推送在外卖订餐中扮演着重要的角色,为商家实时接单、骑手实时派单提供基础的数据通道。早期推送是由第三方服务商提供的, 随着业务复杂度的提升、订单量和用户数的持续增长,之前的系统已经远远不能满足需求,构建一个高性能、高可用的推送系统势在必行。 今年上半年我们用go开发了一个hybrid push服务,用户在线则借助长连接下发消息,不在线则借助厂商或第三方通道下发消息。 在构建过程中遇到了些与 goroutine stack 相关的问题,这里就和大家扯一扯。
带着问题阅读,才能让阅读更加高效,首先让我们看下问题:
- goroutine stack多大呢?是固定的还是动态变化的呢?
- stack动态变化的话,什么时候扩容和缩容呢?如何实现的呢?
- 对服务有什么影响吗?如何排查栈扩容缩容带来的问题呢?
问题明确了,我们就开始往下扯呗。
栈大小
在了解协程栈之前,我们先看下传统的Linux进程内存布局:
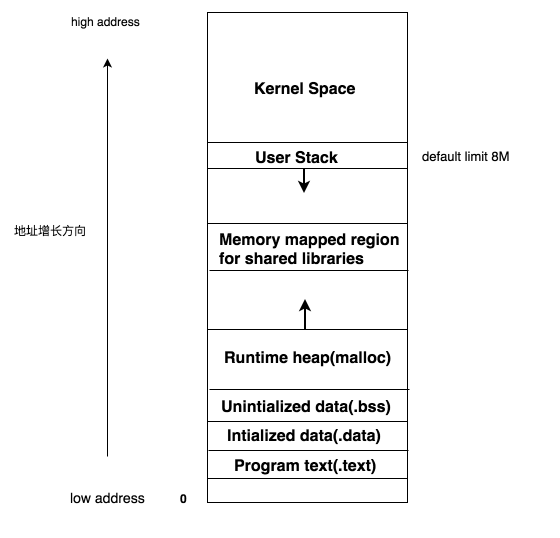
user stack的大小是固定的,Linux中默认为8192KB,运行时内存占用超过上限,程序会崩溃掉并报告segment错误。 为了修复这个问题,我们可以调大内核参数中的stack size, 或者在创建线程时显式地传入所需要大小的内存块。 这两种方案都有自己的优缺点, 前者比较简单但会影响到系统内所有的thread,后者需要开发者精确计算每个thread的大小, 负担比较高。
有没有办法既不影响所有thread又不会给开发者增加太多的负担呢? 答案当然是有的,比如: 我们可以在函数调用处插桩, 每次调用的时候检查当前栈的空间是否能够满足新函数的执行,满足的话直接执行,否则创建新的栈空间并将老的栈拷贝到新的栈然后再执行。 这个想法听起来很fancy & simple, 但当前的Linux thread模型却不能满足,实现的话只能够在用户空间实现,并且有不小的难度。
go作为一门21世纪的现代语言,定位于简单高效,充分利用多核优势,解放工程师,自然不能够少了这个特性。它使用内置的运行时runtime优雅地解决了这个问题, 每个routine(g0除外)在初始化时stack大小都为2KB, 运行过程中会根据不同的场景做动态的调整。
