
>导语 | 当产品的用户量不断翻番时,需求会倒逼着你优化HTTP协议。那么,要想极限优化HTTP性能,应该从哪些维度出发呢?本文将由TVP陶辉老师,为大家分享四个全新维度。「TVP思享」专栏,凝结大咖思考,汇聚专家分享,收获全新思想,欢迎长期关注。(编辑:云加社区 尾尾)
**作者简介:**陶辉,腾讯云最具价值专家(TVP),杭州智链达数据有限公司 CTO及联合创始人,曾就职于阿里云、腾讯、华为、思科等公司,著有畅销书《深入理解Nginx:模块开发与架构解析》,与极客时间合作畅销视频课程《Web协议详解与抓包实战》、《Nginx核心知识100讲》。
无论你在做前端、后端还是运维,HTTP都是不得不打交道的网络协议。它是最常用的应用层协议,对它的优化,既能通过降低时延带来更好的体验性,也能通过降低资源消耗带来更高的并发性。
可是,刚学HTTP不久的同学,很难全面说出HTTP协议的所有优化点。而当你要准备大厂的面试,或者要加入一个快速发展的项目的时候,你就有必要了解这一方面的内容了。因为当产品的用户量不断翻番时,需求会倒逼着你优化HTTP协议。
本文是陶辉老师在2019年GOPS全球运维大会上海站的演讲重新提炼后的总结,希望能从四个全新的维度,带你覆盖绝大部分的HTTP优化技巧。这样,即使不需要极致方法去解决当前的性能瓶颈,也能知道优化方向在哪,当需求来临时,能够到Google上定向查阅资料。
## 一、编码效率优化
第一个维度,是从编码效率上,更快速地把消息转换成更短的字符流。这是最直接的性能优化点。
如果你对HTTP/1.1协议做过抓包分析,就会发现它是用“whitespace-delimited”方式编码的。用空格、回车这些符号来编码,是因为HTTP在诞生之初追求可读性,这样更有利于它的推广。
然而在当下,这种编码方式已经严重影响性能了,所以2009年Google推出了基于二进制的SPDY协议,大幅提升了编码效率。2015年,稍做改进后它被确定为HTTP/2协议,现在50%以上的站点都在使用它。

这是编码优化的大方向,包括即将推出的HTTP/3。
然而这些新技术到底是怎样提升性能的呢?我们需要拆开了来看,先从数据的压缩谈起。
抓包看到的是数据,它并不等于信息。数据其实是信息和冗余数据之和,而压缩技术,就是尽量地去除冗余数据。
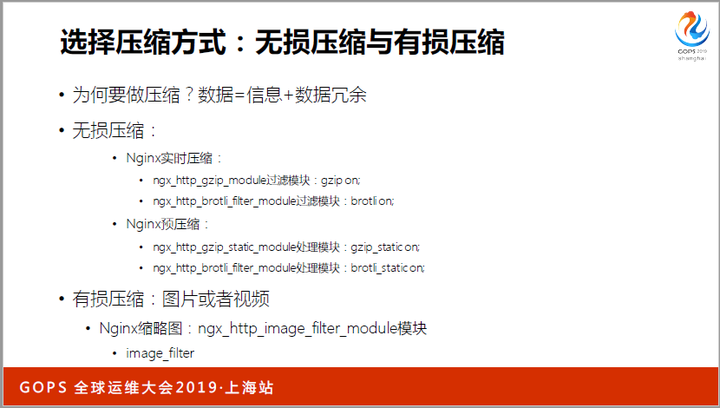
压缩分为无损压缩和有损压缩。针对图片、音视频,我们每天都在与有损压缩打交道。比如,当浏览器只需要缩略图时,就没有必要浪费带宽传输高清图片。
而高清视频做过有损压缩后,在肉眼无法分清时,已经被压缩了上千倍。这是因为,声音、视频都可以做增量压缩。
还记得曾经的VCD吗?当光盘有划痕时,整张盘都无法播放,就是因为那时的视频做了增量压缩,而且关键帧太少,导致关键帧损坏时,后面的增量帧全部无法播放了。
再来看无损压缩,你肯定用过gzip,它让http body实现了无损压缩。肉眼阅读压缩后的报文全是乱码,但接收端解压后,可以看到发送端的原文。然而,gzip的效率其实并不高,以Google推出的brotli做对比,你就知道它的缺陷了:
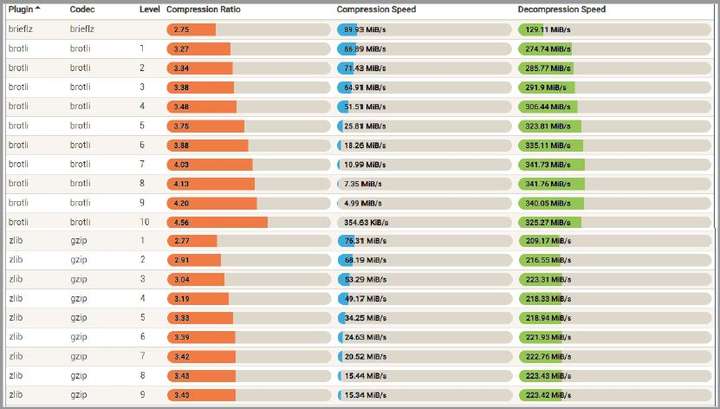
评价压缩算法时,我们重点看两个指标:压缩率和压缩速度。上图中可以看到,无论用gzip 9个压缩级别中的哪一个,它的压缩率都低于brotli(相比gzip,压缩级别它还可以配置为10),压缩速度也更慢。
所以,如果可以,应该尽快更新你的gzip压缩算法了。
说完对body的压缩,再来看HTTP header的压缩。对于HTTP/1.x来说,header就是性能杀手。特别是当下cookie泛滥的时代,每次请求都要携带几个KB的头部,很浪费带宽、CPU、内存!
