Posted 3 months ago by Di Chen
“Go catch em all! ”
本文作者Di Chen,原博客链接 How
to create a pokemon map?
前言
在一个月前,Pokemon Go 成了新一轮现象级手游。基于 LBS (Location Based Service) 的设计给社交带来了更多可能。
从最早玩游戏的时候,我就不甘于受限于游戏的世界,探索各种 “作弊” 的方式。既然是基于位置的游戏,那么制作一个 “地图” 也成了顺其自然的想法。
这篇文章就记录了我从反向工程解构 Pokemon Go 架构,到建立一个实时 Pokemon 地图的过程。
成品: mypokemon.io
探索
对网络安全有一些了解的同学大概都知道,要 hack 某个游戏或者 app ,你需要做的第一件事就是了解它是怎样运作的。对于 Pokemon Go 也是一样的。
监听网络流量
首先,我需要架设一个网络流量监听的工具。由于近年来 REST API 的流行,我假设 Pokemon Go 也是用 REST API 来通信的,那么假设一个 http proxy 便能够进行 MITM (man in the middle attack) 攻击,并截取通信记录了。在这里,我用的工具是 burp
由于我的 macbook 和我的手机接入到了同一个 wifi ,我在电脑上设置的 proxy ,在 iphone 上也能连上。在 burp configure 界面有很详细的设置过程,在设置好电脑跟手机之后,我们就可以在 burp 上看到 Pokemon Go 的网络流量了。
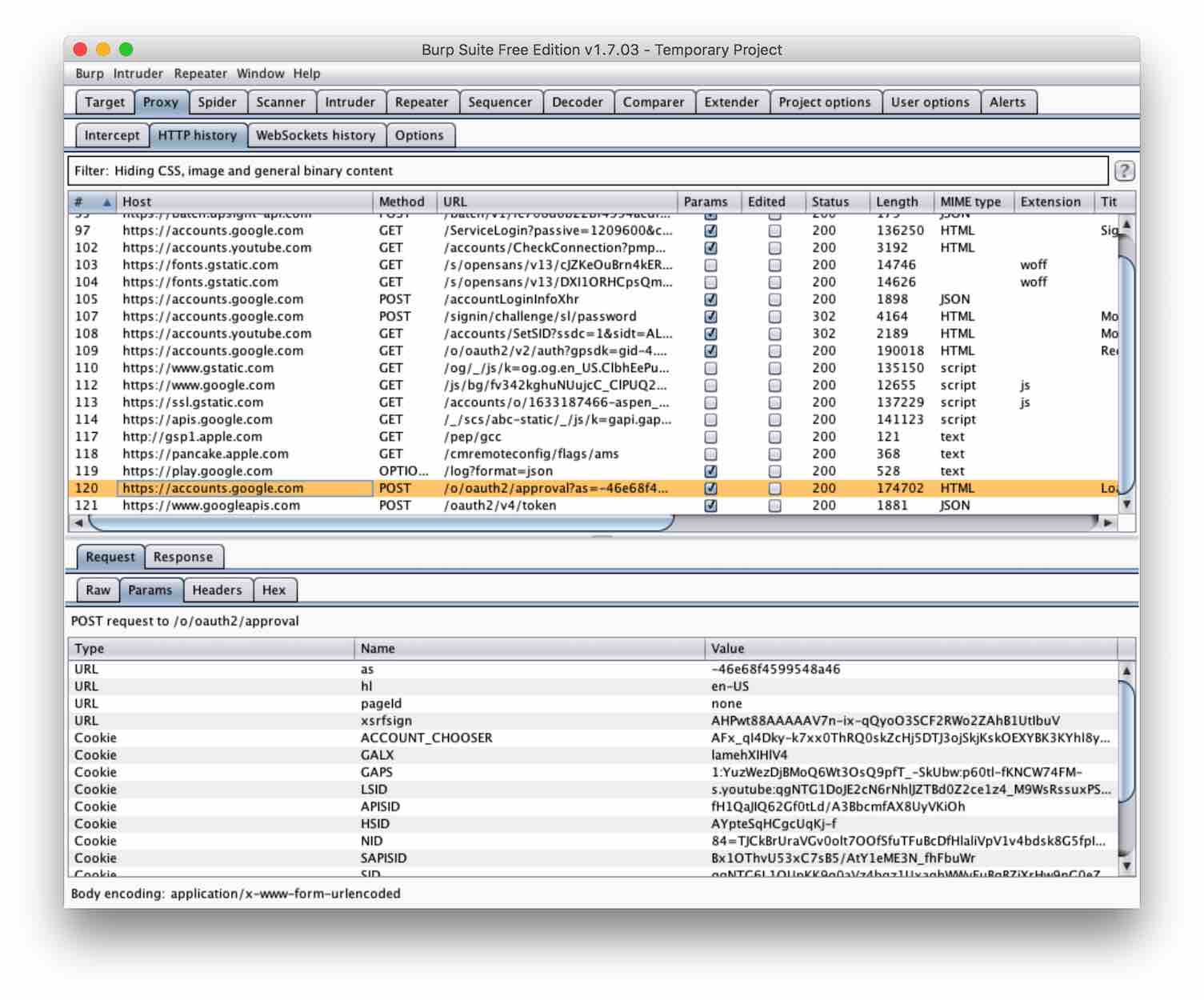
解码
在 burp 里,我们可以看到 Pokemon Go 的通信记录,其中大部分都是毫无意义的二进制码。联想一下 Google 的技术栈,不难想到,这是用 protocol buffer 编码过的,那么用 protobuf 反向解码,就可以看到原请求了。