栈扩容和缩容
在介绍具体的栈处理细节之前,我们先了解下协程栈的内存布局和一些重要的术语:
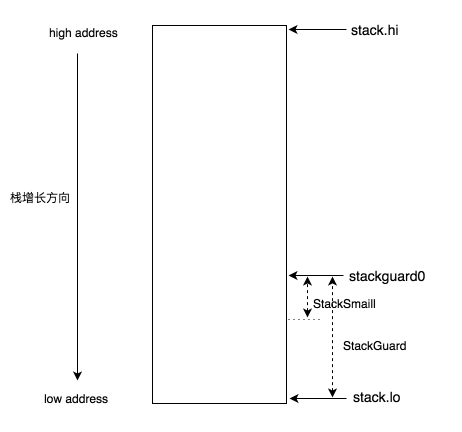
- stack.lo: 栈空间的低地址
- stack.hi: 栈空间的高地址
- stackguard0: stack.lo + StackGuard, 用于stack overlow的检测
- StackGuard: 保护区大小,常量Linux上为880字节
- StackSmall: 常量大小为128字节,用于小函数调用的优化
在判断栈空间是否需要扩容的时候,可以根据被调用函数栈帧的大小, 分为以下两种情况:
小于StackSmall
SP小于stackguard0, 执行栈扩容,否则直接执行。
大于StackSamll
SP - Function’s Stack Frame Size + StackSmall 小于stackguard0, 执行栈扩容,否则直接执行。
runtime中还有个StackBig的常量,默认为4096,被调用函数栈帧大小大于StackBig的时候, 一定会发生栈的扩容,这里就不再展开了。
下面通过一个简单的函数调用,来观察下栈的处理:
|
禁用优化和内敛进行编译 go tool compile -N -l -S stack.go > stack.s , 部分汇编代码如下:
|
通过上面的汇编码,可以看到当被调用函数栈帧小于StackSmall的时候没有执行栈空间大小判断而是直接执行,在一定程度上优化了小函数的调用。 大于StackSmall的,会执行栈空间大小判断,栈空间不足的时候,通过调用runtime.morestack_noctxt来完成栈的扩容,然后再重新开始执行函数。
go在1.3之前栈扩容采用的是分段栈(Segemented Stack),在栈空间不够的时候新申请一个栈空间用于被调用函数的执行, 执行后销毁新申请的栈空间并回到老的栈空间继续执行,当函数出现频繁调用(递归)时可能会引发hot split。为了避免hot split, 1.3之后采用的是连续栈(Contiguous Stack),栈空间不足的时候申请一个2倍于当前大小的新栈,并把所有数据拷贝到新栈, 接下来的所有调用执行都发生在新栈上。