HTTP2通过HPACK技术大幅度降低了header编码后的体积,这也是HTTP3的演进方向。HPACK到底是怎样实现header压缩的呢?
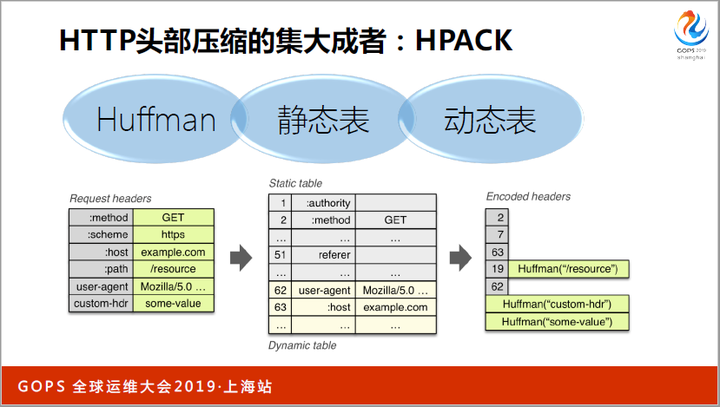
HPACK通过Huffman算法、静态表、动态表对三种header都做了压缩。比如上图中,method GET存在于静态表,用1个字节表示的整数2表达即可;user-agent Mozilla这行头部非常长,当它第2次出现时,用2个字节的整数62表示即可;即使它第1次出现时,也可以用Huffman算法压缩Mozilla这段很长的浏览器标识符,可以获得最多5/8的压缩率。
静态表中只存放最常见的header,有的只有name,有的同时包括name和value。静态表的大小很有限,目前只有61个元素。
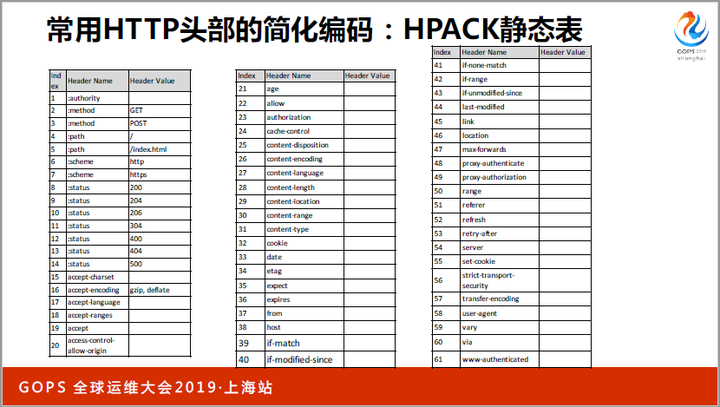
动态表应用了增量编码的思想,即,第1次出现时加入动态表,第2次出现的时候,传输它在动态表中的序号即可。
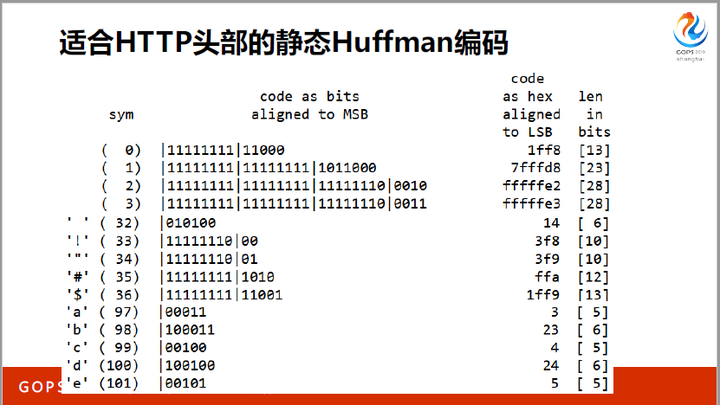
Huffman编码在winrar等压缩软件中广为使用,但HPACK中的Huffman有所不同,它使用的是静态huffman编码。
它统计了互联网上几年内的HTTP头部,按照每个字符出现的概率,重建huffman树。这样,根据规则,出现次数最多的a、c、e或者1、2、3这些字符就只用5个bit位表示,而很少出现的字符则用几十个bit位表示。
说完header,再来看http body的编码。这里举3个例子:
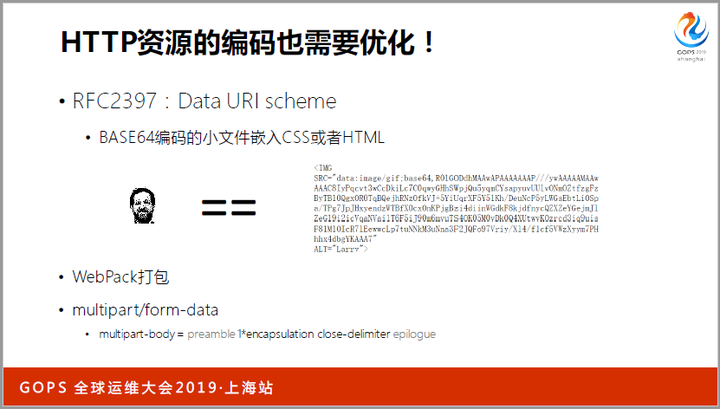
第一:只有几十字节的小图标,没有必要用独立的HTTP请求传输,根据RFC2397的规则,可以把它直接嵌入到HTML或者CSS文件中,而浏览器在解析时会识别出它们,就像下图中的头像:
第二:JS源码文件中,可能有许多小文件,这些文件中也有许多空行、注释,通过WebPack工具,先在服务器端打包为一个文件,并去除冗余的字符,编码效果也很好。
