
# 现象
k8s环境,假设调用链路是A调用B。
- A调用B报超时错误
- 服务B接口监控发现延迟正常(就好像A并没有调用B一样)
- B是`php`服务,阶段性出现`php_network_getaddresses: getaddrinfo failed`报错
# 分析
## DNS问题?
先从这个报错查起`php_network_getaddresses: getaddrinfo failed`
搜索这个错误,谷歌、百度会告诉你`dns`解析的问题,解析失败会报这个错。

但实际上,我们不论在`pod`里面还是在`node`机器上`ping`对应访问的域名,都是可以成功解析的。
排查陷入尴尬的境地,**感觉是网络问题**,为什么呢?
- 上游请求下游,大量超时,但是下游却响应正常,感觉因为网络有问题,请求没有到达下游,或者下游返回的时候上游没有收到。
- `getaddrinfo failed`表示有时候`dns`解析有问题,但是能排除`dns`本身的问题,可能还是网络的问题,但是请求或者响应有问题。
## 网络问题?
网络问题可能是哪些问题呢?
- 带宽满了?
- 不是,检查过`node`的带宽,虽然带宽占用挺高的,但是远没有达到上限
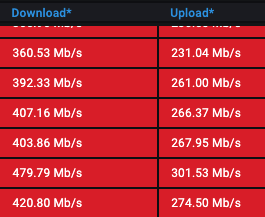
- `LB`超载了?
- 不是,虽然问题期间链接数上升了不少,但是还是没有到达上限。目前主要问题是请求超时,因为请求不能快速结束,所以需要更多的链接,链接数上升也说得通。

