之前回答问题的时候Go还处在1.1版本,到了1.2和1.3,Go的GC跟踪命令和GC内部实现已经有一些变化,并且根据评论中的反馈,这边一并做补充说明。
Go 1.2之后的GC跟踪环境变量已经改为GODEBUG="gctrace=1",具体参数说明可以参考runtime包的文档。
Go 1.3对GC做了优化,回收机制也改变了,从我的实验观测来看,用做内存存储时候产生的持久性的大量对象,一样是明显拖慢GC暂停时间的,但是函数内创建的局部对象一旦没被引用,是会被立即回收的,可以用runtime.SetFinalizer()观测到这个现象,我利用这个现象在v8.go项目做了一个engine实例销毁的单元测试。
这里需要提醒大家,在平时开发或学习的时候gc是透明的,好像不存在一样,gc只在影响到业务的时候才会让人想起来有这样一个东西存在。
gc什么时候才会影响到业务呢?举个例子,比如业务需求是延迟不得大于100ms,当gc暂停超过100ms时,就明显影响到业务了。
而这篇回答针对的是gc影响的业务时的问题排查和优化方案,以及出问题前的提前自检。
请不要因为这篇帖子就误以为gc是很恐怖的。
接着补充一下我对技术分享的看法,有读者反馈一些描述比较容易误导新手,这当然不是我想看到的,技术分享本是好意,如果误导了新人就不好了。
为避免误会,这里说明一下,这个帖子的问题是“Go 的垃圾回收机制在实践中有哪些需要注意的地方?”,所以你正在阅读的这个答案是针对Go语言回答的,其中的一些经验和思路可以用在其他语言,但肯定是不能照搬的。
另外,语言表达的东西总是不那么严谨的,不同人可能产生不同理解,特别是对感受的描述,比如“多”、“少”、“大”、“小”、“长”、“短,这种没给出具体数值的描述,不同人可能有不同的理解,所以参考价值比较低。
所以,对于分享的内容中,比较模糊,比较难以界定,没给出具体数据的部分,希望能抛砖引玉,大家也来实验一下,补充更多数据。对于已经给定数据的部分,也希望大家不要看一下就过了,最好也能实验一下证明数据给的是对的,自己也才有直观感受,万一数据给错了,也才能通过众人之力修订正确。
我尽量在分享时提供方法,而不是纯感受或纯数据,希望可以众人拾柴火焰高,让后来者可以有更高的一个起点,不需要重新填坑,最后整个技术社区的水平能一起提升。
============= 原文 =============
不想看长篇大论的,这里先给个结论,go的gc还不完善但也不算不靠谱,关键看怎么用,尽量不要创建大量对象,也尽量不要频繁创建对象,这个道理其实在所有带gc的编程语言也都通用。
想知道如何提前预防和解决问题的,请耐心看下去。
先介绍下我的情况,我们团队的项目《仙侠道》在7月15号第一次接受玩家测试,这个项目的服务端完全用Go语言开发的,游戏数据都放在内存中由go 管理。
在上线测试后我对程序做了很多调优工作,最初是稳定性优先,所以先解决的是内存泄漏问题,主要靠memprof来定位问题,接着是进一步提高性能,主要靠cpuprof和自己做的一些统计信息来定位问题。
调优性能的过程中我从cpuprof的结果发现发现gc的scanblock调用占用的cpu竟然有40%多,于是我开始搞各种对象重用和尽量避免不必要的对象创建,效果显著,CPU占用降到了10%多。
但我还是挺不甘心的,想继续优化看看。网上找资料时看到GOGCTRACE这个环境变量可以开启gc调试信息的打印,于是我就在内网测试服开启了,每当go执行gc时就会打印一行信息,内容是gc执行时间和回收前后的对象数量变化。
我惊奇的发现一次gc要20多毫秒,我们服务器请求处理时间平均才33微秒,差了一个量级别呢。
于是我开始关心起gc执行时间这个数值,它到底是一个恒定值呢?还是更数据多少有关呢?