第三:在表单中,可以一次传输多个元素,比如既有复选框,也可以有文件。这就减少了HTTP请求的个数。
可见,HTTP协议从header到 body,都有许多编码手段,可以让传输的报文更短小,既节省了带宽,也降低了时延。
## 二、信道利用率优化
编码效率优化完后,再来看“信道”。这虽然是通讯领域的词汇,但用来概括HTTP的优化点非常合适,这里就借用下了。
信道利用率包括3个优化点,第一个优化点是多路复用!高速的低层信道上,可以跑许多低速的高层信道。
比如,主机上只有一块网卡,却能同时让浏览器、微信、钉钉收发消息;一个进程可以同时服务几万个TCP连接;一个TCP连接上可以同时传递多个HTTP2 STREAM消息。

其次,为了让信道有更高的利用率,还得及时恢复错误。所以,TCP工作的很大一部分,都是在及时的发现丢包、乱序报文,并快速的处理它们。
最后,就像经济学里说的,资源总是稀缺的。有限的带宽下,如何公平的对待不同的连接、用户和对象呢?
比如下载页面时,如果把CSS和图片以同等优先级下载就有问题,图片晚点显示没关系,但CSS没获取到页面就无法显示。
另外,传输消息时,报文头报并不承载目标信息,但它又是必不可少的,如何降低这些控制信息的占比呢?
我们先从多路复用谈起。广义上来说,多线程、协程都属于多路复用,但这里我主要指HTTP2的stream。因为HTTP协议被设计为client先发request,server才能回复response,这样收发消息,是没办法跑满带宽的。
最有效率的方式是,发送端源源不断地发请求、接收端源源不断地发响应,这对于长肥网络尤为有效:

HTTP2的stream就是这样复用连接的。我们知道,chrome对一个站点最多同时建立6个连接,而有了HTTP2后,只需要一个连接就能高效的传输页面上的数百个对象。
我特意让我的个人站点www.taohui.pub同时支持HTTP1和HTTP2,下图是连接视角上HTTP2和HTTP1的区别。

熟悉chrome Network网络面板的同学,肯定很熟悉waterfall,它可以帮助你分析HTTP请求到底慢在哪里,是请求发出的慢,还是响应接收的慢,又或者是解析得太慢了。下图还是我的站点在waterfall视角下的对比。

