
本文由云+社区发表
作者:腾讯云数据库团队
随着国内服务共享化的热潮普及,共享单车,共享雨伞,共享充电宝等各种服务如雨后春笋,随之而来的LBS服务定位问题成为了后端服务的一个挑战。MongoDB对LBS查询的支持较为友好,也是各大LBS服务商的首选数据库。腾讯云MongoDB团队在运营中发现,原生MongoDB在LBS服务场景下有较大的性能瓶颈,经腾讯云团队专业的定位分析与优化后,云MongoDB在LBS服务的综合性能上,有10倍以上的提升。 腾讯云MongoDB提供的优异综合性能,为国内各大LBS服务商,例如摩拜单车等,提供了强有力的保障。
LBS业务特点
以共享单车服务为例,LBS业务具有2个特点,分别是时间周期性和坐标分布不均匀。
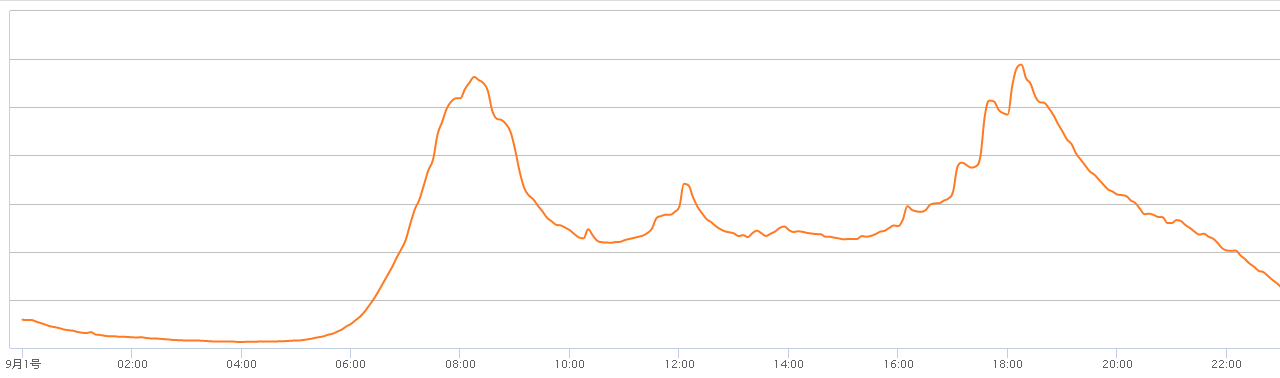
一.时间周期性
高峰期与低谷期的QPS量相差明显,并且高峰期和低峰期的时间点相对固定。
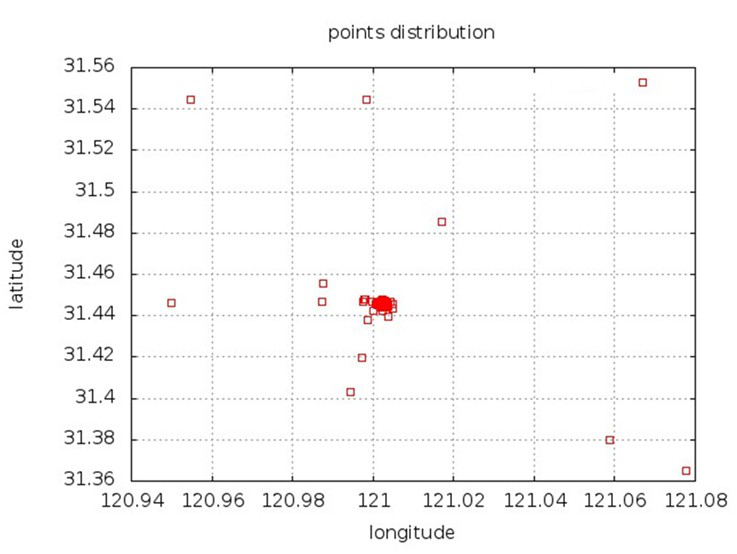
二.坐标分布不均匀
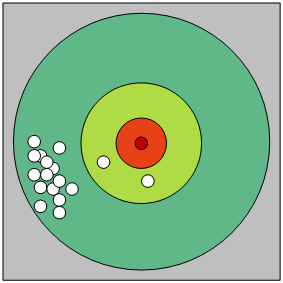
坐地铁的上班族,如果留意可能会发现,在上班早高峰时,地铁周围摆满了共享单车,而下班 时段,地铁周围的共享单车数量非常少。如下图,经纬度(121,31.44)附近集中了99%以上 的坐标。此外,一些特殊事件也会造成点的分布不均匀,例如深圳湾公园在特殊家假日涌入大量的客户,同时这个地域也会投放大量的单车。部分地域单车量非常集中,而其他地域就非常稀疏。
MongoDB的LBS服务原理
MongoDB中使用2d_index 或2d_sphere_index来创建地理位置索引(geoIndex),两者差别不大,下面我们以2d_index为例来介绍。
一.2D索引的创建与使用
db.coll.createIndex({"lag":"2d"}, {"bits":int}))
通过上述命令来创建一个2d索引,索引的精度通过bits来指定,bits越大,索引的精度就越高。更大的bits带来的插入的overhead可以忽略不计
db.runCommand({
geoNear: tableName,
maxDistance: 0.0001567855942887398,
distanceMultiplier: 6378137.0,
num: 30,
near: [ 113.8679388183982, 22.58905429302385 ],
spherical: true|false})
通过上述命令来查询一个索引,其中spherical:true|false 表示应该如何理解创建的2d索引,false表示将索引理解为平面2d索引,true表示将索引理解为球面经纬度索引。这一点比较有意思,一个2d索引可以表达两种含义,而不同的含义是在查询时被理解的,而不是在索引创建时。
二.2D索引的理论 MongoDB 使用GeoHash的技术来构建2d索引(见wiki geohash 文字链 https://en.wikipedia.org/wiki/Geohash )。MongoDB使用平面四叉树划分的方式来生成GeoHashId,每条记录有一个GeoHashId,通过GeoHashId->RecordId的索引映射方式存储在Btree中
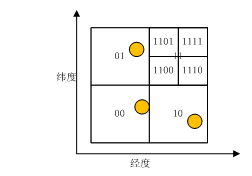
