转载自:http://blog.csdn.net/erlib/article/details/51850912
英文原文链接:https://blog.twitch.tv/gos-march-to-low-latency-gc-a6fa96f06eb7#.lrmfby2xs
下面我们会介绍https://www.twitch.tv视频直播网站在使用Go过程中的GC耗时演变史。
我们是视频直播系统且拥有数百万的在线用户,消息和聊天系统全部是用Go写的,该服务单台机器同时连接了50万左右的用户。在Go1.4到1.5的版本迭代中,GC得到了20倍的提升,在1.6版本得到了10倍的提升,然后跟Go的Runtime开发组进行交流后,在1.7版本又得到了10倍的提升(在1.7之前,我们进行了大量的GC参数调优,在1.7中这些调优都不需要了,原生的runtime就可以支持),总共是2000倍!!!具体的GC停止时间从2秒到了1毫秒!!而且不需要任何GC调优!!
那么我们开始GC大冒险吧
在2013年的时候,我们用Go重写了基于IRC的聊天系统,之前是用Python写的。当时使用的Go版本是1.1,重构后,可以在不进行特殊调优的情况下,达到单台50万用户在线。每个用户使用了3个goroutine,因此系统中有整整150万goroutine在运行,但是神奇的是,系统完全没有任何性能问题,除了GC--基本上每分钟都会运行几次GC,每次GC耗时几秒至10几秒不等,对于我们的交互性服务来说,这个绝对是不可容忍的。
后面我们对系统进行了大量的优化,包括了减少对象分配、控制对象数量等等,这个时候GC的运行频率和STW(Stop The World)时间都得到了改进。基本上系统每2分钟自动GC一次就可以了,虽然GC次数少了,但是每次暂停的时间依然是毁灭性的。
随着Go1.2的发布,GC STW时间缩短为几秒左右,然后我们对服务进行了切分,这样也让GC降低到稍微可以接受的水平。但是这种切分服务的工作队我们来说也是巨大的负担,同时和GO的版本也是息息相关的。
在2015年8月开始使用Go1.5后,Go采用了并行和增值GC,这意味着系统不需要在忍受一个超级久的STW时间了。升级到1.5给我们带来了10倍的GC提升,从2秒到200毫秒。
Go1.5-GC新纪元
虽然Go1.5的GC改进非常棒,但是更棒的是为未来的持续改进搭好了舞台!
Go1.5的GC仍然分为两个主要阶段-markl阶段:GC对对象和不再使用的内存进行标记;sweep阶段,准备进行回收。这中间还分为两个子阶段,第一阶段,暂停应用,结束上一次sweep,接着进入并发mark阶段:找到正在使用的内存;第二阶段,mark结束阶段,这期间应用再一次暂停。最后,未使用的内存会被逐步回收,这个阶段是异步的,不会STW。
gctrace可以用来跟踪GC周期,包括了每个阶段的耗时。对于我们的服务来说,它表明了大部分时间是耗费在mark结束阶段,所以我们的GC分析也会集中在mark结束阶段这块儿。