从这两张图可以看出,HTTP2全面优于HTTP1。
再来看网络错误的恢复。在应用层,lingering_time通过延迟关闭连接来避免浏览器因RST错误收不到http response,而timeout则是用定时器及时发现错误并释放资源。
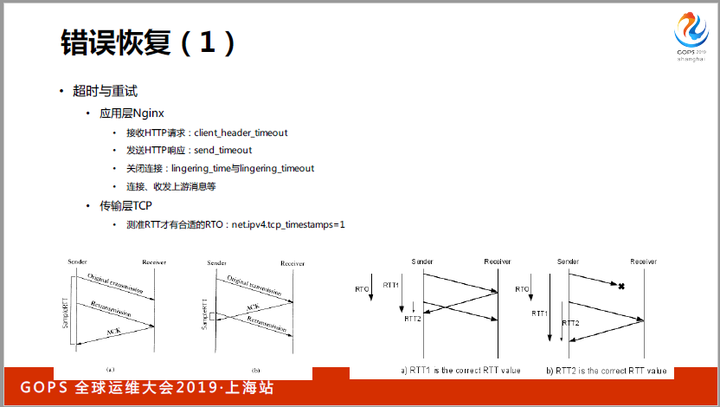
在传输层,通过timestamp=1可以让TCP更精准的测量出定时器的超时时间RTO。当然,timestamp还有一个用途,就是防止长肥网络中的序列号回绕。

什么是序列号回绕呢?我们知道,TCP每个报文都有序列号,它不是指报文的次序,而是已经发送的字节数。由于它是32位整数,所以最多可以处理232也就是4.2GB的飞行中报文。
像上图中,当1G-2G这些报文在网络中飞行时间过长时,就会与5G-6G报文重叠,引发错误。
网络错误还有很多种,比如报文的次序也是无法保证的。打开tcp_sack可以减少乱序时的重发报文量,降低带宽消耗。
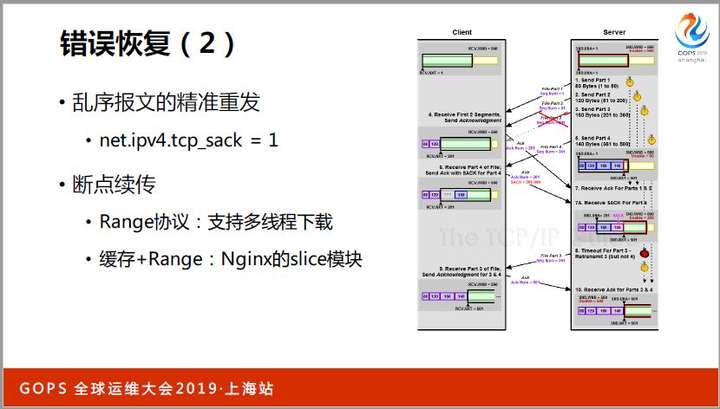
用Chrome浏览器直接下载大文件时,网络不好时,一出错就得全部重传,体验很差。
改用迅雷下载就快了很多。这是因为迅雷把大文件拆成很多小块,可以多线程下载,而且每个小块出错后,重新下载这一个块即可,效率很高。
这个断点续传、多线程下载技术,就是HTTP的Range协议。如果你的服务是缓存,也可以使用Range协议,比如Nginx的Slice模块就做了这件事。
实际上对于网络错误恢复,最精妙的算法是拥塞控制,它可以全面提升网络性能。有同学会问,TCP不是有流量控制,为什么还会发生网络拥塞呢?这是因为,TCP链路中的各个路由器,处理能力并不互相匹配。
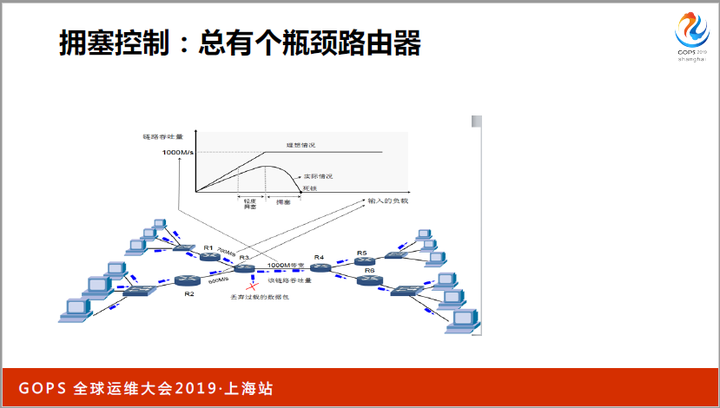
就像上图,R1的峰值网络是700M/s,R2的峰值网络是600M/s,它们都需要通过R3才能到达R4。然而,R3的最大带宽只有1000M/s!当R1、R2中的TCP全速使用各自带宽时,就会引发R3丢包。拥塞控制就是解决丢包问题的。
自1982年TCP诞生起,就在使用传统的拥塞控制算法,它是发现丢包后再刹车减速,效果很不好。