我写了一个小脚本来批量解码,解码的结果是可以 json 格式的 enum 集合。由于没有 schema ,下一步我们需要做的就是搞清楚每个 enum 对应的意思。这个过程就比较枯燥繁琐了,在 github 上效率最高的 project 算是 AeonLucid/POGOProtos,我们就不要重新造轮子了。
同样的,在这步之后,把 protocol buffer 转化成可用的 API 也有开源的项目 tejado/pgoapi,我们就可以跳过这两步,直接开始设计地图了。
架构设计
我最终的目标是提供一个 Pokemon Map as a Service,那么所有的数据储存跟采集都必然发生在云端。我决定的架构是这样的:
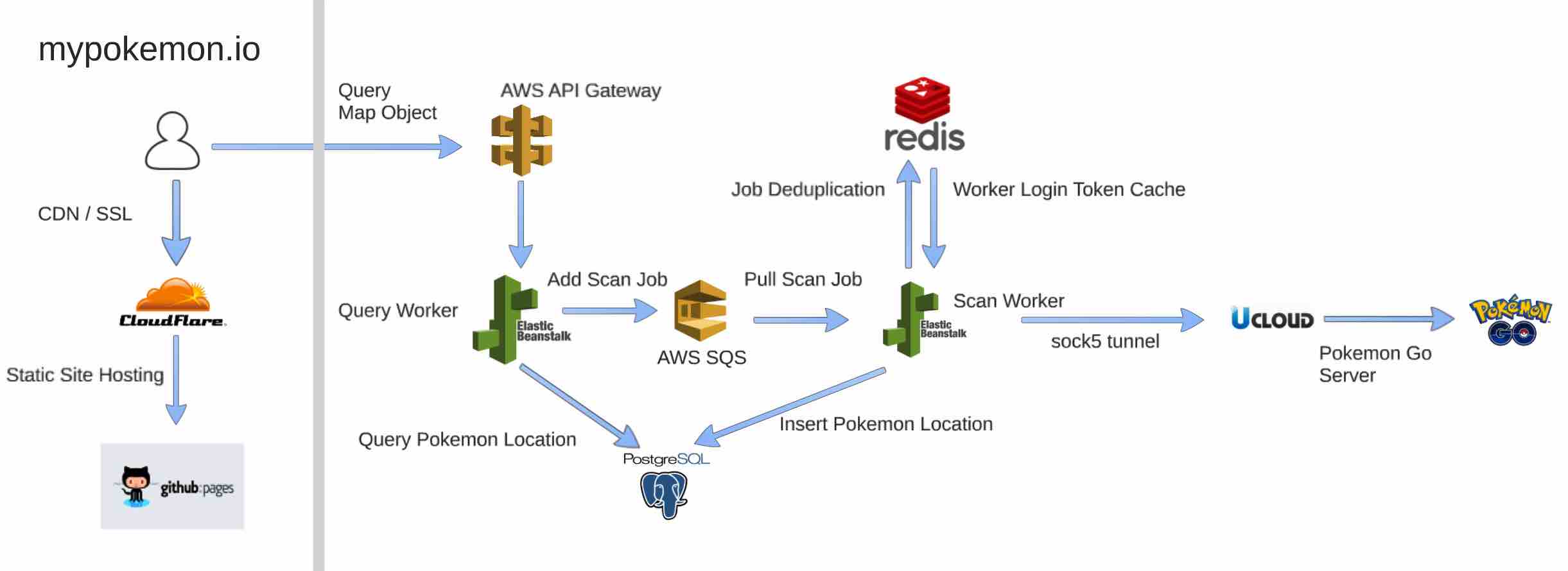
整个系统分为 3 个部分:
网页前端
由于地图的本身的特性,网页前端是非常轻量级的,基本不需要怎么修改,只需要显示后端发回的数据即可。所以前端我就直接用 github pages 来托管。
在最新的 chrome 浏览器里,实时定位信息只能在 https 显示的网页上使用,所以为了能够使用用户的位置信息,我用 cloudflare 做 DNS 提供商。用 cloudflare 不光可以一键增加 SSL 证书,还可以提供 CDN 服务,这样也解决了一部分前端加载速度的问题。
数据查询层
将数据查询跟数据采集分开也是很自然的想法。地图上的数据在短时间内并不会有巨大的改变,所以查询这个动作是很轻量级的,但是数据采集则需要从服务器爬取信息,是需要很多集群资源的。
在这里,我用 AWS 的 API Gateway 来给网页端提供接口,API Gateway 再把请求转发给一个 AWS Elastic Beanstalk 的 Django 后端,最后转化成一个简单的 SQL。由于目前并没有很大的流量,所以即使直接 query 数据库延迟也很低。如果今后流量增大了,也许会考虑再加一个 Elastic Search 来提高效率。
数据采集层