这里我们需要对GC进行跟踪,Go原生就自带一个pprof,但是我们决定使用linux perf工具。使用perf可以采集更高频率的样本,也可以观察os kernel的时间消耗。对kernel进行监控,可以帮我们debug慢系统调用等工作。
下面是我们的profile图表,使用的Go1.5.1,这是一个Flame Graph,使用了Brendan Gregg的工具获取,并进行了剪裁,去除了不重要的部分,留下了runtime.gcMark部分,这个函数耗费的时间可以认为是mark阶段的STW时间。
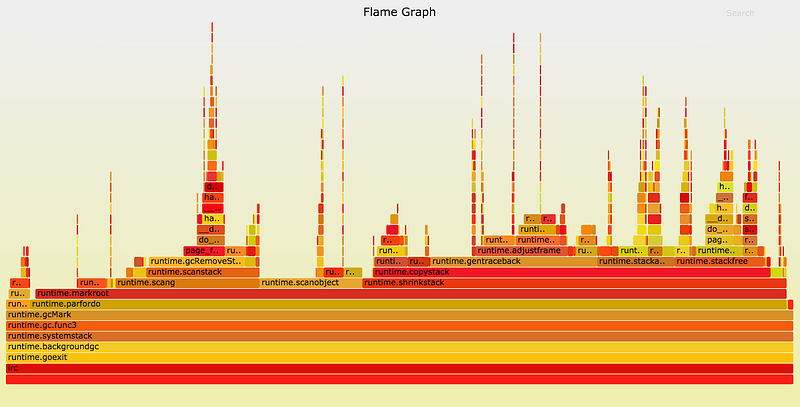
这张图是依次向上的方式来展示栈调用的,每一块的宽度代表了CPU时间,颜色和同一行的顺序不重要。在图表的最左边我们可以找到runtime.gcMark函数,它调用了runtime.parfordo函数。再往上,我们发现了大部分时间都花费在了runtime.markroot上,它调用了runtime.scang, runtime.scanobject, runtime.shrinkstack。
runtime.scang函数是在mark结束阶段时进行重新扫描,这个是必须的函数,无法优化。我们再来看看另外两个函数。
下一个是runtime.scanobject函数,该函数做了几件事情,但是在mark阶段运行的原因是实现finalizers。可能你会想:为什么程序要使用这么多finalizer,给GC带来这么大的压力呢?因为我们的应用是消息和聊天服务,因此会处理几十万的连接。Go的核心net包会为每个TCP连接分配一个finalizer来帮助控制文件描述符泄漏。
就这个问题我们跟Go runtime组进行了多次沟通,他们给我们提供了一些诊断办法。在Go1.6中,finalizer的扫描被移到了并发阶段中,对于大量连接的应用来说,GC的性能得到了显著提升。因此在1.6下,STW时间是1.5的2倍,200ms -> 100ms!
栈收缩
Go的gourtine在初始化时有2KB的栈大小,会随着需要增长。Go的函数在调用前都会假定栈大小是足够的,如果不够,那么旧的gourtine栈会被移动到新的内存区域,同时根据需要重写指针等。
因此,在程序运行时,goroutine的stack就会自动增长以满足函数调用需求。GC的一个目标就是回收这些不在需要的栈空间。将goroutine栈移动到一个合适大小的内存空间,这个工作是通过runtime.shrinkstack工作完成的,这个工作在1.5和1.6中是在mark STW阶段完成的。
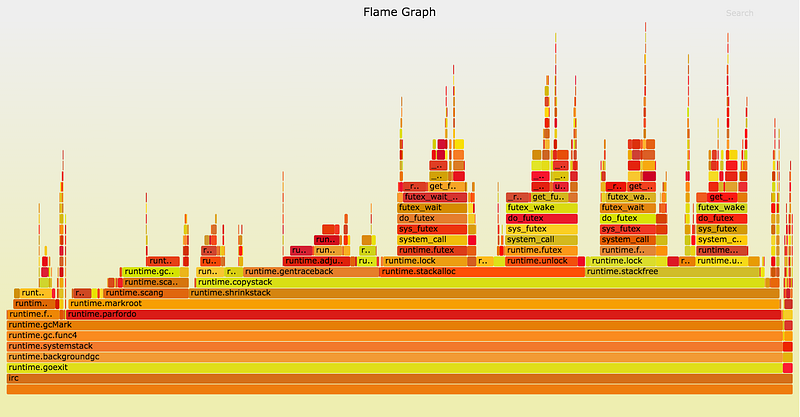
上图纪录了1.6的gc图,runtime.shrinkstack占据了3/4的时间。如果这个函数能在app运行时异步完成,那对于我们的服务来说,可以得到极大的提升。
Go runtime包的文档描述了怎么禁用栈收缩。对于我们的服务,浪费一些内存来换取GC的提升。因此我们决定禁用stack sthrinking,这时GC又得到了2x的提升,STW时间来到了30-70ms。
还有办法继续优化吗?再来另一个profile吧!
