1NoSQL简述
CAP(Consistency,Availabiity,Partitiontolerance)理论告诉我们,一个分布式系统不可能满足一致性,可用性和分区容错性这三个需求,最多只能同时满足两个。关系型数据库通过把更新操作写到事务型日志里实现了部分耐用性,但带来的是写性能的下降。MongoDB等NoSQL数据库背后蕴涵的哲学是不同的平台应该使用不同类型的数据库,MongoDB通过降低一些特性来达到性能的提高,这在很多大型站点中是可行的。因为MongoDB是非原子性的,所以如果如果应用需要事务,还是需要选择MySQL等关系数据库。
NoSQL数据库,顾名思义就是打破了传统关系型数据库的范式约束。很多NoSQL数据库从数据存储的角度看也不是关系型数据库,而是key-value数据格式的hash数据库。由于放弃了关系数据库强大的SQL查询语言和事务一致性以及范式约束,NoSQL数据库在很大程度上解决了传统关系型数据库面临的诸多挑战。
在社区中,NoSQL是指“notonly sql”,其特点是非关系型,分布式,开源,可水平扩展,模式自由,支持replication,简单的API,最终一致性(相对于即时一致性,最终一致性允许有一个“不一致性窗口”,但能保证最终的客户都能看到最新的值)。
2MongoDB简介
mongo取自“humongous”(海量的),是开源的文档数据库──nosql数据库的一种。
MongoDB是一种面向集合(collection)的,模式自由的文档(document)数据库。
面向集合是说数据被分成集合的形式,每个集合在数据库中有惟一的名称,集合可以包含不限数目的文档。除了模式不是预先定义好的,集合与RDBMS中的表概念类似,虽然二者并不是完全对等。数据库和集合的创建是“lazy”的,即只有在第一个document被插入时集合和数据库才真正创建——这时在磁盘的文件系统里才能看见。
模式自由是说数据库不需要知道存放在集合中的文档的结构,完全可以在同一个集合中存放不同结构的文档,支持嵌入子文档。
文档类似于RDBMS中的记录,以BSON的格式保存。BSON是BinaryJSON的简称,是对JSON-like文档的二进制编码序列化。像JSON(JavaScriptObject Notation)一样,BSON支持在对象和数组内嵌入其它的对象和数组。有些数据类型在JSON里不能表示,但可以在BSON里表示,如Date类型和BinData(二进制数据),Python原生的类型都可以表示。与ProtocalBuffers(Google开发的用以处理对索引服务器请求/应答的协议)相比,BSON模式更自由,所以更灵活,但这样也使得每个文档都要保存字段名,所以空间压缩上不如ProtocolBuffers。
BSON第一眼看上去像BLOB,但MongoDB理解BSON的内部机制,所以MongoDB可以深入BSON对象的内部,即使是嵌套的对象,这样MongoDB就可以在顶层和嵌套的BSON对象上建立索引来应对各种查询了。
MongoDB可运行在Linux、Windows和OSX平台,支持32位和64位应用,默认端口为27017。推荐运行在64位平台,因为MongoDB为了提高性能使用了内存映射文件进行数据管理,而在32位模式运行时支持的最大文件为2GB。
MongoDB查询速度比MySQL要快,因为它cache了尽可能多的数据到RAM中,即使是non-cached数据也非常快。当前MongoDB官方支持的客户端API语言就多达8种(C|C++|Java|Javascript|Perl|PHP|Python|Ruby),社区开发的客户端API还有Erlang、Go、Haskell......
3术语介绍
数据库、集合、文档
每个MongoDB服务器可以有多个数据库,每个数据库都有可选的安全认证。数据库包括一个或多个集合,集合以命名空间的形式组织在一起,用“.”隔开(类似于JAVA/Python里面的包),比如集合blog.posts和blog.authors都处于"blog"下,不会与bbs.authors有名称上的冲突。集合里的数据由多个BSON格式的文档对象组成,document的命名有一些限定,如字段名不能以"$"开头,不能有".",名称"_id"被保留为主键。
如果插入的文档没有提供“_id”字段,数据库会为文档自动生成一个ObjectId对象作为“_id”的值插入到集合中。字段“_id”的值可以是任意类型,只要能够保证惟一性。BSONObjectID是一个12字节的值,包括4字节的时间戳,3字节的机器号,2字节的进程id以及3字节的自增计数。建议用户还是使用有意义的“_id”值。
MongoDb相比于传统的SQL关系型数据库,最大的不同在于它们的模式设计(SchemaDesign)上的差别,正是由于这一层次的差别衍生出其它各方面的不同。
如果将关系数据库简单理解为由数据库、表(table)、记录(record)三个层次概念组成,而在构建一个关系型数据库的时候,工作重点和难点都在数据库表的划分与组织上。一般而言,为了平衡提高存取效率与减少数据冗余之间的矛盾,设计的数据库表都会尽量满足所谓的第三范式。相应的,可以认为MongoDb由数据库、集合(collection)、文档对象(Document-oriented、BSON)三个层次组成。MongoDb里的collection可以理解为关系型数据库里的表,虽然二者并不完全对等。当然,不要期望collection会满足所谓的第三范式,因为它们根本就不在同一个概念讨论范围之内。类似于表由多条记录组成,集合也包含多个文档对象,虽然说一般情况下,同一个集合内的文档对象具有相同的格式定义,但这并不是必须的,即MongoDb的数据模式是自由的(schema-free、模式自由、无模式),collection中可以包含具有不同schema的文档记录,支持嵌入子文档。
4MongoDB资源消耗
考虑到性能的原因,mongo做了很多预分配,包括提前在文件系统中为每个数据库分配逐渐增长大小的文件集。这样可以有效地避免潜在的文件系统碎片,使数据库操作更高效。
一个数据库的文件集从序号0开始分配,0,1...,大小依次是64M,128M,256M,512M,1G,2G,然后就是一直2G的创建下去(32位系统最大到512M)。所以如果上一个文件是1G,而数据量刚好超过1G,则下一个文件(大小为2G)则可能有超过90%都是空的。
如果想使磁盘利用更有效率,下面是一些解决方法:
1. 只建立一个数据库,这样最多只会浪费2G。
2. 每个文档使用自建的“_id”值而不要使用默认的ObjectId对象。
3. 由于每个document的每个字段名都会存放,所以如果字段名越长,document的数据占用就会越大,因此把字段名缩短会大大降低数据的占用量。如把“timeAdded”改为“tA”。
Mongo使用内存映射文件来访问数据,在执行插入等操作时,观察mongod进程的内存占用时会发现量很大,当使用内存映射文件时是正常的。并且映射数据的大小只出现在虚拟内存那一列,常驻内存量才反应出有多少数据cached在内存中。
【按照mongodb官方的说法,mongodb完全由系统内核进行内存管理,会尽可能的占用系统空闲内存,用free可以看到,大部分内存都是作为iocache被占用的,而这部分内存是可以释放出来给应用使用的。】
5交互式shell
mongo类似于MySQL中的mysql进程,但功能远比mysql强大,它可以使用JavaScript语法的命令从交互式shell中直接操作数据库。如查看数据库中的内容,使用游标循环查看查询结果,创建索引,更改及删除数据等数据库管理功能。下面是一个在mongo中使用游标的例子:
> for(var cur= db.posts.find(); cur.hasNext();) { ...print(tojson(cur.next())); ... } |
输出:
{ "_id" :ObjectId("4bb311164a4a1b0d84000000"), "date" : "Wed Mar 3117:05:23 2010", "content" :"blablablabla", "author" :"navygong", "title" : "the firstblog" } |
...其它的documents。
6一般功能
6.1插入
客户端把数据序列化为BSON格式传给DB后被存储在磁盘上,在读取时数据库几乎不做什么改动直接把对象返回给客户端,由client完成unserialized。如:
> doc ={'author': 'joe', 'created': new Date('2010, 6, 21'), 'title':'Yet another blogpost', 'text': 'Here is the text...', 'tags': ['example', 'joe'], 'comments':[{'author': 'jim', 'comment': 'I disgree'}, {'author': 'navy', 'comment': 'Goodpost'}], '_id': 'test_id'}
>db.posts.insert(doc)
6.2查询
基本上你能想到的查询种类MongoDB都支持,如等值匹配,<,<=,>,>=,$ne,$in,$mod,$all,$size[1],$exists,$type[2],正则表达式匹配,全文搜索,......。还有distinct(),sort(),count(),skip()[3],group()[4],......。这里列表的查询中很多用法都和一般的RDBMS不同。
[1]匹配一个有size个元素的数组。如db.things.find({a:{$size: 1}})能够匹配文档{a:["foo"]}。
[2] 根据类型匹配。db.things.find({a: {$type : 16}})能够匹配所有a为int类型的文档。BSON协议中规定了各种类型对应的枚举值。
[3]指定跳过多少个文档后开始返回结果,可以用在分页中。如:db.students.find().skip((pageNumber-1)*nPerPage).limit(nPerPage).forEach(function(student) { print(student.name + "<p>"); } )。
[4] 在shardedMongoDB配置环境中应该应该使用map/reduce来代替group()。
6.3删除
可以像查询一样指定条件来删除特定的文档。
6.4索引
可以像在一般的RDBMS中一样使用索引。提供了建立(一般、惟一、组合)索引、删除索引、重建索引等各种方法。索引信息保存在集合“system.indexes”中。
6.5map/reduce
MongoDB提供了map/reduce方法来进行数据的批处理及聚集操作。和Hadoop的使用类似,从集合中接收输入,结果输出到另一个集合。如果你需要使用group,map/reduce会是个不错的选择。但MongoDB中的索引和标准查询不是使用map/reduce,而是与MySQL相似。
7模式设计
Mongo式的模式设计
使用Mongo有很多种方式,你本能上可能会像使用关系型数据库一样去使用。当然这样也可以工作得很好,但却没能发挥出Mongo的真正威力。Monog是专门设计为富对象模型(richobject model)使用的。
例如:如果你建立了一个简单的在线商店并且把产品信息存储在关系型数据库中,那你可能会有两个像这样的表:
item
title | price | sku |
item_features
sku | feature_name | feature_value |
你进行了范式处理因为不同的物品有不同的特征,这样你不用建立一个包含所有特征的表了。在Mongo中你也可以像上面那样建立两个集合,但像下面这样存储每种物品会更有效。
item : { "title" : <title> , "price" : <price> , "sku" : <sku> , "features" : { "optical zoom" : <value> , ... } } |
因为只要查询一个集合就能取得一件物品的所有信息,而这些信息都保存在磁盘上同一个地方,因此大大提高了查询的速度。如果你想插入或更新一种特征,如db.items.update({ sku : 123 } , { "$set" : { "features.zoom" :"5" } } ),也不必在磁盘上移动整个对象,因为Mongo为每个对象在磁盘上预留了空间来适应对象的增长。
8嵌入与引用
以一实例来说,假设需要设计一个小型数据库来存储“学生、地址、科目、成绩”这些信息,那么关系型数据库的设计如图1所示,而key-value型数据库的设计则可能如图2所示。
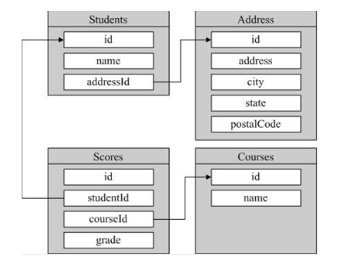
图1关系型的数据库设计
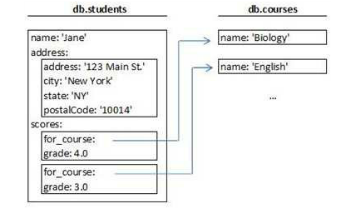
图2key-value型的数据库设计
对比图1和图2,在关系型的数据库设计里划分出了4个表,而在key-value型的数据库设计里却只有两个集合。如果说集合与表一一对应的话,那么图2中应该也有4个集合才对,把本应该是集合的address和scores直接合入了集合students中,原因在于在key-value型的数据库里,数据模式是自由的。
以scores来说,在关系型的数据库设计中将其单独成一个表是因为student与score是一对多的关系,如果将score合入student表,那么就必须预留最多可能的字段,这会存在浪费,并且当以后新增一门课程时扩展困难,因此一般都会将score表单独出来。而对于key-value型的数据库就不同了,其scores字段就是一个BSON,该BSON可以只有一个for_course,也可以有任意多个for_course,其固有的模式自由特性使得它可以将score包含在内而无需另建一个score集合。
对于与student为一对一关系的address表也可以直接合入student,无需担心address的扩展性,当以后需要给address新增一个province字段,直接在数据插入时加上这个值即可。
当然,对于与student成多对多关系course表,为了减少数据冗余,可以将course建立为一个集合,同关系型的数据库设计中类似。
students文档中嵌入了address文档和scores文档,scores文档的“for_course”字段的值是指向courses集合的文档的引用。如果是关系型数据库,需要把“scores”作为一个单独的表,然后在students表中建立一个指向“scores”的外键。所以Mongo模式设计中的一个关键问题就是“是值得为这个对象新建一个集合呢,还是把这个对象嵌入到其它的集合中”。在关系型数据库中为了范式的要求,每个子项都要建一个单独的表,但在Mongo中使用嵌入式对象更有效,所以你应该给出不使用嵌入式对象而单独建一个集合的理由。
为什么说引用要慢些呢,以上面的students集合为例,比如执行:
print(student.scores[0].for_course.name );
如果这是第一次访问scores[0],那些客户端必须执行:
student.scores[0].for_course= db.courses.findOne({_id:_course_id_to_find_}); //伪代码
