
# 开发个人Ollama-Chat--5 模型管理 (一)
## 背景
开发一个chatGPT的网站,后端服务如何实现与大模型的对话?是整个项目中开发困难较大的点。
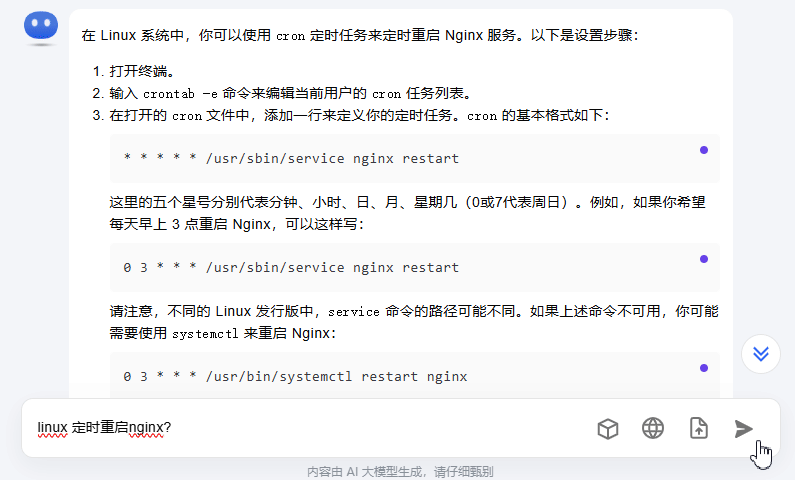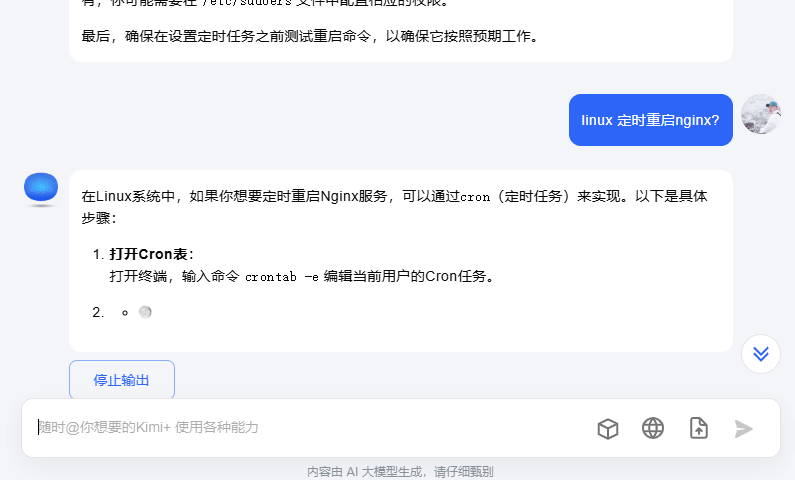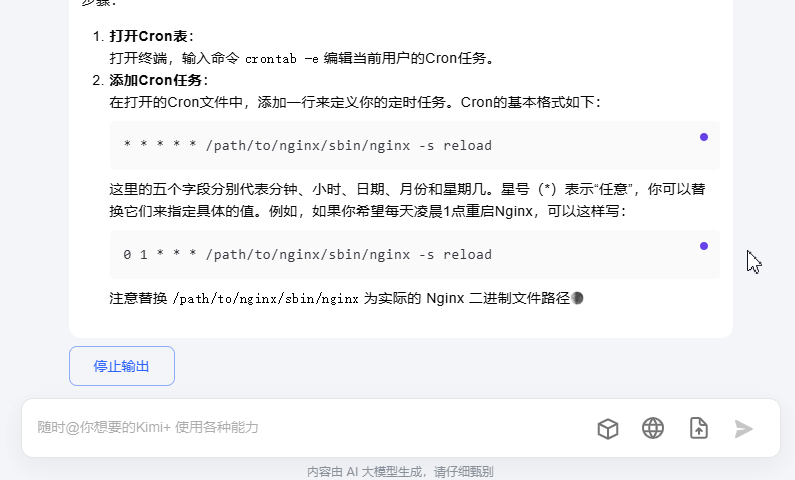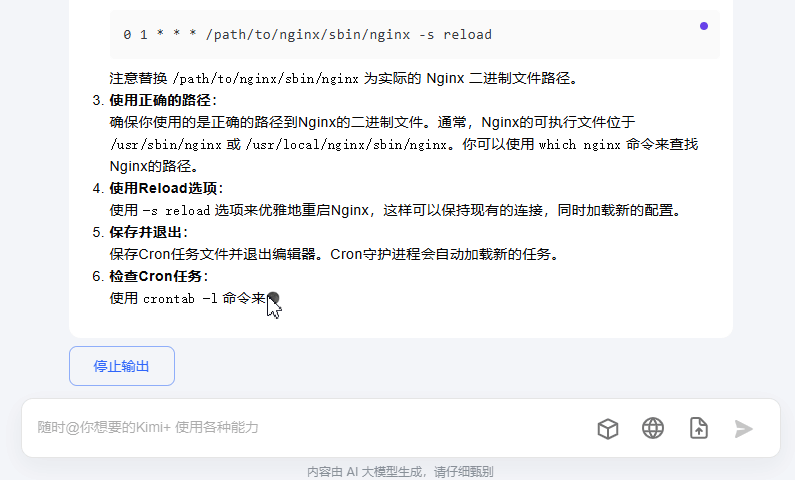
如何实现上图的聊天对话功能?在开发后端的时候,如何实现stream的响应呢?本文就先介绍后端的原理,逐步攻克这个课题。
## 环境部署
- 启动`ollama`: `docker run -d -p 3000:8080 -p 11434:11434 -v ollama:/root/.ollama -v open-webui:/app/backend/data --name open-webui --restart always ollama/ollama`
- ollama 下载对话模型: `docker exec -it open-webui ollama run gemma:2b`
```bash
pulling manifest
pulling c1864a5eb193... 100% ▕████████████████████████████████████████████████████████████████████████████████████████████████████████████████████▏ 1.7 GB
pulling 097a36493f71... 100% ▕████████████████████████████████████████████████████████████████████████████████████████████████████████████████████▏ 8.4 KB
pulling 109037bec39c... 100% ▕████████████████████████████████████████████████████████████████████████████████████████████████████████████████████▏ 136 B
pulling 22a838ceb7fb... 100% ▕████████████████████████████████████████████████████████████████████████████████████████████████████████████████████▏ 84 B
pulling 887433b89a90... 100% ▕████████████████████████████████████████████████████████████████████████████████████████████████████████████████████▏ 483 B
verifying sha256 digest
writing manifest
removing any unused layers
success
```
## Stream reponse
### 前端
```svelte
....
