
## 概述
大量的实际的项目中,都会引入 Redis 缓存来缓解数据库的查询压力,此时由于一个数据在 Redis 和数据库两处进行了存储,就会有数据一致性的问题。目前业界尚未见到成熟的能够确保最终一致性的方案,特别是当如下场景发生时,会直接导致缓存数据与数据库数据不一致,可能给应用带来较大问题。
[dtm-labs](https://github.com/dtm-labs) 致力于解决数据一致性问题,在分析了行业的现有做法后,提出了新解决方案[dtm-labs/dtm](https://github.com/dtm-labs/dtm)+[dtm-labs/rockscache](https://github.com/dtm-labs/rockscache),彻底解决了上述问题。另外作为一个成熟方案,该方案还可以防缓存穿透,防缓存击穿,防缓存雪崩,同时也可应用于要求数据强一致的场景。
关于管理缓存的现有方案,本文不再赘述,不太了解的同学可以参考下面这两篇文章
- 这篇通俗易懂些:[聊聊数据库与缓存数据一致性问题](https://juejin.cn/post/6844903941646319623)
- 这篇更加深入:[携程最终一致和强一致性缓存实践](https://www.infoq.cn/article/hh4iouiijhwb4x46vxeo)
## 乱序产生的不一致
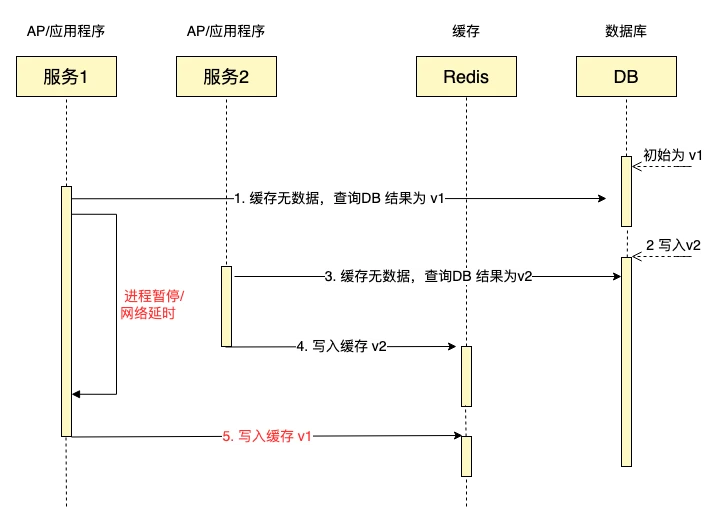
在上述这个时序图中,由于服务1发生了进程暂停(例如由于GC导致),因此当它往缓存当中写入v1时,覆盖了缓存中的v2,导致了最终的不一致(DB中为v2,缓存中为v1)。
对于上述这类问题应当如何解决?目前现存的方案,全都没有彻底解决该问题,一般都是通过设定稍短的过期时间兜底。我们实现的缓存延迟删除方案,能够彻底解决这个问题,确保缓存与数据库之间的数据保持一致。解决原理如下:
缓存中的数据是一个hash,里面有以下几个字段:
- value: 数据本身
- lockUtil: 数据锁定到期时间,当某个进程查询缓存无数据,那么先锁定缓存一小段时间,然后查询DB,然后更新缓存
- owner: 数据锁定者uuid
查询缓存时:
1. 如果数据为空,且被锁定,则睡眠1s后,重新查询
2. 如果数据为空,且未被锁定,同步执行"取数据",返回结果
3. 如果数据不为空,那么立即返回结果,并异步执行"取数据"
其中"取数据"的操作定义为:
1. 判断是否需要更新缓存,下面两个条件满足其一,则需要更新缓存
- 数据为空,并且未被锁定
- 数据的锁定已过期
2. 如果需要更新,则锁定缓存,查询DB,校验锁持有者无变化,写入缓存,解锁缓存
当DB数据更新时,通过dtm确保数据更新成功时,将缓存延迟删除(将在后面一节展开详细讲解)
- 延迟删除会将数据过期时间设定为10s,将锁设置为已过期,触发下一次查询缓存时的“取数据”
在上述的策略下:
假如最后写入数据库的版本为Vi,最后写入到缓存的版本为V,写入V的uuid为uuidv,那么一定存在以下事件序列:
数据库写入Vi -> 缓存数据被标记为删除 -> 某个查询锁定数据并写入uuidv -> 查询数据库结果V -> 缓存中的锁定者为uuidv,写入结果V
在这个序列中,V的读取发生在写入Vi之后,所以V等于Vi,保证了缓存的数据的最终一致性。
[dtm-labs/rockscache](https://github.com/dtm-labs/rockscache)已经实现了上述方法,能够确保缓存数据的最终一致性。
