
> 本文由云+社区发表
> 导语:卷积神经网络日益增长的深度和尺寸为深度学习在移动端的部署带来了巨大的挑战,CNN模型压缩与加速成为了学术界和工业界都重点关注的研究领域之一。
## 前言
自从AlexNet一举夺得ILSVRC 2012 ImageNet图像分类竞赛的冠军后,卷积神经网络(CNN)的热潮便席卷了整个计算机视觉领域。CNN模型火速替代了传统人工设计(hand-crafted)特征和分类器,不仅提供了一种端到端的处理方法,还大幅度地刷新了各个图像竞赛任务的精度,更甚者超越了人眼的精度(LFW人脸识别任务)。CNN模型在不断逼近计算机视觉任务的精度极限的同时,其深度和尺寸也在成倍增长。
自从AlexNet一举夺得ILSVRC 2012 ImageNet图像分类竞赛的冠军后,卷积神经网络(CNN)的热潮便席卷了整个计算机视觉领域。CNN模型火速替代了传统人工设计(hand-crafted)特征和分类器,不仅提供了一种端到端的处理方法,还大幅度地刷新了各个图像竞赛任务的精度,更甚者超越了人眼的精度(LFW人脸识别任务)。CNN模型在不断逼近计算机视觉任务的精度极限的同时,其深度和尺寸也在成倍增长。
表1 几种经典模型的尺寸,计算量和参数数量对比
| Model | Model Size(MB) | MillionMult-Adds | MillionParameters |
| --------------- | -------------- | ---------------- | ----------------- |
| AlexNet[1] | >200 | 720 | 60 |
| VGG16[2] | >500 | 15300 | 138 |
| GoogleNet[3] | ~50 | 1550 | 6.8 |
| Inception-v3[4] | 90-100 | 5000 | 23.2 |
随之而来的是一个很尴尬的场景:如此巨大的模型只能在有限的平台下使用,根本无法移植到移动端和嵌入式芯片当中。就算想通过网络传输,但较高的带宽占用也让很多用户望而生畏。另一方面,大尺寸的模型也对设备功耗和运行速度带来了巨大的挑战。因此这样的模型距离实用还有一段距离。
在这样的情形下,模型小型化与加速成了亟待解决的问题。其实早期就有学者提出了一系列CNN模型压缩方法,包括权值剪值(prunning)和矩阵SVD分解等,但压缩率和效率还远不能令人满意。
近年来,关于模型小型化的算法从压缩角度上可以大致分为两类:从模型权重数值角度压缩和从网络架构角度压缩。另一方面,从兼顾计算速度方面,又可以划分为:仅压缩尺寸和压缩尺寸的同时提升速度。
本文主要讨论如下几篇代表性的文章和方法,包括SqueezeNet[5]、Deep Compression[6]、XNorNet[7]、Distilling[8]、MobileNet[9]和ShuffleNet[10],也可按照上述方法进行大致分类:
表2 几种经典压缩方法及对比
| Method | Compression Approach | Speed Consideration |
| ---------------- | -------------------- | ------------------- |
| SqueezeNet | architecture | No |
| Deep Compression | weights | No |
| XNorNet | weights | Yes |
| Distilling | architecture | No |
| MobileNet | architecture | Yes |
| ShuffleNet | architecture | Yes |
