
**前置知识**
-----------------
### **BM25简介**
BM25算法(Best Matching 25)是一种广泛用于信息检索领域的排名函数,用于在给定查询(Query)时对一组文档(Document)进行评分和排序。BM25在计算Query和Document之间的相似度时,本质上是依次计算Query中每个单词和Document的相关性,然后对每个单词的相关性进行加权求和。BM25算法一般可以表示为如下形式:
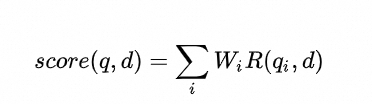
上式中, *q* 和 *d* 分别表示用来计算相似度的Query和Document, *q* ~*i*~表示 *q* 的第 *i* 个单词, *R(q* ~*i*~ *, d)* 表示单词 *q* ~*i*~和文档 *d* 的相关性, *W* ~*i*~表示单词 *q* ~*i*~的权重,计算得到的 *score(q, d)* 表示 *q* 和 *d* 的相关性得分,得分越高表示 *q* 和 *d* 越相似。 *W* ~*i*~和 *R(q* ~*i*~ *, d)* 一般可以表示为如下形式:
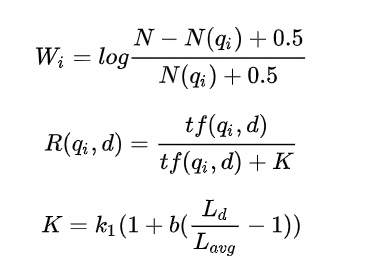
其中, *N* 表示总文档数, *N(q* ~*i*~ *)* 表示包含单词 *q* ~*i*~的文档数, *tf(q* ~*i*~ *, d)* 表示 *q* ~*i*~在文档 *d* 中的词频, *L* ~*d*~表示文档 *d* 的长度, *L* ~*avg*~表示平均文档长度, *k* ~*1*~和 *b* 是分别用来控制 *tf(q* ~*i*~ *, d)* 和 *L* ~*d*~对得分影响的超参数。
### **稀疏向量生成**
在检索场景中,为了让BM25算法的Score方便进行计算,通常分别对Document和Query进行编码,然后通过 **点积** 的方式计算出两者的相似度。得益于BM25原理的特性,其原生支持将Score拆分为两部分Sparse Vector,DashText提供了`encode_document`以及`encode_query`两个接口来分别实现这两部分向量的生成,其生成链路如下图所示:

最终生成的稀疏向量可表示为:

### **Score/距离计算**
生成 *d* 和 *q* 的稀疏向量后,就可以通过简单的点积进行距离计算,即将相同单词上的值对应相乘再求和,通过稀疏向量计算距离的方式如下所示:
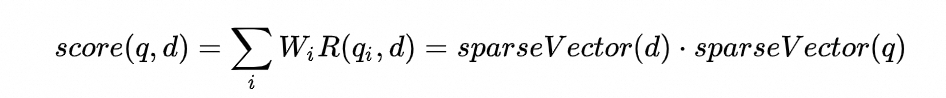
上述计算方式本质上是通过点积来计算的, *score* 越大表示越相似,如果需要结合Dense Vector一起进行距离度量时,需要对齐距离度量方式。也就是说,在结合Dense Vector+Sparse Vector的场景中,距离计算只支持点积度量方式。
**如何自训练模型**
----------------------------
考虑到内置的BM25 Model是基于通用语料([中文Wiki语料](https://dumps.wikimedia.org/zhwiki/latest/zhwiki-latest-pages-articles.xml.bz2))训练得到,在特定领域下通常不能表现出最佳的效果。因此,在一些特定场景下,通常建议训练自定义BM25模型。使用DashText来训练自定义模型时一般需要遵循以下步骤:
### **Step1:确认使用场景**
当准备使用SparseVector来进行信息检索时,应提前考虑当前场景下的Query以及Document来源,通常需要提前准备好一定数量Document来入库,这些Document通常需要和特定的业务场景直接相关。
### **Step2:准备语料**
根据BM25原理,语料直接决定了BM25模型的参数。通常应按照以下几个原则来准备语料:
* 语料来源应尽可能反映对应场景的特性,尽可能让 *N(q* ~*i*~ *)* 能够反映对应真实场景的词频信息。
* 调节合理的语料切片长度和切片数量,避免出现语料当中只有少量长文本的情况。
一般情况下,如无特殊要求或限制,可以直接将Step1准备的一系列Document组织为语料即可。
### **Step3:准备Tokenizer**
Tokenizer决定了分词的结果,分词的结果则直接影响Sparse Vector的生成,在特定领域下使用自定义Tokenizer会达到更好的效果。DashText提供了两种扩展Tokenizer的方式:
* 使用自定义词表:DashText内置的Jieba Tokenizer支持传入自定义词表。(Java SDK暂不支持该功能)
Python示例:
```python
from dashtext import TextTokenizer, SparseVectorEncoder
my_tokenizer = TextTokenizer.from_pretrained(model_name='Jieba', dict='dict.txt')
my_encoder = SparseVectorEncoder(tokenize_function=my_tokenizer.tokenize)
```
* 使用自定义Tokenizer:DashText支持任务自定义的Tokenizer,只需提供一个符合`Callable[[str], List[str]]`签名的Tokenize函数即可。
Python示例:
```python
from dashtext import SparseVectorEncoder
from transformers import BertTokenizer
my_tokenizer = BertTokenizer.from_pretrained('bert-base-uncased')
my_encoder = SparseVectorEncoder(tokenize_function=my_tokenizer.tokenize)
```
Java示例:
```java
import com.aliyun.dashtext.common.DashTextException;
import com.aliyun.dashtext.common.ErrorCode;
import com.aliyun.dashtext.encoder.SparseVectorEncoder;
import com.aliyun.dashtext.tokenizer.BaseTokenizer;
import java.util.Arrays;
import java.util.List;
import java.util.stream.Collectors;
public class Main {
public static class MyTokenizer implements BaseTokenizer {