- `Fetch`函数实现了前面的查询缓存
- `DelayDelete`函数实现了延迟删除逻辑
感兴趣的同学,可以参考[dtm-cases/cache](https://github.com/dtm-labs/dtm-cases/tree/main/cache),里面有详细的例子
## DB与缓存操作的原子性
对于缓存的管理,一般业界会采用写完数据库后,删除/更新缓存数据的策略。由于保存到缓存和保存到数据库两个操作之间不是原子的,一定会有时间差,因此这两个数据之间会有一个不一致的时间窗口,通常这个窗口不大,影响较小。但是两个中间可能发生宕机,也可能发生各种网络错误,因此就有可能发生完成了其中一个,但是未完成另一个,导致数据会出现长时间不一致。
举一个场景来说明上述不一致的情况,数据用户将数据 A 修改为 B ,应用修改完数据库之后,再去删除/更新缓存,如果未发生异常,那么数据库和缓存的数据是一致的,没有问题。但是分布式系统中,可能会发生进程crash、宕机等事件,因此如果更新完数据库,尚未删除/更新缓存时,出现进程crash,那么数据库和缓存的数据就可能出现长时间的不一致。
面对这里的长时间不一致的情况,想要彻底解决,并不是一件容易的事,我们下面分各种应用情况来介绍解决方案。
#### 方案一:较短的缓存时间
这个方案,是最简单的方案,适合并发量不大应用。如果应用的并发不高,那么整个缓存系统,只需要设置了一个较短的缓存时间,例如一分钟。这种情况下数据库需要承担的负载是:大约每一分钟,需要将访问到的缓存数据全部生成一遍,在并发量不大的情况下,这种策略是可行的。
上述这种策略非常简单,易于理解和实现,缓存系统提供的语义是,大多数情况下,缓存和数据库之间不一致的时间窗口是很短的,在较低概率发生进程crash的情况下,不一致的时间窗口会达到一分钟。
应用在上述约束下,需要将一致性要求不高的数据读取,从缓存读取;而将一致性要求较高的读,不走缓存,直接从数据库查询。
#### 方案二:消息队列保证一致
假如应用的并发量很高,缓存过期时间需要比一分钟更长,而且应用中的大量请求不能够容忍较长时间的不一致,那么这个时候,可以通过使用消息队列的方式,来更新缓存。具体的做法是:
- 更新数据库时,同时将更新缓存的消息写入本地表,随着数据库更新操作的提交而提交。
- 写一个轮询任务,不断轮询这部分消息,发给消息队列。
- 消费消息队列中的消息,更新/删除缓存
这种做法可以保证数据库更新之后,缓存一定会被更新。但这种这种架构方案很重,这几个部分开发维护成本都不低:消息队列的维护;高效轮询任务的开发与维护。
#### 方案三:订阅 binlog
这个方案适用场景与方案二非常类似,原理又与数据库的主从同步类似,数据库的主从同步是通过订阅binlog,将主库的更新应用到从库上,而这个方案则是通过订阅binlog,将数据库的更新应用到缓存上。具体做法是:
- 部署并配置阿里开源的 canal ,让它订阅数据库的binlog
- 通过 canal等工具 监听数据更新,同步更新/删除缓存
这种方案也可以保证数据库更新之后,缓存一定会被更新,但是这种架构方案跟前面的消息队列方案一样,也非常重。一方面 canal 的学习维护成本不低,另一方面,开发者可能只需要少量数据更新缓存,通过订阅所有的 binlog 来做这个事情,浪费了很多资源。
#### 方案四: dtm 二阶段消息方案
dtm 里的二阶段消息模式,非常适合这里的修改数据库之后更新/删除缓存,主要代码如下:
``` Go
msg := dtmcli.NewMsg(DtmServer, gid).
