
本文主要介绍带关键词感知能力的向量检索服务的优势、应用示例以及Sparse Vector生成工具。
**背景介绍**
-------------------------
### **关键词检索及其局限**
在信息检索领域,"传统"方式是通过关键词进行信息检索,其大致过程为:
1. 对原始语料(如网页)进行关键词抽取。
2. 建立关键词和原始语料的映射关系,常见的方法有倒排索引、TF-IDF、BM25等方法,其中TF-IDF、BM25通常用 **稀疏向量(Sparse Vector)** 来表示词频。
3. 检索时,对检索语句进行关键词抽取,并通过步骤2中建立的映射关系召回关联度最高的TopK原始语料。
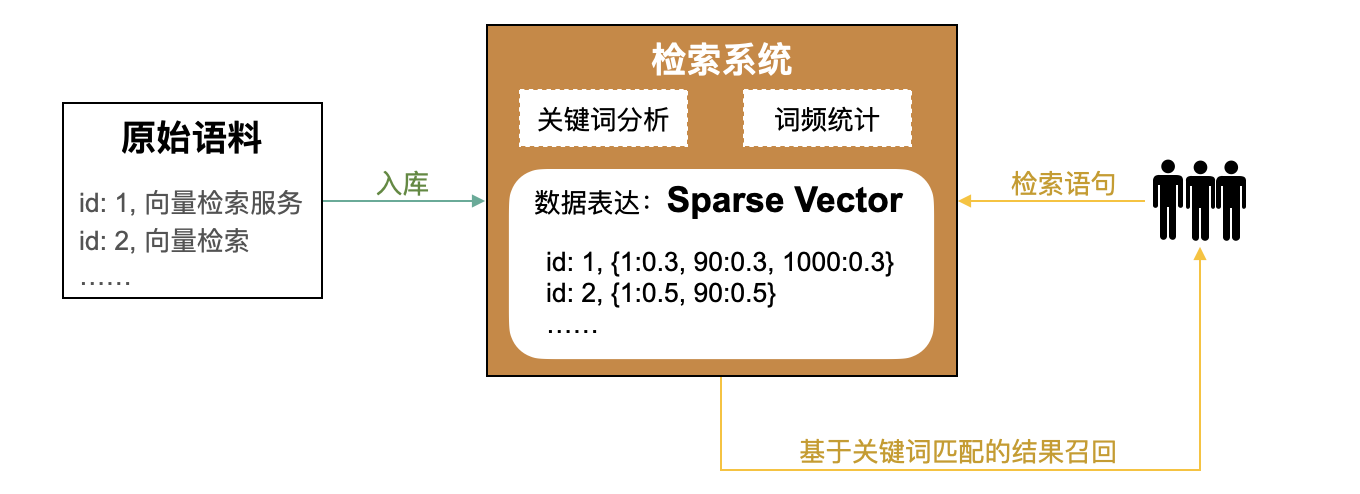
但关键词检索无法对语义进行理解。例如,检索语句为"浙一医院",经过分词后成为"浙一"和"医院",这两个关键词都无法有效的命中用户预期中的"浙江大学医学院附属第一医院"这个目标。
### **基于语义的向量检索**
随着人工智能技术日新月异的发展,语义理解Embedding模型能力的不断增强,基于语义Embedding的向量检索召回关联信息的方式逐渐成为主流。其大致过程如下:
1. 原始语料(如网页)通过Embedding模型产生 **向量(Vector)** ,又称为 **稠密向量(Dense Vector)。**
2. 向量入库向量检索系统。
3. 检索时,检索语句同样通过Embedding模型产生向量,并用该向量在向量检索系统中召回距离最近的TopK原始语料。
