
Hi Everyone,
A few days ago, I'm decide rewrote Antch project, Its open source web crawler framework that inspired by Scrapy project.
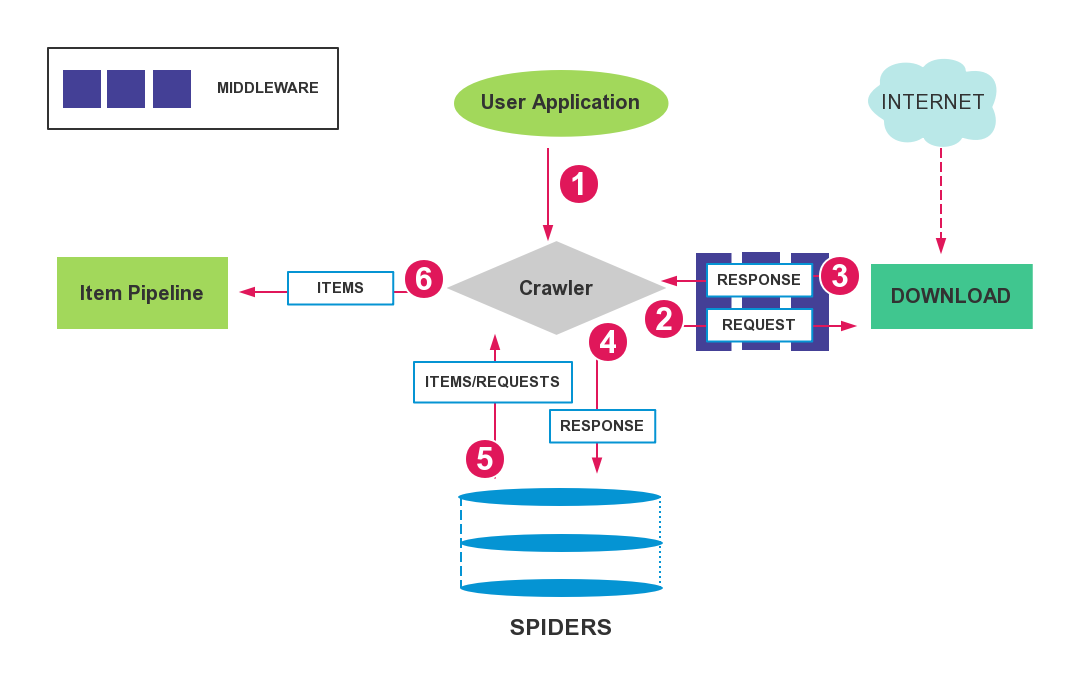
The Antch had two core components: Middleware and Item Pipeline, the Middleware component is for HTTP download(etc, robots.txt, cookies, gzip), the Item Pipeline Component is for to process received Item data that from the Spider Handler.
the built-in Middleware include:
- robots.txt
- proxy(HTTP,HTTPS,SOCKS5)
- cookies
- gzip
Everything can make as Middleware if you want, its easy to extensible.
This jpg file overview the whole architecture design, view jpg, like the scrapy architecture.
Project: https://github.com/antchfx/antch
The next plan is build a distributed web crawler that building on the Antch project.
Does anyone have any idea or suggestions?
评论:
flatMapds:
menuvb:I have done something similar before, in my security research.
Well honestly a big thing you should invest in for a distributed web crawler is scheduling / lb algorithms built into the clients, I followed this variation of P2C https://cs.stanford.edu/~matei/papers/2013/sosp_sparrow.pdf , also another thing that saves up a good bit of work, as you go along, is writing an endpoint that has a bloom filter to check if a link is found before it's submitted to the workers, preferabley one that is mergable along with any other state, also for the sake of avoided duplicate work being sent instead of simply replicating requests to N masters to trigger the state change, I suggest you should just have them periodically pull eachother to merge such state.
As for what kind of state you may have, worker membership, bloom filter, and master membership.
matiasbaruch:Thanks for you suggestion, this project just begin starting, and lack of some middleware/Components, such as filter duplicate URLs, HTTP link depth tracking,etc...
Before start distributed web crawler(if i'm still want), need a lot of time to made this framework more availability and extensible.
Interesting, I've recently started to play around the idea of a web crawling platform (something similar to ScrapingHub or Apify but completely open source), using Go. I won't provide a framework for implementing the crawlers so the goal is to support whatever you need to deploy/orchestrate, collect the data from them, etc., even if they're written in different languages.
In case you're curious you may find it here: https://github.com/zcrawl/zcrawl


{kind=link}