Add(busi.Busi+"/UpdateRedis", &Req{Key: key1})
err := msg.DoAndSubmitDB(busi.Busi+"/QueryPrepared", db, func(tx *sql.Tx) error {
// update db data with key1
})
```
这段代码,DoAndSubmitDB会进行本地数据库操作,进行数据库的数据修改,修改完成后,会提交一个二阶段消息事务,消息事务将会异步调用 UpdateRedis。假如本地事务执行之后,就立刻发生了进程 crash 事件,那么 dtm 会进行回查调用 QueryPrepared ,保证本地事务提交成功的情况下,UpdateRedis 会被最少成功执行一次。
回查的逻辑非常简单,只需要copy类似下面这样的代码即可:
``` Go
app.GET(BusiAPI+"/QueryPrepared", dtmutil.WrapHandler(func(c *gin.Context) interface{} {
return MustBarrierFromGin(c).QueryPrepared(dbGet())
}))
```
这种方案的优点:
- 方案简单易用,代码简短易读
- dtm 本身是一个无状态的普通应用,依赖的存储引擎 redis/mysql 是常见的基础设施,不需要额外维护消息队列或者 canal
- 相关的操作模块化,易维护,不需要像消息队列或者 canal 在其他地方写消费者的逻辑
#### 从库延时
上述的方案中,假定缓存删除后,服务进行数据查询,总是能够查到最新的数据。但是实际的生产环境中,可能会出现主从分离的架构,而主从延时并不是一个可控的变量,那么这时候又要怎么处理?
处理方案两种:一是区分最终一致性很高和不高的缓存数据,查询数据时,将要求很高的数据必须从主库读取,而把要求不高的数据从从库读取。对于使用了rockscache的应用来说,高并发的请求都会在Redis这一层被拦截,对于一个数据,最多只会有一个请求到达数据库,因此数据库的负载已大幅降低,采用主库读取是一个实际可行的方案。
另一种方案是,主从分离需要采用不分叉的单链架构,那么链条末尾的从库必定是延迟最长的从库,此时采用监听binlog的方案,需要监听链条做末端的从库binlog,当收到数据变更通知时,按照上述方案将缓存标记为延迟删除。
这两个方案各有优缺点,业务可以根据自己的特点采用。
## 防缓存击穿
rockscache还可以防缓存击穿。当数据变更时,业界现有做法既可以选择更新缓存,也可以选择删除缓存,各有优劣。而延迟删除综合了两种方法的优势,并克服了两种方法的劣势:
#### 更新缓存
采取更新缓存策略,那么会为所有的DB数据更新生成缓存,不区分冷热数据,那么会存在以下问题:
- 内存上,即使一个数据没有被读取,也会保存在缓存里,浪费了宝贵的内存资源;
- 在计算上,即使一个数据没有被读取,也可能因为多次更新,被多次计算,浪费了宝贵的计算资源。
- 上述的乱序不一致发生的概率会较高,当两个临近的更新中出现延迟,就可能触发。
#### 删除缓存
因为前面的更新缓存做法问题较多,因此大多数的实践采用的是删除缓存策略,查询时再按需生成缓存。这种做法解决了更新缓存中的问题,但是又带来新问题:
- 那么在高并发的情况下,如果删除了一个热点数据,那么此时会有大量请求会无法命中缓存,产生缓存击穿。