@Override
public List<String> tokenize(String s) throws DashTextException {
if (s == null) {
throw new DashTextException(ErrorCode.INVALID_ARGUMENT);
}
// 使用正则表达式将文本按空白符和标点符号分割,并转换为小写
return Arrays.stream(s.split("\\s+|(?<!\\d)[.,](?!\\d)"))
.map(String::toLowerCase)
.filter(token -> !token.isEmpty()) // 过滤掉空字符串
.collect(Collectors.toList());
}
}
public static void main(String[] args) {
SparseVectorEncoder encoder = new SparseVectorEncoder(new MyTokenizer());
}
}
```
### **Step4:训练模型**
实际上,这里的"训练"本质上是一个"统计"参数的过程。由于训练自定义模型的过程中包含着大量Tokenizing/Hashing过程,所以可能会耗费一定的时间。DashText提供了`SparseVectorEncoder.train`接口可以用来训练模型。
### **Step5:调参优化(可选)**
模型训练完成后,可以准备部分验证数据集以及通过微调 *k* ~*1*~和 *b* 来达到最佳的召回效果。调节k~1~和b一般需要遵循以下原则:
* 调节 *k* ~*1*~(1.2 \< *k* ~*1*~ \< 2)可控制Document词频对Score的影响, *k* ~*1*~越大Document的词频对Score的贡献越小。
* 调节 *b* (0 \< *b* \< 1)可控制文档长度对Score的影响, *b* 越大表示文档长度对权重的影响越大
一般情况下,如无特殊要求或限制,不需要调整 *k* ~*1*~和 *b* 。
### **Step6:Finetune模型(可选)**
实际场景下,可能会存在需要补充训练语料来增量式地更新BM25模型参数的情况。DashText的`SparseVectorEncoder.train`接口原生支持模型的增量更新。需要注意的是,模型更改之后,使用旧模型进行编码并已入库的向量就失去了时效性,一般需要重新入库。
### **示例代码**
以下是一个简单完整的自训练模型示例。
Python示例:
```python
from dashtext import SparseVectorEncoder
from pydantic import BaseModel
from typing import Dict, List
class Result(BaseModel):
doc: str
score: float
def calculate_score(query_vector: Dict[int, float], document_vector: Dict[int, float]) -> float:
score = 0.0
for key, value in query_vector.items():
if key in document_vector:
score += value * document_vector[key]
return score
# 创建空SparseVectorEncoder(可以设置自定义Tokenizer)
encoder = SparseVectorEncoder()
# step1: 准备语料以及Documents
corpus_document: List[str] = [
"The quick brown fox rapidly and agilely leaps over the lazy dog that lies idly by the roadside.",
"Never jump over the lazy dog quickly",
"A fox is quick and jumps over dogs",
"The quick brown fox",
"Dogs are domestic animals",
"Some dog breeds are quick and jump high",
"Foxes are wild animals and often have a brown coat",
]
# step2: 训练BM25 Model
encoder.train(corpus_document)
# step3: 调参优化BM25 Model
query: str = "quick brown fox"
print(f"query: {query}")
k1s = [1.0, 1.5]
bs = [0.5, 0.75]
for k1, b in zip(k1s, bs):
print(f"current k1: {k1}, b: {b}")
encoder.b = b
encoder.k1 = k1
query_vector = encoder.encode_queries(query)
results: List[Result] = []
for idx, doc in enumerate(corpus_document):
doc_vector = encoder.encode_documents(doc)
score = calculate_score(query_vector, doc_vector)
results.append(Result(doc=doc, score=score))
results.sort(key=lambda r: r.score, reverse=True)
for result in results:
print(result)
# step4: 选择最优参数并保存模型
encoder.b = 0.75
encoder.k1 = 1.5
encoder.dump("./model.json")
# step5: 后续使用时可以加载模型
new_encoder = SparseVectorEncoder()
bm25_model_path = "./model.json"
new_encoder.load(bm25_model_path)
# step6: 对模型进行finetune并保存
extra_corpus: List[str] = [
"The fast fox jumps over the lazy, chubby dog",
"A swift fox hops over a napping old dog",
"The quick fox leaps over the sleepy, plump dog",
