商业转载请联系作者获得授权,非商业转载请注明出处。
链接:http://www.zhihu.com/question/20862617
来源:知乎
12 个回答

Go runtime的调度器:
在了解Go的运行时的scheduler之前,需要先了解为什么需要它,因为我们可能会想,OS内核不是已经有一个线程scheduler了嘛?
熟悉POSIX API的人都知道,POSIX的方案在很大程度上是对Unix process进场模型的一个逻辑描述和扩展,两者有很多相似的地方。 Thread有自己的信号掩码,CPU affinity等。但是很多特征对于Go程序来说都是累赘。 尤其是context上下文切换的耗时。另一个原因是Go的垃圾回收需要所有的goroutine停止,使得内存在一个一致的状态。垃圾回收的时间点是不确定的,如果依靠OS自身的scheduler来调度,那么会有大量的线程需要停止工作。
单独的开发一个GO得调度器,可以是其知道在什么时候内存状态是一致的,也就是说,当开始垃圾回收时,运行时只需要为当时正在CPU核上运行的那个线程等待即可,而不是等待所有的线程。
用户空间线程和内核空间线程之间的映射关系有:N:1,1:1和M:N
N:1是说,多个(N)用户线程始终在一个内核线程上跑,context上下文切换确实很快,但是无法真正的利用多核。
1:1是说,一个用户线程就只在一个内核线程上跑,这时可以利用多核,但是上下文switch很慢。
M:N是说, 多个goroutine在多个内核线程上跑,这个看似可以集齐上面两者的优势,但是无疑增加了调度的难度。
Go的调度器内部有三个重要的结构:M,P,S
M:代表真正的内核OS线程,和POSIX里的thread差不多,真正干活的人
G:代表一个goroutine,它有自己的栈,instruction pointer和其他信息(正在等待的channel等等),用于调度。
P:代表调度的上下文,可以把它看做一个局部的调度器,使go代码在一个线程上跑,它是实现从N:1到N:M映射的关键。

图中看,有2个物理线程M,每一个M都拥有一个context(P),每一个也都有一个正在运行的goroutine。
P的数量可以通过GOMAXPROCS()来设置,它其实也就代表了真正的并发度,即有多少个goroutine可以同时运行。
图中灰色的那些goroutine并没有运行,而是出于ready的就绪态,正在等待被调度。P维护着这个队列(称之为runqueue),
Go语言里,启动一个goroutine很容易:go function 就行,所以每有一个go语句被执行,runqueue队列就在其末尾加入一个
goroutine,在下一个调度点,就从runqueue中取出(如何决定取哪个goroutine?)一个goroutine执行。
为何要维护多个上下文P?因为当一个OS线程被阻塞时,P可以转而投奔另一个OS线程!
图中看到,当一个OS线程M0陷入阻塞时,P转而在OS线程M1上运行。调度器保证有足够的线程来运行所以的context P。
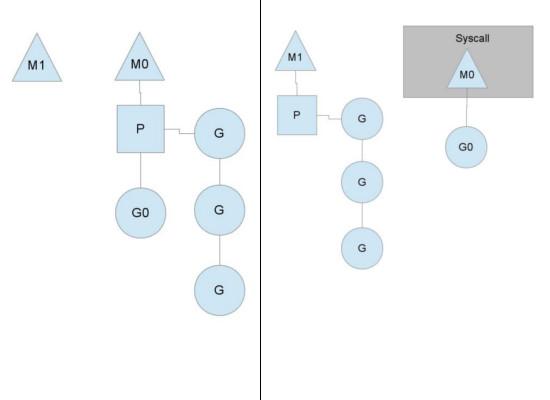
图中的M1可能是被创建,或者从线程缓存中取出。
当MO返回时,它必须尝试取得一个context P来运行goroutine,一般情况下,它会从其他的OS线程那里steal偷一个context过来,
如果没有偷到的话,它就把goroutine放在一个global runqueue里,然后自己就去睡大觉了(放入线程缓存里)。Contexts们也会周期性的检查global runqueue,否则global runqueue上的goroutine永远无法执行。
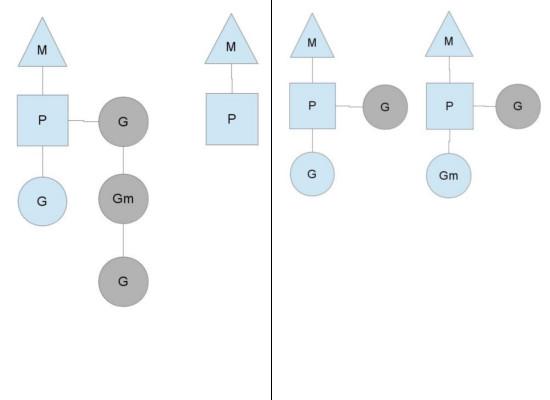
另一种情况是P所分配的任务G很快就执行完了(分配不均),这就导致了一个上下文P闲着没事儿干而系统却任然忙碌。但是如果global runqueue没有任务G了,那么P就不得不从其他的上下文P那里拿一些G来执行。一般来说,如果上下文P从其他的上下文P那里要偷一个任务的话,一般就‘偷’run queue的一半,这就确保了每个OS线程都能充分的使用。
《go中的调度分析》
《goroutine背后的系统知识》
还有一个是Columbia University的三个家伙发表的一篇paper,
《Analysis of the Go runtime scheduler》
最后还有Golang核心成员写一个Goroutine Scheduler的设计。《 Scalable Go Scheduler Design Doc》以及对其详细解释的《The Go scheduler》