缺页(page faults)?!
细心的读者应该发现了,上面的GC时间的范围还是挺大的:30-70ms。这里的flame graph显示了较长时间的STW情况:
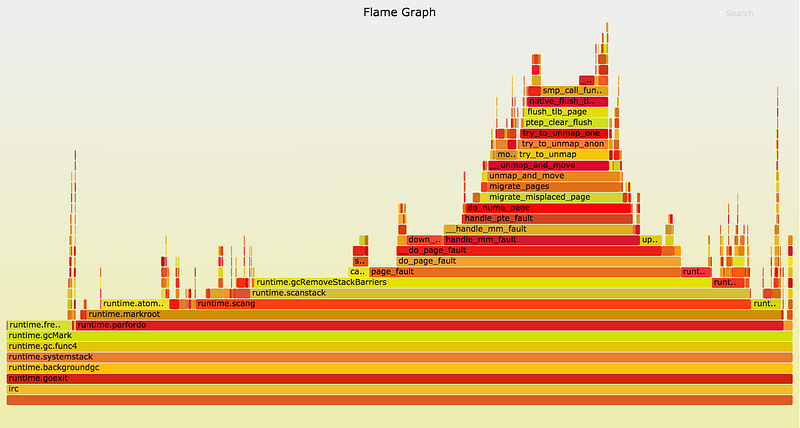
当GC调用runtime.gcRemoveStackBarriers时,系统产生了一次page fault,导致了一次系统函数调用:page_fault。Page Fault 是kernel把虚拟内存映射到物理内存的方式,进程常常被允许分配大量的虚拟内存,在程序访问page fault时,会进行映射后去访问物理内存。
runtime.gcRemoveStackBarriers函数会修正刚被程序访问的栈内存,事实上,这个函数的目的是移除stack barriers(在GC开始插入),在这个期间系统有大量可用的内存,所以问题来了:为什么这次内存访问会导致page faults?
这个时候,一些计算机硬件的背景知识可能会帮上我们。我们用的服务器是现代化的dual-socket机器(应该是主板上有两个CPU插槽的机器)。每个CPU插槽都有自己的内存条,这种就是NUMA,Non-Uniform Memory Access架构,当线程跑在socket 0上时,那该线程访问socket 0的内存就会很快,访问其它内存就会变慢。linux kernel尝试降低这种延迟:让线程在它们使用的内存旁运行,并且将物理内存分页移到了线程运行附近。
有了这些基本知识后,再来看看kernel的page_fault函数。继续往上看flame graph的调用栈,可以看到kernel调用了do_numa_page和migrate_misplaced_page函数,这两个函数将程序内存在各个socket的内存之间移动。
在这里,kernel的这种内存访问模式是基本上没有任何意义的,而且为了匹配这种模式而迁移内存分页也是代价高昂的。
还好我们有perf,靠它我们跟踪到了kernel的行为,这些仅仅依赖Go内部的pprof是不行的-你只能看到程序神秘的慢了,但是慢在哪里?sorry,我们不知道。但是使用perf是相对较为复杂的,需要root权限去访问kernel栈,同时要求Go1.5和1.6使用非标准的构建版本(通过GOEXPERIMENT=framepointer ./make.bash来编译),不过好消息是GO 1.7版本原生支持这种debug,不需要做任何额外的工作。但是不管如何麻烦,对于我们的服务来说,这种测试是非常必须的。
控制内存迁移
如果使用两个CPU socket和两个内存槽太复杂,那我们就只使用一个CPU socket。可以通过linux的tastkset命令来将进程绑定到某个CPU上。这种场景下,程序的线程就只访问邻近的内存,kernel会讲内存移动到对应的socket内存中。
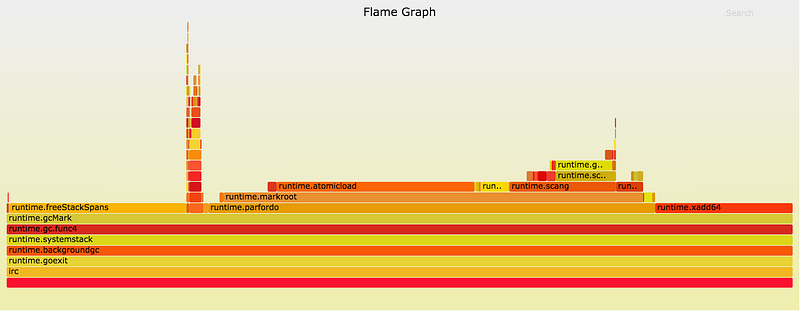
