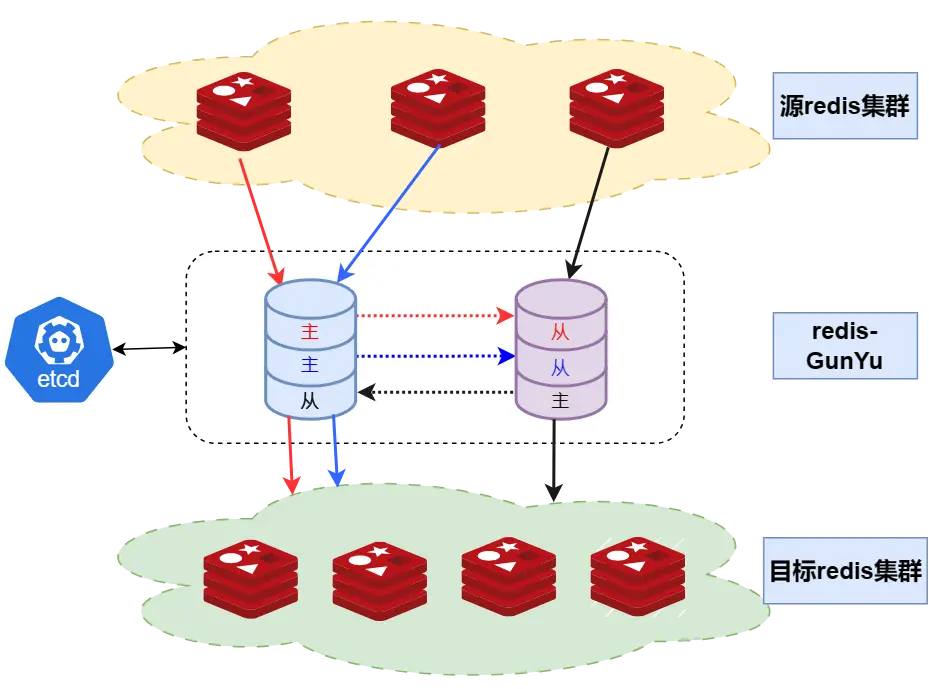
大禹节点之间是P2P架构,互为主备,每个pipeline都会独立地选举缓存数据最新的节点为领导者,由领导者伪装成redis 从库,从源端redis节点同步数据再写到目标端,同时将数据发送到此pipeline的跟随者。这种P2P结构,可以将工具本身故障的影响降到最低。
## **行动起来吧**
欢迎大家使用大禹,完善大禹,一起将大禹建设成一个完善的数据治理解决方案吧。
【请github上点个star吧】源代码地址 : <https://github.com/mgtv-tech/redis-GunYu>
有疑问加站长微信联系(非本文作者))