Goroutines are part of making concurrency easy to use. The idea, which has been around for a while, is to multiplex independently executing functions—coroutines—onto a set of threads. When a coroutine blocks, such as by calling a blocking system call, the run-time automatically moves other coroutines on the same operating system thread to a different, runnable thread so they won't be blocked. The programmer sees none of this, which is the point. The result, which we call goroutines, can be very cheap: unless they spend a lot of time in long-running system calls, they cost little more than the memory for the stack, which is just a few kilobytes.
To make the stacks small, Go's run-time uses segmented stacks. A newly minted goroutine is given a few kilobytes, which is almost always enough. When it isn't, the run-time allocates (and frees) extension segments automatically. The overhead averages about three cheap instructions per function call. It is practical to create hundreds of thousands of goroutines in the same address space. If goroutines were just threads, system resources would run out at a much smaller number.
----------------- 我是分割线----------------------------------
我对goroutine的理解类似于C/C++下常用的线程池技术。但是goroutine要在这基础上大大的前进了好多。首先,go关键字极大的简化了C/C++下往线程池投递任务的操作。虽然C++11引入了lambda,但是因为没有GC的缘故用起来还是稍微蛋疼的。其次就是goroutine的调度器解决了一般线程池常见的问题,就是遇到阻塞或者同步动作时,怎么让线程池更容易扩展,不会因为其中一个任务的阻塞或者同步独占线程,甚至怎么避免由此问题带来的死锁。而在C/C++语言里,想做到这点非常的困难,没有类似Golang的runtime,做起来会非常痛苦。 Golang在这点上做的也是非常的漂亮。发起的同步或者channel动作,哪怕网络操作,都会把自身goroutine切换出去,让下一个预备好的goroutine去运行。而且Golang其本身还在此基础上很容易的做到对线程池的扩展,根据程序行为自动扩展或者收缩线程,尽可能的让线程保持在一个合适的数目。

但是线程又老贵了,花不起那个钱,所以go发明了goroutine。大致就是说给每个goroutine弄一个分配在heap里面的栈来模拟线程栈。比方说有3个goroutine,A,B,C,就在heap上弄三个栈出来。然后Go让一个单线程的scheduler开始跑他们仨。相当于 { A(); B(); C() },连续的,串行的跑。
和操作系统不太一样的是,操作系统可以随时随地把你线程停掉,切换到另一个线程。这个单线程的scheduler没那个能力啊,他就是user space的一段朴素的代码,他跑着A的时候控制权是在A的代码里面的。A自己不退出谁也没办法。
所以A跑一小段后需要主动说,老大(scheduler),我不想跑了,帮我把我的所有的状态保存在我自己的栈上面,让我歇一会吧。这时候你可以看做A返回了。A返回了B就可以跑了,然后B跑一小段说,跑够了,保存状态,返回,然后C再跑。C跑一段也返回了。
这样跑完{A(); B(); C()}之后,我们发现,好像他们都只跑了一小段啊。所以外面要包一个循环,大致是:
goroutine_list = [A, B, C]
while(goroutine):
for goroutine in goroutine_list:
r = goroutine()
if r.finished():
goroutine_list.remove(r)
def A:
上次跑到的地方 = 找到上次跑哪儿了
读取所有临时变量
goto 上次跑到的地方
a = 1
print("do something")
go.scheduler.保存程序指针 // 设置"这次跑哪儿了"
go.scheduler.保存临时变量们
