转自 知乎
Go runtime的调度器:
在了解Go的运行时的scheduler之前,需要先了解为什么需要它,因为我们可能会想,OS内核不是已经有一个线程scheduler了嘛?熟悉POSIX API的人都知道,POSIX的方案在很大程度上是对Unix process进场模型的一个逻辑描述和扩展,两者有很多相似的地方。 Thread有自己的信号掩码,CPU affinity等。但是很多特征对于Go程序来说都是累赘。 尤其是context上下文切换的耗时。另一个原因是Go的垃圾回收需要所有的goroutine停止,使得内存在一个一致的状态。垃圾回收的时间点是不确定的,如果依靠OS自身的scheduler来调度,那么会有大量的线程需要停止工作。
单独的开发一个GO得调度器,可以是其知道在什么时候内存状态是一致的,也就是说,当开始垃圾回收时,运行时只需要为当时正在CPU核上运行的那个线程等待即可,而不是等待所有的线程。
用户空间线程和内核空间线程之间的映射关系有:N:1,1:1和M:N
N:1是说,多个(N)用户线程始终在一个内核线程上跑,context上下文切换确实很快,但是无法真正的利用多核。
1:1是说,一个用户线程就只在一个内核线程上跑,这时可以利用多核,但是上下文switch很慢。
M:N是说, 多个goroutine在多个内核线程上跑,这个看似可以集齐上面两者的优势,但是无疑增加了调度的难度。
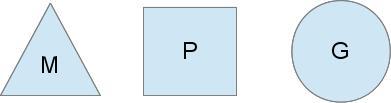
Go的调度器内部有三个重要的结构:M,P,S
M:代表真正的内核OS线程,和POSIX里的thread差不多,真正干活的人
G:代表一个goroutine,它有自己的栈,instruction pointer和其他信息(正在等待的channel等等),用于调度。
P:代表调度的上下文,可以把它看做一个局部的调度器,使go代码在一个线程上跑,它是实现从N:1到N:M映射的关键。

图中看,有2个物理线程M,每一个M都拥有一个context(P),每一个也都有一个正在运行的goroutine。
P的数量可以通过GOMAXPROCS()来设置,它其实也就代表了真正的并发度,即有多少个goroutine可以同时运行。
图中灰色的那些goroutine并没有运行,而是出于ready的就绪态,正在等待被调度。P维护着这个队列(称之为runqueue),
Go语言里,启动一个goroutine很容易:go function 就行,所以每有一个go语句被执行,runqueue队列就在其末尾加入一个
goroutine,在下一个调度点,就从runqueue中取出(如何决定取哪个goroutine?)一个goroutine执行。
为何要维护多个上下文P?因为当一个OS线程被阻塞时,P可以转而投奔另一个OS线程!
图中看到,当一个OS线程M0陷入阻塞时,P转而在OS线程M1上运行。调度器保证有足够的线程来运行所以的context P。
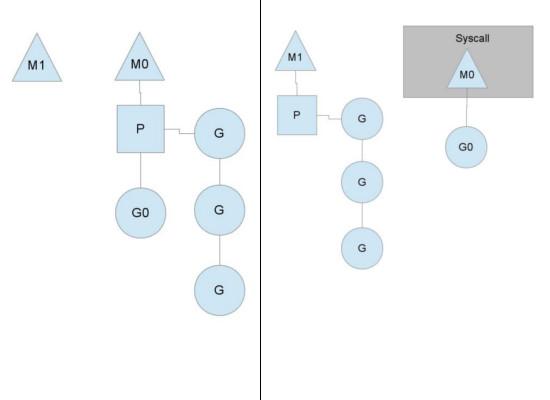
图中的M1可能是被创建,或者从线程缓存中取出。
当MO返回时,它必须尝试取得一个context P来运行goroutine,一般情况下,它会从其他的OS线程那里steal偷一个context过来,
如果没有偷到的话,它就把goroutine放在一个global runqueue里,然后自己就去睡大觉了(放入线程缓存里)。Contexts们也会周期性的检查global runqueue,否则global runqueue上的goroutine永远无法执行。
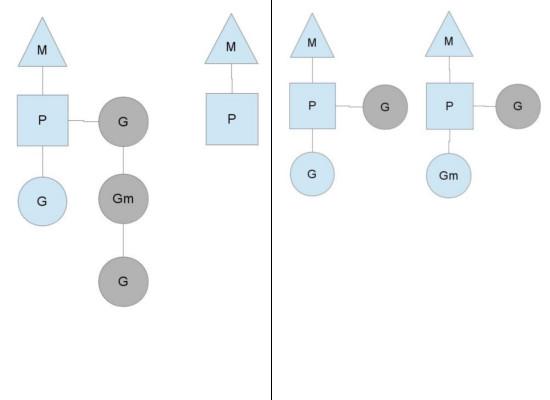
另一种情况是P所分配的任务G很快就执行完了(分配不均),这就导致了一个上下文P闲着没事儿干而系统却任然忙碌。但是如果global runqueue没有任务G了,那么P就不得不从其他的上下文P那里拿一些G来执行。一般来说,如果上下文P从其他的上下文P那里要偷一个任务的话,一般就‘偷’run queue的一半,这就确保了每个OS线程都能充分的使用。
另外,还有一篇类似文章。Here
