
 爬虫框架 go_spider
爬虫框架 go_spider
##简介##
本项目基于golang开发,是一个开放的垂直领域的爬虫引擎,主要希望能将各个功能模块区分开,方便使用者重新实现子模块,进而构建自己垂直方方向的爬虫。
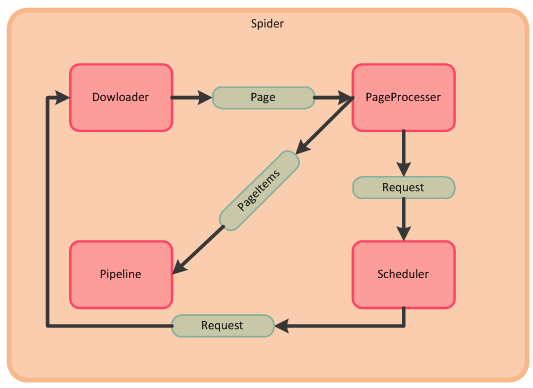
本项目将爬虫的各个功能流程区分成Spider模块(主控),Downloader模块(下载器),PageProcesser模块(页面分析),Scheduler模块(任务队列),Pipeline模块(结果输出);
##执行过程简述:##
- Spider从Scheduler中获取包含待抓取url的Request对象,启动一个协程,一个协程执行一次爬取过程,此处我们把协程也看成Spider,Spider把Request对象传入Downloader,Downloader下载该Request对象中url所对应的页面或者其他类型的数据,生成Page对象;
- Spider调用PageProcesser模块解析Page对象中的页面数据,并存入Page对象中的PageItems中(以Key-Value对的形式保存),同时存入解析结果中的待抓取链接,Spider会将待抓取链接存入Scheduler模块中的Request队列中;
- Spider调用Pipeline模块输出Page中的PageItems的结果;
- 执行步骤1,直至Scheduler中所有链接被处理完成,则Spider被挂起等待下一个待抓取链接或者终止。
执行过程相应的Spider核心代码,代码代表一次爬取过程:
// core processer
func (this *Spider) pageProcess(req *request.Request) {
// Get Page
p := this.pDownloader.Download(req)
if p == nil {
return
}
// Parse Page
this.pPageProcesser.Process(p)
for _, req := range p.GetTargetRequests() {
this.addRequest(req)
}
// Output
if !p.GetSkip() {
for _, pip := range this.pPiplelines {
pip.Process(p.GetPageItems(), this)
}
}
this.sleep()
}
项目安装与示例执行
- 安装本包和依赖包
go get github.com/hu17889/go_spider go get github.com/PuerkitoBio/goquery go get github.com/bitly/go-simplejson
示例执行:
- 编译:
go install github.com/hu17889/go_spider/example/github_repo_page_processor - 执行:
./bin/github_repo_page_processor
展示一个简单爬虫示例
示例的功能是爬取https://github.com/hu17889?tab=repositories下面的项目以及项目详情页的相关信息,并将内容输出到标准输出。
一般在自己的爬虫main包中需要实现爬虫创建,初始化,以及PageProcesser模块的继承实现。可以实现自己的子模块或者使用项目中已经存在的子模块,通过Spider对象中相应的Set或者Add函数将模块引入爬虫。本项目支持链式调用。
spider.NewSpider(NewMyPageProcesser(), "TaskName"). // 创建PageProcesser和Spider,设置任务名称
AddUrl("https://github.com/hu17889?tab=repositories", "html"). // 加入初始爬取链接,需要设置爬取结果类型,方便找到相应的解析器
AddPipeline(pipeline.NewPipelineConsole()). // 引入PipelineConsole输入结果到标准输出
SetThreadnum(3). // 设置爬取参数:并发个数
Run() // 开始执行