## 一、SqueezeNet
### 1.1 设计思想
SqueezeNet是F. N. Iandola,S.Han等人于2016年的论文《SqueezeNet: AlexNet-level accuracy with 50x fewer parameters and < 0.5MB model size》中提出的一个小型化的网络模型结构,该网络能在保证不损失精度的同时,将原始AlexNet压缩至原来的510倍左右(< 0.5MB)。
SqueezeNet的核心指导思想是——在保证精度的同时使用最少的参数。
而这也是所有模型压缩方法的一个终极目标。
基于这个思想,SqueezeNet提出了3点网络结构设计策略:
策略 1.将3x3卷积核替换为1x1卷积核。
这一策略很好理解,因为1个1x1卷积核的参数是3x3卷积核参数的1/9,这一改动理论上可以将模型尺寸压缩9倍。
策略 2.减小输入到3x3卷积核的输入通道数。
我们知道,对于一个采用3x3卷积核的卷积层,该层所有卷积参数的数量(不考虑偏置)为:
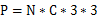
式中,N是卷积核的数量,也即输出通道数,C是输入通道数。
因此,为了保证减小网络参数,不仅仅需要减少3x3卷积核的数量,还需减少输入到3x3卷积核的输入通道数量,即式中C的数量。
策略 3.尽可能的将降采样放在网络后面的层中。
在卷积神经网络中,每层输出的特征图(feature map)是否下采样是由卷积层的步长或者池化层决定的。而一个重要的观点是:分辨率越大的特征图(延迟降采样)可以带来更高的分类精度,而这一观点从直觉上也可以很好理解,因为分辨率越大的输入能够提供的信息就越多。
上述三个策略中,前两个策略都是针对如何降低参数数量而设计的,最后一个旨在最大化网络精度。
### 1.2 网络架构
基于以上三个策略,作者提出了一个类似inception的网络单元结构,取名为fire module。一个fire module 包含一个squeeze 卷积层(只包含1x1卷积核)和一个expand卷积层(包含1x1和3x3卷积核)。其中,squeeze层借鉴了inception的思想,利用1x1卷积核来降低输入到expand层中3x3卷积核的输入通道数。如图1所示。
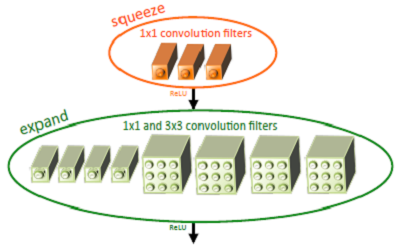
图1 Fire module结构示意图[5]
其中,定义squeeze层中1x1卷积核的数量是s1x1,类似的,expand层中1x1卷积核的数量是e1x1, 3x3卷积核的数量是e3x3。令s1x1 < e1x1+ e3x3从而保证输入到3x3的输入通道数减小。SqueezeNet的网络结构由若干个 fire module 组成,另外文章还给出了一些架构设计上的细节:
- 为了保证1x1卷积核和3x3卷积核具有相同大小的输出,3x3卷积核采用1像素的zero-padding和步长
- squeeze层和expand层均采用RELU作为激活函数
- 在fire9后采用50%的dropout
- 由于全连接层的参数数量巨大,因此借鉴NIN[11]的思想,去除了全连接层而改用global average pooling。
### 1.3 实验结果
表3 不同压缩方法在ImageNet上的对比实验结果[5]
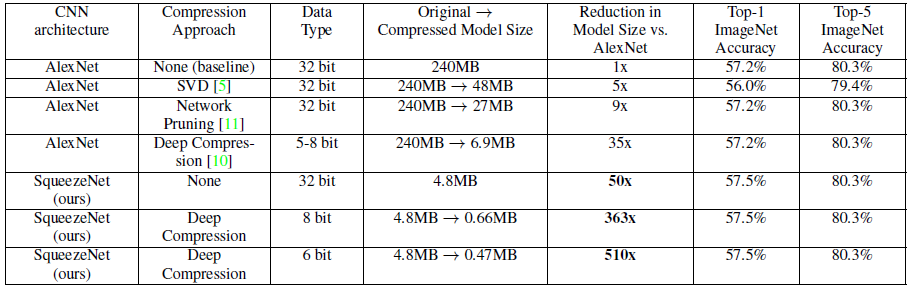
上表显示,相比传统的压缩方法,SqueezeNet能在保证精度不损(甚至略有提升)的情况下,达到最大的压缩率,将原始AlexNet从240MB压缩至4.8MB,而结合Deep Compression后更能达到0.47MB,完全满足了移动端的部署和低带宽网络的传输。