go.scheduler.跑够了_换人 //相当于return
print("do something again")
print(a)
所以你看出来了,这个关键就在于每个goroutine跑一跑就要让一让。一般支持这种玩意(叫做coroutine)的语言都是让每个coroutine自己说,我跑够了,换人。goroutine比较文艺的地方就在于,他可以来帮你判断啥时候“跑够了”。
其中有一大半就是靠的你说的“异步并发”。go把每一个能异步并发的操作,像你说的文件访问啦,网络访问啦之类的都包包好,包成一个看似朴素的而且是同步的“方法”,比如string readFile(我瞎举得例子)。但是神奇的地方在于,这个方法里其实会调用“异步并发”的操作,比如某操作系统提供的asyncReadFile。你也知道,这种异步方法都是很快返回的。
所以你自己在某个goroutine里写了
string s = go.file.readFile("/root")
其实go偷偷在里面执行了某操作系统的API asyncReadFIle。跑起来之后呢,这个方法就会说,我当前所在的goroutine跑够啦,把刚刚跑的那个异步操作的结果保存下下,换人:
// 实际上
handler h = someOS.asyncReadFile("/root") //很快返回一个handler
while (!h.finishedAsyncReadFile()): //很快返回Y/N
go.scheduler.保存现状()
go.scheduler.跑够了_换人() // 相当于return,不过下次会从这里的下一句开始执行
string s = h.getResultFromAsyncRead()
然后scheduler就换下一个goroutine跑了。等下次再跑回刚才那个goroutine的时候,他就看看,说那个asyncReadFile到底执行完没有啊,如果没有,就再换个人吧。如果执行完了,那就把结果拿出来,该干嘛干嘛。所以你看似写了个同步的操作,已经被go替换成异步操作了。
还有另外一种情况是,某个goroutine执行了某个不能异步调用的会blocking的系统调用,这个时候goroutine就没法玩那种异步调用的把戏了。他会把你挪到一个真正的线程里让你在那个县城里等着,他接茬去跑别的goroutine。比如A这么定义
def A:
print("do something")
go.os.InvokeSomeReallyHeavyAndBlockingSystemCall()
print("do something 2")
def 真实的A:
print("do something")
Thread t = new Thread( () => {
SomeReallyHeavyAndBlockingSystemCall();
})
t.start()
while !t.finished():
go.scheduler.保存现状
go.scheduler.跑够了_换人
print("finished")
当然会有一种情况就是A完全没有调用任何可能的“异步并发”的操作,也没有调用任何的同步的系统调用,而是一个劲的用CPU做运算(比如用个死循环调用a++)。在早期的go里,这个A就把整个程序block住了。后面新版本的go好像会有一些处理办法,比如如果你A里面call了任意一个别的函数的话,就有一定几率被踢下去换人。好像也可以自己主动说我要换人的,可以去查查新的go的spec
另外,请不要在意语言细节,技术细节。会意即可
其实实现原理很简单,就是利用C(嵌入汇编)语言可以直接修改寄存器(setcontext/setjmp/longjmp均是类似原理,修改程序指针eip实现跳转,栈指针实现上线文切换)来实现从func_a调进去,从func_b返回出来这种行为。对于golang来说,func_a/func_b属于不同的goroutine,从而就实现了goroutine的调度切换。
另外对于所有可能阻塞的syscall,golang对其进行了封装,底层实际是epoll方式做的,注册回调后切换到另一个runnable的goroutine。
源代码可参考libtask的实现,golang原理类似:
libtask/asm.S at master 路 llhe/libtask 路 GitHub
libtask/fd.c at master 路 llhe/libtask 路 GitHub
 知乎用户,有小聪明,无大智慧
知乎用户,有小聪明,无大智慧一、go 内部有三个对象: P对象(processor) 代表cpu,M(work thread)代表工作线程,G对象(goroutine).
二、正常情况下一个cpu对象启一个工作线程对象,线程去检查并执行goroutine对象。碰到goroutine对象阻塞的时候,会启动一个新的工作线程,以充分利用cpu资源。所有有时候线程对象会比处理器对象多很多。
三、go大部分栈信息存在goroutine中,线程之间切换速度很快,成本很低(介于线程和协程之间)。
有疑问加站长微信联系(非本文作者)