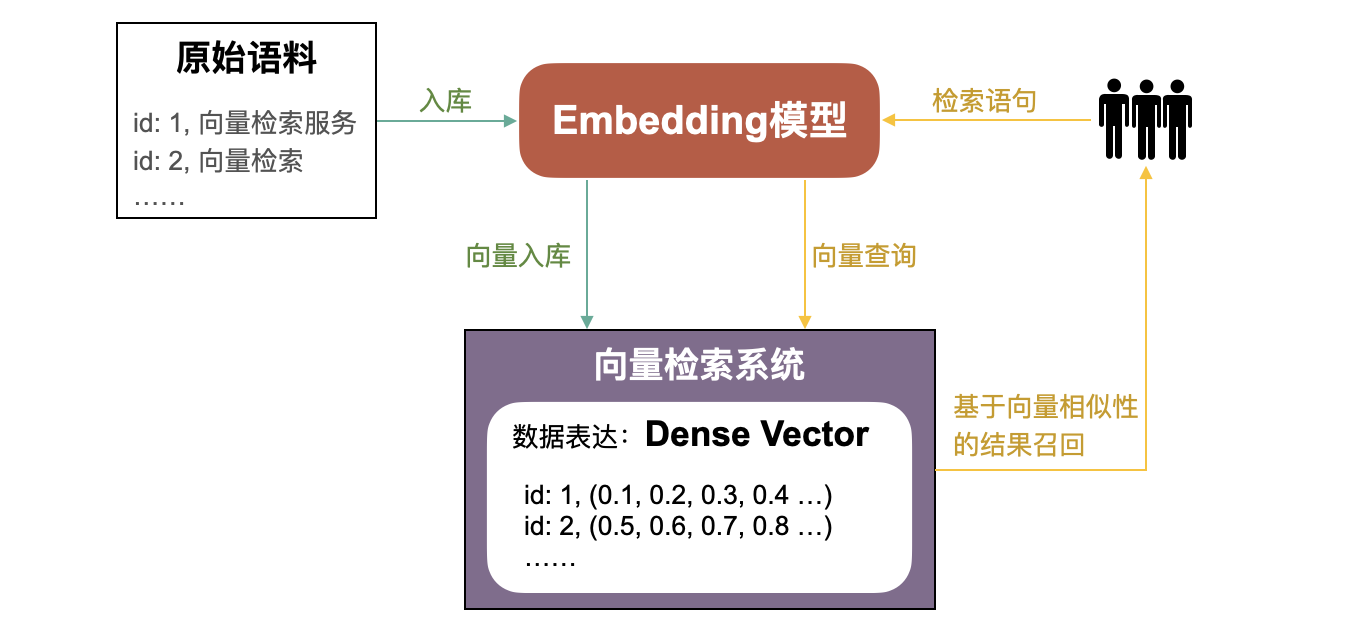
但不可否认的是,基于语义的向量检索来召回信息也存在局限------必须不断的优化Embedding模型对语义的理解能力,才能取得更好的效果。例如,若模型无法理解"水稻灌溉"和"灌溉水稻"在语义上比较接近,就会导致无法通过"水稻灌溉"召回"灌溉水稻"相关的语料。而关键字检索在这个例子上,恰好可以发挥其优势,通过"水稻"、"灌溉"关键字有效的召回相关语料。
### **关键词检索+语义检索**
针对上述问题,逐渐有业务和系统演化出来"两路召回、综合排序"的方法来解决,并且在效果上也超过了单纯的关键字检索或语义检索,如下图所示:
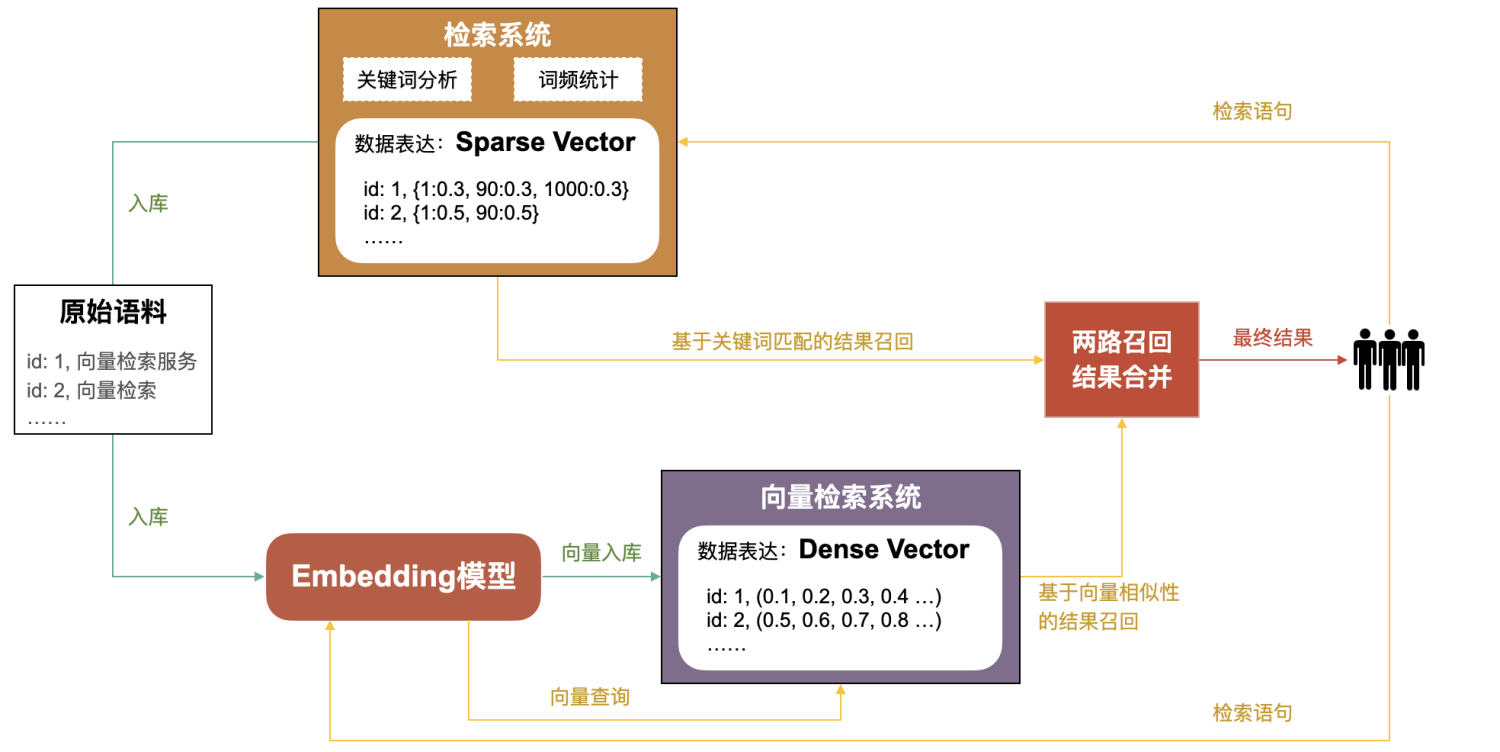
但这种方式的弊端也很明显:
1. 系统复杂度增加。
2. 硬件资源(内存、CPU、磁盘等)开销增加。
3. 可维护性降低。
4. ......
**具有关键词感知能力的语义检索**
---------------------------
向量检索服务DashVector同时支持Dense Vector(稠密向量)和Sparse Vector(稀疏向量),前者用于模型的高维特征(Embedding)表达,后者用于关键词和词频信息表达。DashVector可以进行关键词感知的向量检索,即Dense Vector和Sparse Vector结合的混合检索。
DashVector带关键词感知能力的向量检索能力,既有"两路召回、综合排序"方案的优点,又没有其缺点。使得系统复杂度、资源开销大幅度降低的同时,还具备关键词检索、向量检索、关键词+向量混合检索的优势,可满足绝大多数业务场景的需求。
