
 S3 协议兼容的分布式对象存储系统 Yig
S3 协议兼容的分布式对象存储系统 Yig
Yig 是 S3 协议兼容的分布式对象存储系统。它脱胎于开源软件 [ceph](http://docs.ceph.com/docs/master/radosgw/) ,在多年的商业化运维中, 针对运维中出现的问题和功能上的新需求,重新实现了一遍 radosgw 用于解决以下问题:
单 bucket 下面文件数目的限制
大幅度提高小文件的存储能力
bucket 下面文件过多时,list 操作延迟变高
后台 ceph 集群在做 recovery 或者 backfill 时极大影响系统性能
提高大文件上传并发效率
设计一个新的存储系统解决以上问题,无非这些思路
隔离后台 rebalance 影响
根据 [haystack](https://www.usenix.org/legacy/event/osdi10/tech/full_papers/Beaver.pdf) 的论文,默认的 filestore 或者 bludestore ,并不特别适合小文件存储,需要新的存储引擎
radosgw 对 librados 提高的 omap 和 cls 用得太重,我们如何简化架构,让代码更容易懂,也更不容易出错。
更加统一的 cache 层,提高读性能
架构如图所见:
[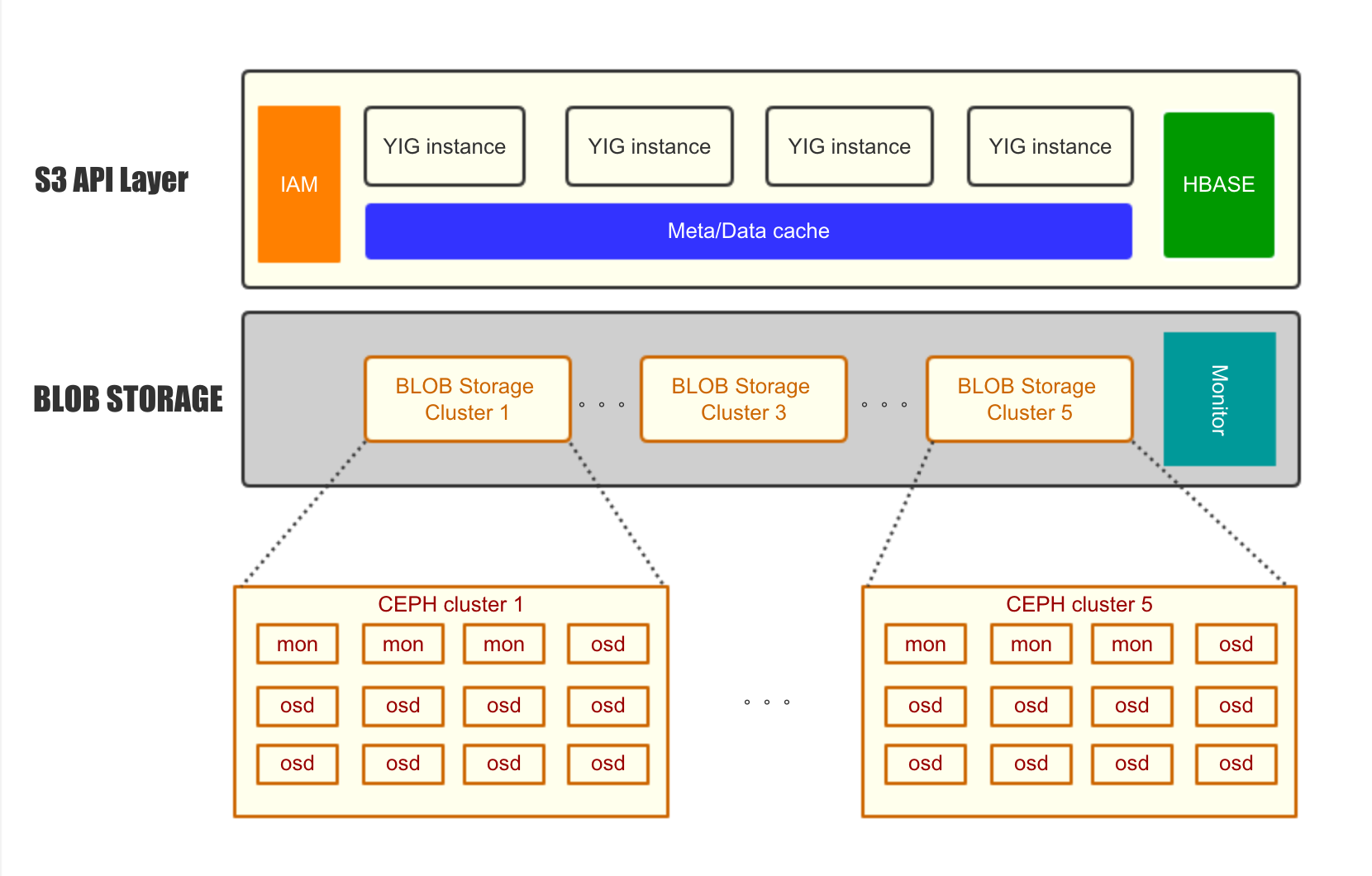](https://github.com/journeymidnight/yig/blob/master/doc/images/_image_1500993074_1458777923.png)
[](https://github.com/journeymidnight/yig/blob/master/doc/images/_image_1500993074_1458777923.png)从整体看,分为2层:
S3 API layer,负责 S3 API 的解析,处理。所有元数据存储在 [hbase](https://hbase.apache.org/) 中,元数据包括 bucket 的信息,object 的元数据(如ACL,contenttype),multipart 的切片信息,权限管理,BLOB Storage 的权值和调度。所以的元数据都 cache 在统一的 cache 层。可以看到所有元数据都存储在 hbase 中,并且有统一的 cache ,相比于 radosgw 大大提高的对元数据操作的可控性,也提高了元数据查询的速度。
BLOB Storage 层,可以并行的存在多个 Ceph Cluster 。只使用 rados_read/rados_write 的 API 。如果其中一个 ceph cluster 正在做 rebalance ,可以把它上面所有写请求调度到其他 ceph 集群,减少写的压力,让 rebalance 迅速完成。