为什么呢?你可以观察下图,路由器中会有缓冲队列,当队列为空时,ping的时延最短;当队列将满时,ping的时延很大,但还未发生丢包;当队列已满时,丢包才会发生。
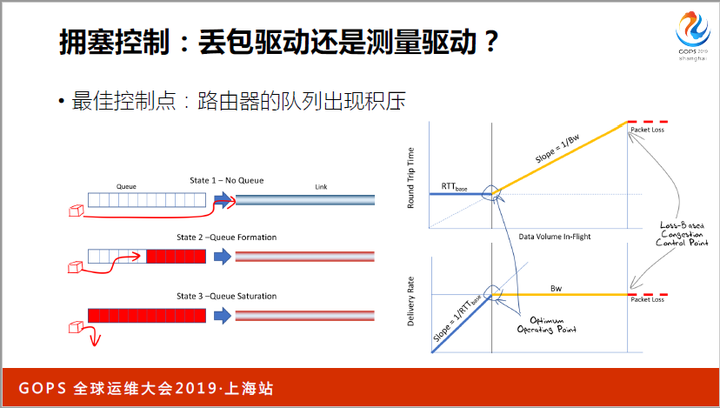
所以,当队列出现积压时,丢包没有发生。虽然此时峰值带宽不会减少,但网络时延变大了,这是要避免的。
而测量驱动的拥塞控制算法,就在队列刚出现积压这个点上开始刹车减速。在当今内存越来越便宜,队列越来越大的年代,新算法尤为有效。
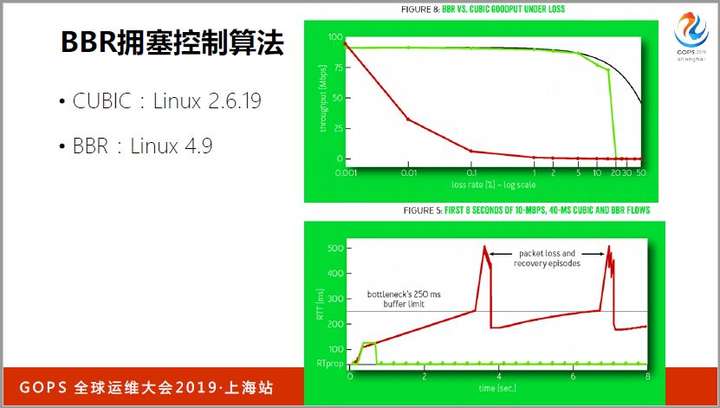
当Linux内核更新到4.9版本时,原先的CUBIC拥塞控制算法就被替换为Google的BBR算法了。
从下图中可以看到,当丢包率达到0.01%时,CUBIC就没法用了,而BBR并没有问题,直到丢包率达到5%时BBR的带宽才剧烈下降。
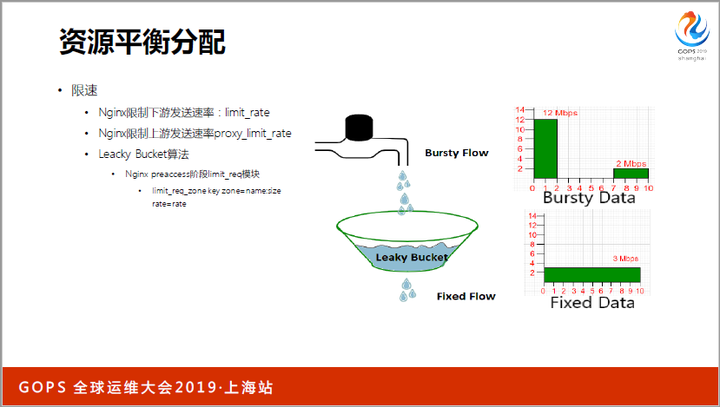
再来看资源的平衡分配。为了公平的对待连接、用户,服务器会做限速。比如下图中的Leacky Bucket算法,它能够平滑突增的流量,更公平的分配带宽。
再比如HTTP2中的优先级功能。一个页面上有几百个对象,这些对象的重要性不同,有些之间还互相依赖。比如,有些JS文件会包含jQuery.js,如果同等对待的话,即使先下载完前者,也无法使用。
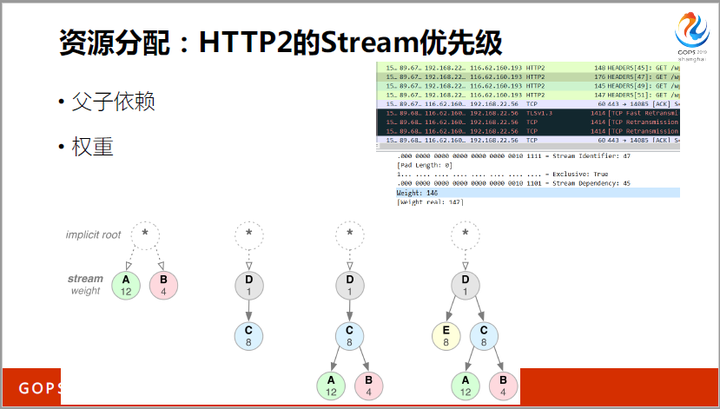
HTTP2允许浏览器下载对象时,根据解析规则,在stream中设置每一个对象的weight优先级(255最大,0最小)。而各代理、资源服务器都会根据优先级,分配内存和带宽,提升网络效率。
最后看下TCP的报文效率,它也会影响HTTP性能。比如开启Nagle算法后,网络中的小报文数量大幅减少,考虑到40字节的报文头部,信息占比更高。
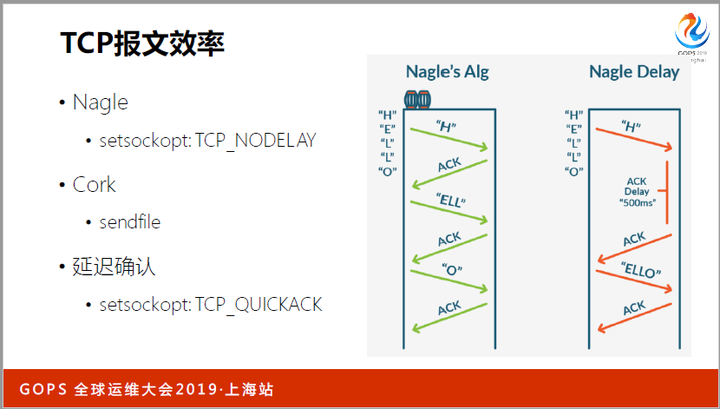
Cork算法与Nagle算法相似,但会更激进的控制小报文。Cork与Nagle是从发送端控制小报文,quickack则从接收端控制纯ack小报文的数量,提高信息占比。