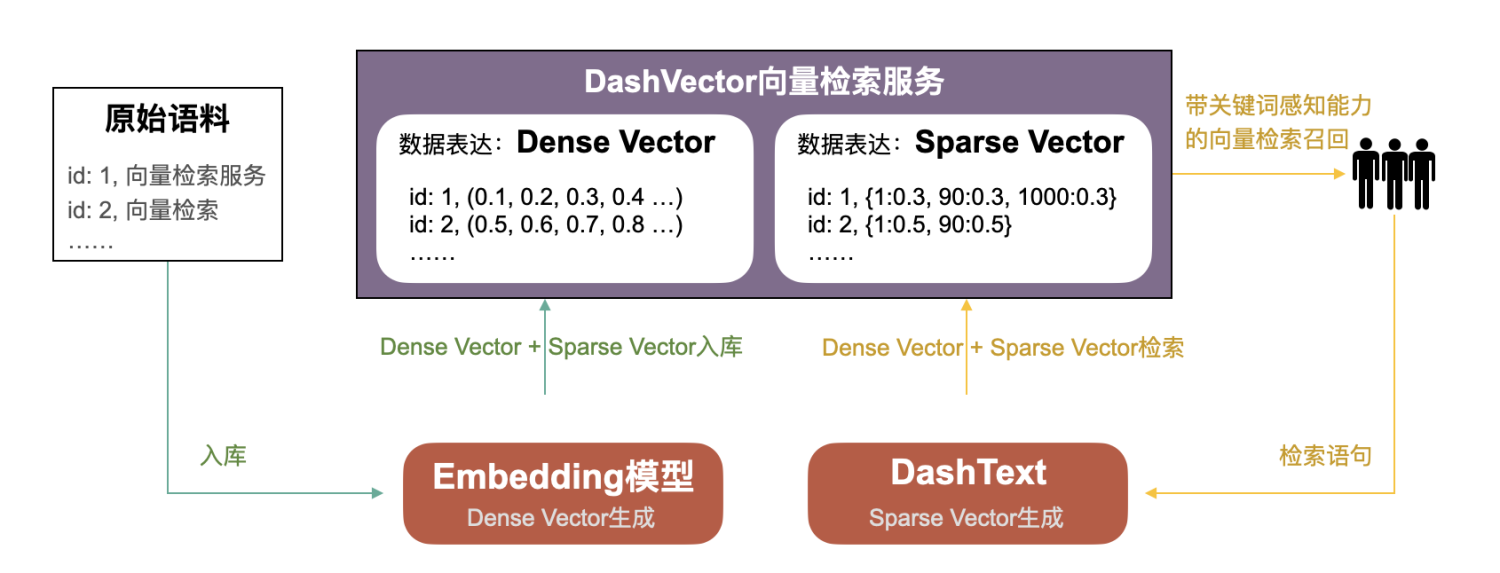
**说明**
Sparse Vector(稀疏向量),稀疏向量是指大部分元素为0,仅少量元素非0的向量。在DashVector中,稀疏向量可用来表示词频等信息。例如,`{1:0.4, 10000:0.6, 222222:0.8}`就是一个稀疏向量,其第1、10000、222222位元素(分别代表三个关键字)有非0值(代表关键字的权重),其他元素全部为0。
**使用示例**
-------------------------
### **前提条件**
* 已创建Cluste
* 已获得API-KEY
* 已安装最新版SDK
### Step1. 创建支持Sparse Vector的Collection
**说明**
1. 需要使用您的api-key替换以下示例中的 YOUR_API_KEY、您的Cluster Endpoint替换示例中的YOUR_CLUSTER_ENDPOINT,代码才能正常运行。
2. 本示例仅对Sparse Vector进行功能演示,简化起见,向量(Dense Vector)维度设置为4。
Python示例:
```python
import dashvector
client = dashvector.Client(
api_key='YOUR_API_KEY',
endpoint='YOUR_CLUSTER_ENDPOINT'
)
ret = client.create('hybrid_collection', dimension=4, metric='dotproduct')
collection = client.get('hybrid_collection')
assert collection
```
**重要**
仅内积度量(`metric='dotproduct'`)支持Sparse Vector功能。
### Step2. 插入带有Sparse Vector的Doc
Python示例:
```python
from dashvector import Doc
collection.insert(Doc(
id='A',
vector=[0.1, 0.2, 0.3, 0.4],
sparse_vector={1: 0.3, 10:0.4, 100:0.3}
))
```
**说明**
向量检索服务DashVector推荐使用快速开始生成Sparse Vector。
### **Step3.** 带有Sparse Vector的 **向量检索**
Python示例:
```python
docs = collection.query(
vector=[0.1, 0.1, 0.1, 0.1],
sparse_vector={1: 0.3, 20:0.7}
)
```
**Sparse Vector生成工具**
--------------------------------------
* DashText,向量检索服务DashVector推荐使用的SparseVectorEncoder
有疑问加站长微信联系(非本文作者))