此外,作者还借鉴ResNet思想,对原始网络结构做了修改,增加了旁路分支,将分类精度提升了约3%。
### 1.4 速度考量
尽管文章主要以压缩模型尺寸为目标,但毋庸置疑的一点是,SqueezeNet在网络结构中大量采用1x1和3x3卷积核是有利于速度的提升的,对于类似caffe这样的深度学习框架,在卷积层的前向计算中,采用1x1卷积核可避免额外的im2col操作,而直接利用gemm进行矩阵加速运算,因此对速度的优化是有一定的作用的。然而,这种提速的作用仍然是有限的,另外,SqueezeNet采用了9个fire module和两个卷积层,因此仍需要进行大量常规卷积操作,这也是影响速度进一步提升的瓶颈。
## 二、Deep Compression
Deep Compression出自S.Han 2016 ICLR的一篇论文《Deep Compression: Compressing Deep Neural Networks with Pruning, Trained Quantization and Huffman Coding》。该文章获得了ICLR 2016的最佳论文奖,同时也具有里程碑式的意义,引领了CNN模型小型化与加速研究方向的新狂潮,使得这一领域近两年来涌现出了大量的优秀工作与文章。
### 2.1 算法流程
与前面的“架构压缩派”的SqueezeNet不同,Deep Compression是属于“权值压缩派”的。而两篇文章均出自S.Han团队,因此两种方法结合,双剑合璧,更是能达到登峰造极的压缩效果。这一实验结果也在上表中得到验证。
Deep Compression的算法流程包含三步,如图2所示:
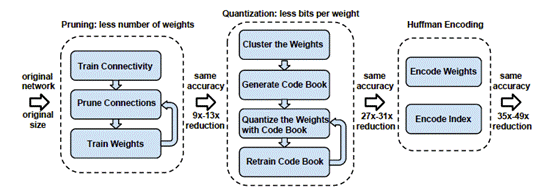
图2 Deep Compression Pipeline[6]
1、Pruning(权值剪枝)
剪枝的思想其实早已在早期论文中可以窥见,LeCun等人曾经就利用剪枝来稀疏网络,减小过拟合的风险,提升网络泛化性。
图3是MNIST上训练得到的LeNet conv1卷积层中的参数分布,可以看出,大部分权值集中在0处附近,对网络的贡献较小,在剪值中,将0值附近的较小的权值置0,使这些权值不被激活,从而着重训练剩下的非零权值,最终在保证网络精度不变的情况下达到压缩尺寸的目的。
实验发现模型对剪枝更敏感,因此在剪值时建议逐层迭代修剪,另外每层的剪枝比例如何自动选取仍然是一个值得深入研究的课题。
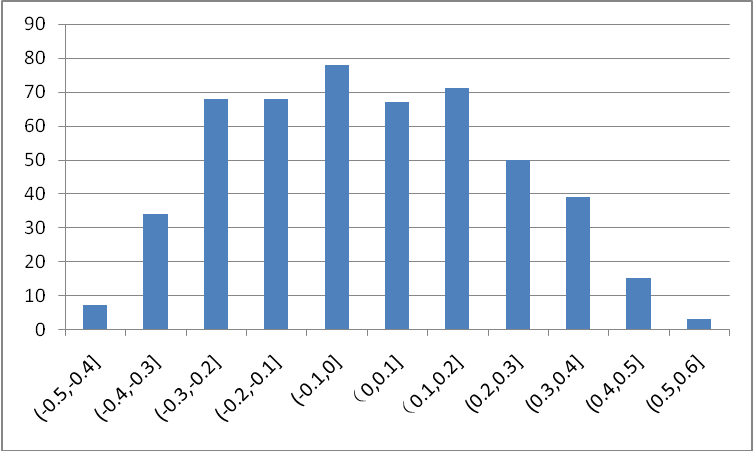
图3 LeNet conv1层权值分布图
2、Quantization (权值量化)
此处的权值量化基于权值聚类,将连续分布的权值离散化,从而减小需要存储的权值数量。
- 初始化聚类中心,实验证明线性初始化效果最好;
- 利用k-means算法进行聚类,将权值划分到不同的cluster中;
- 在前向计算时,每个权值由其聚类中心表示;
- 在后向计算时,统计每个cluster中的梯度和将其反传。
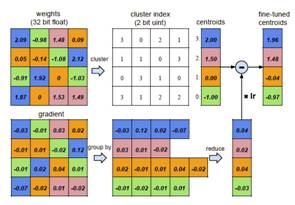
图4 权值量化前向和后向计算过程[6]
3、Huffman encoding(霍夫曼编码)
霍夫曼编码采用变长编码将平均编码长度减小,进一步压缩模型尺寸。
### 2.2 模型存储
前述的剪枝和量化都是为了实现模型的更紧致的压缩,以实现减小模型尺寸的目的。
- 对于剪枝后的模型,由于每层大量参数为0,后续只需将非零值及其下标进行存储,文章中采用CSR(Compressed Sparse Row)来进行存储,这一步可以实现9x~13x的压缩率。
