周末花了一晚上的时间,用Go写了一个ID生成服务,Github地址:go-id-alloc。
分布式ID生成,就我来看主要是2个流派,各有利弊,没有完美的实现。
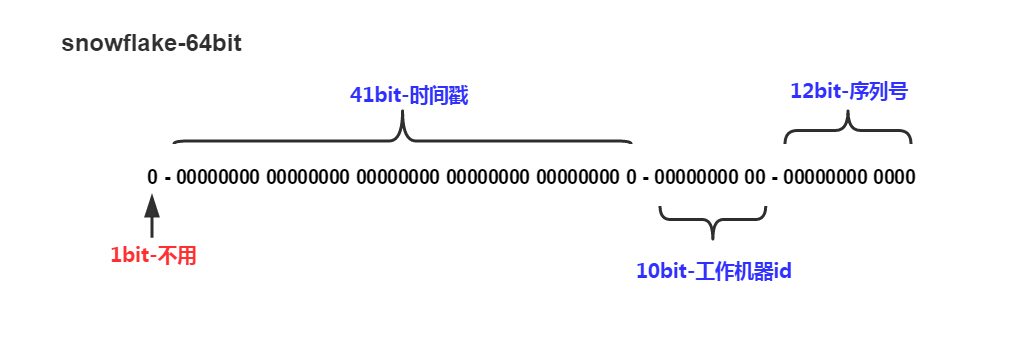
1,snowflake流派。
它用于twitter的微博ID,因为是timeline按发布时间排序,所以这个算法是用毫秒时间戳作为ID的左半部,从而可以实现按时间有序。
像新浪微博也是在使用类似的ID生成算法,snowflake的好处是去中心化,但是依赖时钟的准确性,最差的情况是时钟发生了回退,那么ID就会重复;而如果不开启NTP同步时钟,那么不同节点分配的时间不同,也会影响feed流的排序,所以在我看来只能说基本可用,一旦时钟回退比较大的区间,服务是完全不可用的。美团在这方面做了一些工作,主要还是在发现回退以及报警方面的事情,可以参考:Leaf — 美团点评分布式ID生成系统。
2,mysql流派。
该流派使用广泛,基本原理就是mysql的自增主键。最初为了扩展性能,会通过部署多台mysql,为每个mysql设置不同的起始id,从而实现横向扩展性。
mysql支持自定义表的auto_increment属性,可以用于控制起始ID:
|
1 2 3 4 5 6 7 8 |
CREATE TABLE `partition_1` ( `id` bigint(20) NOT NULL AUTO_INCREMENT, `meanless` tinyint(4) NOT NULL, PRIMARY KEY (`id`), UNIQUE KEY `meanless` (`meanless`) ) ENGINE=InnoDB DEFAULT CHARSET=utf8; ALTER TABLE `partition_1` auto_increment=1; |
ALTER修改了parition_1表的起始ID=1,不同的表可以设置不同的起始ID,例如给partition_2设置auto_increment=2。
仅仅这样是不够的,因为默认partition_1的下一个自增ID=2,会和partition_2表分配的ID重复。
mysql提供了另外一个配置,叫做auto_increment_increment,可以在mysql session级设置(set auto_increment_increment=xxx;),也可以设置给整个mysql实例。该配置用于控制步长,在上述例子中我会设置auto_increment_increment=2,那么2个partition表的ID分配情况如下:
- 1,3,5,7,9…
- 2,4,6,8,10…
你会发现,步长设置为分区的个数,就可以避免ID冲突,整体向更大的ID共同增长了。
那么如何分配下一个ID呢?一般insert新纪录会产生新的ID,而这样会导致数据规模增长,更好的方法是使用replace命令:
|
1 |
replace into partition_0(`meanless`) values(0) |
因为meanless唯一键的原因,id字段会自增,同时最多只会产生一条记录。
在我的go-id-alloc项目中,就是采用了这样的方式实现ID自增,但是仅仅这样还是不够的。数据库更新毕竟存在一个性能的瓶颈,在请求压力更大的业务场景下终将成为一个瓶颈。
新的方案基于mysql自增原理实现,通过”号段”批量获取的方式,将数据库的写入压力降低为忽略不计,下面说明其原理。
仍旧以上面的分配布局为例,两个mysql分别产生如下的ID序列:
- 1,3,5,7,9…
- 2,4,6,8,10…
现在我假设一个号段长度10000,那么当replace产生了ID=1的时候,表示分配得到了[0, 10000)这个号段。同样的,当再次replace时产生ID=3,那么表示分配得到了[20000, 30000)这个号段。
将基于号段的序列重新整理,就会像下面这样:
- [0, 10000),[20000, 30000),[40000,50000),[60000,70000),[80000,90000)
- [10000,20000),[30000,40000),[50000,60000),[70000,80000),[90000,100000)
观察出规律了吗?若分配得到的ID是N,那么号段就是[(N – 1) * SIZE, N * SIZE)。
有了号段,我们只需要写一个服务,每次向mysql分配一个ID,也就得到了一个独占的号段,接下来的ID分配请求可以直接从内存中的号段获取。另外,应当在内存里的号段消耗殆尽之前,向mysql获取新的号段。
通过提升号段的SIZE,我们可以减少访问数据库的频率,从而提升整个ID分配的服务能力。
mysql故障
因为ID序列保存在mysql,因此Mysql丢失数据就变得不可容忍。一般我们有mysql的master-slave模式来实时备份数据,但是毕竟主从存在延迟,主库宕机可能导致最新的更新没有同步给从库,那么就会导致再次分配ID产生重复。
没错,这是mysql方案的劣势,就像snowflake有其自身的劣势一样。但是,通常这个问题可以避免,通过设置更大的号段SIZE,我们可以确保在有限的主从延迟时间内(比如1分钟的延迟),根据业务的请求量,最多只会丢失N次replace产生的ID自增。在这种假设下,我们可以令从库的起始ID跳过一定数量的步长,确保它不会重复。
使用场景
snowflake方案适合时间有序的场景,并且外界无法猜测一天的ID分配总量,从而无法猜测某个公司的业务量;缺点是时间回退服务就会不可用。
mysql方案适合内部业务,对ID有更多的控制能力(比如定义起始ID),扩展性很强,能满足任何体量的业务规模;缺点是依赖mysql,另外ID存在规律,容易暴露公司业务量。
有疑问加站长微信联系(非本文作者)