数据采集才是这个地图中最核心的部分。要设计数据采集层,我们就要先看看有哪些可以用的工具。
在前面我们已经得到了可以模拟 Pokemon Go 客户端的 python api,在 Pokemon Go 中,每 5 秒,客户端就会发送一个 GET_MAP_OBJECTS 请求给服务器,包含了用户所在的位置,服务器则会返回用户可以抓到的小精灵地址,以及离用户很近的小精灵地址。这些小精灵大概是在距离用户
100 米内的。这就意味着,每一个用户请求,只能覆盖半径 100 米的圆形区域,要搜索 1 平方公里的区域,就需要发送约 100 个请求到 Pokemon Go 服务器。例子
现在我们知道如何搜索一个区域,其他的部分就简单多了。
如何知道搜索哪个区域
在数据查询的时候,把查询区域发送到一个消息队列里 (AWS SQS),然后 search worker 不断地从队列里读取需要搜索的区域。
如何得到每个区域里需要搜索的坐标点
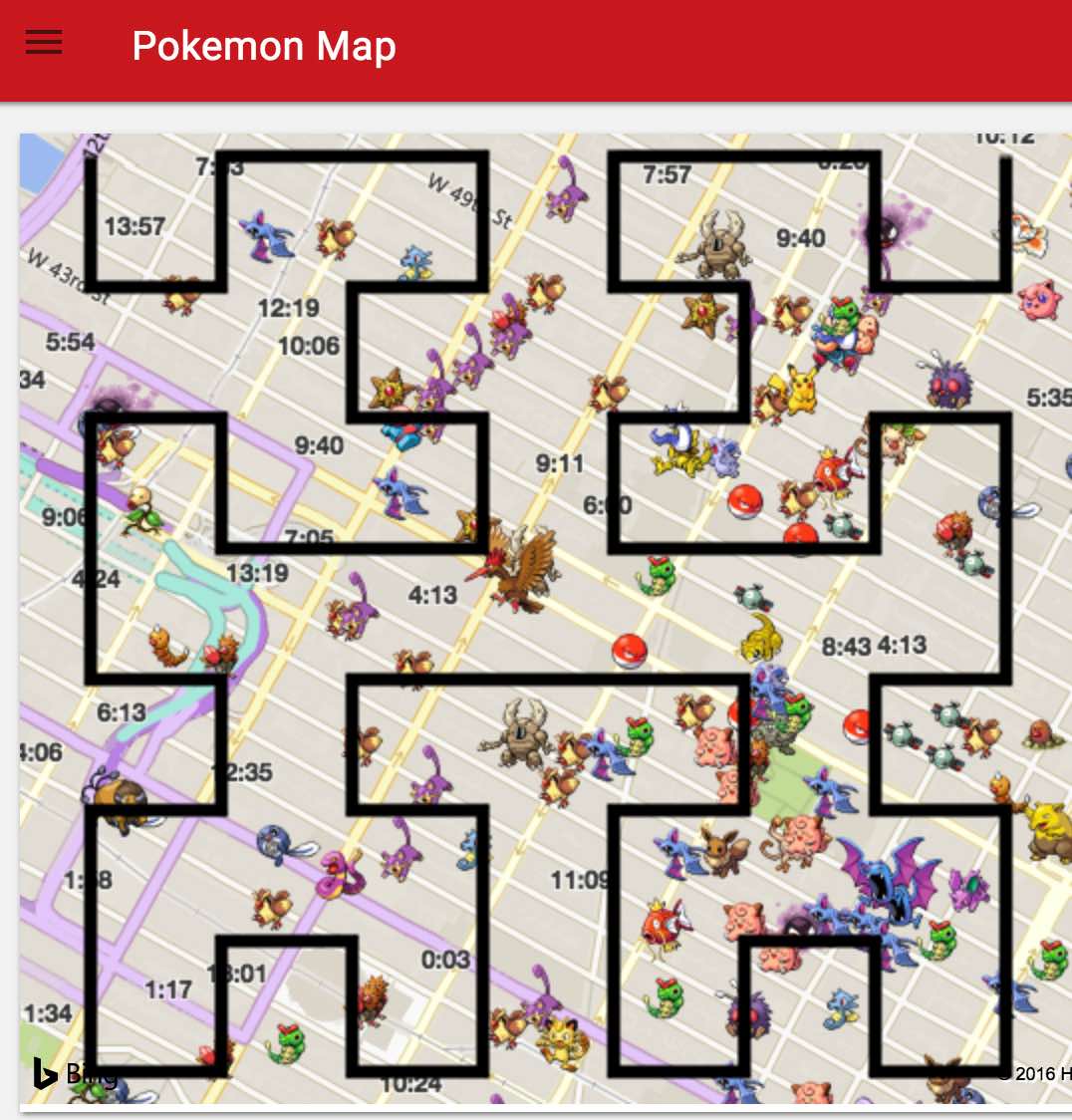
Google S2 是一个基于希尔伯特曲线 的区域分割方式。它可以将一个区域分割成相同大小的区域并且用一个 unique id 来表示。我们可以用 Google S2 将区域分割成 100m * 100m 的小正方形,然后取其中心作为用户位置,发送给服务器。
希尔伯特例子
图中的黑线是一个 hilbert curve,而图中的每一个黑线的转折点就是一个搜索点。
系统优化
在实现了最简单的数据采集层之后,就已经可以在网页端看到小精灵了。但是还有一些问题需要优化解决:
- 如果每个查询地区都进行搜索,搜索服务器的压力会比查询服务器大数十倍,而许多区域是没必要短时间内多次搜索的。
- 如果使用同一个账号进行搜索,非常容易被封号。
- 如果每次搜索都需要先登录服务器,会大大增加搜索延迟。
让我们一个个问题来解决:
如何减少搜索次数
这个问题的关键就在于减少相同地区的重复搜索。借用 Data Deduplication 的思想,我们可以用 时间
