
原文链接:[https://www.ikaze.cn/article/43](https://www.ikaze.cn/article/43)
---
写这篇博文的起因是,我在论坛宣传我开源的新项目[YTask](https://github.com/gojuukaze/YTask)(go语言异步任务队列)时,有小伙伴在下面回了一句“为什么不用nsq?”。这使我想起,我在和同事介绍celery时同事说了一句“这不就是kafka吗?”。
那么YTask和nsq,celery和kafka?他们之间到底有什么不同呢?下面我结合自己的理解。简单的分析一下,如有不足请指出。

首先,nsq和kafka它们属于消息队列;YTask和celery它们属于任务队列。
消息队列和任务队列,最大的不同之处就在于理念的不同 -- **消息队列传递的是“消息”,任务队列传递的是“任务”**。
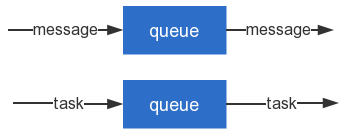
这句话何解呢?

我们可以放到具体的应用场景上:
- 消息队列用来快速消费队列中的消息。比如日志处理场景,我们需要把不同服务器上的日志合并到一起,这时就需要用到消息队列。
- 任务队列是用来执行一个耗时任务。比如用户在购买的一件物品后,通常需要计算用户的积分以及等级,并把它们保存到数据库。这时就需要用到任务队列。
从上面的例子可看出:
- 消息队列更侧重于消息的吞吐、处理,具有有处理海量信息的能力。另外利用消息队列的生长者和消费者的概念,也可以实现任务队列的功能,但是还需要进行额外的开发。
- 任务队列则提供了执行任务所需的功能,比如任务的重试,结果的返回,任务状态记录等。虽然也有并发的处理能力,但一般不适用于高吞吐量快速消费的场景。
任务队列其实和远程函数调用差不多,但和thrift、grpc什么不同,它不需要定义描述文件,调用的方式也不是网络请求方式,而是利用消息队列传递任务信息。
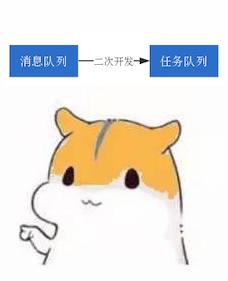
因此可以简单认为任务队列就是消息队列在异步任务场景下的深度化定制开发。
有疑问加站长微信联系(非本文作者)




