
这篇文章给出了一个我们最新项目的技术概述和架构设计理由,corral —— 一个无服务的 MapReduce 框架。
我最近在用 Hadoop 和 Spark 为一个我帮助教学的班级工作。PySpark 的确很棒,但是 Hadoop MapReduce 我从来没有真正关注,直到我发现 [mrjob](https://pythonhosted.org/mrjob/)。MapReduce 的观念是极为强大的,但是大量的样板文件需要用 Java 编写,甚至是一个简单的 Hadoop 作业,在我看来那是不必要的。
Hadoop 和 Spark 也需要了解一些基础设施知识。一些服务像 [EMR](https://aws.amazon.com/emr/) 和 [Dataproc](https://cloud.google.com/dataproc/) 使其更方便,但是需要很大的成本。
曾经有些关于使用 Lambda 做为 MapReduce 平台的谣言。AWS 发布了一个(有限的)参考框架结构,并且有些企业解决方案好像也采用了这种方法。但是,我没有找到一个完全使用这个方法的开发的开源项目。
与此同时,AWS 宣布本地 Go 对 Lambda 的支持。Go 的启动时间短,易于部署(即单二进制包),和通用的速度使其成为该项目的理想选择。
我的想法是:使用 Lambda 作为一个执行环境,类似 Hadoop MapReduce 使用 YARN。本地驱动程序协调函数调用,S3 用于数据存储。

这是 [corral](https://github.com/bcongdon/corral) 的结果,一个用于编写可在 AWS Lamb
da 中执行的任意 MapReduce 应用程序框架。
## MapReduce 的 Golang 接口
众所周知,Go 没有泛型,所以我不得不为 mappers 和 reducers 构建一个令人信服的接口而动些脑筋。Hadoop MapReduce 在指定输入/输出格式,分割记录的方式等方面有很大的灵活性。
我之前考虑用 interface{} 类型做为健和值,但用 [Rob Pike 的话](https://www.youtube.com/watch?v=PAAkCSZUG1c&t=7m36s)说,“interface{} 什么也没说”。所以我决定使用极简主义接口:keys 和 values 都用字符串,输入文件按换行符分割。这些简化假设使整个系统的实现更简单和清晰。Hadoop MapReduce 赢得可定制性,因此我决定采用易用性。
我很满意 Map 和 Reduce 的最终接口(其中一些是受 Damian Gryski 的 [dmrgo](https://github.com/dgryski/dmrgo) 启发):
```go
type Mapper interface {
Map(key, value string, emitter Emitter)
}
type Reducer interface {
Reduce(key string, values ValueIterator, emitter Emitter)
}
type Emitter interface {
Emit(key, value string) error
}
```
`ValueIterator` 只有一个方法:`Iter()`,迭代一系列字符串。
`Emitter` 和 `ValueIterator` 隐藏了需要内部框架实现(改组,分区,文件系统交互等)。我也很高兴决定对值用迭代器来代替普通的切片(这可能更惯用),因为迭代器允许框架方面更加的灵活(例如:延迟流值而不是全部放入内存)。
## 无服务 MapReduce
从框架方面,我花了些时间来决定用一个高效的方式将 MapReduce 实现为一个完全无状态的系统。
Hadoop MapReduce 架构为其带来以下好处……
- 持久,长时间运行的工作节点
- 数据局部性在工作节点
- 通过 YARN/Mesos 等作为抽象的,容错的主节点和工作节点容器。
使用 AWS 堆栈可以很容易地复制最后两方面。S3 和 Lambda 之间的带宽相对不错(至少对我而言),而 Lambda 的构建使得开发人员“不必考虑服务器”。
在 Lambda 上复制最棘手的事情是持久工作节点。Lambda 有最大5分钟的超时时限。因此,Hadoop 使用 MapReduce 的很多方式都不再适用。例如,在 mapper worker 和 reducer worker 之间直接传输数据是不可行的,因为 mapper 需要“尽快”完成。否则,在 reducer 仍在工作时,您可能会冒 mapper 超时的风险。
这种限制在 shuffle/partition 阶段最明显。理想情况下,mappers 将“生存”足够长的时间以按需将数据传输到 reducers(即使在 map 阶段),并且 reducers 将“活”足够长时间去做一个完整的二级排序,使用它们的磁盘当对一个较大的合并排序溢出时。5分钟的上限使得这些方法难以实现。
最后,我决定使用 S3 作为无状态 partition/shuffle 的后端。

对 mapper 输出使用友好的前缀名称,可以方便 reducers 轻松选择它们需要读取的文件。
处理输入数据显然更为直接。与 Hadoop MapReduce 一样,输入文件被拆分为块。Corral 将这些文件块分组为“输入箱”,并且每个 mapper 读取/处理一个输入箱。输入拆分和容器大小是可以根据需要进行配置的。