const [res, controller] = await generateChatCompletion(localStorage.token, {
model: model,
messages: messagesBody,
options: {
...($settings.options ?? {})
},
format: $settings.requestFormat ?? undefined,
keep_alive: $settings.keepAlive ?? undefined,
docs: docs.length > 0 ? docs : undefined
});
if (res && res.ok) {
console.log('controller', controller);
const reader = res.body
.pipeThrough(new TextDecoderStream())
.pipeThrough(splitStream('\n'))
.getReader();
...
```
`ollama`的`open-webui` 前端项目实现和人类一样沟通的方法,使用的是`stream`监听 `messages`事件收到的响应,保持长连接的状态,逐渐将收到的消息显示到前端,直到后端响应结束。
### 后端
- `gin.Stream`
```go
...
c.Stream(func(w io.Writer) bool {
select {
case msg, ok := <-msgChan:
if !ok {
// 如果msgChan被关闭,则结束流式传输
return false
}
fmt.Print(msg)
// 流式响应,发送给 messages 事件,和前端进行交互
c.SSEvent("messages", msg)
return true
case <-c.Done():
// 如果客户端连接关闭,则结束流式传输
return false
}
})
...
```
- `ollama` 响应
```go
...
// llms.WithStreamingFunc 将ollama api 的响应内容逐渐返回,而不是一次性全部返回
callOp := llms.WithStreamingFunc(func(ctx context.Context, chunk []byte) error {
select {
case msgChan <- string(chunk):
case <-ctx.Done():
return ctx.Err() // 返回上下文的错误
}
return nil
})
_, err := llaClient.Call(context.Background(), prompt, callOp)
if err != nil {
log.Fatalf("Call failed: %v", err) // 处理错误,而不是 panic
}
...
```
- 完整代码
```go
package main
import (
"context"
"fmt"
"io"
"log"
"net/http"
"github.com/gin-gonic/gin"
"github.com/tmc/langchaingo/llms"
"github.com/tmc/langchaingo/llms/ollama"
)
func main() {
router := gin.Default()
router.GET("/ping", func(c *gin.Context) {
c.JSON(http.StatusOK, gin.H{
"message": "OK",
})
})
router.POST("/chat", chat)
router.Run(":8083")
}
type Prompt struct {
Text string `json:"text"`
}
func chat(c *gin.Context) {
var prompt Prompt
if err := c.BindJSON(&prompt); err != nil {
c.JSON(http.StatusBadRequest, gin.H{"error": err.Error()})
return
}
var msgChan = make(chan string)
// 通过chan 将ollama 响应返回给前端
go Generate(prompt.Text, msgChan)
c.Stream(func(w io.Writer) bool {
select {
case msg, ok := <-msgChan:
if !ok {
// 如果msgChan被关闭,则结束流式传输
return false
}
// fmt.Print(msg)
c.SSEvent("messages", msg)
return true
case <-c.Done():
// 如果客户端连接关闭,则结束流式传输
return false
}
})
}
var llaClient *ollama.LLM
func init() {
// Create a new Ollama instance
// The model is set to "gemma:2b"
// remote url is set to "http://ollama-ip:11434"
url := ollama.WithServerURL("http://ollama-ip:11434")
lla, err := ollama.New(ollama.WithModel("gemma:2b"), url)
if err != nil {
panic(err)
}
llaClient = lla
fmt.Println("connect to ollama server successfully")
}
func Generate(prompt string, msgChan chan string) {
// ctx, cancel := context.WithTimeout(context.Background(), time.Second*5) // 设置超时
// defer cancel() // 确保在函数结束时取消上下文
callOp := llms.WithStreamingFunc(func(ctx context.Context, chunk []byte) error {
select {
case msgChan <- string(chunk):
case <-ctx.Done():
return ctx.Err() // 返回上下文的错误
}
return nil
})
_, err := llaClient.Call(context.Background(), prompt, callOp)
if err != nil {
log.Fatalf("Call failed: %v", err) // 处理错误,而不是 panic
}
// 确保在所有数据处理完毕后关闭 msgChan
close(msgChan)
}
```
## 项目地址
[jackwillsmith/openui-svelte-build (github.com)](https://github.com/jackwillsmith/openui-svelte-build/)
[GitHub - jackwillsmith/openui-backend-go: openui-backend-go](https://github.com/jackwillsmith/openui-backend-go.git)
有疑问加站长微信联系(非本文作者))