从用户角度看,所有的写入并没有影响,只是到这个正在 rebalance 的 ceph cluster 上的读请求会慢一点儿。大规模扩容也非常容易,比如存在这种情况,初期上线了5台服务器做存储,发现容量增加很快,希望加到50台,但是在原 ceph 集群上一下添加45台新服务器,rebalance 的压力太大。在 yig 的环境中,只要新建一个45台的 ceph 集群,接入 yig 的环境就行,可以快速无缝的添加容量。
对于大文件,相比与 radosgw 每次使用 512K 的 buf ,用 rados_write 的 API 写入 ceph 集群,yig 使用动态的 buf ,根据用户上传的速度的大小调整 buf 在 (512K~1M) 之间。 并且使用 [rados striping](http://docs.ceph.com/docs/master/dev/file-striping/) 的 API 提高写入的并发程度。让更多的 OSD 参与到大文件的写入,提高并发程度。 拆分方法如图:
[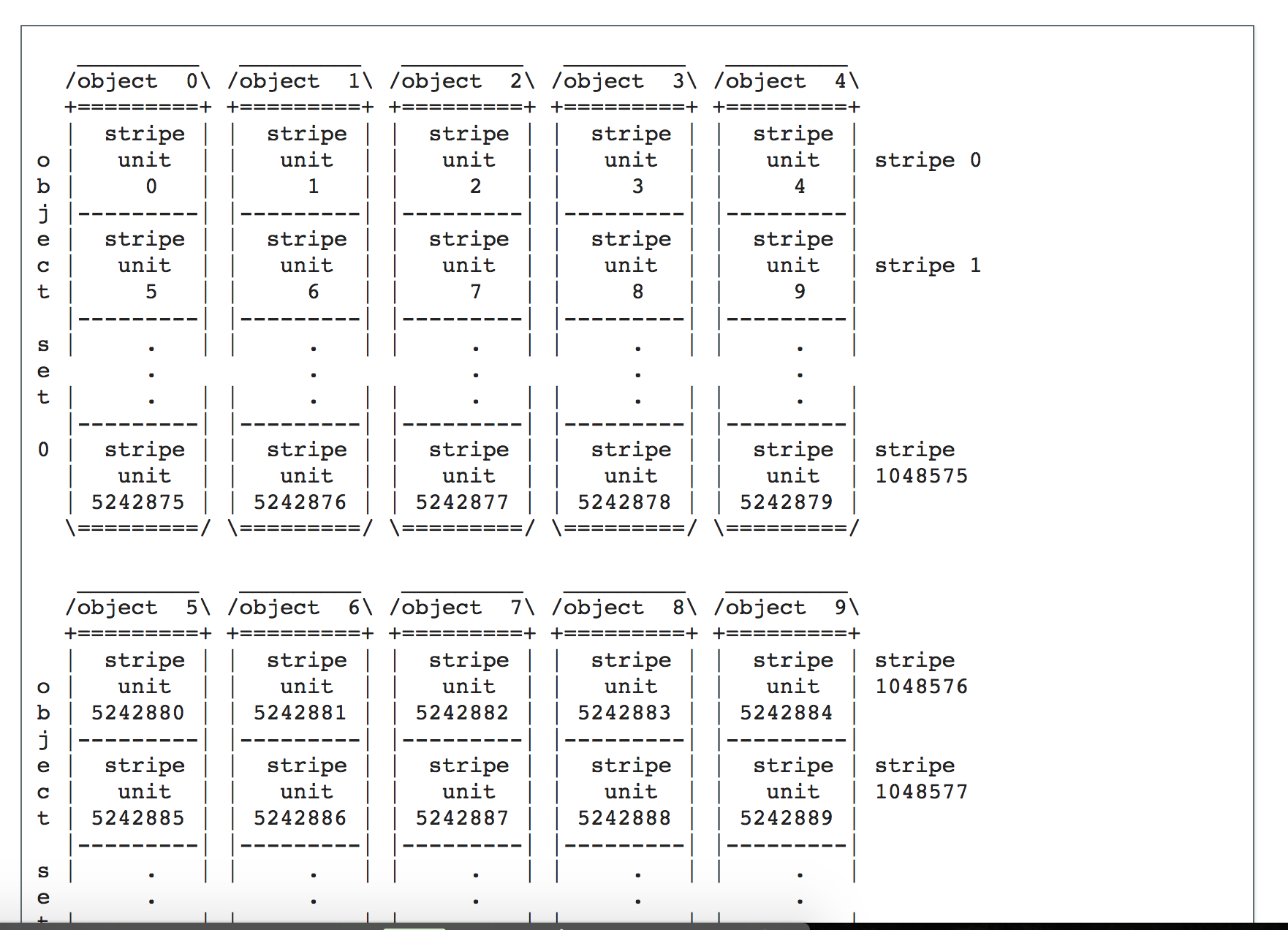](https://github.com/journeymidnight/yig/blob/master/doc/images/_image_1502863860_101027544.png)
