Pholcus
Pholcus(幽灵蛛)是一款纯Go语言编写的支持分布式的高并发、重量级爬虫软件,定位于互联网数据采集,为具备一定Go或JS编程基础的人提供一个只需关注规则定制的功能强大的爬虫工具。
它支持单机、服务端、客户端三种运行模式,拥有Web、GUI、命令行三种操作界面;规则简单灵活、批量任务并发、输出方式丰富(mysql/mongodb/csv/excel等)、有大量Demo共享;另外它还支持横纵向两种抓取模式,支持模拟登录和任务暂停、取消等一系列高级功能。
-
-
-
官方QQ群:Go大数据 42731170
爬虫原理



框架特点
-
为具备一定Go或JS编程基础的用户提供只需关注规则定制、功能完备的重量级爬虫工具;
-
支持单机、服务端、客户端三种运行模式;
-
GUI(Windows)、Web、Cmd 三种操作界面,可通过参数控制打开方式;
-
支持状态控制,如暂停、恢复、停止等;
-
可控制采集量;
-
可控制并发协程数;
-
支持多采集任务并发执行;
-
支持代理IP列表,可控制更换频率;
-
支持采集过程随机停歇,模拟人工行为;
-
根据规则需求,提供自定义配置输入接口
-
有mysql、mongodb、csv、excel、原文件下载共五种输出方式;
-
支持分批输出,且每批数量可控;
-
支持静态Go和动态JS两种采集规则,支持横纵向两种抓取模式,且有大量Demo;
-
持久化成功记录,便于自动去重;
-
序列化失败请求,支持反序列化自动重载处理;
-
采用surfer高并发下载器,支持 GET/POST/HEAD 方法及 http/https 协议,同时支持固定UserAgent自动保存cookie与随机大量UserAgent禁用cookie两种模式,高度模拟浏览器行为,可实现模拟登录等功能;
-
服务器/客户端模式采用Teleport高并发SocketAPI框架,全双工长连接通信,内部数据传输格式为JSON。
下载安装
-
下载第三方依赖包源码,放至 GOPATH/src 目录下 [点击下载 ZIP]
-
下载更新源码,命令行如下
go get -u -v github.com/henrylee2cn/pholcus
备注:Pholcus公开维护的spider规则库地址 https://github.com/pholcus/spider_lib
创建项目
package main
import (
"github.com/henrylee2cn/pholcus/exec"
_ "github.com/pholcus/spider_lib" // 此为公开维护的spider规则库
// _ "spider_lib_pte" // 同样你也可以自由添加自己的规则库
)
func main() {
// 设置运行时默认操作界面,并开始运行
// 运行软件前,可设置 -a_ui 参数为"web"、"gui"或"cmd",指定本次运行的操作界面
// 其中"gui"仅支持Windows系统
exec.DefaultRun("web")
}
编译运行
正常编译方法
cd {{replace your gopath}}/src/github.com/henrylee2cn/pholcus
go install 或者 go build
Windows下隐藏cmd窗口的编译方法
cd {{replace your gopath}}/src/github.com/henrylee2cn/pholcus
go install -ldflags="-H windowsgui" 或者 go build -ldflags="-H windowsgui"
查看可选参数:
pholcus -h

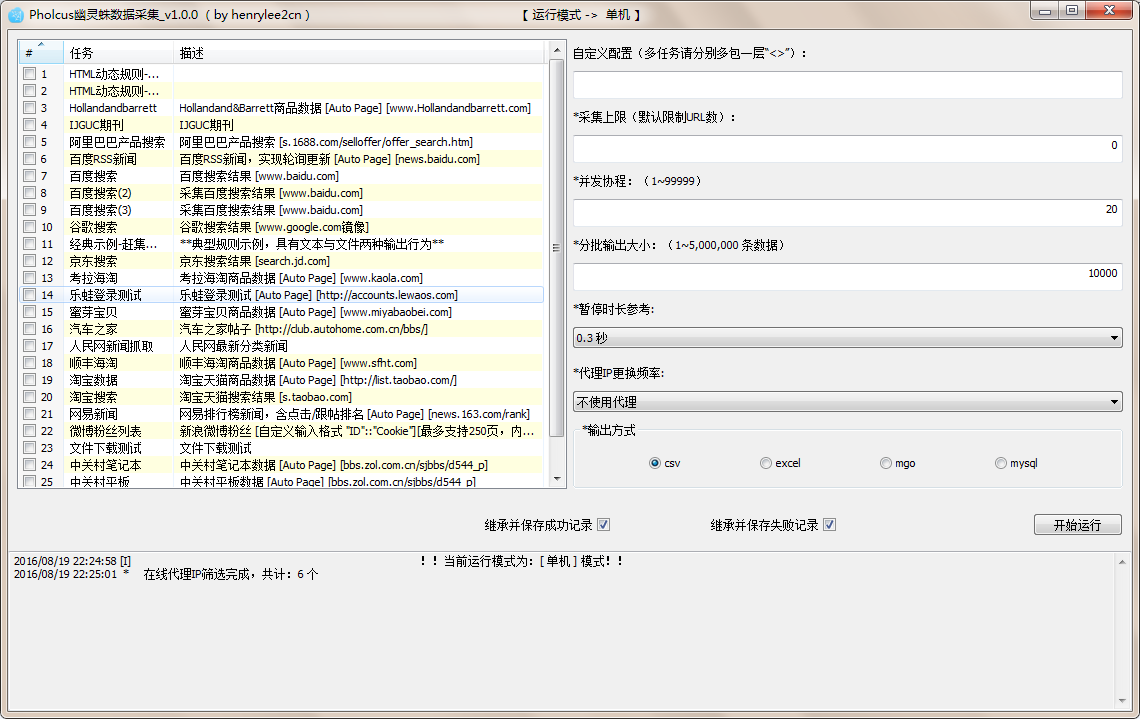
Web版操作界面截图如下:

GUI版操作界面之模式选择界面截图如下

Cmd版运行参数设置示例如下
$ pholcus -_ui=cmd -a_mode=0 -c_spider=3,8 -a_outtype=csv -a_thread=20 -a_dockercap=5000 -a_pause=300 -a_proxyminute=0 -a_keyins="<pholcus><golang>" -a_limit=10 -a_success=true -a_failure=true
