
这里是我的语雀 https://www.yuque.com/abs
# buffer.go
<a name="Overview"></a>
# Overview
这是 bytes 包里的 buffer 实现
<a name="aea8ce3e"></a>
## 一图胜千言
看不懂图的再看下面吧<br />
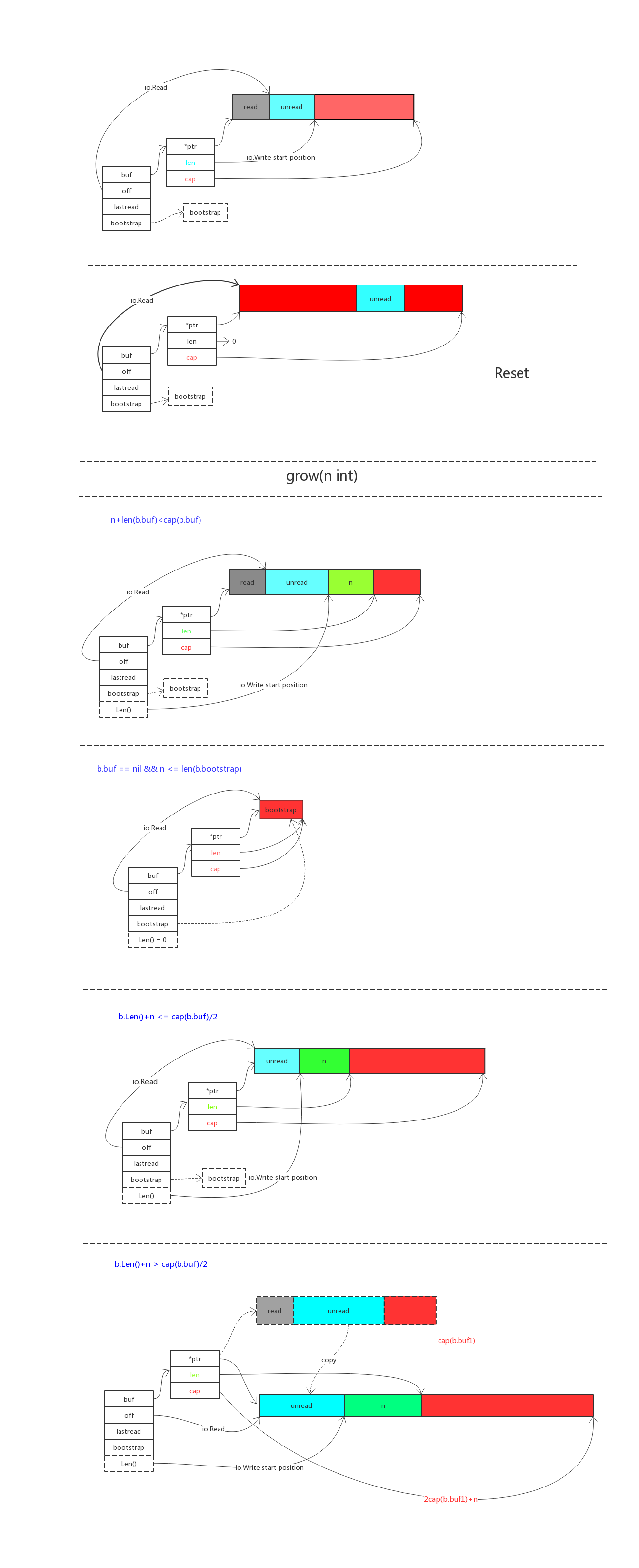
<a name="db3fc4e8"></a>
## 核心函数
<a name="abe899c9"></a>
### Buffer 结构
这是 buffer 的内部结构<br />buf 字节切片,用来存储 buffer 的内容<br />off 是代表从哪里开始读<br />bootstrap 用来作为字节切片过小的时候防止多次申请空间减小开销<br />lastRead 用来记录上一次的操作
```go
// A Buffer is a variable-sized buffer of bytes with Read and Write methods.
// The zero value for Buffer is an empty buffer ready to use.
// 注意 buffer 的零值是空的 buf
type Buffer struct {
buf []byte // contents are the bytes buf[off : len(buf)]
off int // read at &buf[off], write at &buf[len(buf)]
bootstrap [64]byte // memory to hold first slice; helps small buffers avoid allocation.
lastRead readOp // last read operation, so that Unread* can work correctly.
// FIXME: it would be advisable to align Buffer to cachelines to avoid false
// sharing.
}
```
<a name="b9f96af1"></a>
### Grow(n int)
申请扩展缓冲区
```go
// Grow grows the buffer's capacity, if necessary, to guarantee space for
// another n bytes. After Grow(n), at least n bytes can be written to the
// buffer without another allocation.
// If n is negative, Grow will panic.
// If the buffer can't grow it will panic with ErrTooLarge.
// 增加容量 n byte
func (b *Buffer) Grow(n int) {
if n < 0 {
panic("bytes.Buffer.Grow: negative count")
}
m := b.grow(n)
b.buf = b.buf[:m]
}
```
<a name="df6feda3"></a>
### WriteString(s string) (n int, err error)
向 buffer 中写字符串
```go
// WriteString appends the contents of s to the buffer, growing the buffer as
// needed. The return value n is the length of s; err is always nil. If the
// buffer becomes too large, WriteString will panic with ErrTooLarge.
