这个程序其实就是现在挺火热的 Swarm,Swarm 这个程序的模式就是作为 client 的角色向数万个 docker daemon 服务器建连,维持长连接状态,然后再定时的从这些 docker daemon 读取数据。经排查,发现长连接数和线程数基本一致,看到这个现象完全不能够理解。
最开始的怀疑是 DNS 查询,走了 cgo 模式,从而导致线程被不断创建,但不断翻看代码能够肯定的是建连用的 IP,而非域名,最后为了排除 DNS cgo 查询的影响,我又做了配置强制采用纯 Go 方式做 DNS 解析,但并没有因此线程数就降低。强制使用纯 Go DNS 解析器只需要设置如下环境变量即可。
export GODEBUG=netdns=go
然后,继续在 cgo call 这条路上排查,于是开始定位代码中是否有采用 cgo 方式调用 C 代码等,没发现任何 cgo 调用的可能,最后强制关闭 cgo 也还是无济于事。
这个时候我也分析过 pprof 数据了,没有发现任何疑点。pprof 里本来有一个 threadcreate ,感觉这个工具很用,可不知道为什么我获取出来始终只有线程数量,并没有文档介绍的栈信息等。如果你知道使用 pprof/threadcreate 工具的正确姿势,麻烦告诉我一下,谢谢。
无计可施,试图用 runtime.Stack() 方法在 goroutine 调度器创建线程的位置打印出调用栈,但由于用来存储栈的数组会逃逸到堆上,此方法没能成功,应该是我的姿势不对吧。最后又简单的开启调度器的状态信息,可以看到确实创建了很多线程,并且这些线程都不是 idle 状态,也就说都是在干活的,极为不能理解,还是无法清楚为什么会创建这么多线程。
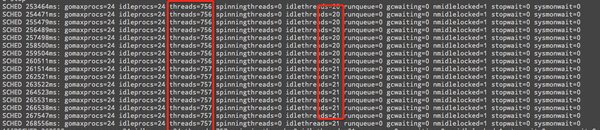 开启调度器状态信息方法:
开启调度器状态信息方法:
export GODEBUG=scheddetail=1,schedtrace=1000
这样就每一 1000 个毫秒就输出调度状态到标准输出。
经同事提醒用 pstack 看看每个线程都在干什么,结果发现绝大多数线程都在 read 系统调用,线程栈如下:
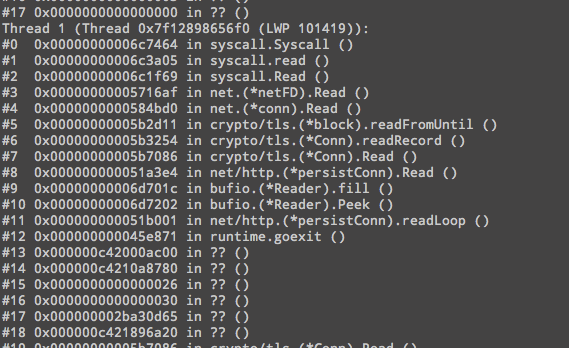 这个时候再 strace 跟踪此线程出现如下现象:
这个时候再 strace 跟踪此线程出现如下现象:
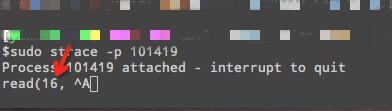
可以看到这个线程长时间阻塞在 read 调用上了,当然我不敢相信自己的眼睛,还是去进一步求证了 fd 16 确实是网络 connection,网络io 在 Go 的世界里是不能够被阻塞的,否则一切都运转不起来了。这个时候我严重怀疑 strace 工具跟踪的问题,于是到 Go net 库中添加日志,确认是否会退出 read 系统调用,重新编译好 Go 和 swarm,放到线上一跑果然发现 read 系统调用在无数据后并不会返回,也就是阻塞了。再看一个添加日志后的线程栈:
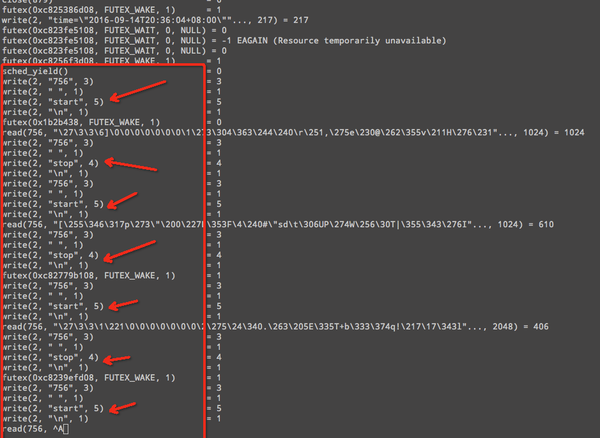 在 read 系统调用前后添加 start/stop 日志信息,可以清楚的看到最后 read 阻塞了。到这个时候,我能够解释为什么线程数暴涨和连接数基本一致了,但 Go 底层 net 库中确实是为每个 connection 都设置了 nonblock 属性,可最后又变成了 block。这种情况要么是内核bug,要么就是 connection 的属性最后又被破坏了;我肯定更愿意相信后一种可能,突然想起代码中自定义的 Dial() 方法里有对 connection 进行 tcp 的选项设置。
在 read 系统调用前后添加 start/stop 日志信息,可以清楚的看到最后 read 阻塞了。到这个时候,我能够解释为什么线程数暴涨和连接数基本一致了,但 Go 底层 net 库中确实是为每个 connection 都设置了 nonblock 属性,可最后又变成了 block。这种情况要么是内核bug,要么就是 connection 的属性最后又被破坏了;我肯定更愿意相信后一种可能,突然想起代码中自定义的 Dial() 方法里有对 connection 进行 tcp 的选项设置。
// TCP_USER_TIMEOUT is a relatively new feature to detect dead peer from sender side.