## 三、传输路径优化
说完相对微观一些的信道,我们再来从宏观上看第三个优化点:传输路径的优化。
传输路径的第一个优化点是缓存,浏览器、CDN、负载均衡等组件中,缓存无处不在。
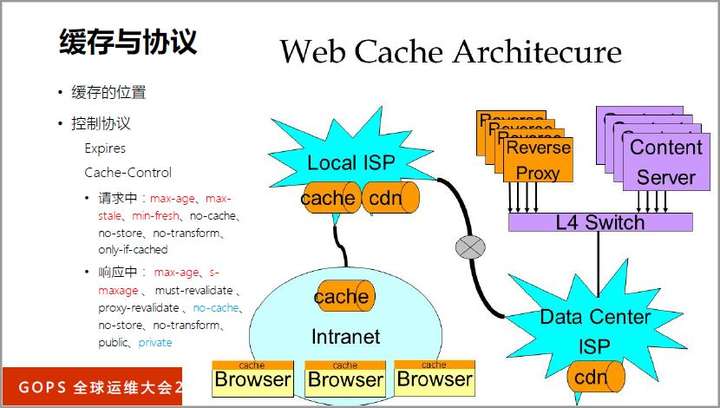
缓存的基本用法你大概很熟悉了,这里我们讲过期缓存的用法。把过期缓存直接丢掉是很浪费的,因为“过期”是客户端的定时器决定的,并不代表资源真正失效。
所以,可以把它的标识符带给源服务器,服务器会判断缓存是否仍然有效,如果有效,直接返回304和空body就可以了,非常节省带宽。
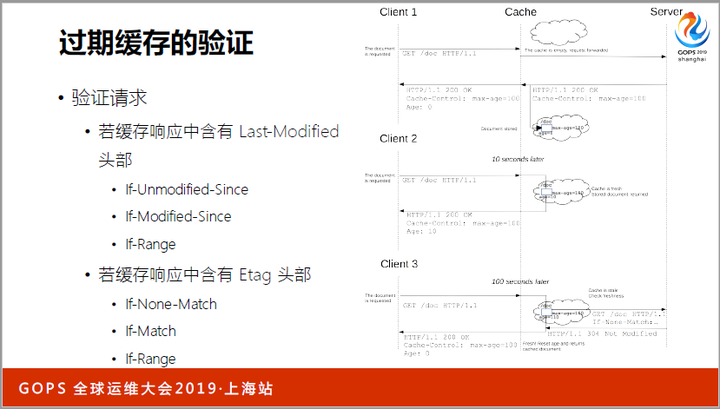
对于负载均衡而言,过期缓存还能够保护源服务器,限制回源请求。当源服务器挂掉后,还能以过期缓存给用户带来降级后的服务体验,这比返回503要好得多。
传输路径的第二个优化点是慢启动。系统自带的TCP协议栈,为了避免瓶颈路由器丢包,会缓缓加大传输速度。它的起始速度就叫做初始拥塞窗口。
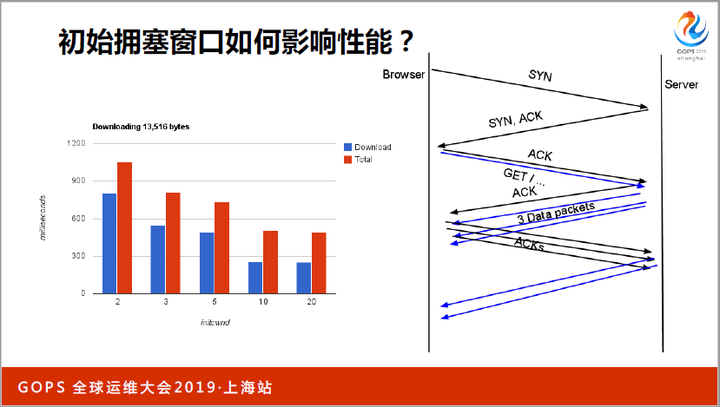
早期的初始拥塞窗口是1个MSS(通常是576字节),后来改到3个MSS(Linux 2.5.32),在Google的建议下又改到10个MSS(Linux 3.0)。
之所以要不断提升起始窗口,是因为随着互联网的发展,网页越来越丰富,体积也越来越大。起始窗口太小,就需要更长的时间下载第一个网页,体验很差。
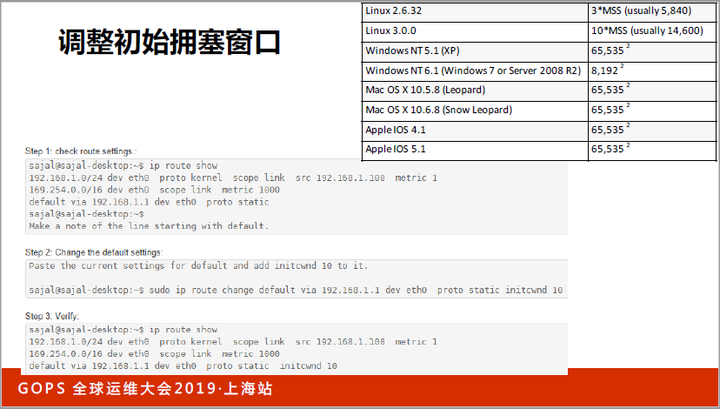
当然,修改起始窗口很简单,下图中是Linux下调整窗口的方法。
修改起始窗口是常见的性能优化手段,比如CDN厂商都改过起始窗口,下图是主流CDN厂商2014和2017年的起始窗口大小。
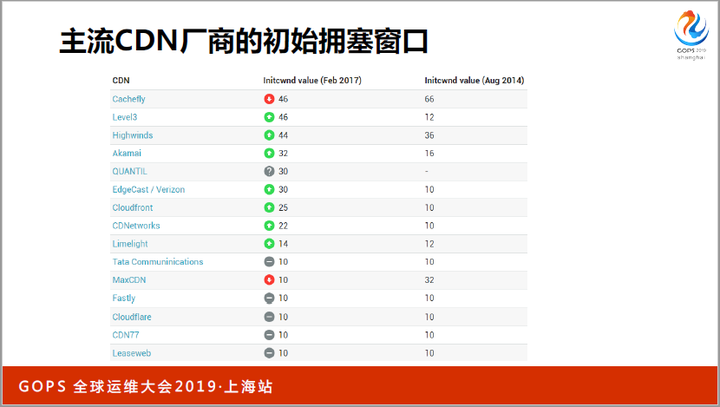
可见,有些窗口14年调得太大了,17年又缩回去了。所以,起始窗口并不是越大越好,它会增加瓶颈路由器的压力。
再来看传输路径上,如何从拉模式升级到推模式。