所以每一次遍历引用都要对数据库进行一次这样的查询,即使所有的数据都在内存中。再考虑到从客户端到服务器端的种种延迟,这个时间也不会低。
有一些规则可以决定该用嵌入还是引用:
1. 第一个类对象,也就是处于顶层的,往往应该有自己的集合。
2. 排列项详情对象应该用嵌入。
3. 处于被包含关系的应该用嵌入。
4. 多对多的关系通常应该用引用。
5. 数据量小的集合可以放心地做成一个单独的集合,因为整个集合可以很快地cached。
6. 要想获得嵌入式对象的系统级视图会更困难一些。如上面的“Scores”如果不做成嵌入式对象可以更容易地查询出分数排名前100的学生。
7. 如果嵌入的是大对象,需要留意到BSON对象的4M大小限定(后面会讲到)。
8. 如果性能是关键就用嵌入。
下面是一些示例:
1.Customer/Order/Order Line-Item
cutomers和orders应该做成一个集合,line-items应该以数组的形式嵌入在order中。
2. 博客系统
posts应该是一个集合;author可以是一个单独的集合,如果只需记录作者的email地址也可以以字段的方式存在于posts中;comments应该做成嵌入的对象。
9GridFS
GridFS是MongoDB中用来存储大文件而定义的一种文件系统。MongoDB默认是用BSON格式来对数据进行存储和网络传输。但由于BSON文档对象在MongoDB中最大为4MB,无法存储大的对象。即使没有大小限制,BSON也无法满足对大数据集的快速范围查询,所以MongoDB引进了GridFS。
9.1GridFS表示的对象信息
1. 文件对象(类GridFSFile 的对象)的元数据信息。结构如下
{ "_id" : <unspecified>, // unique ID for this file "filename" : data_string, // human name for the file "contentType" : data_string, // valid mime type for the object "length" : data_number, // size of the file in bytes "chunkSize" : data_number, // size of each of the chunks. Default is 256k "uploadDate" : data_date, // date when object first stored "aliases" : data_array ofdata_string, // optional array ofalias strings "metadata" : data_object, // anything the user wants tostore "md5" : data_string //result of running "filemd5"command on the file's chunks } |
如下是put进去的一个文件例子:
{ _id:ObjId(4bbdf6200459d967be9d8e98), filename:"/home/hjgong/source_file/wnwb.svg", length: 7429, chunkSize:262144, uploadDate: newDate(1270740513127), md5:"ccd93f05e5b9912c26e68e9955bbf8b9" } |
2. 数据的二进制块以及一些统计信息。结构如下:
{ "_id": <unspecified>, // object id of the chunk in the _chunkscollection "files_id":<unspecified>, // _id value ofthe owning {{files}} collection entry "n": data_number, // "chunk number" -starting with 0 "data": data_binary (type 0x02), // binary data for chunk } |
因此使用GridFS可以储存富媒体文件,同时存入任意的附加信息,因为这些信息实际上也是一个普通的collection。以前,如果要存储一个附件,通常的做法是,在主数据库中存放文件的属性同时记录文件的path,当查询某个文件时,需要首先查询数据库,获得该文件的path,然后从存储系统中获得相应的文件。在使用GridFS时则非常简单,可以直接将这些信息直接存储到文件中。比如下面的Java代码,将文件file(file可以是图片、音频、视频等文件)储存到db中:
其中该方法的第一个参数的类型还可以是InputStream,byte[],从而实现多个重载的方法
9.2GridFS管理
MongoDB提供的工具mongofiles可以从命令行操作GridFS。如:
./mongofiles -host localhost:1727 -unavygong -p 111 put ~/source_file/wnwb.svg
每种语言提供的MongoDB客户端API都提供了一套方法,可以像操作普通文件一样对GridFS文件进行操作,包括read(),write(),tell(),seek()等。
10Replication(复制)
Mongo提供了两种方式的复制:简单的master-slave配置及replicapair的概念。
如果安全认证被enable,不管哪种replicate方式,都要在master/slave中创建一个能为各个database识别的用户名/密码。认证步骤如下:
slave先在local.system.users里查找一个名为"repl"的用户,找到后用它去认证master。如果"repl"用户没有找到,则使用local.system.users中的第一个用户去认证。local数据库和admin数据库一样,local中的用户可以访问整个dbserver。
10.1master-slave模式
一个server可以同时为master和slave。一个slave可以有多个master,这种方式并不推荐,因为可能会产生不可预期的结果。
在该模式中,一般是在两个不同的机器上各部署一个MongDB实例,一个为master,另一作为slave。将MongoDB作为master启动,只需要在命令行输入:
./mongod --master
然后主服务进程将会在数据库中创建一个集合local.oplog.$main,该collection主要记录了事务日志,即需要在slave执行的操作。
而将MongoDB作为slave启动,只需要在命令行输入:
./mongod --slave --source <masterhostname>[:<port>]
port不指定时即使用默认端口,masterhostname是master的IP或master机器的FQDN。
其他配置选项:
--autoresync:自动sync,但在10分钟内最多只会进行一次。
--oplogSize:指定master上用于存放更改的数据量,如果不指定,在32位机上最少为50M,在64位机上最少为1G,最大为磁盘空间的5%。
10.2replicapairs模式
以这种方式启动后,数据库会自动协商谁是master谁是slave。一旦一个数据库服务器断电,另一个会自动接管,并从那一刻起起为master。万一另一个将来也出错了,那么master状态将会转回给第一个服务器。以这种复制方式启动本地MongoDB的命令如下:
./mongod --pairwith <remoteserver> --arbiter <arbiterserver>