## 机器问题?
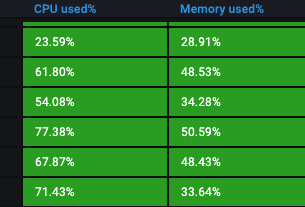
- CPU、内存、负载高了?
- 不是,指标正常
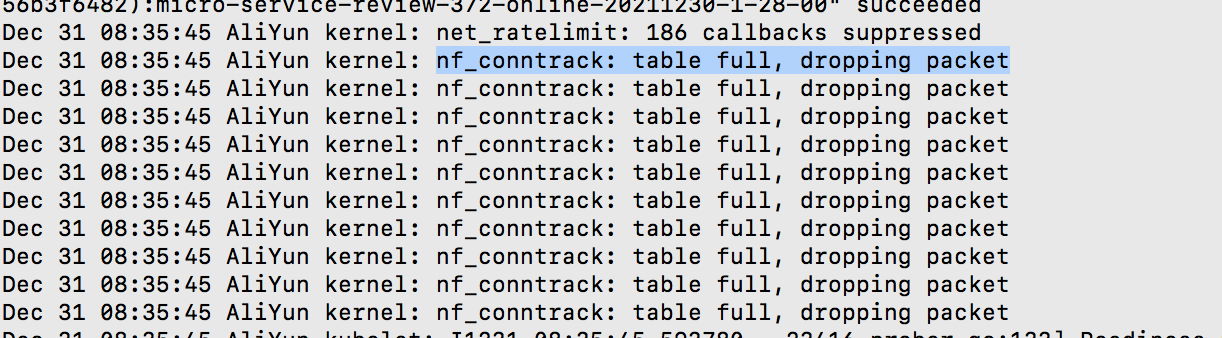
- 看看`node`主机有没有报错?
- `demsg`,看到有如下报错:`dropping packet`不就是丢包的意思么?
# 问题浮现
现在定位的问题是`conntrack table`满了,导致丢包。那`conntrack`是什么呢?
`conntrack`即[连接跟踪](https://arthurchiao.art/blog/conntrack-design-and-implementation-zh/),大概意思是Linux为每一个经过网络堆栈的数据包,生成一个新的连接记录项 (Connection entry)。此后,所有属于此连接的数据包都被唯一地分配给这个连接,并标识连接的状态。
查看`conntrack`的上限和当前值,上线是52.4w,当前已经是`52.2w`,已经接近上限了。
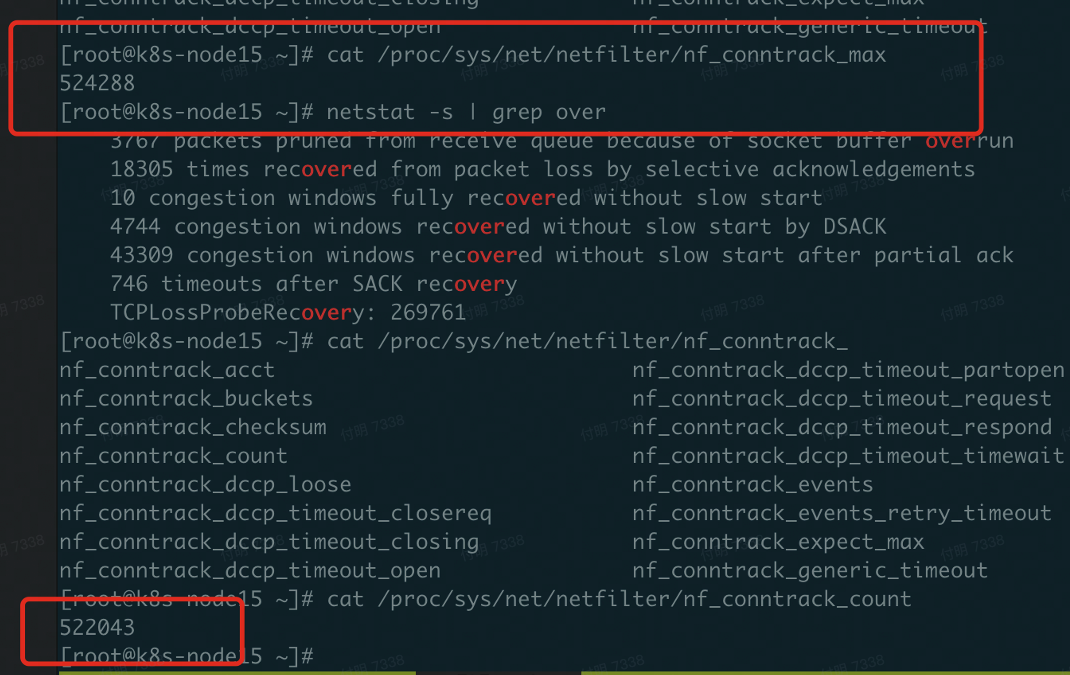
执行命令`sysctl -w net.netfilter.nf_conntrack_max=2310720`,提高上限,此时问题收敛。
**问题复盘期间**,运维同学提到`net.netfilter.nf_conntrack_max`这个值在去年的时候已经调整到`231w`了,为啥现在又变回来了?
考虑到`k8s`的`kube_proxy`组件和`conntrack`有绝对关系,然后谷歌了下,看到`kube-proxy`有几个相关的参数。
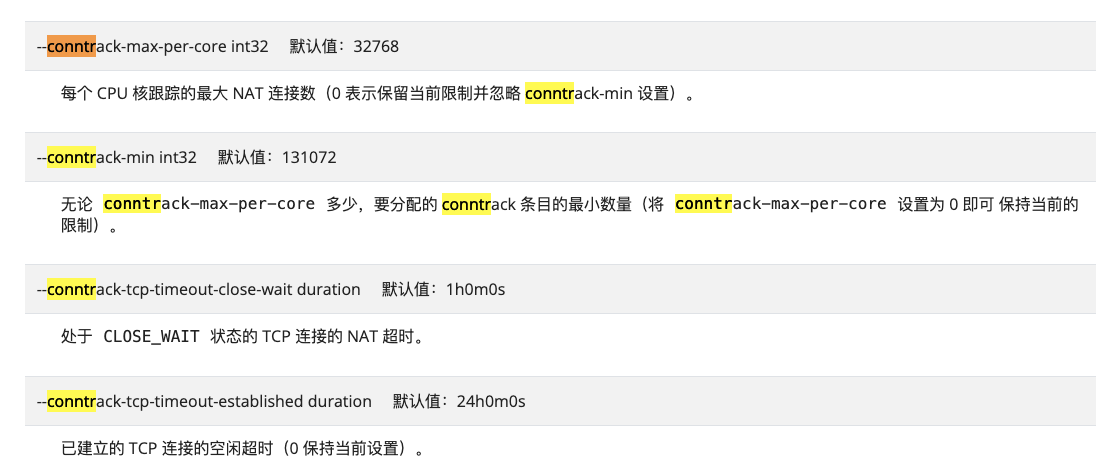
看了下我们`kube-proxy`的启动命令`/usr/local/bin/kube-proxy --config=/var/lib/kube-proxy/config.conf --hostname-override=cn-beijing-xxx`,配置文件是空的,也就是都是使用这些参数的默认值,`--conntrack-max-per-core`代表每个cpu核跟踪的最大NAT数量,默认值是`32768`。我们是`16核`的机器,16*32768=`524288,524288`和系统中的`net.netfilter.nf_conntrack_max`值是一致的。
**net.netfilter.nf_conntrack_max为啥变化了呢**
运维同学很确定这个参数值在去年就修改过,这个事情我也有印象。继续谷歌,看到了这边文章[《kube-proxy conntracker设置》](https://blog.csdn.net/weixin_39961559/article/details/81637023),大概意思是,`kube-proxy`的启动参数中如果没有设置--conntrack-max参数,则对比--`conntrack-min`和--conntrack-max-per-core的值与`cpu`核数的大小取其大者返回`max`值,默认值是`32768 * CPU` 核数,**最后调用SetMax设置conntrack-max的值**。
所以是`kube-proxy`重启的时候修改了系统的`net.netfilter.nf_conntrack_max`值。这是一个坑,不踩真的不知道。
再回想,昨天运维确实升级重启过`kube-proxy`....
# 总结
- 上游请求下游,上游超时,下游响应正常,大概率是网络的问题。
- 网络的问题,是`node`主机conntrack达到上限,导致丢包,丢包导致微服务请求超时。
- `net.netfilter.nf_conntrack_max`这个参数在kube-proxy启动的时候会重新设置,所以要设置好kube-proxy启动参数。
- 再看到`php_network_getaddresses: getaddrinfo failed`报错,排除`dns`本省的问题,很可能就是网络丢包导致的
- 阿里云已经有相关监控和告警了

有疑问加站长微信联系(非本文作者)