比如 index.html 文件中包含<LINK href=”some.css”>,在HTTP/1中,必须先下载完index.html,才能去下载some.css,这是两个RTT的时间。但在HTTP/2中,服务器可以通过2个stream,同时并行传送index.html和some.css,节约了一半的时间。
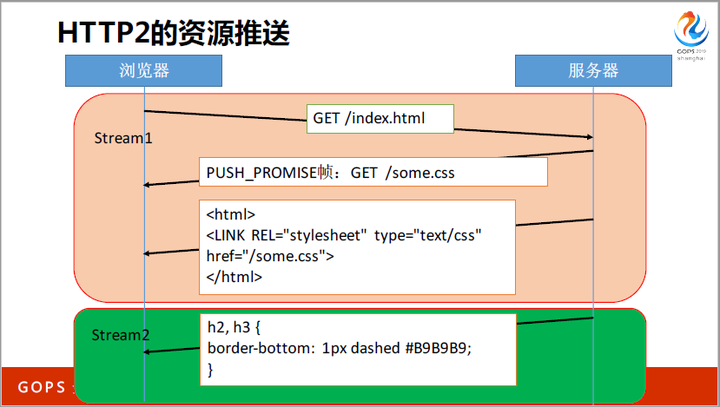
其实当出现丢包时,HTTP2的stream并行发送会严重退化,因为TCP的队头阻塞问题没有解决。
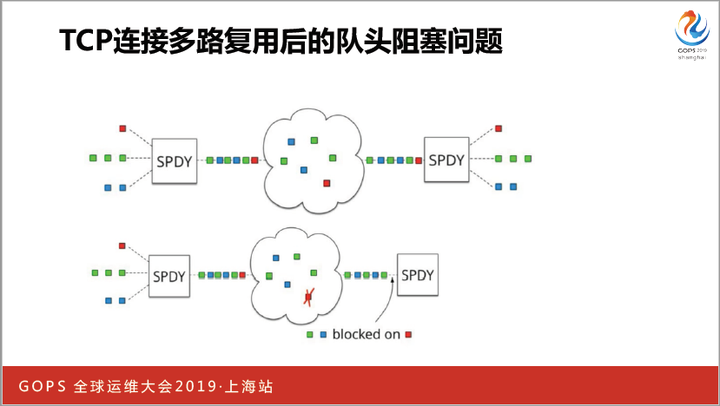
上图中的SPDY与HTTP2是等价的。在红绿色这3个stream并发传输时,TCP层仍然会串行化,假设红色的stream在最先发送的,如果红色报文丢失,那么即使接收端已经收到了完整的蓝、绿stream,TCP也不会把它交给HTTP2,因为TCP自身必须保证报文有序。这样并发就没有保证了,这就是队头阻塞问题。
解决队头阻塞的办法就是绕开TCP,使用UDP协议实现HTTP,比如Google的GQUIC协议就是这么做的,B站在几年前就使用它提供服务了。
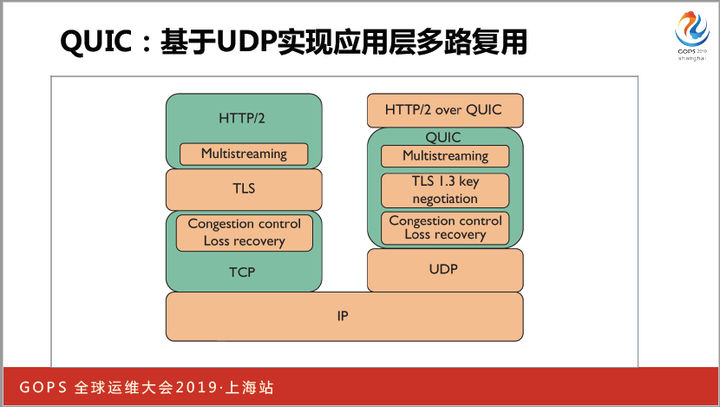
UDP协议自身是不能保证可靠传输的,所以GQUIC需要重新在UDP之上实现TCP曾经做过的事。这是HTTP的发展方向,所以目前HTTP3就基于GQUIC在制定标准。
## 四、信息安全优化
最后,再从网络信息安全的角度,谈谈如何做优化。它实际上与编码、信道、传输路径都有关联,但其实又是独立的环节,所以放在最后讨论。
互联网世界的信息安全,始于1995年的SSL3.0。到现在,许多大型网站都更新到2018年推出的TLS1.3了。
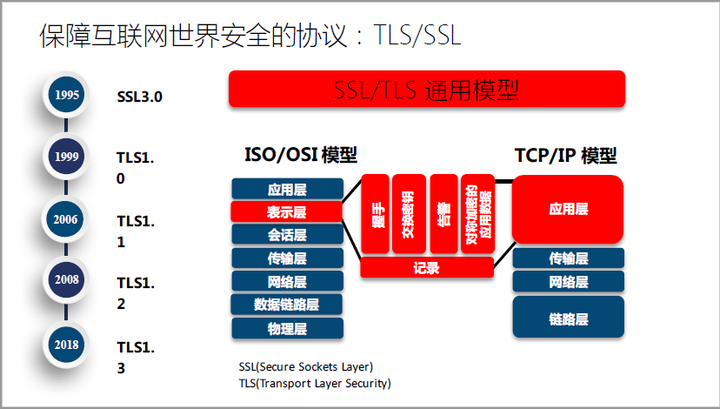
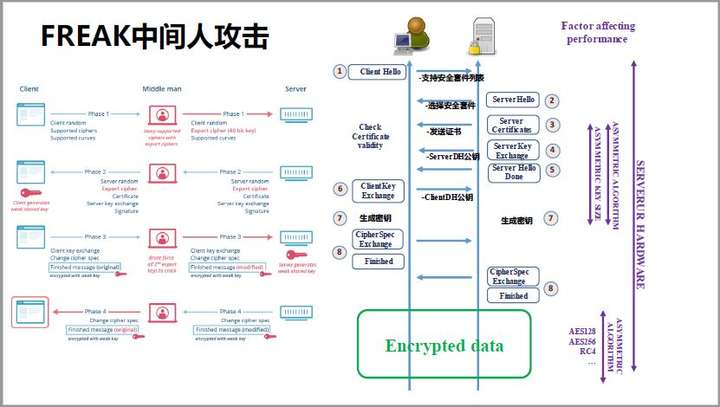
TLS1.2有什么问题呢?最大问题就是,它支持古老的密钥协商协议,这些协议现在已经不安全了。比如2015年出现的FREAK中间人攻击,就可以用Amazon上的虚拟机,分分钟攻陷支持老算法的服务器。