运行时目录文件
├─pholcus 软件 │ ├─pholcus_pkg 运行时文件目录 │ ├─config.ini 配置文件 │ │ │ ├─proxy.lib 代理IP列表文件 │ │ │ ├─spiders 动态规则目录 │ │ └─xxx.pholcus.html 动态规则文件 │ │ │ ├─phantomjs 程序文件 │ │ │ ├─text_out 文本数据文件输出目录 │ │ │ ├─file_out 文件结果输出目录 │ │ │ ├─logs 日志目录 │ │ │ ├─history 历史记录目录 │ │ └─└─cache 临时缓存目录
动态规则示例
特点:动态加载规则,无需重新编译软件,书写简单,添加自由,适用于轻量级的采集项目。
xxx.pholcus.html
<Spider>
<Name>HTML动态规则示例</Name>
<DeScription>HTML动态规则示例 [Auto Page] [http://xxx.xxx.xxx]</DeScription>
<Pausetime>300</Pausetime>
<EnableLimit>false</EnableLimit>
<EnableCookie>true</EnableCookie>
<EnableKeyin>false</EnableKeyin>
<NotDefaultField>false</NotDefaultField>
<Namespace>
<Script></Script>
</Namespace>
<SubNamespace>
<Script></Script>
</SubNamespace>
<Root>
<Script param="ctx">
console.log("Root");
ctx.JsAddQueue({
Url: "http://xxx.xxx.xxx",
Rule: "登录页"
});
</Script>
</Root>
<Rule name="登录页">
<AidFunc>
<Script param="ctx,aid">
</Script>
</AidFunc>
<ParseFunc>
<Script param="ctx">
console.log(ctx.GetRuleName());
ctx.JsAddQueue({
Url: "http://xxx.xxx.xxx",
Rule: "登录后",
Method: "POST",
PostData: "username=44444444@qq.com&password=44444444&login_btn=login_btn&submit=login_btn"
});
</Script>
</ParseFunc>
</Rule>
<Rule name="登录后">
<ParseFunc>
<Script param="ctx">
console.log(ctx.GetRuleName());
ctx.Output({
"全部": ctx.GetText()
});
ctx.JsAddQueue({
Url: "http://accounts.xxx.xxx/member",
Rule: "个人中心",
Header: {
"Referer": [ctx.GetUrl()]
}
});
</Script>
</ParseFunc>
</Rule>
<Rule name="个人中心">
<ParseFunc>
<Script param="ctx">
console.log("个人中心: " + ctx.GetRuleName());
ctx.Output({
"全部": ctx.GetText()
});
</Script>
</ParseFunc>
</Rule>
</Spider>
静态规则示例
特点:随软件一同编译,定制性更强,效率更高,适用于重量级的采集项目。
xxx.go
func init() {
Spider{
Name: "静态规则示例",
Description: "静态规则示例 [Auto Page] [http://xxx.xxx.xxx]",
// Pausetime: 300,
// Limit: LIMIT,
// Keyin: KEYIN,
EnableCookie: true,