针对小文件,直接使用 kvstore 存储,底层使用 rocksdb ,这个方案相比与 bluestore 或者 filestore 更轻。性能更好。但是要注意2点:
默认的 kvstore 并没有打开布隆过滤器,需要在 ceph 的配置文件中配置打开,否则读性能会很差
在 Ceph 的 replicatePG 层,每次写 object 之前,都会尝试读取原 Object ,然后在写入。这个对于 rbd 这种大文件的应用影响不大,但是对于小文件写入就非常糟糕。 所以我们在 rados 的请求中加入的一个新的 FLAG: LIBRADOS_OP_FLAG_FADVISE_NEWOBJ,在 replicatedPG 中会检查是否有这个 FLAG ,如果有,就不会尝试读取不存在的小文件。通过这个 patch ,可以极大的提升小文件的写入性能和降低 cpu 的利用率。
因为采用了标准的 S3 接口,可以使用标准的工具。
采用标准的 [python boto](http://boto.cloudhackers.com/en/latest/ref/s3.html) 库测试 yig
复用 ceph 社区的 [s3-test](https://github.com/ceph/s3-tests) 项目测试 yig
ceph cluster 性能测试原始 ceph 性能,使用 [rados bench](http://tracker.ceph.com/projects/ceph/wiki/Benchmark_Ceph_Cluster_Performance) 测试4k小文件的随机读写。