- 对于量化后的模型,每个权值都由其聚类中心表示(对于卷积层,聚类中心设为256个,对于全连接层,聚类中心设为32个),因此可以构造对应的码书和下标,大大减少了需要存储的数据量,此步能实现约3x的压缩率。
- 最后对上述压缩后的模型进一步采用变长霍夫曼编码,实现约1x的压缩率。
### 2.3 实验结果
表4 不同网络采用Deep Compression后的压缩率[6]
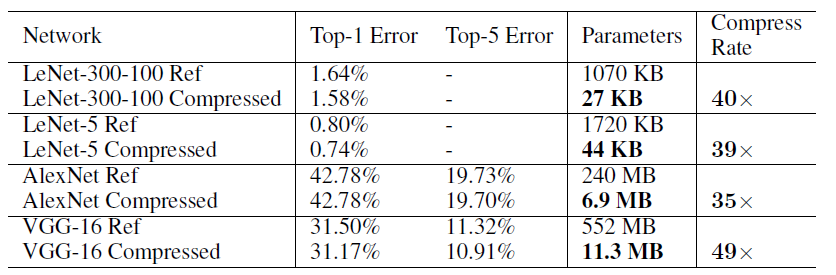
通过SqueezeNet+Deep Compression,可以将原始240M的AlexNet压缩至0.47M,实现约510x的压缩率。
### 2.4 速度考量
可以看出,Deep Compression的主要设计是针对网络存储尺寸的压缩,但在前向时,如果将存储模型读入展开后,并没有带来更大的速度提升。因此Song H.等人专门针对压缩后的模型设计了一套基于FPGA的硬件前向加速框架EIE[12],有兴趣的可以研究一下。
## 三、XNorNet
二值网络一直是模型压缩和加速领域经久不衰的研究课题之一。将原始32位浮点型的权值压缩到1比特,如何最大程度地减小性能损失就成为了研究的关键。
此篇论文主要有以下几个贡献:
- 提出了一个BWN(Binary-Weight-Network)和XNOR-Network,前者只对网络参数做二值化,带来约32x的存储压缩和2x的速度提升,而后者对网络输入和参数都做了二值化,在实现32x存储压缩的同时带了58x的速度提升;
- 提出了一个新型二值化权值的算法;
- 第一个在大规模数据集如ImageNet上提交二值化网络结果的工作;
- 无需预训练,可实现training from scratch。
### 3.1 BWN
为了训练二值化权值网络,令
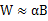
,其中
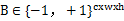
,即二值滤波器,
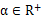
是是尺度因子。通过最小化目标函数,得到其最优解:
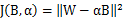
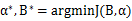


即最优的二值化滤波器张量B即为原始参数的符号函数,最优的尺度因子为每个滤波器权值的绝对值的均值。
训练算法如图5所示,值得注意的是,只有在前向计算和后向传播时使用二值化后的权值,在更新参数时依然使用原始参数,这是因为如果使用二值化后的参数会导致很小的梯度下降,从而使得训练无法收敛。
### 3.2 XNOR-Net
在XNOR网络中,优化的目标是将两个实数向量的点乘近似到两个二值向量的点乘,即
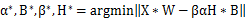
式中,

,
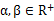
类似的,有最优解如下式
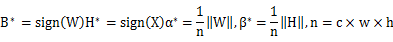
在卷积计算中,输入和权值均量化成了二值,因此传统的乘法计算变成了异或操作,而非二值化数据的计算只占了很小一部分。
XNOR-Net中一个典型的卷积单元如图6所示,与传统单元不同,各模块的顺序有了调整。为了减少二值化带来的精度损失,对输入数据首先进行BN归一化处理,BinActiv层用于对输入做二值化,接着进行二值化的卷积操作,最后进行pooling。

图5 BWN训练过程[7]

图6 传统卷积单元与XNOR-Net卷积单元对比[7]
### 3.3 实验结果
表5 ImageNet上二值网络与AlexNet结果对比[7]