其中remoteserver是pair里的另一个server,arbiterserver是一个起仲裁作用的Mongo数据库服务器,用来协商pair中哪一个是master。arbiter运行在第三个机器上,利用“平分决胜制”决定在pair中的两台机器不能联系上对方时让哪一个做master,一般是能同arbiter通话的那台机器做master。如果不加--arbiter选项,出现网络问题时两台机器都作为master。命令db.$cmd.findOne({ismaster:1})可以检查当前哪一个database是master。
pair中的两台机器只能满足最终一致性。当replicapair中的一台机器完全挂掉时,需要用一台新的来代替。如(n1,n2)中的n2挂掉,这时用n3来代替n2。步骤如下:
1. 告诉n1用n3来代替n2:db.$cmd.findOne({replacepeer:1});
2. 重启n1让它同n3对话:./mongod--pairwith n3 --arbiter <arbiterserver>
3. 启动n3:./mongod--pairwith n1 --arbiter <arbiterserver>。
在n3的数据没有同步到n1前n3还不能做master,这个过程长短由数据量的多少决定。
10.3受限的master-master复制
Mongo不支持完全的master-master复制,通常情况下不推荐使用master-master模式,但在一些特定的情况下master-master也可用。master-master也只支持最终一致性。配置master-master只需运行mongod时同时加上--master选项和--slave选项。如下:
$ nohup mongod --dbpath /data1/db --port 27017 --master --slave --source localhost:27018 > /tmp/dblog1 &
$ nohup mongod --dbpath /data2/db --port 27018 --master --slave --source localhost:27017 > /tmp/dblog2 &
这种模式对插入、查询及根据_id进行的删除操作都是安全的。但对同一对象的并发更新无法进行。
11Sharding(分片)
11.1sharding介绍
MongoDB包括一个自动分片的的模块(“mongos”),从而可以构建一个大的水平可扩展的数据库集群,可以动态地添加和移走机器。如下是一个数据库集群的示意图:
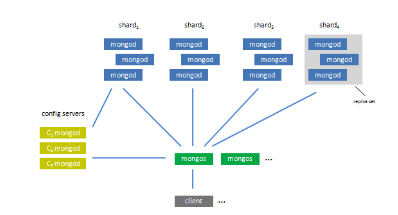
mongod:数据库服务器进程,类似于mysqld。
shards:每个shard有一个或多个mongod,通常是一个master,多个slave组成replication。数据由集合按一个预定的顺序划分,某一个范围的数据被放到一个特定的shard中,这样可以通过shard的key进行有效的范围查询。
shard keys:用于划分集合,格式类似于索引的定义,也是把一个或多个字段作为key,以key来分布数据。如:{name : 1 (1代表升序,-1代表降序)}、{_id : 1 }、{ lastname : 1,firstname : 1 }、{ tag : 1, timestamp :-1 }。如果有100万人同名,可能还需要划分,因为放到一个块里太大了,这时定义的sharkey不能只有一个name字段了。划分能够保证相邻的数据存储在一个server(当然也在相同的块上)。
chunks:是一个集合里某一范围的数据,(collection,minkey, maxkey)描述了一个chunk。块的大小有限定,当块里的数据超过最大值,块会一分为二。如果一个shard里的数据过多(添加shard时,可以指定这个shard上可以存放的最大数据量maxSize),就会有块迁移到其它的shard。同样,当添加新的server时,为了平衡各个server的负载,也会迁移chunk过去。
config server(配置服务器):存储了集群的元信息,包括每一个shard、一个shard里的server、以及每一个chunk的基本信息。其中主要是chunk的信息,每个configserver中都有一份所有chunk信息的完全拷贝。使用两阶段提交协议来保证配置信息在configserver间的一致。mongos:可以认为是一个“数据库路由器”,用以协调集群的各个部分,使它们看起来像一个系统。mongos没有固定的状态,可以在server需要的时候运行。mongos启动后会从configserver里取出元信息,然后接收客户请求,把请求路由到合适的server,得到结果后送回客户。一个系统可以有多个mongos例程,每个例程都需要内存来存储元信息。例程间不需协同工作,每个mongos只需要协同shardservers和config servers工作即可。当然shardservers间也会彼此对话,也会同config servers对话。
11.2sharding的配置和管理
mongod的启动选项中也包含了与sharding相关的参数,如--shardsvr(声明这是一个sharddb),--configsvr(声明这是一个configdb)。mongos的启动选项--configdb指定configserver的位置。下面的链接地址是一个简单的sharding配置例子:http://www.mongodb.org/display/DOCS/A+Sample+Configuration+Session。
像安全和认证一样,如果要sharding,先要允许一个数据库sharding,然后要指定数据库里集合的分片方式,这些都有相应的命令可以完成。
12JavaAPI简介
要使用Java操作MongoDB,在官网上下载jar包,目前最新的版本是:mongo-2.0.jar。首先介绍一下比较常用的几个类:
Mongo:连接服务器,执行一些数据库操作的选项,如新建立一个数据库等;
DB:对应一个数据库,可以用来建立集合等操作;
DBCollection:对应一个集合(类似表),可能是我们用得最多的,可以添加删除记录等;
DBObject接口和BasicDBObject对象:表示一个具体的记录,BasicDBObject实现了DBObject,因为是key-value的数据结构,所以用起来其实和HashMap是基本一致的;
DBCursor:用来遍历取得的数据,实现了Iterable和Iterator。
下面以一段简单的例子说明:
13MongoDB实例分析
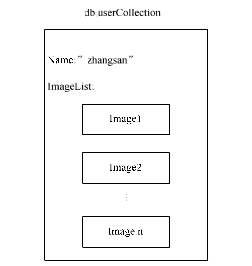
下面通过一个实例说明如何用MongoDB作为数据库。该实例中有一个user实体,包含一个name属性,每个user对应一到多个图片image。按照关系型数据库设计,可以设计一个user表和一个image表,其中image表中有一个关联到user表的外键。如果将这两个表对应为两个collection,即image对应的collection中的每一个document都有一个key,其value是该image关联的user。但为了体现MongoDB的效率,即MongoDB是schema-free的,而且支持嵌入子文档,因此在实现时,将一个user发布的image作为该user的子文档嵌入其中,这样只需要定义一个collection,即userCollection。如下图所示:
对于图片等文件,可以存储在文件系统中,也可以存储在数据库中。因此下面分两种情况实现。
13.1图片保存在文件系统中
这种情况下,图片实体中需要记录图片的路径uri,因此Image类的定义如下:
因为在MongoDB中,当保存的对象没有设置ID时,mongoDB会默认给该条记录设置一个ID("_id"),因此在类中没有定义id属性(下同)。
因为一个user对应多个image,所以在user实体中需要记录对应的image。如下:
在main函数中实现如下功能:首先定义一个user(假设id为1),其对应3张图片,然后将该user插入userCollection中。然后,通过查询查找到该user(根据id),再发布第4张图片,更新该user,然后打印出其信息。部分代码如下:
程序运行后,在控制台打印出的信息如下:
从该结果容易看出,用户user有两个属性“_id”和“Name”,而且ImageList作为其子文档(数组)嵌入其中,该数组中是3个图片,每个图片仍然是bson格式。
13.2图片保存在数据库中
这种情况下,图片实体只需要存储文件名即可,因此Image2类的定义如下:
User2类和上面类似,如下所示:
实现了类MongoTest2,其功能仍然是一个user对应3个图片,存入数据库中后,通过查询得到该user后,再插入第4幅图片,然后打印出信息。同时为了演示文件的查询,对存入MongoDB中的图片进行了查询并打印出其部分元数据信息。部分代码如下所示:
运行程序,控制台打印出的结果如下:
14MongoDB常用API总结
类转换
当把一个类对象存到mongoDB后,从mongoDB取出来时使用setObjectClass()将其转换回原来的类。
public class Tweet implements DBObject { /* ... */ } Tweet myTweet = new Tweet(); myTweet.put("user", "bruce"); myTweet.put("message", "fun"); myTweet.put("date", new Date()); collection.insert(myTweet); //转换 collection.setObjectClass(Tweet.class); Tweet myTweet = (Tweet)collection.findOne(); |
默认ID
当保存的对象没有设置ID时,mongoDB会默认给该条记录设置一个ID("_id")。
当然你也可以设置自己指定的ID,如:(在mongoDB中执行用db.users.save({_id:1,name:'bruce'});)
BasicDBObject bo = new BasicDBObject();
bo.put('_id', 1);
bo.put('name', 'bruce');
collection.insert(bo);
权限
判断是否有mongoDB的访问权限,有就返回true,否则返回false。
boolean auth = db.authenticate(myUserName, myPassword);
查看mongoDB数据库列表
Mongo m = new Mongo(); for (String s : m.getDatabaseNames()) { System.out.println(s); } |
查看当前库下所有的表名,等于在mongoDB中执行showtables;
Set |
查看一个表的索引
List |
删除一个数据库
Mongo m = new Mongo(); m.dropDatabase("myDatabaseName"); |
建立mongoDB的链接
Mongo m = new Mongo("localhost", 27017); //有多个重载方法,可根据需要选择 DB db = m.getDB("myDatabaseName"); //相当于库名 DBCollection coll = db.getCollection("myUsersTable");//相当于表名 |
查询数据
查询第一条记录
DBObject firstDoc = coll.findOne();
findOne()返回一个记录,而find()返回的是DBCursor游标对象。
查询全部数据
DBCursor cur = coll.find(); while(cur.hasNext()) { System.out.println(cur.next()); } |
查询记录数量
coll.find().count(); coll.find(new BasicDBObject("age", 26)).count(); |
条件查询
BasicDBObject condition = new BasicDBObject(); condition.put("name", "bruce"); condition.put("age", 26); coll.find(condition); |
查询部分数据块
DBCursor cursor = coll.find().skip(0).limit(10); while(cursor.hasNext()) { System.out.println(cursor.next()); } |
比较查询(age >50)
BasicDBObject condition = new BasicDBObject(); condition.put("age", new BasicDBObject("$gt",50)); coll.find(condition); |
比较符
"$gt": 大于
"$gte":大于等于
"$lt": 小于
"$lte":小于等于
"$in": 包含
//以下条件查询20<age<=30
condition.put("age", new BasicDBObject("$gt",20).append("$lte", 30));
插入数据
批量插入
List datas = new ArrayList(); for (int i=0; i < 100; i++) { BasicDBObject bo = new BasicDBObject(); bo.put("name", "bruce"); bo.append("age", i); datas.add(bo); } coll.insert(datas); |
又如:
DBCollection coll = db.getCollection("testCollection"); for(int i=1; i<=100; i++) {//插入100条记录 User user = new User(); user.setName("user_"+i); user.setPoint(i); coll.insert(user); } |
正则表达式
查询所有名字匹配 /joh?n/i 的记录
Pattern pattern = Pattern.compile("joh?n",CASE_INSENSITIVE); BasicDBObject query = new BasicDBObject("name", pattern); DBCursor cursor = coll.find(query); |
15Redis简介
Redis是一个key-value类型的内存数据库,每一个key都与一个value关联,使得Redis与其他key-value数据库不同是因为在Redis中的每一个value都有一个类型(type),目前在Redis中支持5中数据类型:String、List、Set、ZSet和Hash。每一种类型决定了可以赋予其上的操作(这些操作成为命令command)。比如你可以使用LPUSH或RPUSH命令在O(1)时间对一个list添加一个元素,然后你可以使用LRANGE命令得到list中的一部分元素或使用LTRIM对该list进行trim操作。集合set操作也是很灵活的,你可以从set(无序的String的集合)中add或remove元素,还可以进行交集、合集和差集运算。每一个command都是服务端自动的操作。