我带着疑问在外网玩家测试的服务器也开启了gc追踪,结果更让我冒冷汗了,gc执行时间竟然达到300多毫秒。go的gc是固定每两分钟执行一次,每次执行都是暂停整个程序的,300多毫秒应该足以导致可感受到的响应延迟。
所以缩短gc执行时间就变得非常必要。从哪里入手呢?首先,可以推断gc执行时间跟数据量是相关的,内网数据少外网数据多。其次,gc追踪信息把对象数量当成重点数据来输出,估计扫描是按对象扫描的,所以对象多扫描时间长,对象少扫描时间短。
于是我便开始着手降低对象数量,一开始我尝试用cgo来解决问题,由c申请和释放内存,这部分c创建的对象就不会被gc扫描了。
但是实践下来发现cgo会导致原有的内存数据操作出些诡异问题,例如一个对象明明初始化了,但还是读到非预期的数据。另外还会引起go运行时报申请内存死锁的错误,我反复读了go申请内存的代码,跟我直接用c的malloc完全都没关联,实在是很诡异。
我只好暂时放弃cgo的方案,另外想了个法子。一个玩家有很多数据,如果把非活跃玩家的数据序列化成一个字节数组,就等于把多个对象压缩成了一个,这样就可以大量减少对象数量。
我按这个思路用快速改了一版代码,放到外网实际测试,对象数量从几百万降至几十万,gc扫描时间降至二十几微秒。
效果不错,但是要用玩家数据时要反序列化,这个消耗太大,还需要再想办法。
于是我索性把内存数据都改为结构体和切片存放,之前用的是对象和单向链表,所以一条数据就会有一个对象对应,改为结构体和结构体切片,就等于把多个对象数据缩减下来。
结果如预期的一样,内存多消耗了一些,但是对象数量少了一个量级。
其实项目之初我就担心过这样的情况,那时候到处问人,对象多了会不会增加gc负担,导致gc时间过长,结果没得到答案。
现在我填过这个坑了,可以确定的说,会。大家就不要再往这个坑跳了。
如果go的gc聪明一点,把老对象和新对象区别处理,至少在我这个应用场景可以减少不必要的扫描,如果gc可以异步进行不暂停程序,我才不在乎那几百毫秒的执行时间呢。
但是也不能完全怪go不完善,如果一开始我早点知道用GOGCTRACE来观测,就可以比较早点发现问题从而比较根本的解决问题。但是既然用了,项目也上了,没办法大改,只能见招拆招了。
总结以下几点给打算用go开发项目或已经在用go开发项目的朋友:
1、尽早的用memprof、cpuprof、GCTRACE来观察程序。
2、关注请求处理时间,特别是开发新功能的时候,有助于发现设计上的问题。
3、尽量避免频繁创建对象(&abc{}、new(abc{})、make()),在频繁调用的地方可以做对象重用。
4、尽量不要用go管理大量对象,内存数据库可以完全用c实现好通过cgo来调用。
手机回复打字好累,先写到这里,后面再来补充案例的数据。
数据补充:
图1,7月22日的一次cpuprof观测,采样3000多次调用,数据显示scanblock吃了43.3%的cpu。
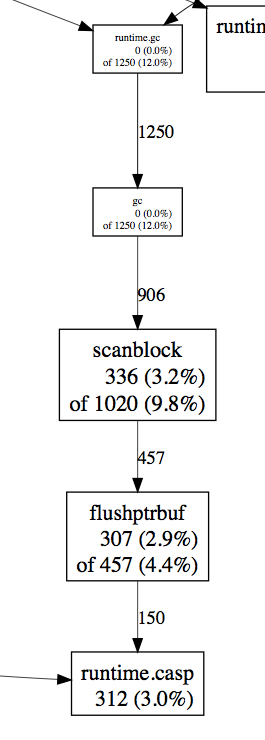
图2,7月23日,对修改后的程序做cpuprof,采样1万多次调用,数据显示cpu占用降至9.8%
数据1,外网服务器的第一次gc trace结果,数据显示gc执行时间有400多ms,回收后对象数量1659922个:
数据2,程序做了优化后的外网服务器gc trace结果,数据显示gc执行时间30多ms,回收后对象数量126097个:
示例1,数据结构的重构过程:
最初的数据结构类似这样
最初的设计会导致每个玩家有一个tables对象,每个tables对象里面有一堆类似tableA和tableC这样的一对一的数据,也有一堆类似tableB这样的一对多的数据。
假设有1万个玩家,每个玩家都有一条tableA和一条tableC的数据,又各有10条tableB的数据,那么将总的产生1w (tables) + 1w (tableA) + 1w (tableC) + 10w (tableB)的对象。
而实际项目中,表数量会有大几十,一对多和一对一的表参半,对象数量随玩家数量的增长倍数显而易见。
为什么一开始这样设计?