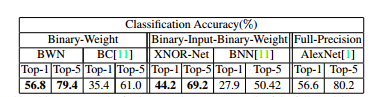
与ALexNet相比,BWN网络能够达到精度基本不变甚至略好,XNOR-Net由于对输入也做了二值化,性能稍降。
## 四、Distilling
Distilling算法是Hinton等人在论文Distilling the Knowledge in a Neural Network中提出的一种类似网络迁移的学习算法。
### 4.1 基本思想
Distilling直译过来即蒸馏,其基本思想是通过一个性能好的大网络来教小网络学习,从而使得小网络能够具备跟大网络一样的性能,但蒸馏后的小网络参数规模远远小于原始大网络,从而达到压缩网络的目的。
其中,训练小模型(distilled model)的目标函数由两部分组成
1) 与大模型(cumbersome model)的softmax输出的交叉熵(cross entropy),称为软目标(soft target)。其中,softmax的计算加入了超参数温度T,用以控制输出,计算公式变为
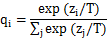
温度T越大,输出的分布越缓和,概率zi/T越小,熵越大,但若T过大,会导致较大熵引起的不确定性增加,增加了不可区分性。
至于为何要以soft target来计算损失,作者认为,在分类问题中,真值(groundtruth)是一个确定性的,即one-hot vector。以手写数字分类来说,对于一个数字3,它的label是3的概率是1,而是其他数值的概率是0,而对于soft target,它能表征label是3的概率,假如这个数字写的像5,还可以给出label是5的一定概率,从而提供更多信息,如
| 数字 | 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 |
| ------ | ---- | ---- | ---- | ---- | ---- | ----- | ----- | ---- | ---- | ---- |
| 真值 | 0 | 0 | 0 | 1 | 0 | 0 | 0 | 0 | 0 | 0 |
| 软目标 | 0 | 0 | 0 | 0.95 | 0 | 0.048 | 0.002 | 0 | 0 | 0 |
2)与真值(groundtruth)的交叉熵(T=1)
训练的损失为上述两项损失的加权和,通常第二项要小很多。
### 4.2 实验结果
作者给出了在语音识别上的实验结果对比,如下表
表6 蒸馏模型与原始模型精度对比[8]
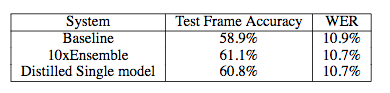
上表显示,蒸馏后的模型的精确度和单字错误率和用于产生软目标的10个模型的性能相当,小模型成功地学到了大模型的识别能力。
### 4.3 速度考量
Distilling的提出原先并非针对网络加速,而最终计算的效率仍然取决于蒸馏模型的计算规模,但理论上蒸馏后的小模型相对原始大模型的计算速度在一定程度上会有提升,但速度提升的比例和性能维持的权衡是一个值得研究的方向。
## 五、MobileNet
MobileNet是由Google提出的针对移动端部署的轻量级网络架构。考虑到移动端计算资源受限以及速度要求严苛,MobileNet引入了传统网络中原先采用的group思想,即限制滤波器的卷积计算只针对特定的group中的输入,从而大大降低了卷积计算量,提升了移动端前向计算的速度。
### 5.1 卷积分解
MobileNet借鉴factorized convolution的思想,将普通卷积操作分成两部分:
- Depthwise Convolution 每个卷积核滤波器只针对特定的输入通道进行卷积操作,如下图所示,其中M是输入通道数,DK是卷积核尺寸:
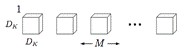
图7 Depthwise Convolution[9]
Depthwise convolution的计算复杂度为 DKDKMDFDF,其中DF是卷积层输出的特征图的大小。
- Pointwise Convolution
采用1x1大小的卷积核将depthwise convolution层的多通道输出进行结合,如下图,其中N是输出通道数:

图8 Pointwise Convolution[9]
Pointwise Convolution的计算复杂度为 MNDFDF
上面两步合称depthwise separable convolution
标准卷积操作的计算复杂度为DKDKMNDFDF
因此,通过将标准卷积分解成两层卷积操作,可以计算出理论上的计算效率提升比例:

对于3x3尺寸的卷积核来说,depthwise separable convolution在理论上能带来约8~9倍的效率提升。
### 5.2 模型架构
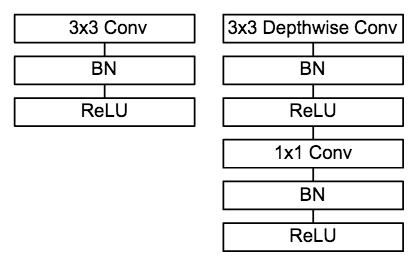
图9 普通卷积单元与MobileNet 卷积单元对比[9]
MobileNet的卷积单元如上图所示,每个卷积操作后都接着一个BN操作和ReLU操作。在MobileNet中,由于3x3卷积核只应用在depthwise convolution中,因此95%的计算量都集中在pointwise convolution 中的1x1卷积中。而对于caffe等采用矩阵运算GEMM实现卷积的深度学习框架,1x1卷积无需进行im2col操作,因此可以直接利用矩阵运算加速库进行快速计算,从而提升了计算效率。
### 5.3 实验结果
表7 MobileNet与主流大模型在ImageNet上精度对比[9]
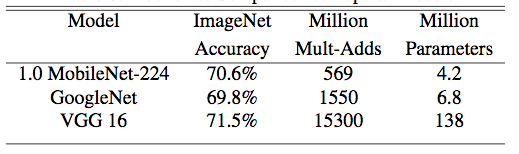
上表显示,MobileNet在保证精度不变的同时,能够有效地减少计算操作次数和参数量,使得在移动端实时前向计算成为可能。
## 六、ShuffleNet
ShuffleNet是Face++今年提出了一篇用于移动端前向部署的网络架构。ShuffleNet基于MobileNet的group思想,将卷积操作限制到特定的输入通道。而与之不同的是,ShuffleNet将输入的group进行打散,从而保证每个卷积核的感受野能够分散到不同group的输入中,增加了模型的学习能力。
### 6.1 设计思想
我们知道,卷积中的group操作能够大大减少卷积操作的计算次数,而这一改动带来了速度增益和性能维持在MobileNet等文章中也得到了验证。然而group操作所带来的另一个问题是:特定的滤波器仅对特定通道的输入进行作用,这就阻碍了通道之间的信息流传递,group数量越多,可以编码的信息就越丰富,但每个group的输入通道数量减少,因此可能造成单个卷积滤波器的退化,在一定程度上削弱了网络了表达能力。
### 6.2 网络架构
在此篇工作中,网络架构的设计主要有以下几个创新点:
- 提出了一个类似于ResNet的BottleNeck单元
借鉴ResNet的旁路分支思想,ShuffleNet也引入了类似的网络单元。不同的是,在stride=2的单元中,用concat操作代替了add操作,用average pooling代替了1x1stride=2的卷积操作,有效地减少了计算量和参数。单元结构如图10所示。
- 提出将1x1卷积采用group操作会得到更好的分类性能
在MobileNet中提过,1x1卷积的操作占据了约95%的计算量,所以作者将1x1也更改为group卷积,使得相比MobileNet的计算量大大减少。