很显然的,一个2bits的精度能把平面分为4个grid,一个4bits的精度能把平面分为16个grid。 2d索引的默认精度是长宽各为26,索引把地球分为(2^26)(2^26)块,每一块的边长估算为2PI6371000/(1<<26) = 0.57 米 mongodb的官网上说的60cm的精度就是这么估算出来的 By default, a 2d index on legacy coordinate pairs uses 26 bits of precision, which isroughly equivalent to 2 feet or 60 centimeters of precision using the default range of-180 to 180
三.2D索引在Mongodb中的存储
上面我们讲到Mongodb使用平面四叉树的方式计算Geohash。事实上,平面四叉树仅存在于运算的过程中,在实际存储中并不会被使用到。
插入 对于一个经纬度坐标[x,y],MongoDb计算出该坐标在2d平面内的grid编号,该编号为是一个52bit的int64类型,该类型被用作btree的key,因此实际数据是按照 {GeoHashId->RecordValue}的方式被插入到btree中的。
查询 对于geo2D索引的查询,常用的有geoNear和geoWithin两种。geoNear查找距离某个点最近的N个点的坐标并返回,该需求可以说是构成了LBS服务的基础(陌陌,滴滴,摩拜),geoWithin是查询一个多边形内的所有点并返回。我们着重介绍使用最广泛的geoNear查询。
geoNear的查询过程,查询语句如下
db.runCommand(
{
geoNear: "places", //table Name
near: [ -73.9667, 40.78 ] , // central point
spherical: true, // treat the index as a spherical index
query: { category: "public" } // filters
maxDistance: 0.0001531 // distance in about one kilometer
}
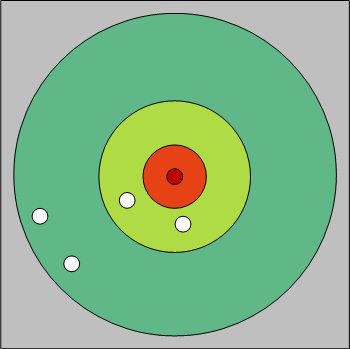
geoNear可以理解为一个从起始点开始的不断向外扩散的环形搜索过程。如下图所示: 由于圆自身的性质,外环的任意点到圆心的距离一定大于内环任意点到圆心的距离,所以以圆 环进行扩张迭代的好处是: 1)减少需要排序比较的点的个数 2)能够尽早发现满足条件的点从而返回,避免不必要的搜索 MongoDB在实现的细节中,如果内环搜索到的点数过少,圆环每次扩张的步长会倍增
MongoDB LBS服务遇到的问题
部分大客户在使用MongoDB的geoNear功能查找附近的对象时,经常会发生慢查询较多的问题,早高峰压力是低谷时段的10-20倍,坐标不均匀的情况慢查询严重,濒临雪崩。初步分析发现,这些查询扫描了过多的点集。 如下图,查找500米范围内,距离最近的10条记录,花费了500ms,扫描了24000+的记录。类似的慢查询占据了高峰期5%左右的查询量
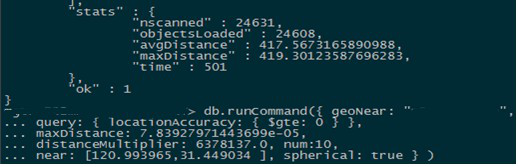
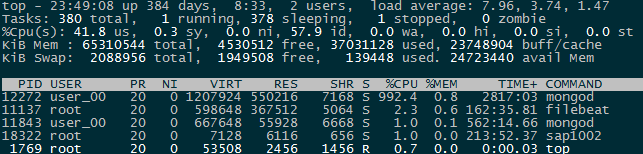