1、因为有的表可能没有记录,用对象的形式可以用 == nil 来判断是否有记录
2、一对多的表可以动态增加和删除记录,所以设计成链表
3、省内存,没数据就是没数据,有数据才有对象
改造后的设计:
一对一表用结构体,一对多表用slice,每个表都加一个_is_nil的字段,用来表示当前的数据是否是有用的数据。
这样修改的结果就是,一万个玩家,产生的对象总量是 1w (tables) + 1w ([]tablesB),跟之前的设计差别很明显。
但是slice不会收缩,而结构体则是一开始就占了内存,所以修改后会导致内存消耗增大。
参考链接:
go的gc代码,scanblock等函数都在里面:
http://golang.org/src/pkg/runtime/mgc0.c
go的runtime包文档有对GOGCTRACE等关键的几个环境变量做说明:
http://golang.org/pkg/runtime/
如何使用cpuprof和memprof,请看《Profiling Go Programs》:
http://blog.golang.org/profiling-go-programs
我做的一些小试验代码,优化都是基于这些试验的数据的,可以参考下:

Go 1.2之后的GC跟踪环境变量已经改为GODEBUG="gctrace=1",具体参数说明可以参考runtime包的文档。
Go 1.3对GC做了优化,回收机制也改变了,从我的实验观测来看,用做内存存储时候产生的持久性的大量对象,一样是明显拖慢GC暂停时间的,但是函数内创建的局部对象一旦没被引用,是会被立即回收的,可以用runtime.SetFinalizer()观测到这个现象,我利用这个现象在v8.go项目做了一个engine实例销毁的单元测试。
这里需要提醒大家,在平时开发或学习的时候gc是透明的,好像不存在一样,gc只在影响到业务的时候才会让人想起来有这样一个东西存在。
gc什么时候才会影响到业务呢?举个例子,比如业务需求是延迟不得大于100ms,当gc暂停超过100ms时,就明显影响到业务了。
而这篇回答针对的是gc影响的业务时的问题排查和优化方案,以及出问题前的提前自检。
请不要因为这篇帖子就误以为gc是很恐怖的。
接着补充一下我对技术分享的看法,有读者反馈一些描述比较容易误导新手,这当然不是我想看到的,技术分享本是好意,如果误导了新人就不好了。
为避免误会,这里说明一下,这个帖子的问题是“Go 的垃圾回收机制在实践中有哪些需要注意的地方?”,所以你正在阅读的这个答案是针对Go语言回答的,其中的一些经验和思路可以用在其他语言,但肯定是不能照搬的。
另外,语言表达的东西总是不那么严谨的,不同人可能产生不同理解,特别是对感受的描述,比如“多”、“少”、“大”、“小”、“长”、“短,这种没给出具体数值的描述,不同人可能有不同的理解,所以参考价值比较低。
所以,对于分享的内容中,比较模糊,比较难以界定,没给出具体数据的部分,希望能抛砖引玉,大家也来实验一下,补充更多数据。对于已经给定数据的部分,也希望大家不要看一下就过了,最好也能实验一下证明数据给的是对的,自己也才有直观感受,万一数据给错了,也才能通过众人之力修订正确。
我尽量在分享时提供方法,而不是纯感受或纯数据,希望可以众人拾柴火焰高,让后来者可以有更高的一个起点,不需要重新填坑,最后整个技术社区的水平能一起提升。
============= 原文 =============
不想看长篇大论的,这里先给个结论,go的gc还不完善但也不算不靠谱,关键看怎么用,尽量不要创建大量对象,也尽量不要频繁创建对象,这个道理其实在所有带gc的编程语言也都通用。
想知道如何提前预防和解决问题的,请耐心看下去。
先介绍下我的情况,我们团队的项目《仙侠道》在7月15号第一次接受玩家测试,这个项目的服务端完全用Go语言开发的,游戏数据都放在内存中由go 管理。
在上线测试后我对程序做了很多调优工作,最初是稳定性优先,所以先解决的是内存泄漏问题,主要靠memprof来定位问题,接着是进一步提高性能,主要靠cpuprof和自己做的一些统计信息来定位问题。
调优性能的过程中我从cpuprof的结果发现发现gc的scanblock调用占用的cpu竟然有40%多,于是我开始搞各种对象重用和尽量避免不必要的对象创建,效果显著,CPU占用降到了10%多。
但我还是挺不甘心的,想继续优化看看。网上找资料时看到GOGCTRACE这个环境变量可以开启gc调试信息的打印,于是我就在内网测试服开启了,每当go执行gc时就会打印一行信息,内容是gc执行时间和回收前后的对象数量变化。
我惊奇的发现一次gc要20多毫秒,我们服务器请求处理时间平均才33微秒,差了一个量级别呢。
于是我开始关心起gc执行时间这个数值,它到底是一个恒定值呢?还是更数据多少有关呢?