栈扩容和拷贝不是件容易的事情,涉及到很多内容和细节,这里只介绍下基本过程和算法意图,不会深入到所有细节。
runtime.morestack_noctxt是用汇编实现的,以下是amd64架构的部分代码(runtime/asm_amd64.s):
|
newstack是用go实现的,可读性很高也很有意思,大家有空可读读,基本过程就是分配一个2x大小的新栈, 把数据拷贝到新栈,并用新栈替换到旧栈, 下面是部分代码(runtime/stack.go):
|
扯完了扩容,我们来看看缩容。一些long running的goroutine可能由于某次函数调用中引发了栈的扩容, 被调用函数返回后很大部分空间都未被利用,为了解决这样的问题,需要能够对栈进行收缩,以节约内存提高利用率。
栈收缩不是在函数调用时发生的,是由垃圾回收器在垃圾回收时主动触发的。基本过程是计算当前使用的空间,小于栈空间的1/4的话, 执行栈的收缩,将栈收缩为现在的1/2,否则直接返回。下面是栈收缩的部分代码(runtime/stack.go):
|
扩缩容影响
在正常的http service、rpc service中,栈扩容和收缩的影响几乎可以忽略不计,大家在排查问题的时候可以直接跳过。 在一些对内存占用、延时敏感的服务中,要特别注意,否则将可能面临内存占用高、服务不稳定的状况。
我们用go构建的hybrid push服务,每个连接都是全双工的,使用两个routine来分别处理读写,刚开始上线压测时内存占用非常高,甚至出现OOM的情况。
刚开始怀疑堆占用过高,通过runtime和pprof排查,堆占用和预期设想的一样,
并没有太多的问题 ,一度非常头大。后来通过curl -s http://localhost:port/debug/pprof/heap?debug=1 | grep -A 20 runtime.MemStats