Redis性能上和memcached一样快但提供了更多的特性。和memcached一样,Redis支持对key设置失效时间,因此当设定的时间过后会被自动删除。
15.1Redis特性
速度快
Redis使用标准C编写实现,而且将所有数据加载到内存中,所以速度非常快。官方提供的数据表明,在一个普通的Linux机器上,Redis读写速度分别达到81000/s和110000/s。
持久化
由于所有数据保持在内存中(2.0版本开始可以只将部分数据的value放在内存,见“虚拟内存”),所以对数据的更新将异步地保存到磁盘上,Redis提供了一些策略来保存数据,比如根据时间或更新次数。
数据结构
可以将Redis看做“数据结构服务器”。目前,Redis支持5种数据结构。
自动操作
Redis对不同数据类型的操作是自动的,因此设置或增加key值,从一个集合中增加或删除一个元素都能安全的操作。
支持多种语言
Redis支持多种语言,诸如Ruby,Python, Twisted Python, PHP, Erlang, Tcl, Perl, Lua, Java, Scala, Clojure等。对Java的支持,包括两个。一是JDBC-Redis,是使用JDBC连接Redis数据库的驱动。这个项目的目标并不是完全实现JDBC规范,因为Redis不是关系型数据库,但给Java开发人员提供了一个像操作关系数据库一样操作Redis数据库的接口。
另一个是JRedis,是使用Redis作为数据库开发Java程序的开发包,主要提供了对数据结构的操作。
主-从复制
Redis支持简单而快速的主-从复制。官方提供了一个数据,Slave在21秒即完成了对Amazon网站10Gkey set的复制。
Sharding
很容易将数据分布到多个Redis实例中,但这主要看该语言是否支持。目前支持Sharding功能的语言只有PHP、Ruby和Scala。
16Redis数据类型
官方文档上,将Redis成为一个“数据结构服务器”(data structures server)是有一定道理的。Redis的所有功能就是以其固有的几种数据结构保存,并提供用户操作这几种结构的接口。可以对比在其他语言中那些固有数据类型及其操作。
Redis目前提供四种数据类型:string、list、set和zset(sortedset)。
16.1String类型
String是最简单的类型,一个key对应一个value。RedisString是安全的,String类型的数据最大1G。String类型的值可以被视作integer,从而可以让“INCR”命令族操作,这种情况下,该integer的值限制在64位有符号数。
在list、set和zset中包含的独立的元素类型都是RedisString类型。
在Redis中,String类型由sds.c库定义,它被封装成Redis对象。和Java中的对象一样,Redis对象也是使用“引用”,因此当一个Redis String被多次使用时,Redis会尽量使用同一个String对象而不是多次分配。
从Redis 1.1版开始,String对象可以编码成数字,因此这样可以节省内存空间。
16.2List类型
链表类型,主要功能是push、pop、获取一个范围的所有值等。其中的key可以理解为链表的名字。在Redis中,list就是RedisString的列表,按照插入顺序排序。比如使用LPUSH命令在list头插入一个元素,使用RPUSH命令在list的尾插入一个元素。当这两个命令之一作用于一个空的key时,一个新的list就创建出来了。比如:
最终在mylist中存储的元素为:”b”,”a”,”c”。
List的最大长度是2^32-1个元素。
16.3Set类型
集合,和数学中的集合概念相似。操作中的key理解为集合的名字。在Redis中,set就是RedisString的无序集合,不允许有重复元素。对set操作的command一般都有返回值标识所操作的元素是否已经存在。比如SADD命令是往set中插入一个元素,如果set中已存在该元素,则命令返回0,否则返回1。
Set的最大元素数是2^32-1。
Redis中对set的操作还有交集、并集、差集等。
16.4ZSet类型
Zset是set的一个升级版本,在set的基础上增加了一个顺序属性,这一属性在添加修改元素时可以指定,每次指定后zset会自动安装指定值重新调整顺序。可以理解为一张表,一列存value,一列存顺序。操作中的key理解为zset的名字。
比如ZADD命令是向zset中添加一个新元素,对该元素要指定一个score。如果对已经在zset中存在的元素施加ZADD命令同时指定了不同的score,则该元素的score将更新同时该元素将被移动到合适的位置以使集合保持有序。
使用ZRANGE命令可以得到zset的一部分元素,当然也可以使用命令ZRANGEBYSCORE,根据score得到或删除一部分元素。
Zset的最大元素数是2^32-1。
对于已经有序的zset,仍然可以使用SORT命令,通过指定ASC|DESC参数对其进行排序。
16.5Hash类型
Redis Hash类型对数据域和值提供了映射,这一结构很方便表示对象。此外,在Hash中可以只保存有限的几个“域”,而不是将所有的“域”作为key,这可以节省内存。这一特性的体现可以参考下文的“虚拟内存”部分。
17Alldata in memory, but saved on disk
Redis在内存中加载并维护整个数据集,但这些数据是持久化的,因为它们在同一时间被保持在磁盘上,所以当Redis服务重启时,这些数据能够重新被加载到内存中。
Redis支持两种数据持久化的方法。一种称为snapsshotting,在这种模式下,Redis异步地将数据dump到磁盘上。Redis还可以通过配置,根据更新操作次数或间隔时间,将数据dump到磁盘。比如你可以设定发生1000个更新操作时,或距上次转储最多60s就要将数据dump到磁盘。
因为数据是异步dump的,所以当系统崩溃时,就会出现错误。因为,Redis提供了另外一种模式,更安全的持久化模式,称为AppendOnly File,当出现修改数据命令的地方,这些命令就要写到“appendonly file”—ASAP。当服务重启时,这些命令会重新执行(replay)从而在内存中重新构建数据。
Redis的存储可以分为:内存存储、磁盘存储和log文件三部分,配置文件(redis.conf)中有三个参数对其进行配置。
save<seconds> <changes>:save配置,指出在多长时间,有多少次更新操作,就将数据同步到数据文件。在默认的配置文件中设置就设置了三个条件。
appendonlyyes/no:appendonly配置,指出是否在每次更新操作后进行日志记录,如果不开启,可能会在断电时导致一段时间内的数据丢失。因为redis本身同步数据文件是按上面的save条件来同步的,所以有的数据会在一段时间内只存在于内存中。
appendfsyncno/always/everysec:appendfsync配置,no表示等操作系统进行数据缓存同步到磁盘,always表示每次更新操作后手动调用fsync()将数据写到磁盘,everysec表示每秒同步一次。
18Redis的Master-Slave模式
Redis中配置Master-Slave模式很简单,二者会自动同步。配置方法是在从机的配置文件中指定slaveof参数为主机的ip和port即可,比如:slaveof 192.168.2.2016379。从原理上来说,是从机请求主机的方式,按照tokyotyrant的做法,是可以实现主-主,主-从等灵活形式的,而redis只能支持主-从,不能支持主-主。Redis中的复制具有以下特点:
- 一个master可以有多个slave。
- 一个slave可以接收其他slave的链接,即不仅仅能连接一个master所属的slaves,而且能连接到slave的slave,从而形成了“图”结构。
- 在复制进行时,master是“非阻塞”的。即一个或多个slave对master进行第一次同步时,master仍然可以提供查询服务,而对于slave,当复制进行时则是“阻塞”的,期间slave不能响应查询。
- 复制可以用于提高数据的扩展性(比如多个slave用于只读查询),或者仅用于数据备份。
- 使用复制可以避免在master存储数据,通过修改redis.conf文件(将“save”的al注释),这样数据存储只在slave端进行。
slave连接master并发出SYNC命令开始复制或当连接关闭时与master同步数据。master在“后台”进行存储操作,同时会监听所有对数据的更新操作。当存储操作完成后,master开始向slave传送数据并将数据保存到磁盘,加载到内存。这一过程中,master将会向slave发送所有对数据有更新操作的命令。通过telnet可以实验这一过程。通过连接到Redis端口并且发出SYNC命令,在telnet的session中,可以看到数据包的传送,以及发送给master的命令都将重新发送给slave。
当master-slave连接断掉时,slave能自动重新建立连接。当一个master并发地收到多个slave数据同步请求时,master也能自动处理。
19Redis虚拟内存管理
在Redis2.0开始(目前最新版本)第一次提出了Virtual Memory(VM)的特性。Redis是内存数据库,因此通常情况下Redis会将所有的key和value都放在内存中,但有时这并不是最好的选择,为了查询速度,可以将所有的key放在内存中,而values可以放在磁盘上,当用到时再交换到内存。
比如你的数据有100000个key都放在了内存中,而只有其中10%的key被经常访问,那么可进行VM配置的Redis会尝试将不经常访问的key关联的value放到磁盘上,当这些value被请求时才会交换到内存中。
什么时候使用VM配置是需要考虑的问题。因为Redis是以磁盘为后备的内存数据库,在大多数情况下,只有RAM足够大时才使用Redis。但实际情况是,总会出现内存不够的情况:
- 有“倾向”的数据访问。只有很小比例的key被经常访问(比如一个网站的在线用户),但同时在内存中却有所有的数据。
- 不考虑访问情况以及大的value,内存不能加载所有数据。这种情况下,Redis可以视作on-disk DB,即所有的key在内存中,而访问value时要访问慢速的磁盘。
需要注意的一点是,Redis不能交换key。即如果是因为数据的key太大,value太小而造成内存不够,VM是不能解决这种情况的。当出现这种情况时,有时可以使用Hash结构,将“manykeys with small values”的问题转换成“less keys but withvery values”的问题(对key进行hash,从而对数据进行“分组”)。
启用VM功能,只需要在redis.conf文件中使vm-enabled的值为yes。
20Redis实例分析
仍然以用户和图片的例子进行说明。假设将图片存储在文件系统中,即类Image中只保存图片的uri。类Image和类User的代码参见MongoDB部分的例子。下面给出测试类的关键代码:
在实现中,将类User的对象实例存放在一个set中,所以利用了SADD命令,在Java中即调用JRedis对象的sadd方法。smembers方法将返回指定key(这里是userSet)的集合中的所有value,这样就可以对每一个元素进行操作。
21Redis命令总结
Redis提供了丰富的命令(command)对数据库和各种数据类型进行操作,这些command可以在Linux终端使用。在编程时,比如使用Redis 的Java语言包,这些命令都有对应的方法,比如上面例子中使用的sadd方法,就是对集合操作中的SADD命令。下面将Redis提供的命令做一总结。
21.1连接操作相关的命令
- quit:关闭连接(connection)
- auth:简单密码认证
21.2对value操作的命令
- exists(key):确认一个key是否存在
- del(key):删除一个key
- type(key):返回值的类型
- keys(pattern):返回满足给定pattern的所有key
- randomkey:随机返回key空间的一个key
- rename(oldname, newname):将key由oldname重命名为newname,若newname存在则删除newname表示的key
- dbsize:返回当前数据库中key的数目
- expire:设定一个key的活动时间(s)
- ttl:获得一个key的活动时间
- select(index):按索引查询
- move(key, dbindex):将当前数据库中的key转移到有dbindex索引的数据库
- flushdb:删除当前选择数据库中的所有key
- flushall:删除所有数据库中的所有key
21.3对String操作的命令
- set(key, value):给数据库中名称为key的string赋予值value
- get(key):返回数据库中名称为key的string的value
- getset(key, value):给名称为key的string赋予上一次的value
- mget(key1, key2,…, key N):返回库中多个string(它们的名称为key1,key2…)的value
- setnx(key, value):如果不存在名称为key的string,则向库中添加string,名称为key,值为value
- setex(key, time,value):向库中添加string(名称为key,值为value)同时,设定过期时间time
- mset(key1, value1, key2, value2,…key N, value N):同时给多个string赋值,名称为keyi的string赋值valuei
- msetnx(key1, value1, key2, value2,…key N, value N):如果所有名称为keyi的string都不存在,则向库中添加string,名称keyi赋值为value i
- incr(key):名称为key的string增1操作
- incrby(key, integer):名称为key的string增加integer
- decr(key):名称为key的string减1操作
- decrby(key, integer):名称为key的string减少integer
- append(key, value):名称为key的string的值附加value
- substr(key, start, end):返回名称为key的string的value的子串
21.4对List操作的命令
- rpush(key, value):在名称为key的list尾添加一个值为value的元素
- lpush(key, value):在名称为key的list头添加一个值为value的元素
- llen(key):返回名称为key的list的长度
- lrange(key, start, end):返回名称为key的list中start至end之间的元素(下标从0开始,下同)