我带着疑问在外网玩家测试的服务器也开启了gc追踪,结果更让我冒冷汗了,gc执行时间竟然达到300多毫秒。go的gc是固定每两分钟执行一次,每次执行都是暂停整个程序的,300多毫秒应该足以导致可感受到的响应延迟。
所以缩短gc执行时间就变得非常必要。从哪里入手呢?首先,可以推断gc执行时间跟数据量是相关的,内网数据少外网数据多。其次,gc追踪信息把对象数量当成重点数据来输出,估计扫描是按对象扫描的,所以对象多扫描时间长,对象少扫描时间短。
于是我便开始着手降低对象数量,一开始我尝试用cgo来解决问题,由c申请和释放内存,这部分c创建的对象就不会被gc扫描了。
但是实践下来发现cgo会导致原有的内存数据操作出些诡异问题,例如一个对象明明初始化了,但还是读到非预期的数据。另外还会引起go运行时报申请内存死锁的错误,我反复读了go申请内存的代码,跟我直接用c的malloc完全都没关联,实在是很诡异。
我只好暂时放弃cgo的方案,另外想了个法子。一个玩家有很多数据,如果把非活跃玩家的数据序列化成一个字节数组,就等于把多个对象压缩成了一个,这样就可以大量减少对象数量。
我按这个思路用快速改了一版代码,放到外网实际测试,对象数量从几百万降至几十万,gc扫描时间降至二十几微秒。
效果不错,但是要用玩家数据时要反序列化,这个消耗太大,还需要再想办法。
于是我索性把内存数据都改为结构体和切片存放,之前用的是对象和单向链表,所以一条数据就会有一个对象对应,改为结构体和结构体切片,就等于把多个对象数据缩减下来。
结果如预期的一样,内存多消耗了一些,但是对象数量少了一个量级。
其实项目之初我就担心过这样的情况,那时候到处问人,对象多了会不会增加gc负担,导致gc时间过长,结果没得到答案。
现在我填过这个坑了,可以确定的说,会。大家就不要再往这个坑跳了。
如果go的gc聪明一点,把老对象和新对象区别处理,至少在我这个应用场景可以减少不必要的扫描,如果gc可以异步进行不暂停程序,我才不在乎那几百毫秒的执行时间呢。
但是也不能完全怪go不完善,如果一开始我早点知道用GOGCTRACE来观测,就可以比较早点发现问题从而比较根本的解决问题。但是既然用了,项目也上了,没办法大改,只能见招拆招了。
总结以下几点给打算用go开发项目或已经在用go开发项目的朋友:
1、尽早的用memprof、cpuprof、GCTRACE来观察程序。
2、关注请求处理时间,特别是开发新功能的时候,有助于发现设计上的问题。
3、尽量避免频繁创建对象(&abc{}、new(abc{})、make()),在频繁调用的地方可以做对象重用。
4、尽量不要用go管理大量对象,内存数据库可以完全用c实现好通过cgo来调用。
手机回复打字好累,先写到这里,后面再来补充案例的数据。
数据补充:
图1,7月22日的一次cpuprof观测,采样3000多次调用,数据显示scanblock吃了43.3%的cpu。
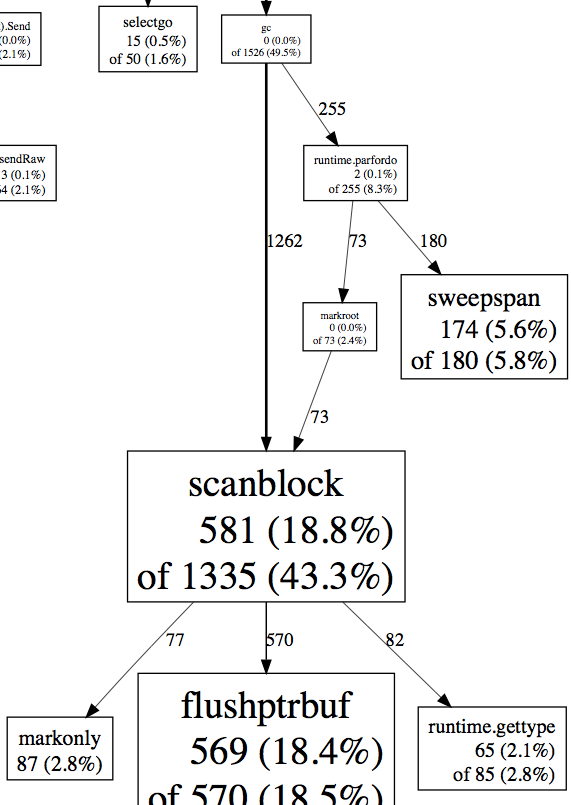
图2,7月23日,对修改后的程序做cpuprof,采样1万多次调用,数据显示cpu占用降至9.8%
数据1,外网服务器的第一次gc trace结果,数据显示gc执行时间有400多ms,回收后对象数量1659922个:
gc13(1): 308+92+1 ms , 156 -> 107 MB 3339834 -> 1659922 (12850245-11190323) objects, 0(0) handoff, 0(0) steal, 0/0/0 yields
数据2,程序做了优化后的外网服务器gc trace结果,数据显示gc执行时间30多ms,回收后对象数量126097个:
gc14(6): 16+15+1 ms, 75 -> 37 MB 1409074 -> 126097 (10335326-10209229) objects, 45(1913) handoff, 34(4823) steal, 455/283/52 yields