查看MemStats状态,发现Stack占用很高甚至达到了20G,基本上就确定了问题是由栈造成的,接下来就可以通过工具来定位具体的原因了。
我们借助了perf和FlameGraph来trace函数调用,下面是部分截图:
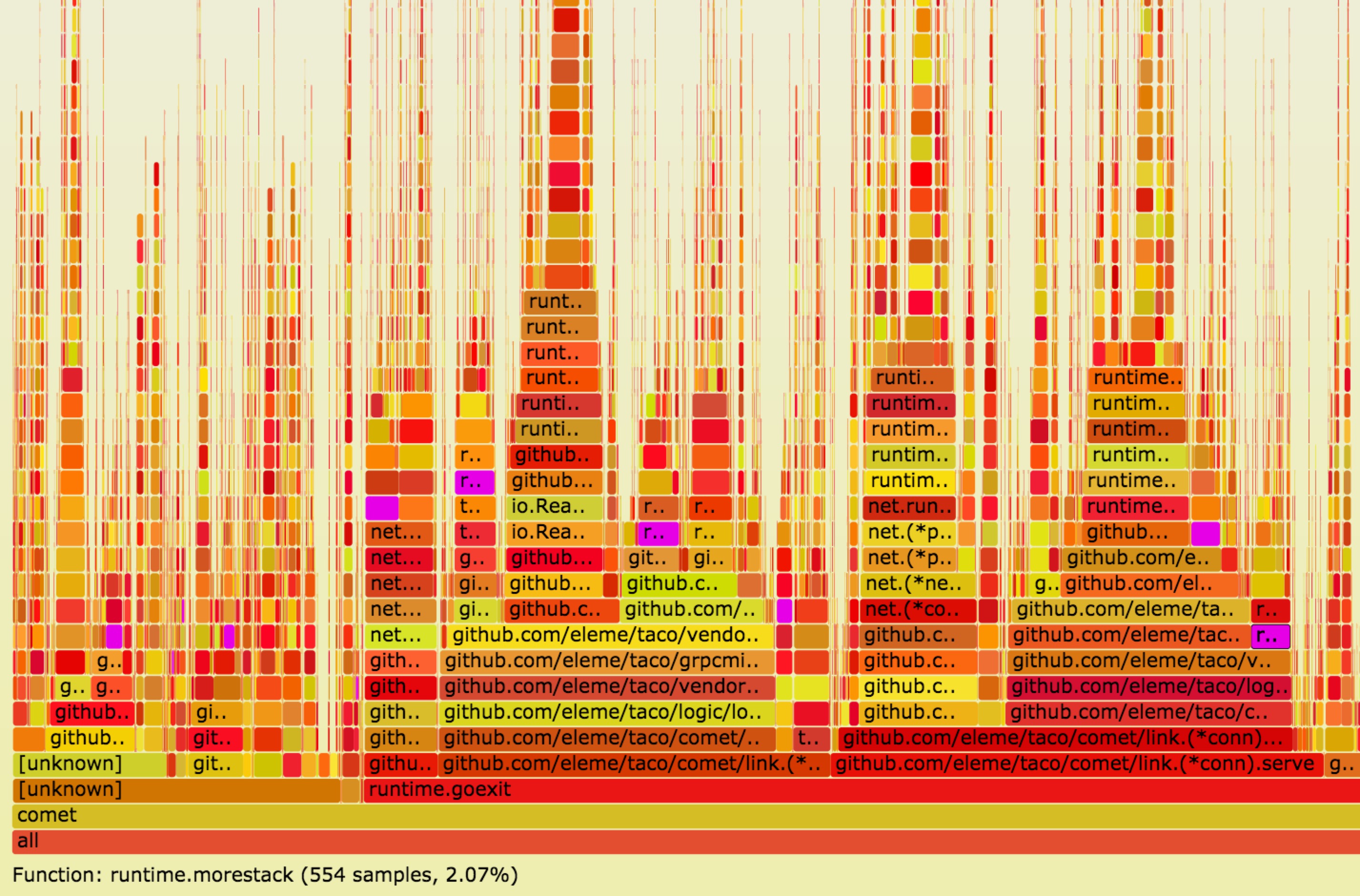
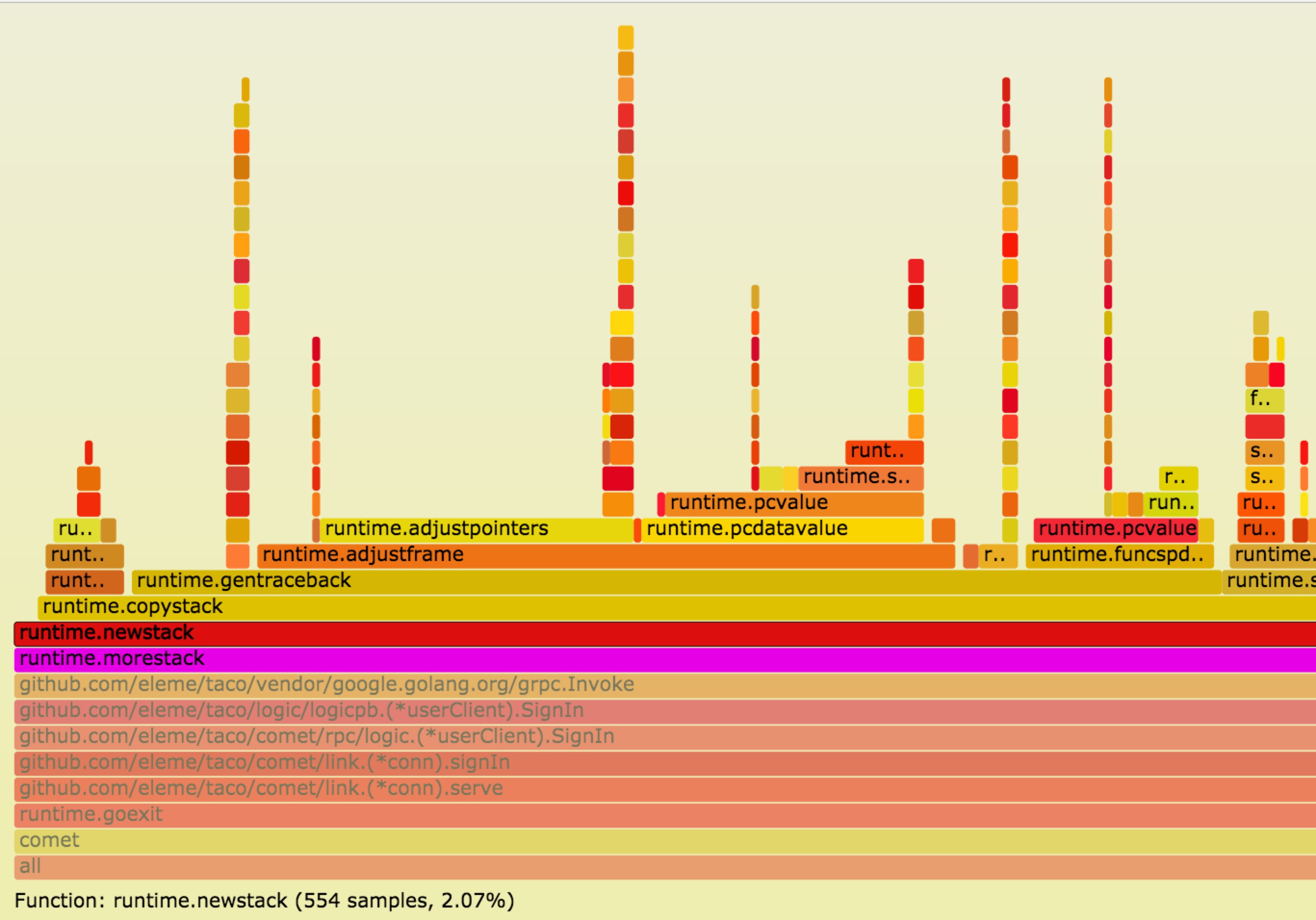
可以看到在rpc调用(grpc invoke)时,栈会发生扩容(runtime.morestack),也就意味着在读写routine内的任何rpc调用都会导致栈扩容, 占用的内存空间会扩大为原来的两倍,4kB的栈会变为8kB,100w的连接的内存占用会从8G扩大为16G(全双工,不考虑其他开销),这简直是噩梦。
解决这个问题的方案有很多,我们选择了channel和worker group,读写routine只负责流量和连接处理,逻辑处理的部分完全交给worker。 优化后,读写routine各占用4KB内存,运行过程中都不会出现栈扩容的问题,单机(24core 32G memory)可以承载100W连接和每秒2~3w消息的发送(512 ~ 1024 byte)。
上面介绍到栈缩容的目标是提高内存利用率,但在缩容过程中会存在栈拷贝和写屏障(write barrier),对于一些准实时应用可能会存在一些影响。 好在go提供了可设置的参数,需要的话大家可以通过设置环境变量 GODEBUG=gcshrinkstackoff=1 来关闭栈缩容。关闭栈缩容后, 需要承担栈持续增长的风险,在关闭前需要慎重考虑。
如果想查看程序运行过程中栈alloc、扩容、拷贝和缩容细节的话,可以通过设置stackDebug变量(runtime/stack.go)为非0,
然后重新编译程序(记得要重新编译runtime, 编译时加入-a参数),就可以看到所有栈操作的细节了。
暂时没有找到更好的设置方式比如GODEBUG之类的,如果大家更好的办法,欢迎告诉我。
备注
上面的所有常量和代码,都是基于Linux x86_64架构,go 1.8.3版本的。