TLS1.3针对这一情况,取消了在当前的计算力下,数学上已经不再安全的非对称密钥协商算法。在Openssl的最新实现中,仅支持5种安全套件:

TLS1.3的另一个优势是握手速度。在TLS1.2中,由于需要2个RTT才能协商完密钥,才诞生了session cache和session ticket这两个工具,它们都把协商密钥的握手降低为1个RTT。但是,这两种方式都无法应对重放攻击。
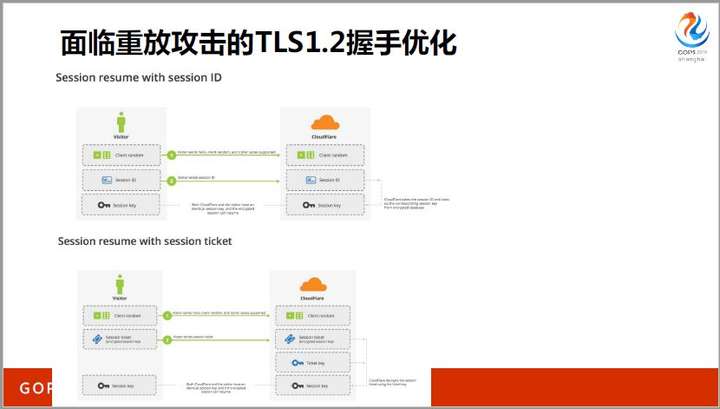
而TLS1.2中的安全套件协商、ECDHE公钥交换这两步,在TLS1.3中被合并成一步,这大大提升了握手速度。
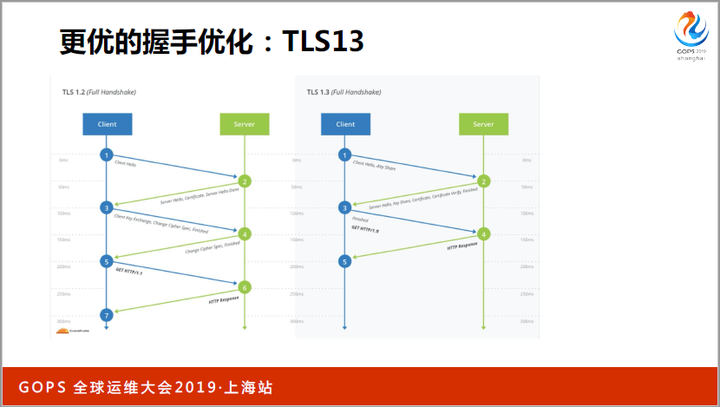
如果你还在使用TLS1.2,尽快升级到1.3吧,除了安全性,还有性能上的收益。
## 五、小结
HTTP的性能优化手段众多,从这四个维度出发,可以建立起树状的知识体系,囊括绝大部分的HTTP优化点。
编码效率优化包括http header和body ,它可以使传输的数据更短小紧凑,从而获得更低的时延和更高的并发。同时,好的编码算法也可以减少编解码时的CPU消耗。
信道利用率的优化,可以从多路复用、错误发现及恢复、资源分配这3个角度出发,让快速的底层信道,有效的承载慢速的应用层信道。
传输路径的优化,包括各级缓存、慢启动、消息传送模式等,它能够让消息更及时的发给浏览器,提升用户体验。
当下互联网中的信息安全,主要还是建立在TLS协议之上的。TLS1.3从安全性、性能上都有很大的提升,我们应当及时的升级。
希望这些知识能够帮助你全面、高效地优化HTTP协议!
## 腾讯云TVP

腾讯云最具价值专家,简称TVP(Tencent Cloud Valuable Professional),是腾讯云颁发给技术专家的一项荣誉认证,以此感谢他们为推动云计算的发展所作出的贡献。这些技术专家来自于各个技术领域和行业,他们热衷实践、乐于分享,为技术社区的建设和推动云计算的传播做出了卓越的贡献。
*了解TVP更多信息,请关注「云加社区」,回复「TVP」。*

有疑问加站长微信联系(非本文作者)