为了防止缓存击穿,通用的做法是使用分布式 Redis 锁保证只有一个请求到数据库,等缓存生成之后,其他请求进行共享。这种方案能够适合很多的场景,但有些场景却不适合。
- 例如有一个重要的热点数据,计算代价比较高,需要3s才能够获得结果,那么上述方案在删除一个这种热点数据之后,就会在这个时刻,有大量请求3s才返回结果,一方面可能造成大量请求超时,另一方面3s没有释放链接,会导致并发连接数量突然升高,可能造成系统不稳定。
- 另外使用 Redis 锁时,未获得锁的这部分用户,通常会定时轮询,而这个睡眠时间不好设定。如果设定比较大的睡眠时间1s,那么对于10ms就计算出结果的缓存数据,返回太慢了;如果设定的睡眠时间太短,那么很消耗 CPU 和 Redis 性能
#### 延迟删除法的应对策略
前面介绍的[dtm-labs/rockscache](https://github.com/dtm-labs/rockscache)实现的延时删除法也属于删除法,但它彻底解决了删除缓存中的击穿问题,以及击穿带来的附带问题。
1. 缓存击穿问题:延迟删除法中,如果缓存中的数据不存在,那么会锁定缓存中的这条数据,因此避免了多个请求打到后端数据库。
2. 上述大量请求3s才返回数据,以及定时轮询的问题,在延时删除中也不存在,因为热点数据被延时删除时,旧版本的数据还在缓存中,会被立即返回,无需等待。
我们来看看不同的数据访问频率下,延迟删除法的表现如何:
1. 热点数据,每秒1K qps,计算缓存时间5ms,此时延迟删除法,大约5~8ms左右的时间里,会返回过期数据,而先更新DB,再更新缓存,因为更新缓存需要时间,也会有大约0~3ms返回过期数据,因此两者差别不大。
2. 热点数据,每秒1K qps,计算缓存时间3s,此时延迟删除法,大约3s的时间里,会返回过期数据。对比于等待3s后再返回数据,那么返回旧数据,通常是更好的行为。
3. 普通数据,每秒50 qps,计算缓存时间1s,此时延迟删除法的行为分析,类似2,没有问题。
4. 低频数据,5秒访问一次,计算缓存时间3s,此时延迟删除法的行为与删除缓存策略基本一样,没有问题
5. 冷数据,10分钟访问一次,此时延迟删除法,与删除缓存策略基本一样,只是数据比删除缓存的方式多保存10s,占用空间不大,没有问题
有一种极端情况是,那就是原先缓存中没有数据,突然大量请求到来,这种场景对,更新缓存法删除缓存法,延迟删除法,都是不友好的。这种的场景是开发人员需要避免的,需要通过预热来解决,而不应当直接扔给缓存系统。当然,由于延迟删除法已经把打到数据库的请求量降到最低,因此表现也不弱于任何其他方案。
## 防缓存穿透与缓存雪崩
[dtm-labs/rockscache](https://github.com/dtm-labs/rockscache)还实现了防缓存穿透与缓存雪崩。
缓存穿透是指,缓存和数据库都没有的数据,被大量请求。由于数据不存在,缓存就也不会存在该数据,所有的请求都会直接穿透到数据库。rockscache中可以设定`EmptyExipire`设定对空结果的缓存时间,如果设定为0,那么不缓存空数据,关闭防缓存穿透
缓存雪崩是指缓存中有大量的数据,在同一个时间点,或者较短的时间段内,全部过期了,这个时候请求过来,缓存没有数据,都会请求数据库,则数据库的压力就会突增,扛不住就会宕机。rockscache可以设定`RandomExpireAdjustment`,对过期时间加上随机值,避免同时过期。