我们都知道Go语言是原生支持语言级并发的,这个并发的最小逻辑单元就是goroutine。goroutine就是Go语言提供的一种用户态线程,当然这种用户态线程是跑在内核级线程之上的。当我们创建了很多的goroutine,并且它们都是跑在同一个内核线程之上的时候,就需要一个调度器来维护这些goroutine,确保所有的goroutine都使用cpu,并且是尽可能公平的使用cpu资源。
这个调度器的原理以及实现值得我们去深入研究一下。支撑整个调度器的主要有4个重要结构,分别是M、G、P、Sched,前三个定义在runtime.h中,Sched定义在proc.c中。
- Sched结构就是调度器,它维护有存储M和G的队列以及调度器的一些状态信息等。
- M代表内核级线程,一个M就是一个线程,goroutine就是跑在M之上的;M是一个很大的结构,里面维护小对象内存cache(mcache)、当前执行的goroutine、随机数发生器等等非常多的信息。
- P全称是Processor,处理器,它的主要用途就是用来执行goroutine的,所以它也维护了一个goroutine队列,里面存储了所有需要它来执行的goroutine,这个P的角色可能有一点让人迷惑,一开始容易和M冲突,后面重点聊一下它们的关系。
- G就是goroutine实现的核心结构了,G维护了goroutine需要的栈、程序计数器以及它所在的M等信息。
理解M、P、G三者的关系对理解整个调度器非常重要,我从网络上找了一个图来说明其三者关系:

地鼠(gopher)用小车运着一堆待加工的砖。M就可以看作图中的地鼠,P就是小车,G就是小车里装的砖。一图胜千言啊,弄清楚了它们三者的关系,下面我们就开始重点聊地鼠是如何在搬运砖块的。
启动过程
在关心绝大多数程序的内部原理的时候,我们都试图去弄明白其启动初始化过程,弄明白这个过程对后续的深入分析至关重要。在asm_amd64.s文件中的汇编代码_rt0_amd64就是整个启动过程,核心过程如下:
CALL runtime·args(SB)
CALL runtime·osinit(SB)
CALL runtime·hashinit(SB)
CALL runtime·schedinit(SB)
// create a new goroutine to start program
PUSHQ $runtime·main·f(SB) // entry
PUSHQ $0 // arg size
CALL runtime·newproc(SB)
POPQ AX
POPQ AX
// start this M
CALL runtime·mstart(SB)
启动过程做了调度器初始化runtime·schedinit后,调用runtime·newproc创建出第一个goroutine,这个goroutine将执行的函数是runtime·main,这第一个goroutine也就是所谓的主goroutine。我们写的最简单的Go程序”hello,world”就是完全跑在这个goroutine里,当然任何一个Go程序的入口都是从这个goroutine开始的。最后调用的runtime·mstart就是真正的执行上一步创建的主goroutine。
启动过程中的调度器初始化runtime·schedinit函数主要根据用户设置的GOMAXPROCS值来创建一批小车(P),不管GOMAXPROCS设置为多大,最多也只能创建256个小车(P)。这些小车(p)初始创建好后都是闲置状态,也就是还没开始使用,所以它们都放置在调度器结构(Sched)的pidle字段维护的链表中存储起来了,以备后续之需。
查看runtime·main函数可以了解到主goroutine开始执行后,做的第一件事情是创建了一个新的内核线程(地鼠M),不过这个线程是一个特殊线程,它在整个运行期专门负责做特定的事情——系统监控(sysmon)。接下来就是进入Go程序的main函数开始Go程序的执行。
至此,Go程序就被启动起来开始运行了。一个真正干活的Go程序,一定创建有不少的goroutine,所以在Go程序开始运行后,就会向调度器添加goroutine,调度器就要负责维护好这些goroutine的正常执行。
