
来源:[《gothrift 一 go版thrift性能优化项目》](https://tlnet.top/article/fb19efb6aef1dac52a8d95cea2e14d14)
thrift目前最新的版本是0.19.0
调优之后项目 gothrift:[https://github.com/donnie4w/gothrift](https://github.com/donnie4w/gothrift)
`这个项目不会做特别大的修改,只针对特别影响性能的地方做修改,影响小的不改,功能不改,其他更新争取与官方同步更新,gothrift使用方式与官方thrift一样,把库路径换成"github.com/donnie4w/gothrift/thrift" 即可`
`目前优化测试效果,gothrift 反序列化效率为原thrift 3倍以上,内存占比为 原thrift 10%以下。`
`网络传输效率 视不同参数结构有不同表现,某些数据结构下,gothrift传输效率超过原thrift 10倍。`
* * *
事实上,目前go版本的thrift序列化性能总体已经非常好。可能有一些写法的问题会导致序列化没有到达应该有的效果
比如go,直接用thrift提供的<span style="color: rgb(0, 128, 0);">TSerialize</span>来写序列化:
t := thrift.NewTSerializer()
pf := thrift.NewTCompactProtocolFactoryConf(tconf)
t.Protocol = pf.GetProtocol(t.Transport)
_r, _ = t.Write(context.Background(), ts) //ts为struct
从t.Write的实现源码可以看到,真正实现序列化的 是 msg.Write(ctx, t.Protocol) 而t.Write方法最后返回的 b = append(b, t.Transport.Bytes()...) 相当于把序列化的结果拷贝了一份,这个可能是数据安全性方面的考虑,不过按thrift序列化的实现,在序列化时,数据已经经过一次拷贝,没有安全问题。
go写thrift序列化个人的通常的写法都是:
buf := &thrift.TMemoryBuffer{Buffer: bytes.NewBuffer([]byte{})}
protocol := thrift.NewTCompactProtocolConf(buf, tconf)
ts.Write(context.Background(), protocol)
protocol.Flush(context.Background())
_r = buf.Bytes()`
这个写法同样适用于其他语言
比如java
TMemoryBuffer tmb = new TMemoryBuffer(1024);
ts.write(new TCompactProtocol(tmb));
return tmb.getArray();
比如python
def TEncode(ts):
tmb = TMemoryBuffer()
ts.write(TCompactProtocol(tmb))
return tmb.getvalue()
* * *
我测试了protobuf,thrift,go/json,msgpack等序列化框架,从序列化测试结果来看,thrift的序列化性能最好,反序列化性能最差
不过我没有全面测试,我主要针对我项目中用到的类型:整型64位,32位,16位,8位,字符串,bool,binary, list,map