+ 地点 来作为 Deduplication Key,如果区域 A 在 x 秒内搜索过了,就跳过这个区域。
在这里,我用 redis 来储存搜索记录,原因有两个:
- Redis 的 setex 功能可以自动添加 ttl (Time to live),在一定时间之后,记录会自动消失。
- Redis 作为一种 in memory cache,对于这类不需要高可靠性的数据,可以提供很好的查询速度。
具体实现:
def filter_duplciate_cell_ids(cell_ids): # validate it against redis redis_query = [ "request.{0}".format(cell_id) for cell_id in cell_ids ] cell_exist = redis_client.mget(redis_query) cell_states = zip(cell_ids, cell_exist) filtered_cells = [ cell_state[0] for cell_state in cell_states if cell_state[1] != None ] for cell_id in new_cell_ids: redis_client.setex("request.{0}".format(cell_id), 60, '1') return new_cell_ids
如何避免同一个账户过于频繁地访问 Pokemon Go 服务器
答案很简单。使用多个账号( > 10000 个)。那么如何注册并使用多个账号呢?
由于 Pokemon Go 官网的注册 不需要验证码,我用 selenium 写了一个批量注册机,自动填写注册信息。
注册邮箱需要验证之后才能使用,如何批量得到邮箱地址呢?
我申请了一个域名,设置通用邮件转发。这样所有在那个域名下的邮箱地址都会转发到我指定的一个邮箱了。我只需要注册一个邮箱,就可以映射到所有在我域名下的邮箱了。大部分的域名提供商都有邮件转发功能。
怎样批量激活账户呢?