## 自发布应用
Corroal 让我最兴奋的一点是,它能够自我部署到 AWS Lambda。我希望能够快速将 corral 作业部署到 Lambda 上——不得不通过 web 界面手动将发布包重新上传到 Lambda 上是一种拖累,而像 Serverless 这样的框架依赖于非 Go 工具,这些工具包含起来很繁琐。
我最初的想法是,构建 corral 二进制文件作为发布包上传到 Lambda 上。这个想法确实有效……直到您处理跨平台构建目标时。Lambda 期望使用 `GOOS=linux` 编译二进制文件,因此任何二进制文件在 macOS 或 Windows 上不能运行。
我几乎放弃了这个想法,但后来我偶尔发现了 Kelsey Hightower 在2017年的GopherCon上发布的 [Self Deploying Kubernetes Applications](https://www.youtube.com/watch?v=XPC-hFL-4lU)。Kelsey 描述了一个类似的方法,尽管他的代码是在 Kubernetes 而不是 Lambda 上运行的。但是,他描述了我需要的“缺失链接”:让特定平台的二进制文件重新编译为目标 GOOO=linux。
因此,总而言之,corral 用于部署到 Lambda 的过程如下:
1. 用户编译针对其所选平台的 corral 应用程序。
2. 在执行时,corral app 为 GOOS=linux 重新编译自己,并将生成的二进制文件压缩为 zip 文件。
3. 然后 Corral 上传 zip 文件到 Lambda,创建一个 Lambda 函数。
4. Corral 调用此 Lambda 函数作为 map/reduce 任务的执行程序。
通过在运行时对环境进行一些巧妙的检查,Corral 能够使用与驱动程序和远程执行程序完全相同的源码。如果二进制文件检测到它在 Lambda 环境中,则它会监听调用请求;否则它表现正常。
顺便说一句,自我上传或自我重新编译应用程序的想法对我来说是相当兴奋的。我记得当我上计算机理论课时,“自嵌入”程序的概念(通常在不可判断性证明的上下文中引用)是很有趣的。但我想不到你确实想要一个程序使用内部反射的案例。
在某种程度上,自我发布应用程序是这个想法的实际例子。它是一个自我重编,上传到云上的程序,并远程调用自己(尽管通过不同的代码路径)。够整洁!
一旦部署后,这个 corral 上传到 Lambda 的二进制文件有条件地表现为 Mapper 或 Reducer,具体取决于它的调用输入。您在本地执行的二进制文件在 Map/Reduce 阶段保持运行并调用 Lambda 函数。