很多序列化的测试报告可能会比较片面,序列化中,类型转换本身对序列化的影响至关重要,如果只是简单测试一两个数据类型,而且赋值时赋很少的数据,比如"1","a", 类似这样测试出来的结果可能与实际业务中表现出来的结果大相径庭。而且测试报告只是针对本次具体环境的测试,不应该推导到全部情况,甚至推导到其他编程语言.
从设计上来看,个人认为thrift的序列化设计模式是优于protobuf的,抛开类型转换算法的优劣,它的性能理应优于protobuf。不过实际测试时,反序列化的结果与我想象相差巨大,看看以下的测试数据:
* * *
thrift版本是0.19.0
测试结果
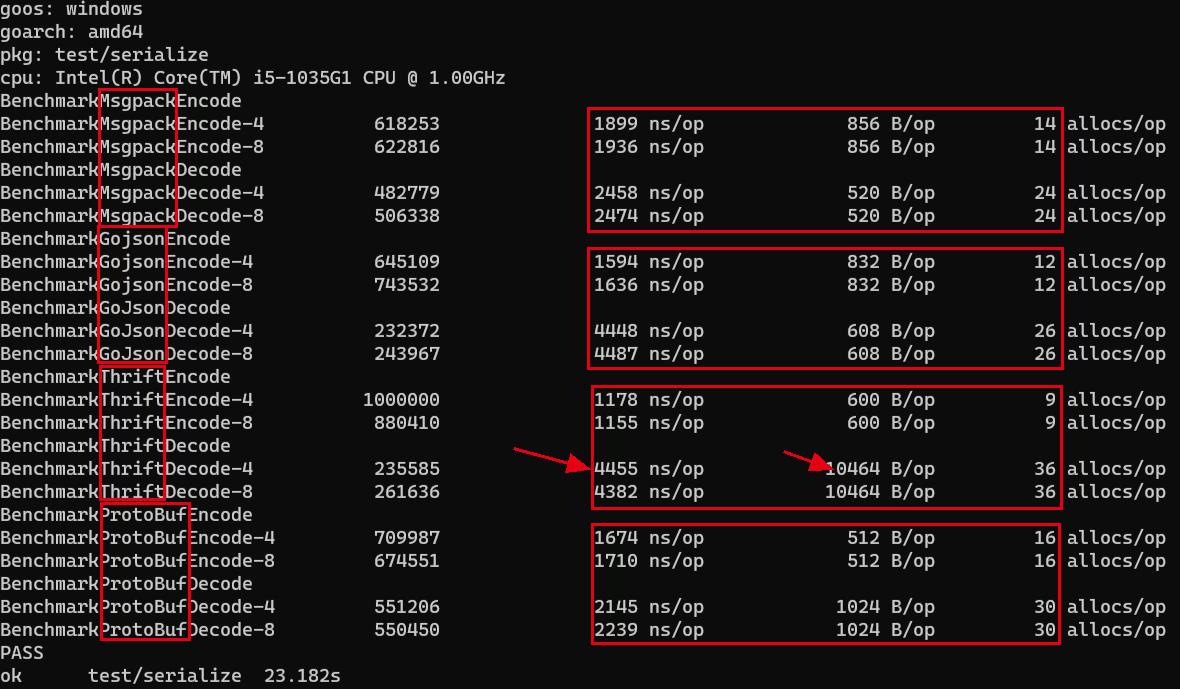
第一是MsgPack,也是序列化框架,可以看出,它的性能也相当不错
第二是go自带的json库,可以看到其实它序列化的性能很好,反序列化性能比较差。
第三是thrift,可以看出序列化方面,无论是性能还是内存占用 thrift表现非常好,但是反序列化比较糟糕,性能差,占用内存大,比别的框架大了一个数量级。
第四是protobuf,protobuf在性能方面一直很好,从结果看,综合来说,protobuf还是最好的。
**以下[gothrift](https://github.com/donnie4w/gothrift)性能优化之后的测试结果:
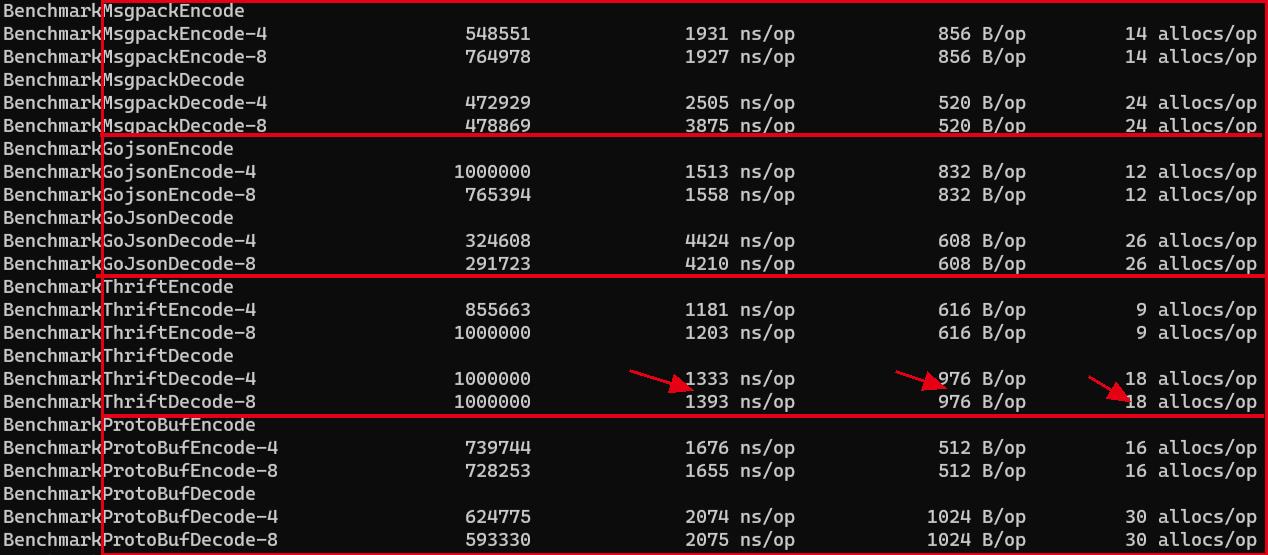
可以看到,其他框架测试结果与之前相差不大。
thrift反序列化优化效果比较明显:


`耗时对比: 4455ns, 4382ns -> 1333ns, 1393ns`
`分配内存对比:10464B -> 976B `
`性能超过3倍,内存消耗也降一个数量级`
这与其他框架比较中,无论序列化还是反序列化,性能表现都是最好的。
thrift的网络传输问题,在这篇文章中有说明《[thrift的网络传输性能和需要注意的问题](https://tlnet.top/article/69674c151133c6f641c55f6e58ff55e2)》,[gothrift](https://github.com/donnie4w/gothrift)所优化的是现thrift存在的问题,达到网络传输效率优化效果。
[**gothrift **](https://github.com/donnie4w/gothrift)除了性能优化,<span style="color: rgb(33, 37, 41); background-color: rgb(255, 255, 255); font-size: 16px;">也优化部分网络传输的实现,使其更适合海量高并发数据的传输</span>。
[**gothrift **](https://github.com/donnie4w/gothrift)宗旨是优化性能,不改功能,及时与官方同步更新。如果官方实现更加优秀时,随时可以切换到官方包。
[测试程序](https://github.com/donnie4w/test/tree/main/serialize)[源码](https://github.com/donnie4w/test/tree/main/serialize)[与结果数据](https://github.com/donnie4w/test/tree/main/serialize)
* * *
有任何问题或建议请Email:donnie4w@gmail.com或 https://tlnet.top/contact 发信给我,谢谢!
有疑问加站长微信联系(非本文作者)