// Linux supports it since kernel 2.6.37. It's among Golang experimental under
// golang.org/x/sys/unix but it doesn't support all Linux platforms yet.
// we explicitly define it here until it becomes official in golang.
// TODO: replace it with proper package when TCP_USER_TIMEOUT is supported in golang.
const tcpUserTimeout = 0x12
syscall.SetsockoptInt(int(f.Fd()), syscall.IPPROTO_TCP, tcpUserTimeout, msecs)
将这个 TCP 选项去掉,重新编译后放到线上一跑,果然一切都对了,线程数也降到正常的几十个。
真正的原因
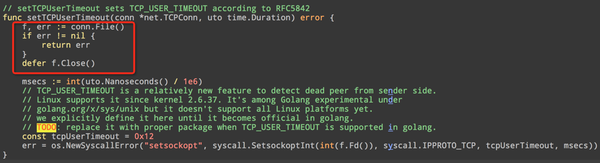 这是设置 TCP_USER_TIMEOUT 选项的代码,之前我将这个函数调用给注释了,就轻率的认为是设置了这个选项出的问题,最后发现其实真正导致 block 的应该是 conn.File() 调用。底层代码是这样的:
这是设置 TCP_USER_TIMEOUT 选项的代码,之前我将这个函数调用给注释了,就轻率的认为是设置了这个选项出的问题,最后发现其实真正导致 block 的应该是 conn.File() 调用。底层代码是这样的:
// File sets the underlying os.File to blocking mode and returns a copy.
// It is the caller's responsibility to close f when finished.
// Closing c does not affect f, and closing f does not affect c.
//
// The returned os.File's file descriptor is different from the connection's.
// Attempting to change properties of the original using this duplicate
// may or may not have the desired effect.
func (c *conn) File() (f *os.File, err error) {
f, err = c.fd.dup()
if err != nil {
err = &OpError{Op: "file", Net: c.fd.net, Source: c.fd.laddr, Addr: c.fd.raddr, Err: err}
}
return
}
func (fd *netFD) dup() (f *os.File, err error) {
ns, err := dupCloseOnExec(fd.sysfd)
if err != nil {
return nil, err
}
// We want blocking mode for the new fd, hence the double negative.
// This also puts the old fd into blocking mode, meaning that
// I/O will block the thread instead of letting us use the epoll server.
// Everything will still work, just with more threads.
if err = syscall.SetNonblock(ns, false); err != nil {
return nil, os.NewSyscallError("setnonblock", err)
}
return os.NewFile(uintptr(ns), fd.name()), nil
}
不用看代码,光看看注释就明白了。所以这里设置 TCP 选项的姿势是不对的。
很久以前我在 swarm 的代码中就发现如下注释:
// Swarm runnable threads could be large when the number of nodes is large
// or under request bursts. Most threads are occupied by network connections.
// Increase max thread count from 10k default to 50k to accommodate it.
const maxThreadCount int = 50 * 1000
debug.SetMaxThreads(maxThreadCount)
好像也发现了线程数巨多的情况,但认为大量连接和并发请求需要消耗这么多的线程。从这一点看可能没有深入理解 Go 的并发原理以及 Linux 上的事件驱动。
排查这个问题花了我不少的时间,主要是这个问题的现象和我自己理解的『世界』完全不一致,我很难去想这是 Go 的bug,确实也不是,于是造成很多时候不知道从什么地方入手,只能让自己不断回到 runtime 的代码中去寻找线程被创建的条件等细节。
之前写过的一些博客文章:www.skoo.me
有疑问加站长微信联系(非本文作者)