// 直接写 string 也行,同时自动扩展
func (b *Buffer) WriteString(s string) (n int, err error) {
b.lastRead = opInvalid
//先尝试不用扩展容量的写法
m, ok := b.tryGrowByReslice(len(s))
if !ok {
m = b.grow(len(s))
}
// copy 可以直接把 string 类型作为 字节切片拷贝过去
return copy(b.buf[m:], s), nil
}
```
也有写字节切片的形式 `Write(p []byte) (n int, err error)`
<a name="9845d6fe"></a>
### ReadFrom(r io.Reader) (n int64, err error)
从 io.Reader 读取数据到 buffer 中
```go
// ReadFrom reads data from r until EOF and appends it to the buffer, growing
// the buffer as needed. The return value n is the number of bytes read. Any
// error except io.EOF encountered during the read is also returned. If the
// buffer becomes too large, ReadFrom will panic with ErrTooLarge.
// 从实现了 io.Reader 接口的 r 中读取到 EOF 为止,如果超出了 maxInt 那么大就会返回太
// 大不能通过一个 [maxInt]byte 字节切片来存储了
func (b *Buffer) ReadFrom(r io.Reader) (n int64, err error) {
b.lastRead = opInvalid
for {
i := b.grow(MinRead)
// grow 申请了 n 个空间之后,会将 buffer 中的字节切片延长长度到 n 个字节之后
// 所以需要重新赋值一下长度,避免一些误解,保证长度都是有效数据提供的
b.buf = b.buf[:i]
// 将 r 中的数据读到 buffer 中去
m, e := r.Read(b.buf[i:cap(b.buf)])
if m < 0 {
panic(errNegativeRead)
}
// 手动更改长度
b.buf = b.buf[:i+m]
n += int64(m)
if e == io.EOF {
return n, nil // e is EOF, so return nil explicitly
}
if e != nil {
return n, e
}
}
}
```
<a name="c8b4b8d5"></a>
### WriteTo(w io.Writer) (n int64, err error)
向 io.Writer 中写数据
```go
// WriteTo writes data to w until the buffer is drained or an error occurs.
// The return value n is the number of bytes written; it always fits into an
// int, but it is int64 to match the io.WriterTo interface. Any error
// encountered during the write is also returned.
func (b *Buffer) WriteTo(w io.Writer) (n int64, err error) {
b.lastRead = opInvalid
if nBytes := b.Len(); nBytes > 0 {
//从 off 开始读的地方算起,全部写到 io.Writer 中去
m, e := w.Write(b.buf[b.off:])
//写的多了就报错
if m > nBytes {
panic("bytes.Buffer.WriteTo: invalid Write count")
}
//记录写过了多少,位移 offset 指针
b.off += m
n = int64(m)
if e != nil {
return n, e
}
// all bytes should have been written, by definition of
// Write method in io.Writer
// 因为刚才判断过写多了的情况,所以这里是写少了
if m != nBytes {
return n, io.ErrShortWrite
}
}
// Buffer is now empty; reset.
// 写完之后重置
b.Reset()
return n, nil
}
```
<a name="9b97a768"></a>
### ReadBytes(delim byte) (line []byte, err error)
用来读到终止符就结束,返回的是一个 line 字节切片包含终止符前的数据
```go
// ReadBytes reads until the first occurrence of delim in the input,
// returning a slice containing the data up to and including the delimiter.
// If ReadBytes encounters an error before finding a delimiter,
// it returns the data read before the error and the error itself (often io.EOF).
// ReadBytes returns err != nil if and only if the returned data does not end in
// delim.
// 读取到终止符为止,就结束
func (b *Buffer) ReadBytes(delim byte) (line []byte, err error) {
slice, err := b.readSlice(delim)
// return a copy of slice. The buffer's backing array may
// be overwritten by later calls.
line = append(line, slice...)
return line, err
}
```
<a name="8e0f0f0e"></a>
### NewBuffer(buf []byte) *Buffer
用来新建一个新的 Buffer ,其实也可以使用 new 和 var 来声明
```go
// NewBuffer creates and initializes a new Buffer using buf as its
// initial contents. The new Buffer takes ownership of buf, and the
// caller should not use buf after this call. NewBuffer is intended to
// prepare a Buffer to read existing data. It can also be used to size
// the internal buffer for writing. To do that, buf should have the
// desired capacity but a length of zero.
//
// In most cases, new(Buffer) (or just declaring a Buffer variable) is
// sufficient to initialize a Buffer.
// 通过字节切片创建一个 buffer ,字节切片会保留初始值
// 在渴望容量但是长度为 0?的情况下
// 也可以当作内核的 buffer 来写入
func NewBuffer(buf []byte) *Buffer { return &Buffer{buf: buf} }
```
同时也有通过 string 类型的实现<br />`**func NewBufferString(s string) *Buffer {return &Buffer{buf: []byte(s)}}**`
<a name="25f9c7fa"></a>
## 总结
缓冲区,实现了大小控制,字节切片和 string 类型的读写,同时还对情况进行了优化,比如存在 bootstrap,比如 grow 函数中的多次检定。适合多读精读来学习
有疑问加站长微信联系(非本文作者)