NotDefaultField: false,
Namespace: nil,
SubNamespace: nil,
RuleTree: &RuleTree{
Root: func(ctx *Context) {
ctx.AddQueue(&request.Request{Url: "http://xxx.xxx.xxx", Rule: "登录页"})
},
Trunk: map[string]*Rule{
"登录页": {
ParseFunc: func(ctx *Context) {
ctx.AddQueue(&request.Request{
Url: "http://xxx.xxx.xxx",
Rule: "登录后",
Method: "POST",
PostData: "username=123456@qq.com&password=123456&login_btn=login_btn&submit=login_btn",
})
},
},
"登录后": {
ParseFunc: func(ctx *Context) {
ctx.Output(map[string]interface{}{
"全部": ctx.GetText(),
})
ctx.AddQueue(&request.Request{
Url: "http://accounts.xxx.xxx/member",
Rule: "个人中心",
Header: http.Header{"Referer": []string{ctx.GetUrl()}},
})
},
},
"个人中心": {
ParseFunc: func(ctx *Context) {
ctx.Output(map[string]interface{}{
"全部": ctx.GetText(),
})
},
},
},
},
}.Register()
}
FAQ
请求队列中,重复的URL是否会自动去重?
url默认情况下是去重的,但是可以通过设置Request.Reloadable=true忽略重复。
URL指向的页面内容若有更新,框架是否有判断的机制?
url页面内容的更新,框架无法直接支持判断,但是用户可以自己在规则中自定义支持。
请求成功是依据web头的状态码判断?
不是判断状态,而是判断服务器有无响应流返回。即,404页面同样属于成功。
请求失败后的重新请求机制?
每个url尝试下载指定次数之后,若依然失败,则将该请求追加到一个类似defer性质的特殊队列中。 在当前任务正常结束后,将自动添加至下载队列,再次进行下载。如果依然有没下载成功的,则保存至失败历史记录。 当下次执行该条爬虫规则时,可通过选择继承历史失败记录,把这些失败请求自动加入defer性质的特殊队列……(后面是重复步骤)
贡献者名单
| 贡献者 | 贡献内容 |
|---|---|
| henrylee2cn | 软件作者 |
| kas | surfer下载器中phantomjs内核 |
| wang898jian | 参与完全手册编写 |
第三方依赖包
go get github.com/pholcus/spider_lib go get github.com/henrylee2cn/teleport go get github.com/PuerkitoBio/goquery go get github.com/robertkrimen/otto go get github.com/andybalholm/cascadia go get github.com/lxn/walk go get github.com/lxn/win go get github.com/go-sql-driver/mysql go get github.com/jteeuwen/go-bindata/... go get github.com/elazarl/go-bindata-assetfs/... go get gopkg.in/mgo.v2 <以下需翻墙下载> go get golang.org/x/net/html go get golang.org/x/text/encoding go get golang.org/x/text/transform
(在此感谢以上开源项目的支持!)
有疑问加站长微信联系(非本文作者)