系统中的每个组件都运行相同的源,但有很多并行副本运行在 Lambda 上(由驱动协调)。这导致 MapReduce 快速的并行。
## 像文件系统一样对待S3
像 mrjob 一样,Corral 试图与它运行到文件系统无关。这允许它在本地和 Lambda 执行之间透明地切换(并允许扩展空间,例如,如果 GCP 在云函数上开始支持 Go)。
但是,S3 不是一个真正的文件系统;他使一个对象存储。像文件一样使用 S3 需要一点聪明。例如,当读取输入分割时,corral 需要寻找文件的某个部分并开始阅读。默认情况下,对 S3 的 GET 请求将返回整个数据。当您的对象可能几十千兆字节时,这并不是很好。
幸运的是,您可以在 S3 的 GET 请求中设置一个 [Range 请求头](https://docs.aws.amazon.com/AmazonS3/latest/API/RESTObjectGET.html#RESTObjectGET-requests-request-headers)以接收对象块。Corral 的 [S3FileSystem](https://github.com/bcongdon/corral/blob/master/internal/pkg/corfs/s3.go#L104) 利用这一点,根据需要下载一个对象块。
写入 S3 也需要一些思考。对于较小的上传,一个标准的“PUT Object”请求就可以。对于较大的上传,[分段上传](https://docs.aws.amazon.com/AmazonS3/latest/dev/mpuoverview.html)变得更具吸引力。分段上传允许功能等同于写入本地文件;您将数据流传输到文件,而不是将其保留在内存中一次写入所有内容。
令我惊讶的是,没有一个出色的 S3 客户端提供 io.Reader 和 io.Writer 接口。[s3gof3r](https://github.com/rlmcpherson/s3gof3r) 是我能找到最接近的了;它非常出色,但(以我的经验)泄露了太多内存,我无法在内存有限的 Lambda 环境中使用它。
## 在 Lambda 上管理内存
虽然 AWS Lambda 在过去几年中一直在增长,但感觉缺少分析 Lambda 函数的 工具。默认,Lambda 把日志记在 Cloudwatch。如果您的函数报错,则错误堆栈会被记录下来。因此,“崩溃”错误调试相对简单。
但是,如果您的函数耗尽内存或时间,您看到的是这样:
```
REPORT RequestId: 16e55aa5-4a87-11e8-9c63-3f70efb9da7e Duration: 1059.94 ms Billed Duration: 1100 ms Memory Size: 1500 MB Max Memory Used: 1500 MB
```
在本地,像 [pprof](https://golang.org/pkg/runtime/pprof/) 这样的工具非常适合了解内存泄露的来源。但在 Lambda 你就没那么好运了。
在 corral 早期的版本中,我花了几个小时追踪由 [s3gof3r](https://github.com/rlmcpherson/s3gof3r) 引起的内存泄露。由于 [Lambda 容器](https://aws.amazon.com/blogs/compute/container-reuse-in-lambda/)可以重复使用,即使很小的内存泄露也会导致最终的故障。换句话说,内存使用在调用中持续存在——漏洞抽象(没有双关语)。
能看到为 AWS Lambda 的分析工具真是太棒了,特别是因为 Golang 是一个对分析非常容易的运行环境。
## 当 Lambda 变的昂贵
显然,corral 的目标是对 Hadoop MapReduce 提供一个便宜,快速的选择。AWS Lambda 是便宜的,所以这是一个大扣篮,对吧?
是,不是。Lambda 的免费等级每月为您提供 400,000 GB/秒。这听起来很多,但是长时间运行的应用程序很快就会用完。
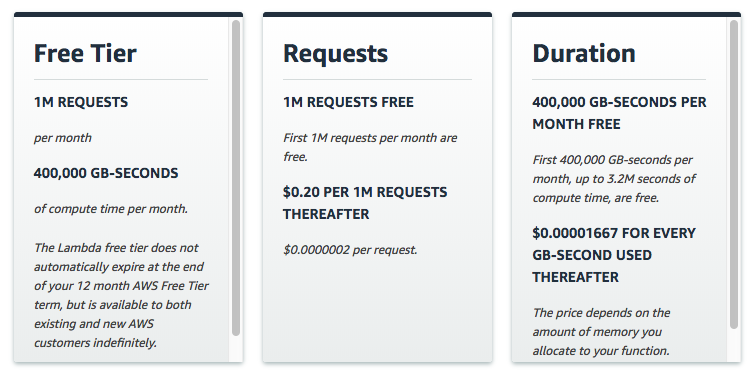
最终,corral 仍然能非常便宜。但是,您需要调整应该程序以尽可能少使用内存。在 corral 设置最大内存上限尽可能降低成本。
在 AWS Lambda 时间是一个 as-you-use-it 资源——您需要支付的使用时间为毫秒。内存是通过 use-it-or-lose-it 计费的。如果您设置最大内存为 3GB 但仅用了 500MB ,您仍然需要为全部 3GB 内存付费。
## 表现
虽然不是主要的设计考虑因素,但 corral 的表现相对可观。其中很大一部分原因归功于 Lambda 提供的几乎无限的并行性。我使用 [Amplab 的"大数据基准"](https://amplab.cs.berkeley.edu/benchmark/)来了解一下 corral 的表现。这个基准测试基本的过滤,聚合和连接。
正如我所料,corral 在过滤和聚合方面做得相当好。然而,它在连接方面表现平平。没有[二级排序](https://www.safaribooksonline.com/library/view/data-algorithms/9781491906170/ch01.html),连接变得昂贵。
Amplab 基准测试可测高达大约 125GB 的输入数据。我很好奇用大约 1TB 的数据做更多的基准测试,看看性能是否会线性地或多或少的变化。
[在 corral 示例文件夹](https://github.com/bcongdon/corral/tree/master/examples)中能找到更多信息和基准测试统计。
## 结论
就是这样:corral 让您编写一个简单的 MR 作业,无摩擦地将其发布到 Lambda ,并在 S3 的数据集上运行该作业。

值得注意的是,我没有与 AWS 生态系统结合。Corral 与 Lambda 和 S3 毫无关系,因为将来可以添加 GCP 的云函数和数据存储的连接器(if/when GCP 添加 CF 支持 Go)。
就个人而言,我发现这个项目对工作相当有益。构建 MapReduce 系统的在线资源要少于使用它的,因此有一些实现细节需要解决。
随意在 [corral 库](https://github.com/bcongdon/corral)中提出问题。我很想知道这个项目是否有足够的市场来证明有必要持续发展。:smile:
via: https://benjamincongdon.me/blog/2018/05/02/Introducing-Corral-A-Serverless-MapReduce-Framework/
作者:Benjamin Congdon 译者:themoonbear 校对:polaris1119
本文由 GCTT 原创翻译,Go语言中文网 首发。也想加入译者行列,为开源做一些自己的贡献么?欢迎加入 GCTT!
翻译工作和译文发表仅用于学习和交流目的,翻译工作遵照 CC-BY-NC-SA 协议规定,如果我们的工作有侵犯到您的权益,请及时联系我们。
欢迎遵照 CC-BY-NC-SA 协议规定 转载,敬请在正文中标注并保留原文/译文链接和作者/译者等信息。
文章仅代表作者的知识和看法,如有不同观点,请楼下排队吐槽
有疑问加站长微信联系(非本文作者))