## 应用能否做到强一致?
上面已经介绍了缓存一致性的各种场景,以及相关的解决方案,那么是否可以保证使用缓存的同时,还提供强一致的数据读写呢?强一致的读写需求比前面的最终一致的需求场景少,但是在金融领域,也是有不少场景的。
当我们在这里讨论强一致时,我们需要先把一致性的含义做一下明确。
开发者最直观的强一致性很可能理解为,数据库和缓存保持完全一致,写数据的过程中以及写完之后,无论从数据库直接读,或者从缓存直接读,都能够获得最新写入的结果。对于这种两个独立系统之间的“强一致性”,可以非常明确的说,理论上是不可能的,因为更新数据库和更新缓存在不同的机器上,无法做到同时更新,无论如何都会有时间间隔,在这个时间间隔里,一定是不一致的。
但是应用层的强一致性,则是可以做到的。可以简单考虑我们熟悉的场景:CPU的缓存作为内存的缓存,内存作为磁盘的缓存,这些都是缓存的场景,从来没有发生过一致性问题。为什么?其实很简单,要求所有的数据使用方,只能够从缓存读取数据,而不能同时从缓存和底层存储同时读取数据。
对于DB和Redis,如果所有的数据读取,只能够由缓存提供,就可以很容易的做到强一致,不会出现不一致的情况。下面我们来根据DB和Redis的特点,来分析其中的设计:
#### 先更新缓存还是DB
类比CPU缓存与内存,内存缓存与磁盘,这两个系统都是先修改缓存,再修改底层存储,那么到了现在的DB缓存场景是否也先修改缓存再修改DB?
在绝大多数的应用场景下,开发者会认为Redis作为缓存,当Redis出现故障时,那么应用需要支持降级处理,依旧能够访问数据库,提供一定的服务能力。考虑这种场景,一旦出现降级,先写缓存再写DB方案就有问题,一方面会丢失数据,另一方面会发生先读取到缓存中的新版本v2,再读取到旧版本v1。因此在Redis作为缓存的场景下,绝大部分系统会采取先写入DB,再写入缓存的这种设计
#### 写入DB成功缓存失败情况
假如因为进程crash,导致写入DB成功,但是标记延迟删除第一次失败怎么办?虽然间隔几秒之后,会重试成功,但这几秒钟的时间里,用户去读取缓存,依旧还是旧版本的数据。例如用户发起了一笔充值,资金已经进入到DB,只是更新缓存失败,导致从缓存看到的余额还是旧值。这种情况的处理很简单,用户充值时,写入DB成功时,应用不要给用户返回成功,而是等缓存更新也成功了,再给用户返回成功;用户查询充值交易时,要查询DB和缓存是否都成功了(可以查询二阶段消息全局事务是否已成功),只有两者都成功了,才返回成功。
在上述的处理策略下,当用户发起充值后,在缓存更新完成之前,用户看到的是,这笔交易还在处理中,结果未知,此时是符合强一致要求的;当用户看到交易已经处理成功,也就是缓存已更新成功,那么所有从缓存中拿到的数据都是更新后的数据,那么也符合强一致的要求。
[dtm-labs/rockscache](https://github.com/dtm-labs/rockscache)也实现了强一致的读取需求。当打开`StrongConsistency`选项,那么rockscache里`Fetch`函数就提供了强一致的缓存读取。其原理与延迟删除差别不大,仅做了很小的改变,就是不再返回旧版本的数据,而是同步等待“取数据”的最新结果
当然这个改变会带来性能上的下降,对比与最终一致的数据读取,强一致的读取一方面要等待当前“取数据”的最新结果,增加了返回延迟,另一方面要等待其他进程的结果,会产生sleep等待,耗费资源。
## 缓存降级升级中的强一致
上述的强一致方案中,说明了其强一致的前提是:“所有的数据读取,只能够由缓存”。不过如果Redis如果发生故障,需要进行降级,那么降级的过程可能很短只有几秒,但是这个几秒内如果不能接受不可访问,还严苛的要求提供访问的话,就会出现读取缓存和读取DB混用情况,就不满足这个前提。不过因为Redis故障的频率不高,要求强一致性的应用通常配备专有Redis,因此遇见故障降级的概率很低,很多应用不会在这个地方提出苛刻的要求。
不过dtm-labs作为数据一致性领域的领导者,也深入研究了这个问题,并给出这种苛刻条件下的解决方案。
#### 升降级的过程
现在我们来考虑应用在Redis缓存出现问题的升降级处理。一般情况下这个升降级的开关在配置中心,当修改配置后,各个应用进程会陆续收到降级配置变更通知,然后在行为上降级。在降级的过程中,会出现缓存与DB混合访问的情况,这时我们上面的方案就有可能出现不一致。那么如何处理才能够保证在这种混合访问的情况下,依旧能够让应用获取到强一致的结果呢?