"The agile fox jumps over the dozing, heavy-set dog",
"A speedy fox vaults over a lazy, old dog lying in the sun"
]
new_encoder.train(extra_corpus)
new_bm25_model_path = "new_model.json"
new_encoder.dump(new_bm25_model_path)
```
Java示例:
```java
import com.aliyun.dashtext.encoder.SparseVectorEncoder;
import java.io.*;
import java.util.*;
public class Main {
public static class Result {
public String doc;
public float score;
public Result(String doc, float score) {
this.doc = doc;
this.score = score;
}
@Override
public String toString() {
return String.format("Result(doc=%s, score=%f)", doc, score);
}
}
public static float calculateScore(Map<Long, Float> queryVector, Map<Long, Float> documentVector) {
float score = 0.0f;
for (Map.Entry<Long, Float> entry : queryVector.entrySet()) {
if (documentVector.containsKey(entry.getKey())) {
score += entry.getValue() * documentVector.get(entry.getKey());
}
}
return score;
}
public static void main(String[] args) throws IOException {
// 创建空SparseVectorEncoder(可以设置自定义Tokenizer)
SparseVectorEncoder encoder = new SparseVectorEncoder();
// step1: 准备语料以及Documents
List<String> corpusDocument = Arrays.asList(
"The quick brown fox rapidly and agilely leaps over the lazy dog that lies idly by the roadside.",
"Never jump over the lazy dog quickly",
"A fox is quick and jumps over dogs",
"The quick brown fox",
"Dogs are domestic animals",
"Some dog breeds are quick and jump high",
"Foxes are wild animals and often have a brown coat"
);
// step2: 训练BM25 Model
encoder.train(corpusDocument);
// step3: 调参优化BM25 Model
String query = "quick brown fox";
System.out.println("query: " + query);
float[] k1s = {1.0f, 1.5f};
float[] bs = {0.5f, 0.75f};
for (int i = 0; i < k1s.length; i++) {
float k1 = k1s[i];
float b = bs[i];
System.out.println("current k1: " + k1 + ", b: " + b);
encoder.setB(b);
encoder.setK1(k1);
Map<Long, Float> queryVector = encoder.encodeQueries(query);
List<Result> results = new ArrayList<>();
for (String doc : corpusDocument) {
Map<Long, Float> docVector = encoder.encodeDocuments(doc);
float score = calculateScore(queryVector, docVector);
results.add(new Result(doc, score));
}
results.sort((r1, r2) -> Float.compare(r2.score, r1.score));
for (Result result : results) {
System.out.println(result);
}
}
// step4: 选择最优参数并保存模型
encoder.setB(0.75f);
encoder.setK1(1.5f);
encoder.dump("./model.json");
// step5: 后续使用时可以加载模型
SparseVectorEncoder newEncoder = new SparseVectorEncoder();
newEncoder.load("./model.json");
// step6: 对模型进行finetune并保存
List<String> extraCorpus = Arrays.asList(
"The fast fox jumps over the lazy, chubby dog",
"A swift fox hops over a napping old dog",
"The quick fox leaps over the sleepy, plump dog",
"The agile fox jumps over the dozing, heavy-set dog",
"A speedy fox vaults over a lazy, old dog lying in the sun"
);
newEncoder.train(extraCorpus);
newEncoder.dump("./new_model.json");
}
}
```
API参考
----------------------
DashText API详情可参考:https://pypi.org/project/dashtext/
有疑问加站长微信联系(非本文作者))