- ltrim(key, start, end):截取名称为key的list,保留start至end之间的元素
- lindex(key, index):返回名称为key的list中index位置的元素
- lset(key, index, value):给名称为key的list中index位置的元素赋值为value
- lrem(key, count, value):删除count个名称为key的list中值为value的元素。count为0,删除所有值为value的元素,count>0从头至尾删除count个值为value的元素,count<0从尾到头删除|count|个值为value的元素。
- lpop(key):返回并删除名称为key的list中的首元素
- rpop(key):返回并删除名称为key的list中的尾元素
- blpop(key1, key2,… key N, timeout):lpop命令的block版本。即当timeout为0时,若遇到名称为keyi的list不存在或该list为空,则命令结束。如果timeout>0,则遇到上述情况时,等待timeout秒,如果问题没有解决,则对key i+1开始的list执行pop操作。
- brpop(key1, key2,… key N, timeout):rpop的block版本。参考上一命令。
- rpoplpush(srckey, dstkey):返回并删除名称为srckey的list的尾元素,并将该元素添加到名称为dstkey的list的头部
21.5对Set操作的命令
- sadd(key, member):向名称为key的set中添加元素member
- srem(key, member) :删除名称为key的set中的元素member
- spop(key) :随机返回并删除名称为key的set中一个元素
- smove(srckey, dstkey, member) :将member元素从名称为srckey的集合移到名称为dstkey的集合
- scard(key) :返回名称为key的set的基数
- sismember(key, member) :测试member是否是名称为key的set的元素
- sinter(key1, key2,…key N) :求交集
- sinterstore(dstkey, key1, key2,…key N) :求交集并将交集保存到dstkey的集合
- sunion(key1, key2,…key N) :求并集
- sunionstore(dstkey, key1, key2,…key N) :求并集并将并集保存到dstkey的集合
- sdiff(key1, key2,…key N) :求差集
- sdiffstore(dstkey, key1, key2,…key N) :求差集并将差集保存到dstkey的集合
- smembers(key) :返回名称为key的set的所有元素
- srandmember(key) :随机返回名称为key的set的一个元素
21.6对zset(sorted set)操作的命令
- zadd(key, score, member):向名称为key的zset中添加元素member,score用于排序。如果该元素已经存在,则根据score更新该元素的顺序。
- zrem(key, member) :删除名称为key的zset中的元素member
- zincrby(key, increment, member) :如果在名称为key的zset中已经存在元素member,则该元素的score增加increment;否则向集合中添加该元素,其score的值为increment
- zrank(key, member) :返回名称为key的zset(元素已按score从小到大排序)中member元素的rank(即index,从0开始),若没有member元素,返回“nil”
- zrevrank(key, member) :返回名称为key的zset(元素已按score从大到小排序)中member元素的rank(即index,从0开始),若没有member元素,返回“nil”
- zrange(key, start, end):返回名称为key的zset(元素已按score从小到大排序)中的index从start到end的所有元素
- zrevrange(key, start, end):返回名称为key的zset(元素已按score从大到小排序)中的index从start到end的所有元素
- zrangebyscore(key, min, max):返回名称为key的zset中score>= min且score <= max的所有元素
- zcard(key):返回名称为key的zset的基数
- zscore(key, element):返回名称为key的zset中元素element的score
- zremrangebyrank(key, min, max):删除名称为key的zset中rank>= min且rank <= max的所有元素
- zremrangebyscore(key, min, max) :删除名称为key的zset中score>= min且score <= max的所有元素
- zunionstore/ zinterstore(dstkeyN, key1,…,keyN, WEIGHTS w1,…wN, AGGREGATE SUM|MIN|MAX):对N个zset求并集和交集,并将最后的集合保存在dstkeyN中。对于集合中每一个元素的score,在进行AGGREGATE运算前,都要乘以对于的WEIGHT参数。如果没有提供WEIGHT,默认为1。默认的AGGREGATE是SUM,即结果集合中元素的score是所有集合对应元素进行SUM运算的值,而MIN和MAX是指,结果集合中元素的score是所有集合对应元素中最小值和最大值。
21.7对Hash操作的命令
- hset(key, field, value):向名称为key的hash中添加元素field<—>value
- hget(key, field):返回名称为key的hash中field对应的value
- hmget(key, field1, …,field N):返回名称为key的hash中fieldi对应的value
- hmset(key, field1, value1,…,field N, value N):向名称为key的hash中添加元素fieldi<—>value i
- hincrby(key, field, integer):将名称为key的hash中field的value增加integer
- hexists(key, field):名称为key的hash中是否存在键为field的域
- hdel(key, field):删除名称为key的hash中键为field的域
- hlen(key):返回名称为key的hash中元素个数
- hkeys(key):返回名称为key的hash中所有键
- hvals(key):返回名称为key的hash中所有键对应的value
- hgetall(key):返回名称为key的hash中所有的键(field)及其对应的value
21.8持久化
- save:将数据同步保存到磁盘
- bgsave:将数据异步保存到磁盘
- lastsave:返回上次成功将数据保存到磁盘的Unix时戳
- shundown:将数据同步保存到磁盘,然后关闭服务
21.9远程服务控制
- info:提供服务器的信息和统计
- monitor:实时转储收到的请求
- slaveof:改变复制策略设置
- config:在运行时配置Redis服务器
有疑问加站长微信联系(非本文作者)