- 提出了核心的shuffle操作将不同group中的通道进行打散,从而保证不同输入通道之间的信息传递。
ShuffleNet的shuffle操作如图11所示。
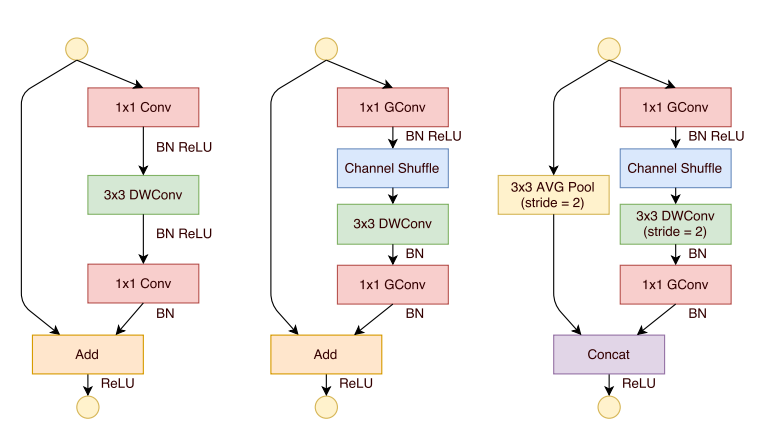
图10 ShuffleNet网络单元[10]
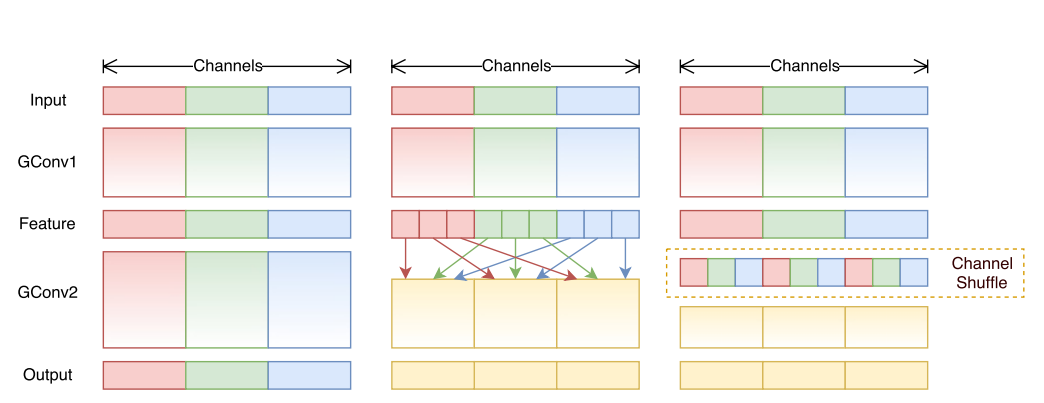
图11 不同group间的shuffle操作[10]
### 6.3 实验结果
表8 ShuffleNet与MobileNet在ImageNet上精度对比 [10]
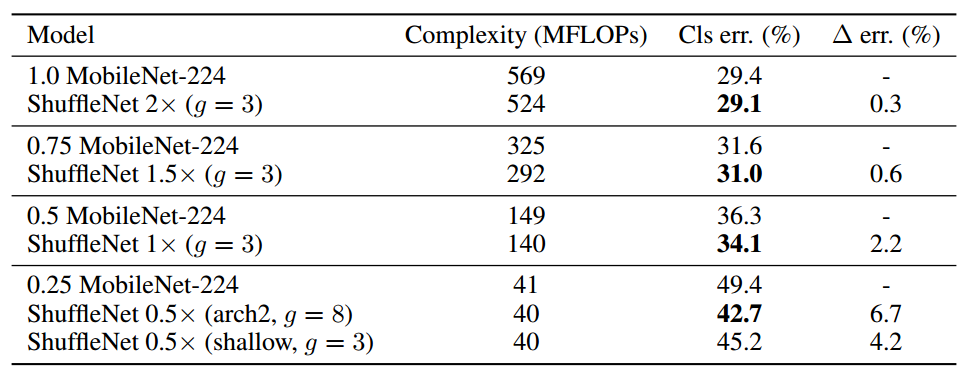
上表显示,相对于MobileNet,ShuffleNet的前向计算量不仅有效地得到了减少,而且分类错误率也有明显提升,验证了网络的可行性。
### 6.4 速度考量
作者在ARM平台上对网络效率进行了验证,鉴于内存读取和线程调度等因素,作者发现理论上4x的速度提升对应实际部署中约2.6x。作者给出了与原始AlexNet的速度对比,如下表。
表9 ShuffleNet与AlexNet在ARM平台上速度对比 [10]

## 结束语
近几年来,除了学术界涌现的诸多CNN模型加速工作,工业界各大公司也推出了自己的移动端前向计算框架,如Google的Tensorflow、Facebook的caffe2以及苹果今年刚推出的CoreML。相信结合不断迭代优化的网络架构和不断发展的硬件计算加速技术,未来深度学习在移动端的部署将不会是一个难题。
## 参考文献
[1] ImageNet Classification with Deep Convolutional Neural Networks
[2] Very Deep Convolutional Networks for Large-Scale Image Recognition
[3] Going Deeper with Convolutions
[4] Rethinking the Inception Architecture for Computer Vision
[5] SqueezeNet: AlexNet-level accuracy with 50x fewer parameters and < 0.5MB model size
[6] Deep Compression: Compressing Deep Neural Networks with Pruning, Trained Quantization and Huffman Coding
[7] Distilling the Knowledge in a Neural Network
[8] XNOR-Net: ImageNet Classification Using Binary Convolutional Neural Networks
[9] MobileNets: Efficient Convolutional Neural Networks for Mobile Vision Applications
[10] ShuffleNet: An Extremely Efficient Convolutional Neural Network for Mobile Devices
[11] Network in Network
[12] EIE: Efficient Inference Engine on Compressed Deep Neural Network
**此文已由作者授权腾讯云+社区在各渠道发布**
**获取更多新鲜技术干货,可以关注我们腾讯云技术社区-云加社区官方号**
有疑问加站长微信联系(非本文作者)