进行了上面的改造后(除了绑定CPU外,还可以通过设置set_mempolicy(2)函数或者mbind(2)函数将内存策略设置为MPOL_BIND来实现),STW时间缩减到了10-15ms。这张图是在pre-1.6版本下获取的。注意这里的runtime.freeStackSpans,这个函数在后面已经被移到了并发GC阶段,所以不用再关注。到了这里,对于STW来说,已经没有多少可以优化了。
GO 1.7
到1.6为止,我们通过禁用栈收缩等办法来优化GC。虽然这些办法都有一定的副作用,比如增加内存消耗等,而且大大增加了操作复杂度。对于一些程序而言,栈收缩是非常重要的,因此只在部分应用上使用了这些优化。还好Go1.7要来了,这个号称史上改进最多的版本,在Gc上的改进也很显著:并发的进行栈收缩,这样我们既实现了低延迟,又避免了对runtime进行调优,只要使用标准的runtime就可以。
自从GO1.5引入并发GC后,runtime会对一个goroutine在上次扫描过stack后是否执行过,进行了跟踪。STW阶段会检查每个goroutine是否执行过,然后会重新扫描那些执行过的。在GO1.7开始,runtime会维护一个独立的短list,这样就不需要在STW期间再遍历一次所有的goroutine,同时极大的减少了那些会触发kernel的NUMA迁移的内存访问。
最后,1.7中,amd64的编译器会默认维护frame pointers,这样标准的debug和性能测试工具,例如perf,就可以debug当前的Go函数调用堆栈 了。这样使用标准构建的程序就可以选择更多的高级工具,不再需要重新使用不标准的方式来构建Go的工具链。这个改进对于系统整体性能测试来说,是非常棒的!
使用2016年6月发布的pre-1.7版本,GC的STW时间达到了惊人的1ms,而且是在没有进行任何调优的情况下!!对比Go1.6又是10倍的提升!!
跟Go开发组分享我们的经验,帮助他们找到了在GC方面一些问题的解决方案。总得来说,从最开始到Go1.7,GC的性能得到了20 * 10 * 10 = 2000x的提升!!!!向Go开发组脱帽致敬!
下一步呢?
所有的分析都聚焦在了GC的STW阶段,但是对于GC来说,这个只是调优的一个维度。下一步Go runtime开发的重心将在吞吐方面。
他们近期的提议Transaction Oriented Collector描述了一种方法:对于那些没有被goroutines共享的内存(goroutine的私有堆栈),提供代价低廉的分配和回收。这样可以减少full GC的次数,减少整个GC过程的CPU时钟耗费。
总结:
在现在的Go版本中,还咬着GO GC不行的陈旧观念不放已经没有意义了,除非是对延迟要求非常苛刻的应用,比如不允许暂停超过1ms。
现在泛型已经提上了Go开发组的议程了,只不过他们还在讨论那种解决方案更完美,等实现,可能要明年了。
祝愿Go语言的明天越来越好!
广告时间
欢迎大家加入Golang隐修会,QQ群894864,欢迎加入这个大
家庭,这里有所有你想要的,而且热心大神很多哦!
有疑问加站长微信联系(非本文作者)