设置邮箱的 Pop3,并且写一个小脚本,定期轮询新邮件,并且点击激活地址。在激活之后,储存用户名密码到数据库。
如何降低由于登录服务器引起的搜索延迟
在 tejado/pgoapi 中,为了模拟用户的行为,使用 API 之前,都会进行登录行为。整个流程分为 3 个部分:
- 从 oauth 服务器获取 account token。这里的 token 既可能是 Pokemon Trainer Club 的,也可能是 Google 的。
- 从 Load Balance 服务器 (pgorelease.nianticlabs.com/plfe) 获取实际的 rpc 服务器地址以及 access token。
- 使用第二部的 access token 签名 rpc 请求,发送到 rpc 服务器。
在第一步跟第二步获得的 token 都是可以重复使用的,oauth token 有效时间大概是 3 小时,access token 有效时间大概是 30 分钟。我在每次成功登陆之后把 access token 和 rpc 服务器地址存到数据库中,这样就可以在不同的 Scan worker 之间使用了。
在优化了上面三点之后,每条数据爬取的速度就快了一倍。
Pokemon Map 的灾难
这个地图做起来其实并不难,所以有很多同质性的地图网站,最有名的大概就是 pokevision。在 2016/07/30,Niantic (Pokemon Go的制作公司)将大部分云服务提供商的 ip 地址都封禁了,包括 AWS, Azure, DigitalOcean 等等。由于大部分的 Pokemon Map 都托管在云服务上,这就导致了几乎所有的 Pokemon Map 都无法使用了。比如这篇报道。
同样,我的 Pokemon Map 也无法获取数据了,所有的 rpc 请求都返回了 nginx 403 错误请求。 为了解决这个问题,我们就需要更改发送请求的ip地址,最简单的方式就是使用一个 proxy 转发所有的通信流量。具体实现也很简单,在 Scan Worker 服务器上跑一个 ssh 链接即可:
ssh -o StrictHostKeyChecking=no -D <port number> -f -C -q -N username@<ip
address>。
于是我们就成了少量生存下来的 Pokemon Map 之一了。
小新闻
在 8 月 18 日,比利时最大的移动通信商 proximus 的 IP 被 Niantic 禁掉了。而这家通信商两周前还以无限 Pokemon Go 流量作为宣传。经过与 Niantic 的交涉之后,终于又重新恢复了连接。
IP 封禁也是会有误伤呀。
后记
Next Step
这个 project 主要是做一个自己喜欢的游戏辅助工具,锻炼一下各个 tech stack 的使用,并不为盈利。
接下来,主要考虑增加一些自己喜欢的功能。比如统计各类小精灵出现的频次,在曼哈顿哪些地方稀有小精灵最多等等。
如果 Niantic 不开放公共 API,也许最终这个地图会无疾而终,毕竟作为游戏作者的 Niantic,有权控制自己的游戏方式。
Lession Learned
在这个过程中学到的东西还蛮多的。
-
做对社会有价值的事
在这个 project 初始之时,Pokemon Go 火爆的程度让我感觉 Pokemon Map 一定会有很大的受众,于是花了很多时间来写这个 project,希望能早日推广给玩家。
在这个过程中最大的问题大概是利益方的分析错误。Pokemon Map 能给玩家额外的游戏优势,但是 Pokemon Go 的作者并不一定希望这个优势存在。如此一来,Pokemon Map 虽然提供给了玩家价值,但是损害了 Niantic 的价值,这并不是一个很好的 project。
纵观成功的创业项目,大部分都是多方共赢的。比如打车软件对司机的收入提高,对乘客的便捷度提高,新技术推进传统行业的效率等等。马云在哥大的演讲就曾提到过,赚钱的项目不一定对社会有益,但是对社会有价值的项目一定能赚钱。
-
MVP (Minimum Viable Product)
在做 project 的时候一定要加快迭周期,越早推出原型,就能越快获得反馈。这点在 UI / UX 设计上尤为重要,想当然是没有出路的。
-
全栈
在做网页 UI 的时候发现,我的前端能力实在是不足。如果要把后端的成果完整体现出来,前端的能力也要跟上。我曾经试过在前端的微信群里邀请小伙伴跟我一起做这个 project,结果并没有什么人表现出兴趣,更多的反馈是
“这个已经有类似的了呀”。/(ㄒoㄒ)/~~这对很多创业公司也是个头疼的问题吧,在同质化竞争日益激烈的时候,怎样招揽人才,并拥有自己的竞争优势。
在找到合适的 UI 小伙伴之前,增强自己的前端能力,让自己成为真正的全栈也许更容易一些吧。
如果你看到这里,一定是真爱!欢迎看看我的其他 blog。O(∩_∩)O
本科毕业于上海交通大学和密西根大学。目前就职于Bloomberg的交易系统基础架构组,负责集群负载均衡,数据收集等。本科期间及毕业之后参与多个数据收集分析项目。曾参与SemEval语义相似度分析,twitter方言检测,Quora提问自动分类,中文语义词向量生成等自然语言处理项目。目前正在参加kaggle的"BNP Paribas Cardif Claims Management" 并学习数据挖掘与特征工程的知识。
有疑问加站长微信联系(非本文作者)