使用 [wrk](https://github.com/wg/wrk) 配合 lua 脚本测试 S3 API
使用 [ycsb](https://github.com/brianfrankcooper/YCSB) 测试 S3 API 性能
部分性能测试数据: 测试平台: 后台3台物理机,ceph 采用普通硬盘,hbase 采用普通硬盘,3副本方案 测试场景:写入1K小文件,然后测试在 90% read 和 10% write 的情况下(类似有于线上环境)的性能数据 测试结果:
load 数据阶段性能: 可以看到即使是在3副本的情况下,S3 写入 iops 仍然很高,可以注意到没割一段时间,iops 的的性能会下降,这是由于 rocksdb 后台在做 compaction 。
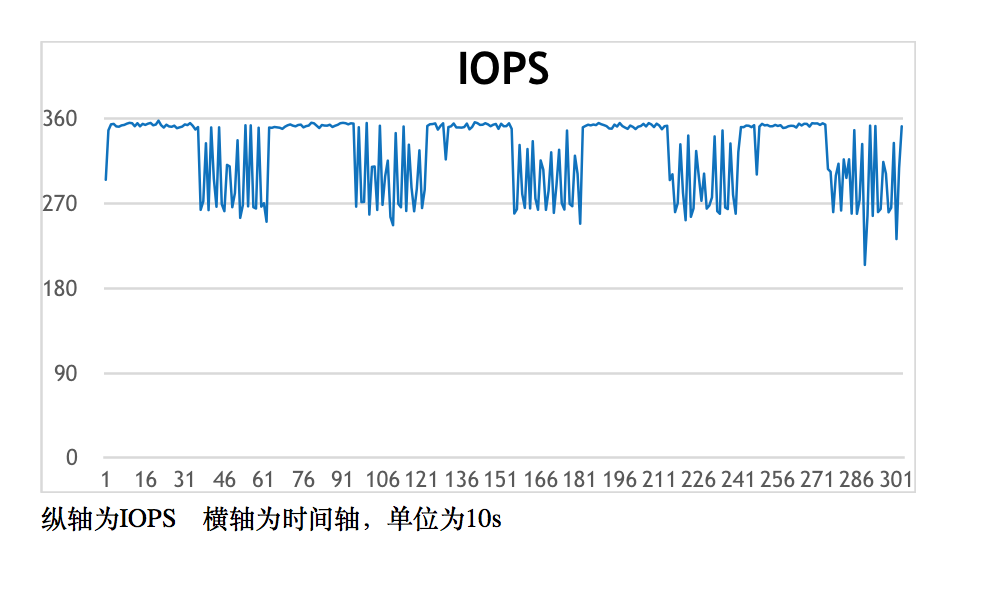
模拟线上环境性能:
由于是读多写少的环境,iops 相比于纯写入有很大提升,也不容易发生 compact ,所以 iops 能维持在较高的水平。延迟情况是90%以上的请求延迟小于1s,平均延迟就更小了。
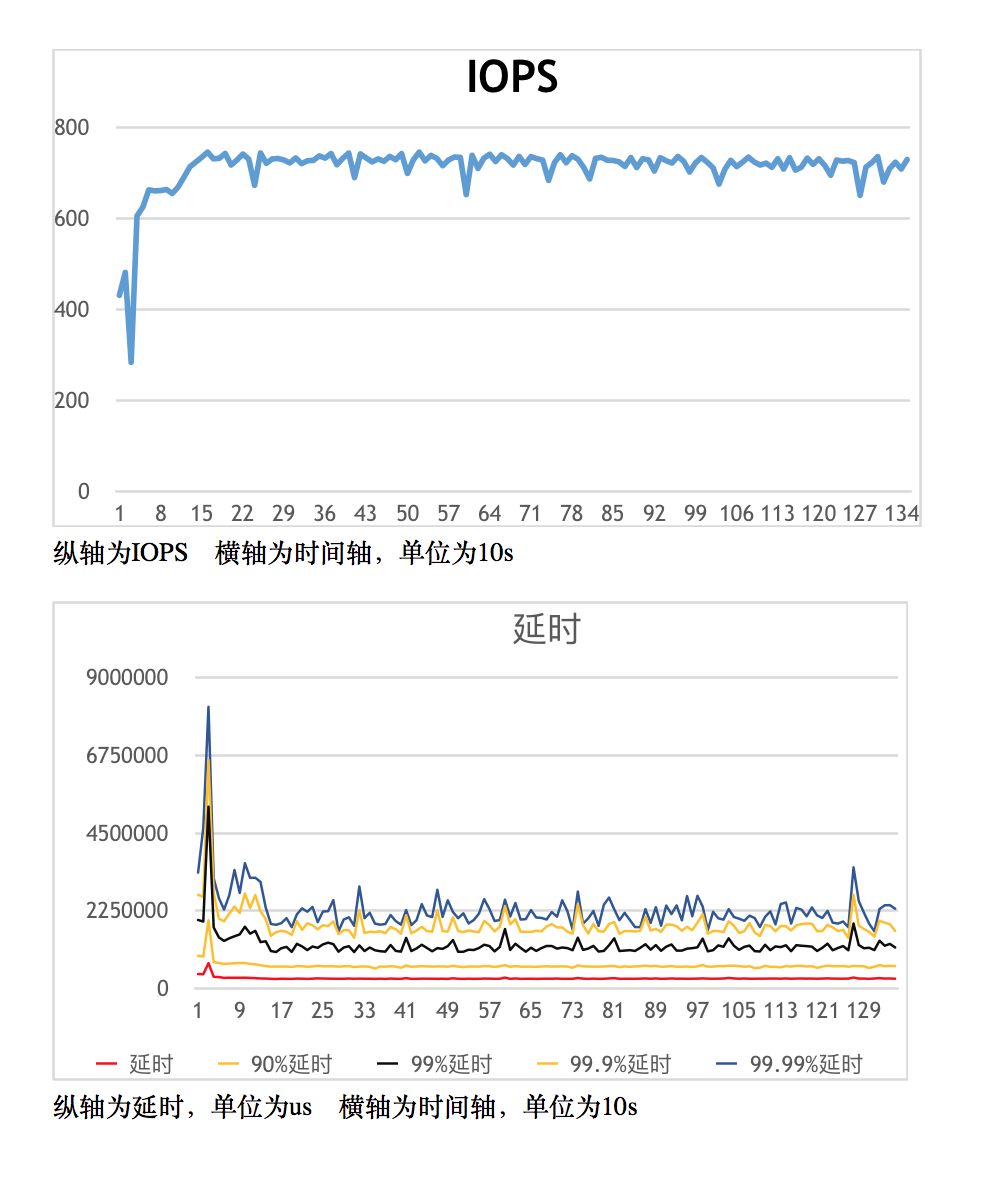
- 授权协议:
- Apache 2.0
- 开发语言:
- Google Go 查看源码»
- 操作系统:
- 跨平台