创建goroutine(G)
在Go程序中,时常会有类似代码:
go do_something()
go关键字就是用来创建一个goroutine的,后面的函数就是这个goroutine需要执行的代码逻辑。go关键字对应到调度器的接口就是runtime·newproc。runtime·newproc干的事情很简单,就负责制造一块砖(G),然后将这块砖(G)放入当前这个地鼠(M)的小车(P)中。
每个新的goroutine都需要有一个自己的栈,G结构的sched字段维护了栈地址以及程序计数器等信息,这是最基本的调度信息,也就是说这个goroutine放弃cpu的时候需要保存这些信息,待下次重新获得cpu的时候,需要将这些信息装载到对应的cpu寄存器中。
假设这个时候已经创建了大量的goroutne,就轮到调度器去维护这些goroutine了。
创建内核线程(M)
Go程序中没有语言级的关键字让你去创建一个内核线程,你只能创建goroutine,内核线程只能由runtime根据实际情况去创建。runtime什么时候创建线程?以地鼠运砖图来讲,砖(G)太多了,地鼠(M)又太少了,实在忙不过来,刚好还有空闲的小车(P)没有使用,那就从别处再借些地鼠(M)过来直到把小车(p)用完为止。这里有一个地鼠(M)不够用,从别处借地鼠(M)的过程,这个过程就是创建一个内核线程(M)。创建M的接口函数是:
void newm(void (*fn)(void), P *p)
newm函数的核心行为就是调用clone系统调用创建一个内核线程,每个内核线程的开始执行位置都是runtime·mstart函数。参数p就是一辆空闲的小车(p)。
每个创建好的内核线程都从runtime·mstart函数开始执行了,它们将用分配给自己小车去搬砖了。
调度核心
newm接口只是给新创建的M分配了一个空闲的P,也就是相当于告诉借来的地鼠(M)——“接下来的日子,你将使用1号小车搬砖,记住是1号小车;待会自己到停车场拿车。”,地鼠(M)去拿小车(P)这个过程就是acquirep。runtime·mstart在进入schedule之前会给当前M装配上P,runtime·mstart函数中的代码:
} else if(m != &runtime·m0) {
acquirep(m->nextp);
m->nextp = nil;
}
schedule();
if分支的内容就是为当前M装配上P,nextp就是newm分配的空闲小车(P),只是到这个时候才真正拿到手罢了。没有P,M是无法执行goroutine的,就像地鼠没有小车无法运砖一样的道理。对应acquirep的动作是releasep,把M装配的P给载掉;活干完了,地鼠需要休息了,就把小车还到停车场,然后睡觉去。
地鼠(M)拿到属于自己的小车(P)后,就进入工场开始干活了,也就是上面的schedule调用。简化schedule的代码如下:
static void
schedule(void)
{
G *gp;
gp = runqget(m->p);
if(gp == nil)
gp = findrunnable();
if (m->p->runqhead != m->p->runqtail &&
runtime·atomicload(&runtime·sched.nmspinning) == 0 &&
runtime·atomicload(&runtime·sched.npidle) > 0) // TODO: fast atomic
wakep();
execute(gp);
}
schedule函数被我简化了太多,主要是我不喜欢贴大段大段的代码,因此只保留主干代码了。这里涉及到4大步逻辑:

runqget, 地鼠(M)试图从自己的小车(P)取出一块砖(G),当然结果可能失败,也就是这个地鼠的小车已经空了,没有砖了。findrunnable, 如果地鼠自己的小车中没有砖,那也不能闲着不干活是吧,所以地鼠就会试图跑去工场仓库取一块砖来处理;工场仓库也可能没砖啊,出现这种情况的时候,这个地鼠也没有偷懒停下干活,而是悄悄跑出去,随机盯上一个小伙伴(地鼠),然后从它的车里试图偷一半砖到自己车里。如果多次尝试偷砖都失败了,那说明实在没有砖可搬了,这个时候地鼠就会把小车还回停车场,然后睡觉休息了。如果地鼠睡觉了,下面的过程当然都停止了,地鼠睡觉也就是线程sleep了。wakep, 到这个过程的时候,可怜的地鼠发现自己小车里有好多砖啊,自己根本处理不过来;再回头一看停车场居然有闲置的小车,立马跑到宿舍一看,你妹,居然还有小伙伴在睡觉,直接给屁股一脚,“你妹,居然还在睡觉,老子都快累死了,赶紧起来干活,分担点工作。”,小伙伴醒了,拿上自己的小车,乖乖干活去了。有时候,可怜的地鼠跑到宿舍却发现没有在睡觉的小伙伴,于是会很失望,最后只好向工场老板说——”停车场还有闲置的车啊,我快干不动了,赶紧从别的工场借个地鼠来帮忙吧。”,最后工场老板就搞来一个新的地鼠干活了。execute,地鼠拿着砖放入火种欢快的烧练起来。
注: “地鼠偷砖”叫work stealing,一种调度算法。
到这里,貌似整个工场都正常的运转起来了,无懈可击的样子。不对,还有一个疑点没解决啊,假设地鼠的车里有很多砖,它把一块砖放入火炉中后,何时把它取出来,放入第二块砖呢?难道要一直把第一块砖烧练好,才取出来吗?那估计后面的砖真的是等得花儿都要谢了。这里就是要真正解决goroutine的调度,上下文切换问题。
调度点
当我们翻看channel的实现代码可以发现,对channel读写操作的时候会触发调用runtime·park函数。goroutine调用park后,这个goroutine就会被设置位waiting状态,放弃cpu。被park的goroutine处于waiting状态,并且这个goroutine不在小车(P)中,如果不对其调用runtime·ready,它是永远不会再被执行的。除了channel操作外,定时器中,网络poll等都有可能park goroutine。
除了park可以放弃cpu外,调用runtime·gosched函数也可以让当前goroutine放弃cpu,但和park完全不同;gosched是将goroutine设置为runnable状态,然后放入到调度器全局等待队列(也就是上面提到的工场仓库,这下就明白为何工场仓库会有砖块(G)了吧)。
除此之外,就轮到系统调用了,有些系统调用也会触发重新调度。Go语言完全是自己封装的系统调用,所以在封装系统调用的时候,可以做不少手脚,也就是进入系统调用的时候执行entersyscall,退出后又执行exitsyscall函数。 也只有封装了entersyscall的系统调用才有可能触发重新调度,它将改变小车(P)的状态为syscall。还记一开始提到的sysmon线程吗?这个系统监控线程会扫描所有的小车(P),发现一个小车(P)处于了syscall的状态,就知道这个小车(P)遇到了goroutine在做系统调用,于是系统监控线程就会创建一个新的地鼠(M)去把这个处于syscall的小车给抢过来,开始干活,这样这个小车中的所有砖块(G)就可以绕过之前系统调用的等待了。被抢走小车的地鼠等系统调用返回后,发现自己的车没,不能继续干活了,于是只能把执行系统调用的goroutine放回到工场仓库,自己睡觉去了。
从goroutine的调度点可以看出,调度器还是挺粗暴的,调度粒度有点过大,公平性也没有想想的那么好。总之,这个调度器还是比较简单的。
现场处理
goroutine在cpu上换入换出,不断上下文切换的时候,必须要保证的事情就是保存现场和恢复现场,保存现场就是在goroutine放弃cpu的时候,将相关寄存器的值给保存到内存中;恢复现场就是在goroutine重新获得cpu的时候,需要从内存把之前的寄存器信息全部放回到相应寄存器中去。
goroutine在主动放弃cpu的时候(park/gosched),都会涉及到调用runtime·mcall函数,此函数也是汇编实现,主要将goroutine的栈地址和程序计数器保存到G结构的sched字段中,mcall就完成了现场保存。恢复现场的函数是runtime·gogocall,这个函数主要在execute中调用,就是在执行goroutine前,需要重新装载相应的寄存器。
版权声明:本文为博主原创文章,未经博主允许不得转载。
有疑问加站长微信联系(非本文作者)