示例1,数据结构的重构过程:
最初的数据结构类似这样
// 玩家数据表的集合
type tables struct {
tableA *tableA
tableB *tableB
tableC *tableC
// ...... 此处省略一大堆表
}
// 每个玩家只会有一条tableA记录
type tableA struct {
fieldA int
fieldB string
}
// 每个玩家有多条tableB记录
type tableB struct {
xxoo int
ooxx int
next *tableB // 指向下一条记录
}
// 每个玩家只有一条tableC记录
type tableC struct {
id int
value int64
}
最初的设计会导致每个玩家有一个tables对象,每个tables对象里面有一堆类似tableA和tableC这样的一对一的数据,也有一堆类似tableB这样的一对多的数据。
假设有1万个玩家,每个玩家都有一条tableA和一条tableC的数据,又各有10条tableB的数据,那么将总的产生1w (tables) + 1w (tableA) + 1w (tableC) + 10w (tableB)的对象。
而实际项目中,表数量会有大几十,一对多和一对一的表参半,对象数量随玩家数量的增长倍数显而易见。
为什么一开始这样设计?
1、因为有的表可能没有记录,用对象的形式可以用 == nil 来判断是否有记录
2、一对多的表可以动态增加和删除记录,所以设计成链表
3、省内存,没数据就是没数据,有数据才有对象
改造后的设计:
// 玩家数据表的集合
type tables struct {
tableA tableA
tableB []tableB
tableC tableC
// ...... 此处省略一大堆表
}
// 每个玩家只会有一条tableA记录
type tableA struct {
_is_nil bool
fieldA int
fieldB string
}
// 每个玩家有多条tableB记录
type tableB struct {
_is_nil bool
xxoo int
ooxx int
}
// 每个玩家只有一条tableC记录
type tableC struct {
_is_nil bool
id int
value int64
}
一对一表用结构体,一对多表用slice,每个表都加一个_is_nil的字段,用来表示当前的数据是否是有用的数据。
这样修改的结果就是,一万个玩家,产生的对象总量是 1w (tables) + 1w ([]tablesB),跟之前的设计差别很明显。
但是slice不会收缩,而结构体则是一开始就占了内存,所以修改后会导致内存消耗增大。
参考链接:
go的gc代码,scanblock等函数都在里面:
http://golang.org/src/pkg/runtime/mgc0.c
go的runtime包文档有对GOGCTRACE等关键的几个环境变量做说明:
http://golang.org/pkg/runtime/
如何使用cpuprof和memprof,请看《Profiling Go Programs》:
http://blog.golang.org/profiling-go-programs
我做的一些小试验代码,优化都是基于这些试验的数据的,可以参考下:
go-labs/src at master · idada/go-labs · GitHub
转自:http://www.zhihu.com/question/21615032
有疑问加站长微信联系(非本文作者)