混合访问的过程中,我们可以采取下面这个策略,来保证DB和缓存混合访问时的数据一致性。
- 更新数据时,使用分布式事务,保证以下操作为原子操作
- 将缓存标记为“锁定中”
- 更新DB
- 将缓存“锁定中”标记去除,标记为延迟删除
- 读取缓存数据时,对于标记为“锁定中”的数据,睡眠等待后再次读取;对于延迟删除的数据,不返回旧数据,等待新数据完成再返回。
- 读取DB数据时,直接读取,无需任何额外操作
这个策略跟前面不考虑降级场景的强一致方案,差别不大,读数据部分完全不变,需要变的是更新数据。rockscache假定更新DB是一个业务上可能失败的操作,于是采用一个SAGA事务来保证原子操作,详情参见例子[dtm-cases/cache](https://github.com/dtm-labs/dtm-cases/tree/main/cache)
升降级的开启关闭有顺序要求,不能够同时开启缓存读和写,而是需要在开启缓存读的时候,所有的写操作都已经确保会更新缓存。
降级的详细过程如下:
1. 最初状态:
- 读:混合读
- 写:DB+缓存
2. 读降级:
- 读:关闭缓存读。混合读 => 全部DB读
- 写:DB+缓存
3. 写降级:
- 读:全部DB读;
- 写:关闭缓存写。DB+缓存 => 只写DB
升级的过程与此相反,如下:
1. 最初状态:
- 读:全部读DB
- 写:全部只写DB
2. 写升级:
- 读:全部读DB
- 写:打开写缓存。只写DB => 写DB+缓存
4. 读升级:
- 读:部分读缓存。全部读DB => 混合读
- 写:写DB+缓存
[dtm-labs/rockscache](https://github.com/dtm-labs/rockscache)已实现了上述强一致的缓存管理方法。
感兴趣的同学,可以参考[dtm-cases/cache](https://github.com/dtm-labs/dtm-cases/tree/main/cache),里面有详尽的例子
## 小结
这篇文章很长,许多的分析比较晦涩,最后将Redis缓存的使用方式做个总结:
- 最简单的方式为:较短的缓存时间,允许少量数据库修改,未同步删除缓存
- 保证最终一致,并且可防缓存击穿的方式为:二阶段消息+延迟删除(rockscache)
- 强一致:二阶段消息+强一致(rockscache)
- 一致性要求最严苛的方式为:二阶段消息+强一致(rockscache)+升降级兼容
对于后两种方式,我们都推荐使用[dtm-labs/rockscache](https://github.com/dtm-labs/rockscache)来作为您的缓存方案
欢迎访问[dtm-labs/rockscache](https://github.com/dtm-labs/rockscache)和[dtm-labs/dtm](https://github.com/dtm-labs/dtm),并star支持我们
有疑问加站长微信联系(非本文作者)