测试环境复现与定位 排查数据库的性能问题,主要从锁等待,IO等待,CPU消耗三封面分析。上面的截图扫描了过多的记录,直觉上是CPU或者IO消耗性的瓶颈。为了严谨起见,我们在测试环境复现后,发现慢日志中无明显的timeAcquiringMicroseconds项排除了MongoDB执行层面的锁竞争问题,并选用较大内存的机器使得数据常驻内存,发现上述用例依旧需要200ms以上的执行时间。10核的CPU资源针对截图中的case,只能支持50QPS。
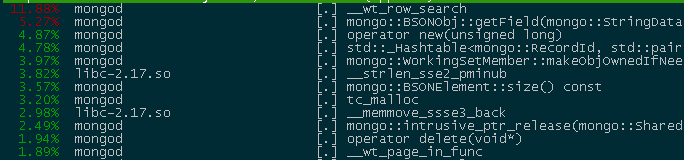
为何扫描集如此大 上面我们说过,MongoDB搜索距离最近的点的过程是一个环形扩张的过程,如果内环满足条件的点不够多,每次的扩张半径都会倍增。因此在遇到内环点稀少,外环有密集点的场景时,容易陷入BadCase。如下图,我们希望找到离中心点距离最近的三个点。由于圆环扩张太快,外环做了很多的无用扫描与排序。 这样的用例很符合实际场景,早高峰车辆聚集在地铁周围,你从家出发一路向地铁,边走边找,共享单车软件上动态搜索距你最近的10辆车,附近只有三两辆,于是扩大搜索半径到地铁周围,将地铁周围的所有几千辆车都扫描计算一遍,返回距离你最近的其余的七八辆
问题的解决
问题我们已经知道了,我们对此的优化方式是控制每一圈的搜索量,为此我们为geoNear命令增加了两个参数,将其传入NearStage中。hintCorrectNum可以控制结果品质的下限,返回的前N个一定是最靠近中心点的N个点。hintScan用以控制扫描集的大小的上限。
hintScan: 已经扫描的点集大小大于hintScan后,做模糊处理。 hintCorrectNum:已经返回的结果数大于hintCorrectNum后,做模糊处理。
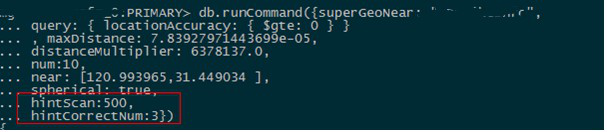
该优化本质上是通过牺牲品质来尽快返回结果。对于国内大部分LBS服务来说,完全的严格最近并不是必要的。且可以通过控制参数获得严格最近的效果。在搜索过程中,密集的点落到一个环内,本身距离相差也不会不大。该优化在上线后,将部分大客户的MongoDB性能上限从单机1000QPS提升了10倍到10000QPS以上。
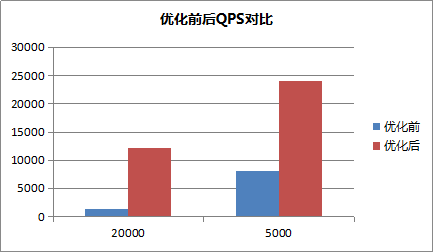
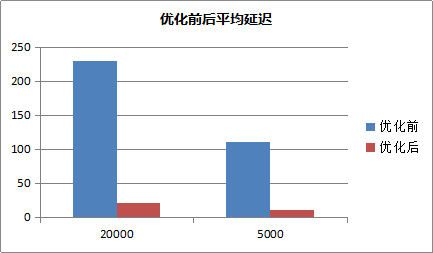
和Redis3.2的对比
Redis3.2也加入了地理位置查询的功能,我们也将开源Redis和云数据库MongoDB进行对比。 Redis使用方式:GEORADIUS appname 120.993965 31.449034 500 m count 30 asc。在密集数据集场景下,使用腾讯云MongoDB和开源的Redis进行了性能对比。下图是在密集数据集上,在24核CPU机器上,MongoDB单实例与Redis单实例的测试对比。需要注意的是Redis本身是单线程的内存缓存数据库。MongoDB是多线程的高可用持久化的数据库,两者的使用场景有较大不同。
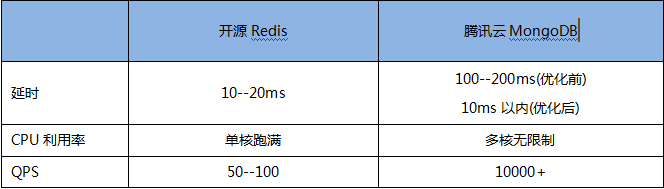
总结
MongoDB原生的geoNear接口是国内各大LBS应用的主流选择。原生MongoDB在点集稠密的情况下,geoNear接口效率会急剧下降,单机甚至不到1000QPS。腾讯云MongoDB团队对此进行了持续的优化,在不影响效果的前提下,geoNear的效率有10倍以上的提升,为我们的客户如摩拜提供了强力的支持,同时相比Redis3.2也有较大的性能优势。
此文已由腾讯云+社区在各渠道发布
获取更多新鲜技术干货,可以关注我们腾讯云技术社区-云加社区官方号及知乎机构号
有疑问加站长微信联系(非本文作者)



